Longe vão os dias em que um banco de dados era implantado como um único nó ou instância - um servidor poderoso e autônomo que tinha a tarefa de lidar com todas as solicitações ao banco de dados. O dimensionamento vertical era o caminho a seguir - substitua o servidor por outro ainda mais poderoso. Durante esses tempos, não era preciso se incomodar com o desempenho da rede. Enquanto os pedidos estavam chegando, tudo estava bem.
Mas hoje em dia, os bancos de dados são construídos como clusters com nós interconectados em uma rede. Nem sempre é uma rede local rápida. Com as empresas alcançando escala global, a infraestrutura de banco de dados também precisa abranger todo o mundo, para ficar perto dos clientes e reduzir a latência. Ele vem com desafios adicionais que temos que enfrentar ao projetar um ambiente de banco de dados altamente disponível. Nesta postagem do blog, analisaremos os problemas de rede que você pode enfrentar e forneceremos algumas sugestões sobre como lidar com eles.
Duas opções principais para MySQL ou MariaDB HA
Cobrimos esse tópico específico bastante extensivamente em um dos whitepapers, mas vamos analisar as duas principais maneiras de criar alta disponibilidade para MySQL e MariaDB.
Conjunto Galera
Galera Cluster é uma tecnologia de cluster virtualmente síncrona e sem compartilhamento para MySQL. Ele permite criar configurações de vários gravadores que podem abranger todo o mundo. O Galera prospera em ambientes de baixa latência, mas também pode ser configurado para funcionar com conexões WAN longas. O Galera possui um mecanismo de quorum integrado que garante que os dados não sejam comprometidos em caso de particionamento de rede de alguns dos nós.
Replicação MySQL
A replicação do MySQL pode ser assíncrona ou semi-síncrona. Ambos são projetados para criar clusters de replicação em grande escala. Como em qualquer outra configuração de replicação mestre-escravo ou primário-secundário, pode haver apenas um gravador, o mestre. Outros nós, escravos, são usados para fins de failover, pois contêm a cópia do conjunto de dados do maser. Os escravos também podem ser usados para ler os dados e descarregar parte da carga de trabalho do mestre.
Ambas as soluções têm seus próprios limites e recursos, ambas sofrem de problemas diferentes. Ambos podem ser afetados por conexões de rede instáveis. Vamos dar uma olhada nessas limitações e como podemos projetar o ambiente para minimizar o impacto de uma infraestrutura de rede instável.
Galera Cluster - Problemas de rede
Primeiro, vamos dar uma olhada no Galera Cluster. Conforme discutimos, ele funciona melhor em um ambiente de baixa latência. Um dos principais problemas relacionados à latência no Galera é a maneira como o Galera lida com as gravações. Não entraremos em todos os detalhes neste blog, mas leremos mais em nosso tutorial Galera Cluster for MySQL. A conclusão é que, devido ao processo de certificação para gravações, em que todos os nós no cluster precisam concordar se a gravação pode ser aplicada ou não, seu desempenho de gravação para uma única linha é estritamente limitado pelo tempo de ida e volta da rede entre o gravador nó e o nó mais distante. Contanto que a latência seja aceitável e que você não tenha muitos pontos de acesso em seus dados, as configurações de WAN podem funcionar bem. O problema começa quando a latência da rede aumenta de tempos em tempos. As gravações demoram 3 ou 4 vezes mais do que o normal e, como resultado, os bancos de dados podem começar a ficar sobrecarregados com gravações de longa duração.
Um dos grandes recursos do Galera Cluster é sua capacidade de detectar o estado do cluster e reagir ao particionamento da rede. Se um nó do cluster não puder ser alcançado, ele será despejado do cluster e não poderá realizar nenhuma gravação. Isso é crucial para manter a integridade dos dados durante o tempo em que o cluster é dividido - somente a maioria do cluster aceitará gravações. A minoria vai reclamar. Para lidar com isso, o Galera apresenta uma vasta gama de verificações e tempos limite configuráveis para evitar alertas falsos em problemas de rede muito transitórios. Infelizmente, se a rede não for confiável, o Galera Cluster não poderá funcionar corretamente - os nós começarão a sair do cluster, ingressar nele mais tarde. Será especialmente problemático quando tivermos o Galera Cluster abrangendo a WAN - partes separadas do cluster podem desaparecer aleatoriamente se a rede de interconexão não funcionar corretamente.
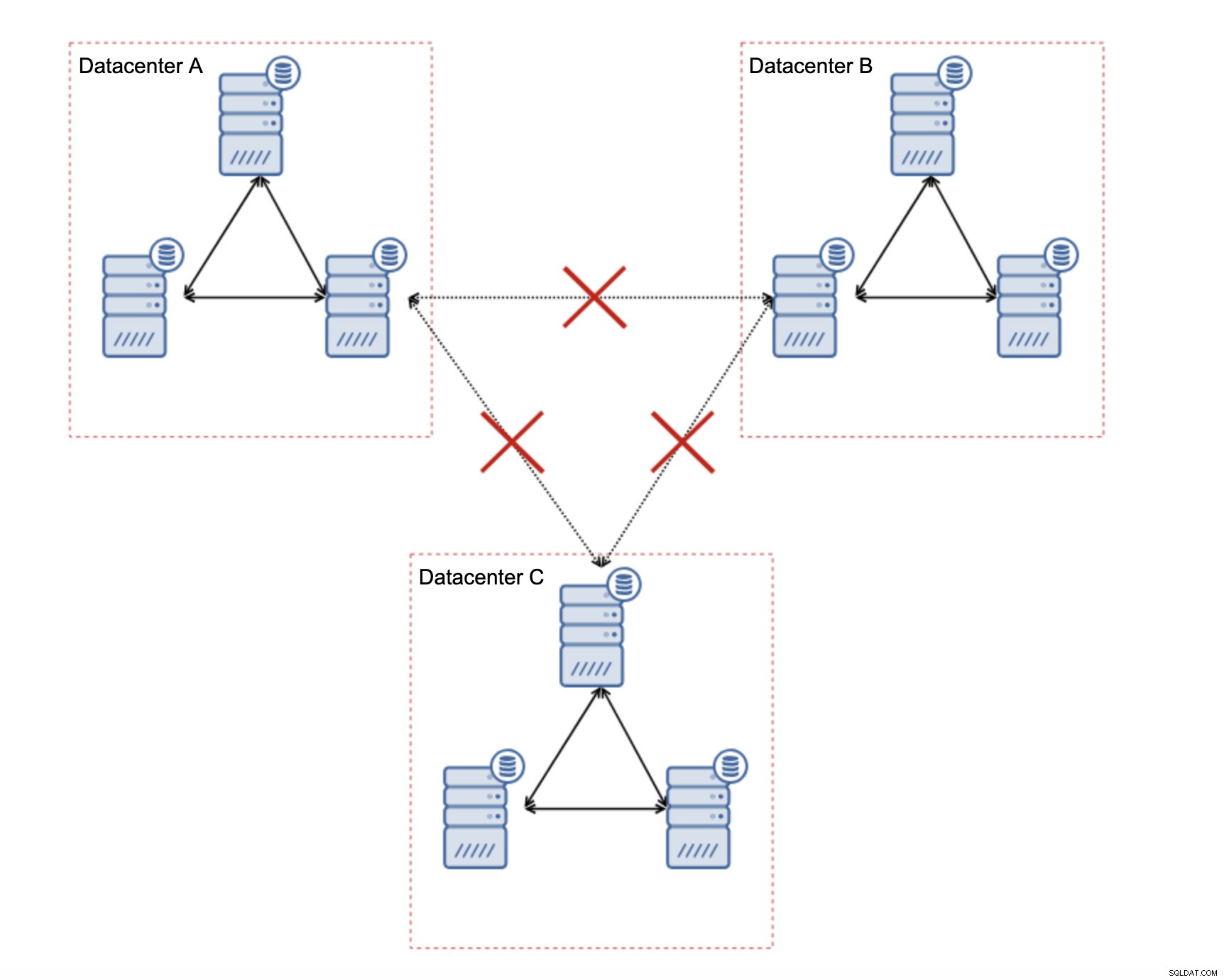
Como projetar o Galera Cluster para uma rede instável?
Em primeiro lugar, se você tiver problemas de rede em um único datacenter, não há muito o que fazer, a menos que consiga resolver esses problemas de alguma forma. Rede local não confiável não é uma boa opção para o Galera Cluster, você deve reconsiderar o uso de outra solução (mesmo que, para ser honesto, uma rede não confiável sempre será um problema). Por outro lado, se os problemas estão relacionados apenas a conexões WAN (e este é um dos casos mais típicos), pode ser possível substituir os links WAN Galera por replicação assíncrona regular (se o ajuste Galera WAN não ajudar).
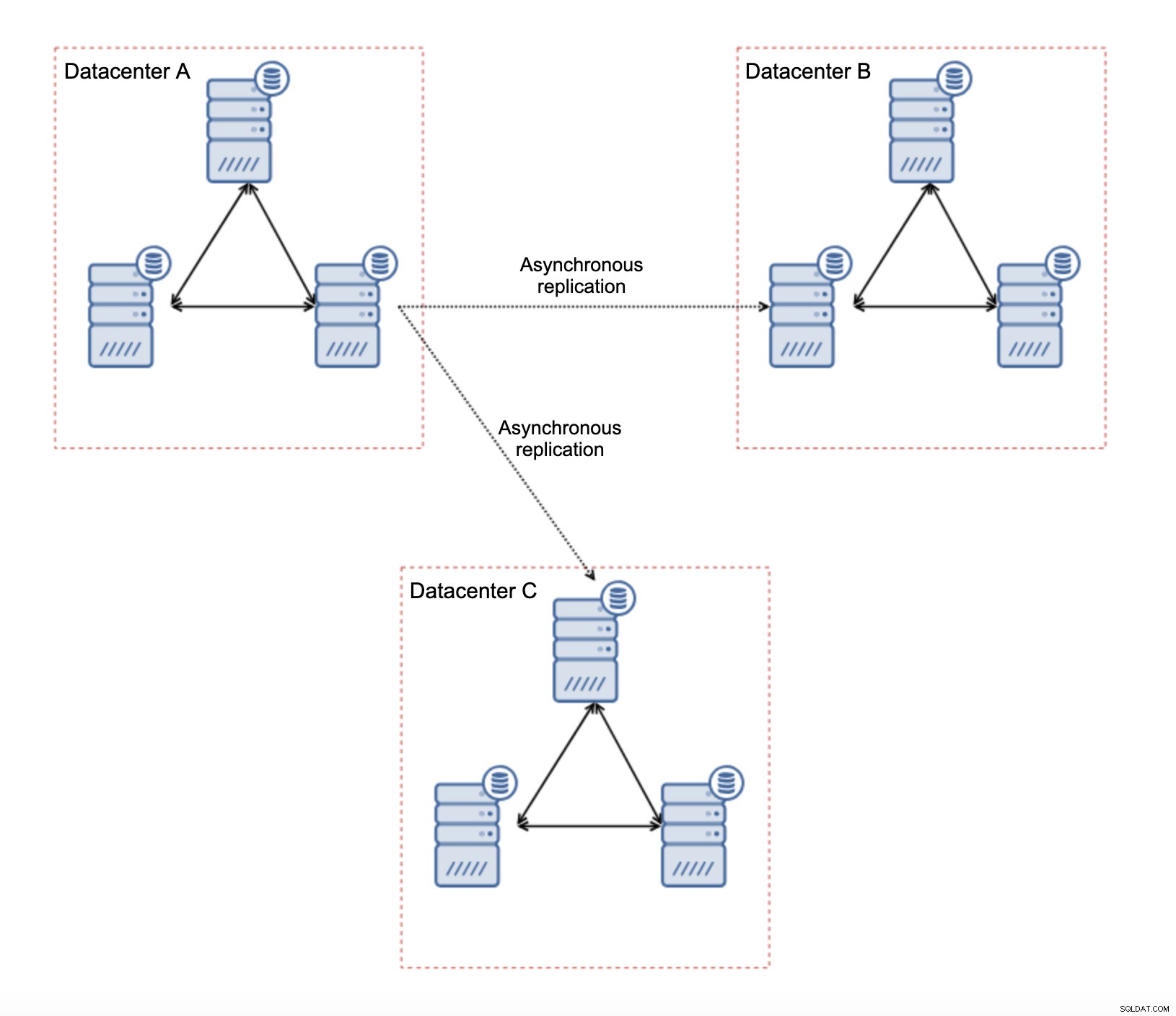
Existem várias limitações inerentes a essa configuração - o principal problema é que as gravações costumavam acontecer localmente. Agora, todas as gravações terão que ir para o datacenter “mestre” (DC A no nosso caso). Isso não é tão ruim quanto parece. Lembre-se de que, em um ambiente totalmente Galera, as gravações serão retardadas pela latência entre nós localizados em datacenters diferentes. Até mesmo gravações locais serão afetadas. Será mais ou menos a mesma lentidão da configuração assíncrona na qual você enviaria as gravações pela WAN para o datacenter “mestre”.
O uso da replicação assíncrona traz todos os problemas típicos da replicação assíncrona. O atraso na replicação pode se tornar um problema - não que o Galera tenha mais desempenho, é apenas que o Galera diminuiria o tráfego por meio do controle de fluxo, enquanto a replicação não possui nenhum mecanismo para limitar o tráfego no mestre.
Outro problema é o failover:se o nó “mestre” do Galera (aquele que atua como mestre para os escravos em outros datacenters) falhar, algum mecanismo deve ser criado para redirecionar os escravos para outro nó mestre em funcionamento. Pode ser algum tipo de script, também é possível tentar algo com VIP onde o cluster Galera “escravo” escraviza o IP Virtual que é sempre atribuído ao nó Galera vivo no cluster “mestre”.
A principal vantagem de tal configuração é que removemos o link WAN Galera, o que significa que nosso cluster “mestre” não será desacelerado pelo fato de alguns dos nós estarem separados geograficamente. Como mencionamos, perdemos a capacidade de gravar em todos os data centers, mas a gravação com base na latência na WAN é o mesmo que gravar localmente no cluster Galera, que abrange a WAN. Como resultado, a latência geral deve melhorar. A replicação assíncrona também é menos vulnerável às redes instáveis. Na pior das hipóteses, o link de replicação será interrompido e será recriado quando as redes convergirem.
Como projetar a replicação do MySQL para uma rede instável?
Na seção anterior, abordamos o cluster Galera e uma solução foi usar a replicação assíncrona. Como se parece em uma configuração de replicação assíncrona simples? Vejamos como uma rede instável pode causar as maiores interrupções na configuração da replicação.
Em primeiro lugar, a latência - um dos principais pontos problemáticos do Galera Cluster. Em caso de replicação, é quase um problema. A menos que você use a replicação semi-síncrona - nesse caso, o aumento da latência diminuirá a velocidade das gravações. Na replicação assíncrona, a latência não afeta o desempenho de gravação. Pode, no entanto, ter algum impacto no atraso de replicação. Não é nada tão significativo quanto foi para o Galera, mas você pode esperar mais picos de atraso e desempenho de replicação geral menos estável se a rede entre os nós sofrer de alta latência. Isso se deve principalmente ao fato de que o mestre também pode servir várias gravações antes que a transferência de dados para o escravo possa ser iniciada em uma rede de alta latência.
A instabilidade da rede pode definitivamente afetar os links de replicação, mas, novamente, não é tão crítica. Os escravos MySQL tentarão se reconectar aos seus mestres e a replicação começará.
O principal problema com a replicação do MySQL é, na verdade, algo que o Galera Cluster resolve internamente - particionamento de rede. Estamos falando do particionamento de rede como a condição na qual os segmentos da rede são separados uns dos outros. A replicação do MySQL utiliza um único nó de gravação - mestre. Não importa como você projeta seu ambiente, você precisa enviar suas gravações para o mestre. Se o mestre não estiver disponível (por qualquer motivo), o aplicativo não poderá fazer seu trabalho a menos que seja executado em algum tipo de modo somente leitura. Portanto, é necessário escolher o novo mestre o mais rápido possível. É aqui que os problemas aparecem.
Primeiro, como saber qual host é mestre e qual não é. Uma das formas usuais é usar a variável “read_only” para distinguir escravos do mestre. Se o nó tiver read_only habilitado (definir read_only=1), ele é um escravo (já que os escravos não devem lidar com nenhuma gravação direta). Se o nó tiver read_only desabilitado (set read_only=0), ele é um mestre. Para tornar as coisas mais seguras, uma abordagem comum é definir read_only=1 na configuração do MySQL - no caso de uma reinicialização, é mais seguro se o nó aparecer como escravo. Tal “linguagem” pode ser entendida por proxies como ProxySQL ou MaxScale.
Vejamos um exemplo.
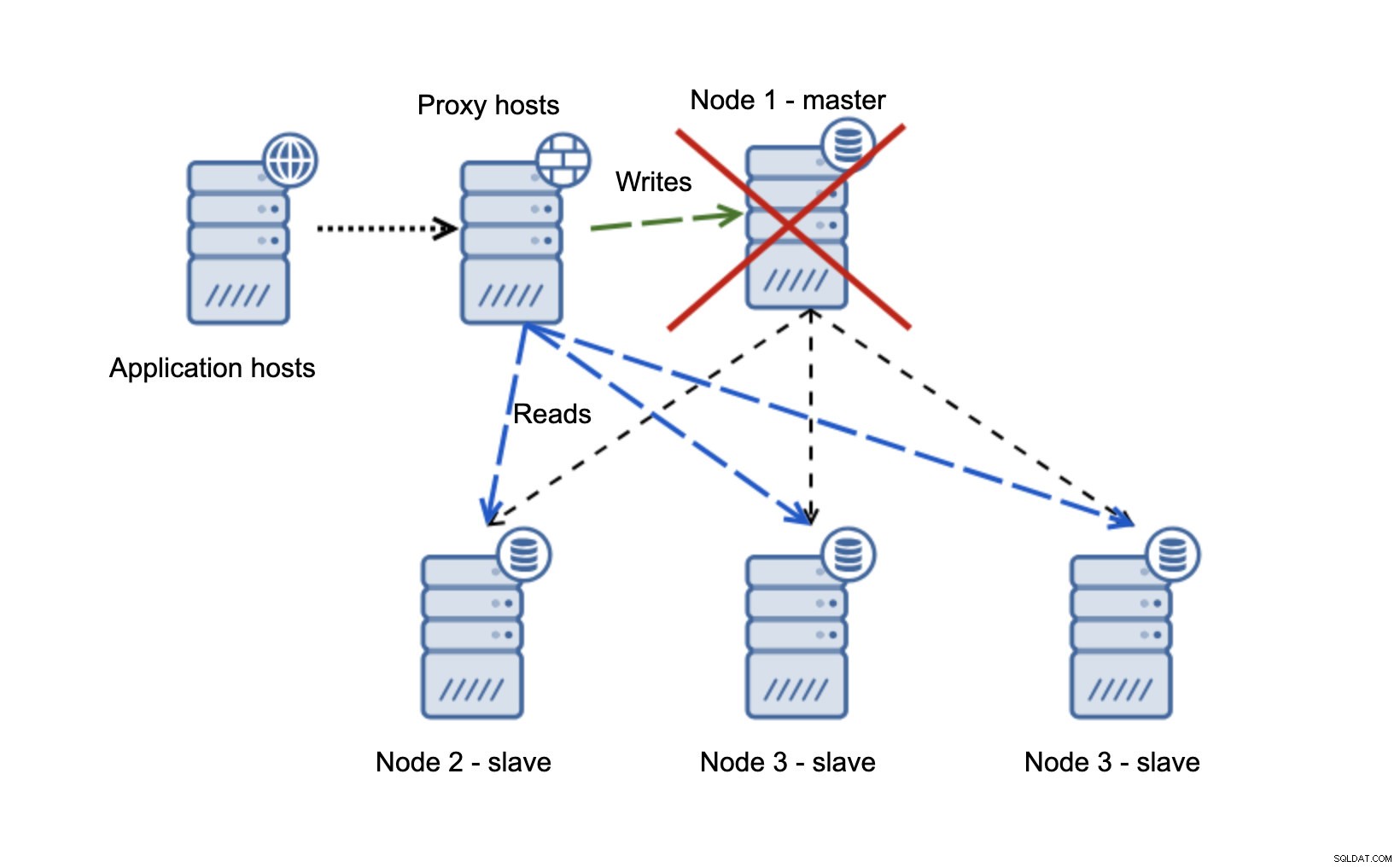
Temos hosts de aplicativos que se conectam à camada proxy. Os proxies realizam a divisão de leitura/gravação enviando SELECTs para escravos e grava para mestre. Se o mestre estiver inativo, o failover é executado, um novo mestre é promovido, a camada proxy detecta isso e começa a enviar gravações para outro nó.
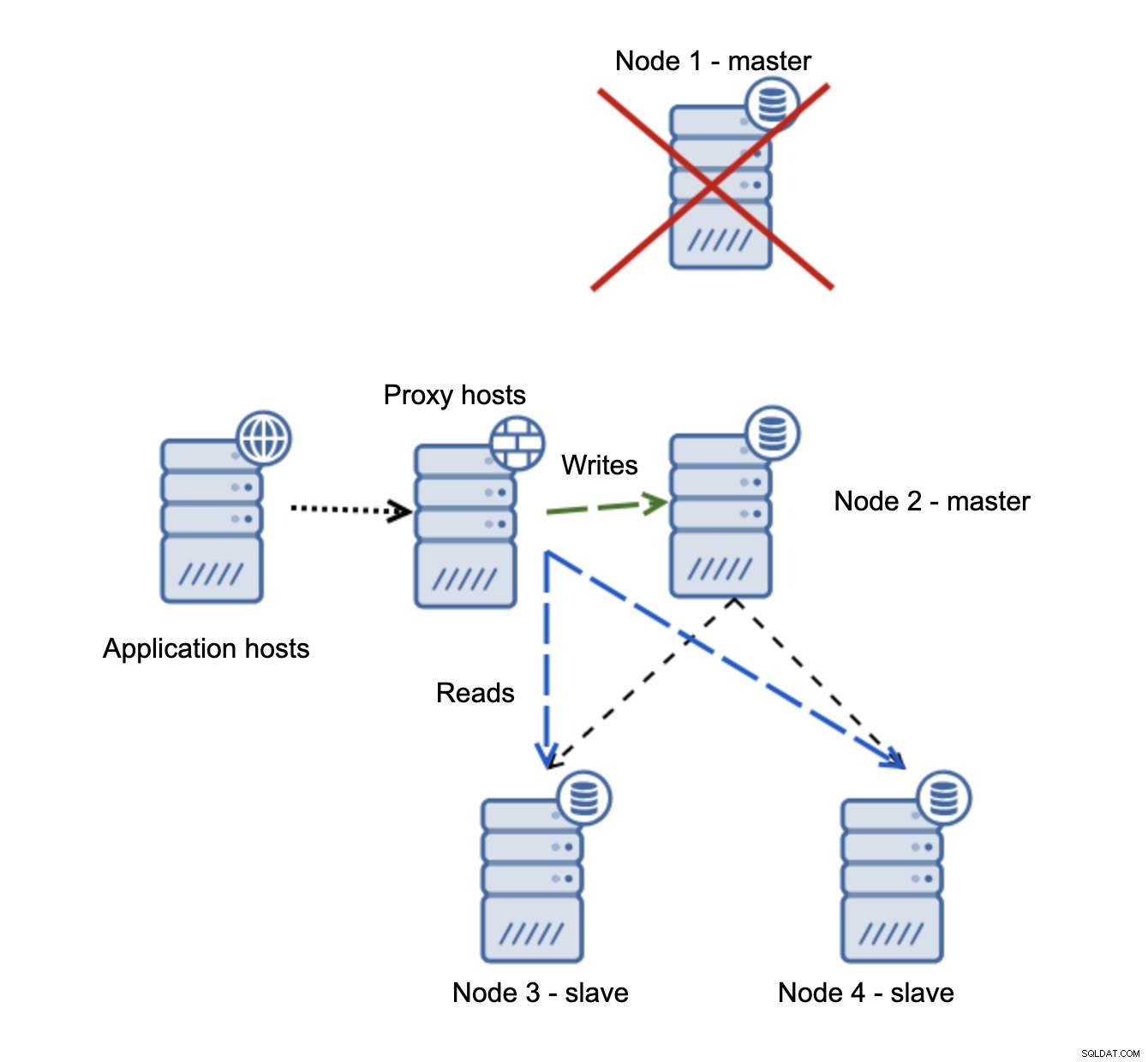
Se o node1 for reiniciado, ele apresentará read_only=1 e será detectado como escravo. Não é ideal, pois não está replicando, mas é aceitável. Idealmente, o antigo mestre não deve aparecer até que seja reconstruído e escravizado pelo novo mestre.
Uma situação muito mais problemática é se tivermos que lidar com o particionamento de rede. Vamos considerar a mesma configuração:camada de aplicativo, camada de proxy e bancos de dados.
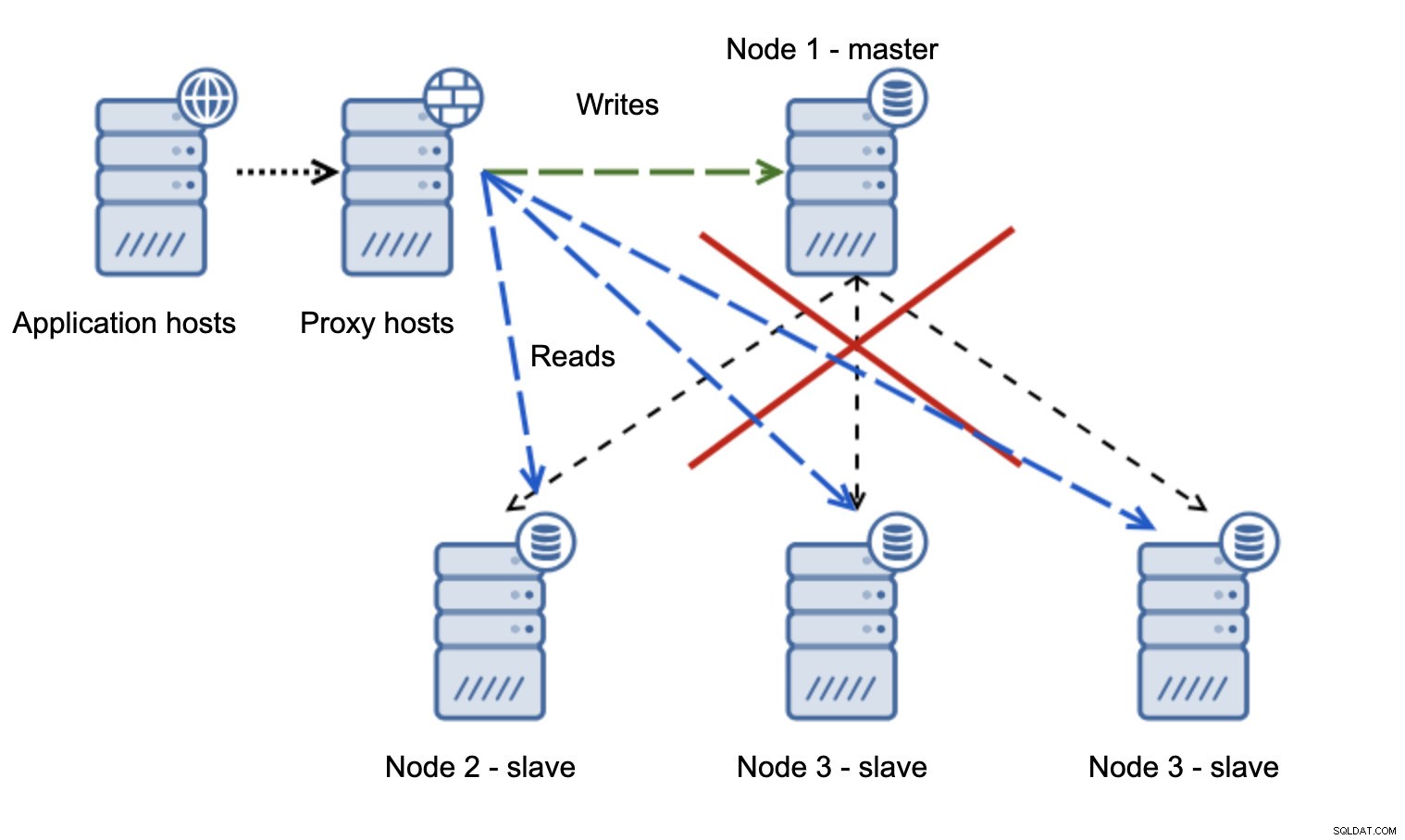
Quando a rede torna o mestre inacessível, o aplicativo não pode ser usado, pois nenhuma gravação chega ao destino. O novo mestre é promovido, as gravações são redirecionadas para ele. O que acontecerá então se os problemas de rede cessarem e o antigo mestre se tornar acessível? Ele não foi interrompido, portanto, ainda está usando read_only=0:
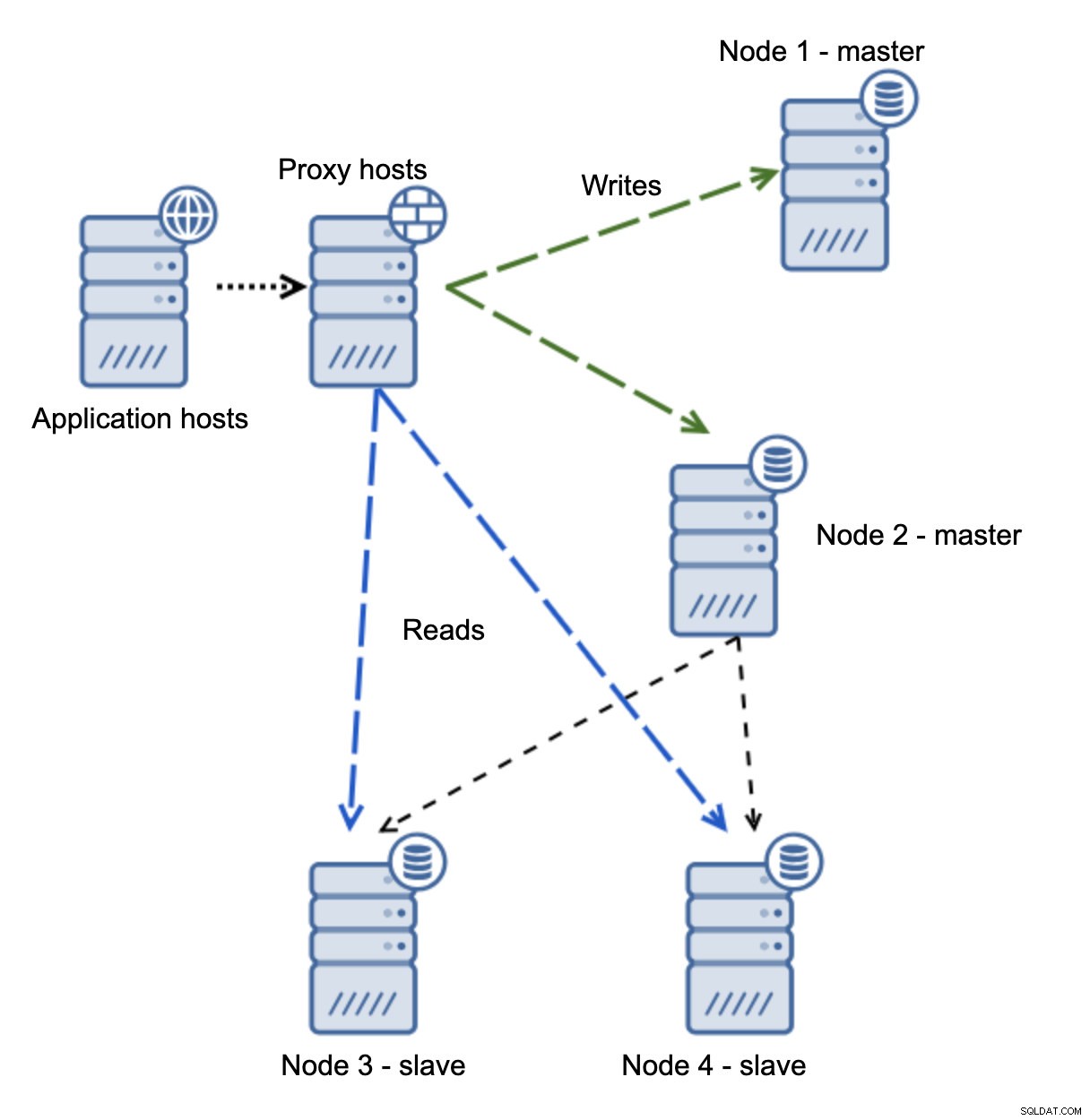
Agora você acabou em um cérebro dividido, quando as gravações foram direcionadas para dois nós. Essa situação é muito ruim, pois mesclar conjuntos de dados divergentes pode demorar um pouco e é um processo bastante complexo.
O que pode ser feito para evitar esse problema? Não há bala de prata, mas algumas ações podem ser tomadas para minimizar a probabilidade de um cérebro dividido acontecer.
Em primeiro lugar, você pode ser mais inteligente na detecção do estado do mestre. Como os escravos veem isso? Eles podem replicar a partir dele? Talvez alguns dos escravos ainda possam se conectar ao mestre, significando que o mestre está em funcionamento ou, pelo menos, possibilitando pará-lo caso seja necessário. E a camada proxy? Todos os nós proxy veem o mestre como indisponível? Se alguns ainda puderem se conectar, você poderá tentar utilizar esses nós para ssh no mestre e pará-lo antes do failover?
O software de gerenciamento de failover também pode ser mais inteligente na detecção do estado da rede. Talvez utilize RAFT ou algum outro protocolo de cluster para construir um cluster com reconhecimento de quorum. Se um software de gerenciamento de failover puder detectar o cérebro dividido, ele também poderá executar algumas ações com base nisso, como, por exemplo, definir todos os nós no segmento particionado como somente leitura, garantindo que o mestre antigo não apareça como gravável quando as redes convergirem.
Você também pode incluir ferramentas como Consul ou Etcd para armazenar o estado do cluster. A camada proxy pode ser configurada para usar dados do Consul, não o estado da variável read_only. Caberá então ao software de gerenciamento de failover fazer as alterações necessárias no Consul para que todos os proxies enviem o tráfego para um novo mestre correto.
Algumas dessas dicas podem até ser combinadas para tornar a detecção de falhas ainda mais confiável. Em suma, é possível minimizar as chances de que o cluster de replicação sofra com redes não confiáveis.
Como você pode ver, não importa se estamos falando de Galera ou MySQL Replication, redes instáveis podem se tornar um problema sério. Por outro lado, se você projetar o ambiente corretamente, ainda poderá fazê-lo funcionar. Esperamos que esta postagem do blog ajude você a criar ambientes que funcionem estáveis mesmo que as redes não sejam.