Todos os meus posts deste ano foram sobre reações automáticas para esperar estatísticas, mas neste post estou me desviando desse tema para falar sobre um bug em particular meu:o contador de desempenho de expectativa de vida da página (que chamarei de PLE ).
O que significa PLE?
Existem todos os tipos de declarações incorretas sobre a expectativa de vida da página na Internet, e as mais notórias são aquelas que especificam que o valor 300 é o limite para onde você deve se preocupar.
Para entender por que essa afirmação é tão enganosa, você precisa entender o que o PLE realmente é.
A definição de PLE é o tempo esperado, em segundos, que uma página de arquivo de dados lida no buffer pool (o cache na memória das páginas de arquivos de dados) permanecerá na memória antes de ser empurrada para fora da memória para dar espaço para dados diferentes página do arquivo. Outra maneira de pensar no PLE é uma medida instantânea da pressão no buffer pool para liberar espaço para as páginas que estão sendo lidas do disco. Para ambas as definições, um número maior é melhor.
O que é um bom limite de PLE?
Um PLE de 300 significa que todo o buffer pool está sendo efetivamente liberado e relido a cada cinco minutos. Quando a orientação de limite para PLE de 300 foi dada pela primeira vez pela Microsoft, por volta de 2005/2006, esse número pode ter feito mais sentido, pois a quantidade média de memória em um servidor era muito menor.
Hoje em dia, onde os servidores têm rotineiramente 64 GB, 128 GB e quantidades maiores de memória, ter aproximadamente essa quantidade de dados sendo lidos do disco a cada cinco minutos provavelmente seria a causa de um problema de desempenho incapacitante
Na realidade, quando o PLE estiver pairando em ou abaixo de 300, seu servidor já estará em apuros. Você começaria a se preocupar muito, muito antes de o PLE ser tão baixo.
Então, qual é o limite a ser usado quando você deve se preocupar?
Bem, esse é apenas o ponto. Não posso dar um limite, pois esse número varia para todos. Se você realmente quer um número para usar, meu colega Jonathan Kehayias criou uma fórmula:
(Memória do buffer pool em GB/4) x 300
Mesmo esse número é um tanto arbitrário, e sua milhagem vai variar.
Não gosto de recomendar nenhum número. Meu conselho é que você meça seu PLE quando o desempenho estiver no nível desejado – isso é o limite que você usa.
Então você começa a se preocupar assim que o PLE cai abaixo desse limite? Não. Você começa a se preocupar quando o PLE cai abaixo desse limite e permanece abaixo desse limite, ou se ele cai vertiginosamente e você não sabe por quê.
Isso ocorre porque existem algumas operações que causarão uma queda de PLE (por exemplo, executando
DBCC CHECKDB ou recompilações de índice podem fazer isso às vezes) e não são motivo de preocupação. Mas se você vir uma grande queda de PLE e não souber o que está causando isso, é aí que você deve se preocupar. Você pode estar se perguntando como
DBCC CHECKDB pode causar uma queda de PLE quando desfavorece e se esforça para evitar liberar o pool de buffers com os dados que ele usa (consulte esta postagem do blog para obter uma explicação). É porque a concessão de memória de execução de consulta para DBCC CHECKDB é calculado incorretamente pelo Query Optimizer e pode causar uma grande redução no tamanho do buffer pool (a memória para a concessão é roubada do buffer pool) e uma consequente queda no PLE. Como você monitora o PLE?
Esta é a parte complicada. A maioria das pessoas irá direto para o
Buffer Manager objeto de desempenho no PerfMon e monitorar a Page life expectancy contador. É este o caminho certo? Mais provável que não. Eu diria que a grande maioria dos servidores existentes hoje está usando a arquitetura NUMA, e isso tem um efeito profundo em como você monitora o PLE.
Quando o NUMA está envolvido, o pool de buffers é dividido em nós de buffer, com um nó de buffer por nó NUMA que o SQL Server pode ‘ver’. Cada nó de buffer rastreia o PLE separadamente e o
Buffer Manager:Page life expectancy counter é a média dos PLEs do nó de buffer. Se você estiver apenas monitorando o PLE geral do buffer pool, a pressão em um dos nós de buffer pode ser mascarada pela média (discuti isso em uma postagem no blog aqui). Portanto, se seu servidor estiver usando NUMA, você precisará monitorar o
Buffer Node:Page life expectancy individual contadores (haverá um objeto de desempenho Buffer Node para cada nó NUMA), caso contrário, é bom monitorar o Buffer Manager:Page life expectancy contador. Melhor ainda é usar uma ferramenta de monitoramento como o SQL Sentry Performance Advisor, que mostrará esse contador como parte do painel, levando em consideração os nós NUMA no servidor, e permitirá configurar alertas facilmente.
Exemplos de uso do Performance Advisor
Abaixo está uma parte de exemplo de uma captura de tela do Performance Advisor para um sistema com um único nó NUMA:
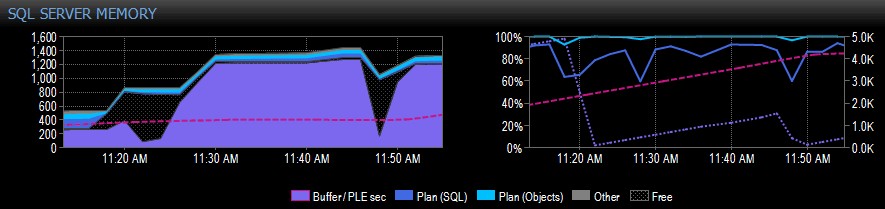
No lado direito da captura, a linha tracejada rosa é o PLE entre 10h30 e cerca de 11h20 – está subindo constantemente até 5.000 ou mais, um número realmente saudável. Pouco antes das 11h20, há uma queda enorme, e depois começa a subir novamente até as 11h45, onde cai novamente.
Isso normalmente é o que você veria se o pool de buffers estivesse cheio, com todas as páginas sendo usadas e, em seguida, uma consulta fosse executada, fazendo com que uma grande quantidade de dados diferentes fossem lidos do disco, deslocando muito do que já está na memória e causando um queda abrupta do PLE. Se você não sabia o que causou algo assim, você gostaria de investigar, como descrevo mais abaixo.
Como segundo exemplo, a captura de tela abaixo é de um de nossos clientes DBA remotos em que o servidor possui dois nós NUMA (você pode ver que há duas linhas PLE roxas) e onde usamos o Performance Advisor extensivamente:

No servidor desse cliente, todas as manhãs, por volta das 5h, é iniciado um trabalho de manutenção de índice e verificação de consistência que faz com que o PLE caia em ambos os nós de buffer. Este é o comportamento esperado, portanto, não há necessidade de investigar, desde que o PLE volte a subir durante o dia.
O que você pode fazer sobre o descarte de PLE?
Se a causa da queda do PLE não for conhecida, você pode fazer várias coisas:
- Se o problema estiver acontecendo agora, investigue quais consultas estão causando leituras usando o
sys.dm_os_waiting_tasksDMV para ver quais threads estão esperando que as páginas sejam lidas do disco (ou seja, aquelas que estão esperando porPAGEIOLATCH_SH) e, em seguida, corrija essas consultas. - Se o problema aconteceu no passado, procure na DMV sys.dm_exec_query_stats consultas com números altos de leituras físicas ou use uma ferramenta de monitoramento que possa fornecer essas informações (por exemplo, a visualização Top SQL no Performance Advisor) e em seguida, corrija essas consultas.
- Correlacione a queda do PLE com os trabalhos de agente agendados que realizam a manutenção do banco de dados.
- Procure consultas com concessões de memória de execução de consulta muito grandes usando o
sys.dm_exec_query_memory_grantsDMV e corrija essas consultas.
Meu post anterior aqui explica mais sobre #1 e #2, e um script para investigar esperas que ocorrem em um servidor e link para seus planos de consulta está aqui.
O "corrigir essas consultas" está além do escopo deste post, então vou deixar isso para outro momento ou como exercício para o leitor ☺
Resumo
Não caia na armadilha de acreditar em qualquer limite de PLE recomendado que você possa ler online. A melhor maneira de reagir às mudanças do PLE é quando o PLE cai abaixo de qualquer seu o nível de conforto é e permanece lá – isso é a indicação de um problema de desempenho que você deve investigar.
No próximo artigo da série, discutirei outra causa comum de ajuste de desempenho instintivo. Até então, feliz solução de problemas!