Houve muitos comentários após meu post na semana passada sobre divisão de strings. Acho que o ponto do artigo não era tão óbvio quanto poderia ter sido:gastar muito tempo e esforço tentando "aperfeiçoar" uma função de divisão inerentemente lenta baseada em T-SQL não seria benéfico. Desde então, coletei a versão mais recente da função de divisão de strings de Jeff Moden e a coloquei contra as outras:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO (As únicas alterações que fiz:formatei para exibição e removi os comentários. Você pode recuperar a fonte original aqui.)
Eu tive que fazer alguns ajustes em meus testes para representar de maneira justa a função de Jeff. Mais importante:tive que descartar todas as amostras que envolviam strings> 4.000 caracteres. Então, alterei as strings de 5.000 caracteres na tabela dbo.strings para 4.000 caracteres e foquei apenas nos três primeiros cenários não MAX (mantendo os resultados anteriores para os dois primeiros e executando os terceiros testes novamente para o novo comprimentos de cadeia de 4.000 caracteres). Eu também eliminei a tabela de números de todos os testes, exceto um, porque ficou claro que o desempenho sempre foi pior por um fator de pelo menos 10. O gráfico a seguir mostra o desempenho das funções em cada um dos quatro testes, novamente média de mais de 10 execuções e sempre com um cache frio e buffers limpos.
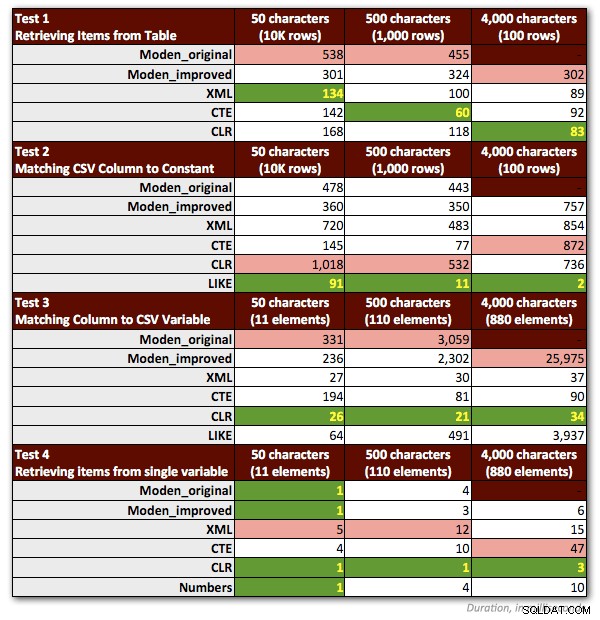
Então, aqui estão meus métodos preferidos ligeiramente revisados, para cada tipo de tarefa:
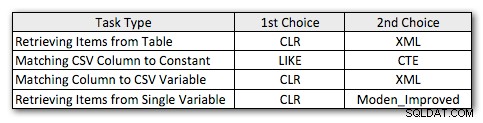
Você notará que o CLR permaneceu meu método de escolha, exceto no caso em que a divisão não faz sentido. E nos casos em que CLR não é uma opção, os métodos XML e CTE são geralmente mais eficientes, exceto no caso de divisão de variável única, onde a função de Jeff pode muito bem ser a melhor opção. Mas, considerando que talvez eu precise dar suporte a mais de 4.000 caracteres, a solução da tabela Numbers pode voltar à minha lista em situações específicas em que não tenho permissão para usar o CLR.
Prometo que meu próximo post envolvendo listas não falará sobre divisão, via T-SQL ou CLR, e demonstrará como simplificar esse problema independentemente do tipo de dados.
Como aparte, notei este comentário em uma das versões das funções de Jeff que foi postado nos comentários:Agradeço também a quem escreveu o primeiro artigo que vi sobre “tabelas de números” que está localizado no seguinte URL e a Adam Machanic por me levar a isso há muitos anos.
https://web.archive.org/web/20150411042510/https://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an -auxiliary-numbers-table.html
Esse artigo foi escrito por mim em 2004. Então, quem adicionou o comentário à função, seja bem-vindo. :-)



