A qualidade de um plano de execução é altamente dependente da precisão do número estimado de linhas de saída de cada operador do plano. Se o número estimado de linhas for significativamente desviado do número real de linhas, isso poderá ter um impacto significativo na qualidade do plano de execução de uma consulta. A má qualidade do plano pode ser responsável por E/S excessiva, CPU inflada, pressão de memória, taxa de transferência reduzida e simultaneidade geral reduzida.
Por "qualidade do plano" – estou falando sobre fazer com que o SQL Server gere um plano de execução que resulte em escolhas de operador físico que reflitam o estado atual dos dados. Ao tomar essas decisões com base em dados precisos, há uma chance maior de que a consulta seja executada corretamente. Os valores da estimativa de cardinalidade são utilizados como entrada para o custeio da operadora, e quando os valores estão muito distantes da realidade, o impacto negativo no plano de execução pode ser acentuado. Essas estimativas são alimentadas aos vários modelos de custo associados à própria consulta, e estimativas de linha incorretas podem afetar uma variedade de decisões, incluindo seleção de índice, operações de busca versus varredura, execução paralela versus serial, seleção de algoritmo de junção, junção física interna versus externa seleção (por exemplo, build vs. probe), geração de spool, pesquisas de bookmark vs. acesso completo a cluster ou heap table, seleção de fluxo ou agregado de hash e se uma modificação de dados usa ou não um plano amplo ou estreito.
Como exemplo, digamos que você tenha o seguinte
SELECT consulta (usando o banco de dados Credit):SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
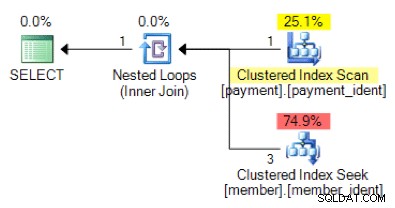
Com base na lógica de consulta, a forma de plano a seguir é o que você esperaria ver?
E esse plano alternativo, onde em vez de um loop aninhado temos uma correspondência de hash?
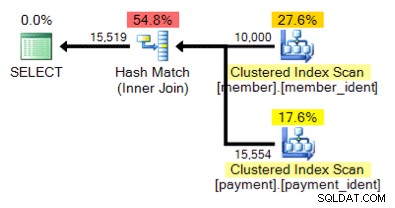
A resposta "correta" depende de alguns outros fatores - mas um fator importante é o número de linhas em cada uma das tabelas. Em alguns casos, um algoritmo de junção física é mais apropriado que o outro – e se as suposições de estimativa de cardinalidade inicial não estiverem corretas, sua consulta pode estar usando uma abordagem não ideal.
Identificando questões de estimativa de cardinalidade é relativamente simples. Se você tiver um plano de execução real, poderá comparar os valores de contagem de linhas estimados versus reais para operadores e procurar desvios. O SQL Sentry Plan Explorer simplifica essa tarefa, permitindo que você veja linhas reais versus linhas estimadas para todos os operadores em uma única guia da árvore do plano, em vez de passar o mouse sobre os operadores individuais no plano gráfico:

Agora, distorções nem sempre resultam em planos de baixa qualidade, mas se você estiver tendo problemas de desempenho com uma consulta e vir tais distorções no plano, essa é uma área que merece uma investigação mais aprofundada.
A identificação de problemas de estimativa de cardinalidade é relativamente simples, mas a resolução geralmente não é. Há uma série de causas básicas para a ocorrência de problemas de estimativa de cardinalidade, e abordarei dez dos motivos mais comuns neste post.
Estatísticas ausentes ou obsoletas
De todos os motivos para problemas de estimativa de cardinalidade, este é o que você espera para ver, como muitas vezes é mais fácil de abordar. Nesse cenário, suas estatísticas estão ausentes ou desatualizadas. Você pode ter opções de banco de dados para criação e atualizações automáticas de estatísticas desabilitadas, "não recalculado" habilitado para estatísticas específicas, ou ter tabelas grandes o suficiente para que suas atualizações automáticas de estatísticas simplesmente não aconteçam com a frequência necessária.
Problemas de amostragem
Pode ser que a precisão do histograma estatístico seja inadequada – por exemplo, se você tiver uma tabela muito grande com desvios de dados significativos e/ou frequentes. Você pode precisar alterar sua amostragem do padrão ou, se mesmo isso não ajudar – investigue usando tabelas separadas, estatísticas filtradas ou índices filtrados.
Correlações de colunas ocultas
O otimizador de consulta assume que as colunas na mesma tabela são independentes. Por exemplo, se você tiver uma coluna de cidade e estado, podemos intuitivamente saber que essas duas colunas estão correlacionadas, mas o SQL Server não entende isso, a menos que ajudemos com um índice de várias colunas associado ou com várias colunas criadas manualmente. estatísticas da coluna. Sem ajudar o otimizador com a correlação, a seletividade de seus predicados pode ser exagerada.
Abaixo está um exemplo de dois predicados correlacionados:
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
Acontece que eu sei que 10% do nosso
member de 10.000 linhas table se qualifica para essa combinação, mas o otimizador de consulta está supondo que é 1% das 10.000 linhas: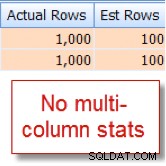
Agora compare isso com a estimativa apropriada que vejo depois de adicionar estatísticas de várias colunas:
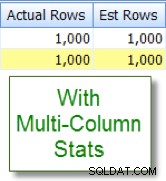
Comparações de colunas intra-tabelas
Problemas de estimativa de cardinalidade podem ocorrer ao comparar colunas na mesma tabela. Este é um problema conhecido. Se você precisar fazer isso, poderá melhorar as estimativas de cardinalidade das comparações de coluna usando colunas computadas ou reescrevendo a consulta para usar autojunções ou expressões de tabela comuns.
Uso da variável da tabela
Usando muito variáveis de tabela? As variáveis de tabela mostram uma estimativa de cardinalidade de "1" – o que para apenas um pequeno número de linhas pode não ser um problema, mas para conjuntos de resultados grandes ou voláteis podem afetar significativamente a qualidade do plano de consulta. Abaixo está uma captura de tela da estimativa de um operador de 1 linha versus as 1.600.000 linhas reais do
@charge variável da tabela:
Se esta for sua causa raiz, você deve explorar alternativas como tabelas temporárias e/ou tabelas temporárias permanentes sempre que possível.
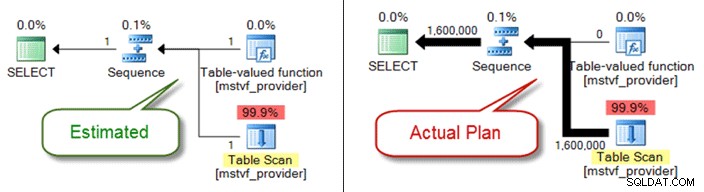
UDFs escalares e MSTV
Semelhante às variáveis de tabela, funções escalares e com valor de tabela de várias instruções são uma caixa preta de uma perspectiva de estimativa de cardinalidade. Se você estiver encontrando problemas de qualidade do plano devido a eles, considere as funções de tabela inline como uma alternativa – ou até mesmo retirando a referência de função inteiramente e apenas referenciando objetos diretamente.
Abaixo mostra um plano estimado versus real ao usar uma função com valor de tabela de várias instruções:
Problemas de tipo de dados
Problemas de tipo de dados implícitos em conjunto com condições de pesquisa e junção podem causar problemas de estimativa de cardinalidade. Eles também podem sub-repticiamente consumir recursos no nível do servidor (CPU, E/S, memória), por isso é importante abordá-los sempre que possível.
Predicados complexos
Você provavelmente já viu esse padrão antes - uma consulta com um
WHERE cláusula que tem cada referência de coluna de tabela envolta em várias funções, operações de concatenação, operações matemáticas e muito mais. E embora nem todos os agrupamentos de funções impeçam estimativas de cardinalidade adequadas (como para LOWER , UPPER e GETDATE ), existem várias maneiras de enterrar seu predicado a ponto de o otimizador de consulta não conseguir mais fazer estimativas precisas. Complexidade da consulta
Semelhante aos predicados enterrados, suas consultas são extraordinariamente complexas? Eu percebo que “complexo” é um termo subjetivo, e sua avaliação pode variar, mas a maioria pode concordar que aninhar visualizações dentro de visualizações dentro de visualizações que fazem referência a tabelas sobrepostas provavelmente não é o ideal – especialmente quando combinado com mais de 10 junções de tabela, referências de função e predicados enterrados. Embora o otimizador de consulta faça um trabalho admirável, não é mágico e, se você tiver distorções significativas, a complexidade da consulta (consultas de canivete suíço) certamente pode tornar quase impossível derivar estimativas de linha precisas para os operadores.
Consultas distribuídas
Você está usando consultas distribuídas com servidores vinculados e vê problemas significativos de estimativa de cardinalidade? Em caso afirmativo, verifique as permissões associadas ao principal do servidor vinculado que está sendo usado para acessar os dados. Sem o mínimo
db_ddladmin função de banco de dados fixa para a conta de servidor vinculada, essa falta de visibilidade para estatísticas remotas devido a permissões insuficientes pode ser a origem de seus problemas de estimativa de cardinalidade. E há outros…
Existem outras razões pelas quais as estimativas de cardinalidade podem ser distorcidas, mas acredito que abordei as mais comuns. O ponto-chave é prestar atenção às distorções associadas a consultas conhecidas e com desempenho insatisfatório. Não presuma que o plano foi gerado com base em condições precisas de contagem de linhas. Se esses números estiverem distorcidos, você precisa tentar solucionar isso primeiro.



