Um cenário comum em muitos aplicativos cliente-servidor é permitir que o usuário final dite a ordem de classificação dos resultados. Algumas pessoas querem ver os itens com preços mais baixos primeiro, algumas querem ver os itens mais recentes primeiro e algumas querem vê-los em ordem alfabética. Isso é uma coisa complexa de se conseguir no Transact-SQL porque você não pode simplesmente dizer:
CREATE PROCEDURE dbo.SortOnSomeTable @SortColumn NVARCHAR(128) = N'key_col', @SortDirection VARCHAR(4) = 'ASC' AS BEGIN ... ORDER BY @SortColumn; -- or ... ORDER BY @SortColumn @SortDirection; END GO
Isso ocorre porque o T-SQL não permite variáveis nesses locais. Se você usar apenas @SortColumn, receberá:
Msg 1008, Level 16, State 1, Line x
O item SELECT identificado pelo ORDER BY número 1 contém uma variável como parte da expressão que identifica uma posição de coluna. As variáveis só são permitidas ao ordenar por uma expressão que faça referência a um nome de coluna.
(E quando a mensagem de erro diz "uma expressão referenciando um nome de coluna", você pode achar ambígua, e eu concordo. Mas posso garantir que isso não significa que uma variável seja uma expressão adequada.)
Se você tentar anexar @SortDirection, a mensagem de erro será um pouco mais opaca:
Msg 102, Level 15, State 1, Line x
Sintaxe incorreta perto de '@SortDirection'.
Existem algumas maneiras de contornar isso, e seu primeiro instinto pode ser usar SQL dinâmico ou introduzir a expressão CASE. Mas, como acontece com a maioria das coisas, existem complicações que podem forçá-lo a seguir um caminho ou outro. Então, qual você deve usar? Vamos explorar como essas soluções podem funcionar e comparar os impactos no desempenho de algumas abordagens diferentes.
Dados de amostra
Usando uma exibição de catálogo que todos nós provavelmente entendemos muito bem, sys.all_objects, criei a tabela a seguir com base em uma junção cruzada, limitando a tabela a 100.000 linhas (eu queria dados que preenchiam muitas páginas, mas que não demoravam muito para consultar e teste):
CREATE DATABASE OrderBy;
GO
USE OrderBy;
GO
SELECT TOP (100000)
key_col = ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- a BIGINT with clustered index
s1.[object_id], -- an INT without an index
name = s1.name -- an NVARCHAR with a supporting index
COLLATE SQL_Latin1_General_CP1_CI_AS,
type_desc = s1.type_desc -- an NVARCHAR(60) without an index
COLLATE SQL_Latin1_General_CP1_CI_AS,
s1.modify_date -- a datetime without an index
INTO dbo.sys_objects
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]; (O truque COLLATE é porque muitas exibições de catálogo têm colunas diferentes com agrupamentos diferentes, e isso garante que as duas colunas correspondam para os propósitos desta demonstração.)
Em seguida, criei um par de índice clusterizado/não clusterizado típico que pode existir em tal tabela, antes da otimização (não posso usar object_id para a chave, porque a junção cruzada cria duplicatas):
CREATE UNIQUE CLUSTERED INDEX key_col ON dbo.sys_objects(key_col); CREATE INDEX name ON dbo.sys_objects(name);
Casos de uso
Como mencionado acima, os usuários podem querer ver esses dados ordenados de várias maneiras, então vamos definir alguns casos de uso típicos que queremos oferecer suporte (e por suporte, quero dizer, demonstrar):
- Ordenado por key_col crescente ** padrão se o usuário não se importar
- Ordenado por object_id (ascendente/descendente)
- Ordenado por nome (crescente/decrescente)
- Ordenado por type_desc (ascendente/descendente)
- Ordenado por modify_date (ascendente/descendente)
Vamos deixar a ordenação key_col como padrão porque ela deve ser a mais eficiente se o usuário não tiver preferência; como o key_col é um substituto arbitrário que não deve significar nada para o usuário (e pode nem ser exposto a eles), não há motivo para permitir a classificação reversa nessa coluna.
Abordagens que não funcionam
A abordagem mais comum que vejo quando alguém começa a resolver esse problema é introduzir a lógica de controle de fluxo na consulta. Eles esperam ser capazes de fazer isso:
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
IF @SortColumn = 'key_col'
key_col
IF @SortColumn = 'object_id'
[object_id]
IF @SortColumn = 'name'
name
...
IF @SortDirection = 'ASC'
ASC
ELSE
DESC; Isso obviamente não funciona. Em seguida, vejo CASE sendo introduzido incorretamente, usando sintaxe semelhante:
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
WHEN 'name' THEN name
...
END CASE @SortDirection WHEN 'ASC' THEN ASC ELSE DESC END; Isso está mais próximo, mas falha por dois motivos. Uma é que CASE é uma expressão que retorna exatamente um valor de um tipo de dado específico; isso mescla tipos de dados que são incompatíveis e, portanto, interromperá a expressão CASE. A outra é que não há como aplicar condicionalmente a direção de classificação dessa maneira sem usar SQL dinâmico.
Abordagens que funcionam
As três abordagens principais que eu vi são as seguintes:
Agrupe tipos e direções compatíveis
Para usar CASE com ORDER BY, deve haver uma expressão distinta para cada combinação de tipos e direções compatíveis. Nesse caso teríamos que usar algo assim:
CREATE PROCEDURE dbo.Sort_CaseExpanded
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END DESC,
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END DESC,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'ASC' THEN modify_date
END,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'DESC' THEN modify_date
END DESC;
END Você pode dizer, uau, isso é um código feio, e eu concordaria com você. Acho que é por isso que muitas pessoas armazenam seus dados no front-end e deixam a camada de apresentação lidar com os malabarismos em ordens diferentes. :-)
Você pode reduzir um pouco mais essa lógica convertendo todos os tipos não string em strings que serão classificadas corretamente, por exemplo,
CREATE PROCEDURE dbo.Sort_CaseCollapsed
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END DESC;
END Ainda assim, é uma bagunça muito feia, e você precisa repetir as expressões duas vezes para lidar com as diferentes direções de classificação. Eu também suspeitaria que usar OPTION RECOMPILE nessa consulta impediria que você fosse picado por sniffing de parâmetro. Exceto no caso padrão, não é como se a maioria do trabalho feito aqui fosse de compilação.
Aplicar uma classificação usando funções de janela
Eu descobri esse truque legal do AndriyM, embora seja mais útil nos casos em que todas as colunas de ordenação em potencial são de tipos compatíveis, caso contrário, a expressão usada para ROW_NUMBER() é igualmente complexa. A parte mais inteligente é que para alternar entre ordem crescente e decrescente, simplesmente multiplicamos ROW_NUMBER() por 1 ou -1. Podemos aplicá-lo nesta situação da seguinte forma:
CREATE PROCEDURE dbo.Sort_RowNumber
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
;WITH x AS
(
SELECT key_col, [object_id], name, type_desc, modify_date,
rn = ROW_NUMBER() OVER (
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END
FROM dbo.sys_objects
)
SELECT key_col, [object_id], name, type_desc, modify_date
FROM x
ORDER BY rn;
END
GO Novamente, OPTION RECOMPILE pode ajudar aqui. Além disso, você pode notar em alguns desses casos que os empates são tratados de maneira diferente pelos vários planos - ao ordenar por nome, por exemplo, você geralmente verá key_col aparecer em ordem crescente em cada conjunto de nomes duplicados, mas também poderá ver os valores misturados. Para fornecer um comportamento mais previsível em caso de empates, você sempre pode adicionar uma cláusula ORDER BY adicional. Observe que se você adicionar key_col ao primeiro exemplo, precisará torná-lo uma expressão para que key_col não seja listado em ORDER BY duas vezes (você pode fazer isso usando key_col + 0, por exemplo).
SQL Dinâmico
Muitas pessoas têm reservas sobre o SQL dinâmico - é impossível de ler, é um terreno fértil para injeção de SQL, leva a planejar o inchaço do cache, anula o propósito de usar procedimentos armazenados ... Alguns deles são simplesmente falsos, e alguns deles são fáceis de mitigar. Eu adicionei alguma validação aqui que poderia ser facilmente adicionada a qualquer um dos procedimentos acima:
CREATE PROCEDURE dbo.Sort_DynamicSQL
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
-- reject any invalid sort directions:
IF UPPER(@SortDirection) NOT IN ('ASC','DESC')
BEGIN
RAISERROR('Invalid parameter for @SortDirection: %s', 11, 1, @SortDirection);
RETURN -1;
END
-- reject any unexpected column names:
IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date')
BEGIN
RAISERROR('Invalid parameter for @SortColumn: %s', 11, 1, @SortColumn);
RETURN -1;
END
SET @SortColumn = QUOTENAME(@SortColumn);
DECLARE @sql NVARCHAR(MAX);
SET @sql = N'SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';';
EXEC sp_executesql @sql;
END Comparações de desempenho
Eu criei um procedimento armazenado de wrapper para cada procedimento acima, para que eu pudesse testar facilmente todos os cenários. Os quatro procedimentos do wrapper se parecem com isso, com o nome do procedimento variando, é claro:
CREATE PROCEDURE dbo.Test_Sort_CaseExpanded AS BEGIN SET NOCOUNT ON; EXEC dbo.Sort_CaseExpanded; -- default EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC'; END
E então, usando o SQL Sentry Plan Explorer, gerei planos de execução reais (e as métricas para acompanhá-lo) com as seguintes consultas e repeti o processo 10 vezes para somar a duração total:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; EXEC dbo.Test_Sort_CaseExpanded; --EXEC dbo.Test_Sort_CaseCollapsed; --EXEC dbo.Test_Sort_RowNumber; --EXEC dbo.Test_Sort_DynamicSQL; GO 10
Também testei os três primeiros casos com OPTION RECOMPILE (não faz muito sentido para o caso SQL dinâmico, pois sabemos que será um novo plano a cada vez), e todos os quatro casos com MAXDOP 1 para eliminar a interferência de paralelismo. Aqui estão os resultados:
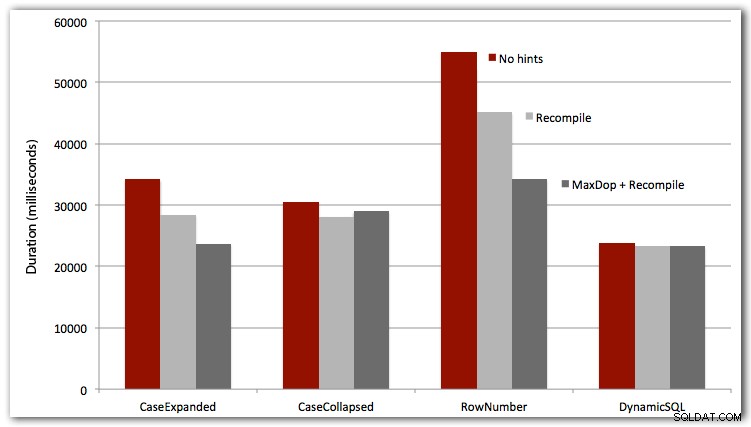
Conclusão
Para desempenho total, o SQL dinâmico sempre vence (embora apenas por uma pequena margem neste conjunto de dados). A abordagem ROW_NUMBER(), embora inteligente, foi a perdedora em cada teste (desculpe AndriyM).
Fica ainda mais divertido quando você quer introduzir uma cláusula WHERE, não importa a paginação. Esses três são como a tempestade perfeita para introduzir complexidade ao que começa como uma simples consulta de pesquisa. Quanto mais permutações sua consulta tiver, maior a probabilidade de você querer descartar a legibilidade e usar SQL dinâmico em combinação com a configuração "otimizar para cargas de trabalho ad hoc" para minimizar o impacto dos planos de uso único no cache do plano.



