Ao analisar o desempenho da consulta, há muitas fontes excelentes de informações no SQL Server, e uma das minhas favoritas é o próprio plano de consulta. Nas últimas versões, principalmente a partir do SQL Server 2012, cada nova versão incluiu mais detalhes nos planos de execução. Embora a lista de aprimoramentos continue crescendo, aqui estão alguns atributos que considero valiosos:
- NonParallelPlanReason (SQL Server 2012)
- Diagnóstico de empilhamento de predicado residual (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- diagnóstico de vazamento de tempdb (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Sinalizadores de rastreamento habilitados (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Estatísticas de execução de consulta do operador (SQL Server 2014 SP2, SQL Server 2016)
- Memória máxima habilitada para uma única consulta (SQL Server 2014 SP2, SQL Server 2016 SP1)
Para ver o que existe para cada versão do SQL Server, visite a página Showplan Schema, onde você pode encontrar o esquema para cada versão desde o SQL Server 2005.
Por mais que eu ame todos esses dados extras, é importante observar que algumas informações são mais relevantes para um plano de execução real do que um estimado (por exemplo, informações de derramamento de tempdb). Alguns dias podemos capturar e usar o plano real para solução de problemas, outras vezes temos que usar o plano estimado. Muitas vezes obtemos esse plano estimado – o plano que foi usado para execuções potencialmente problemáticas – do cache de planos do SQL Server. E puxar planos individuais é apropriado ao ajustar uma consulta ou conjunto ou consultas específicas. Mas e quando você quer ideias sobre onde concentrar seus esforços de ajuste em termos de padrões?
O cache do plano do SQL Server é uma fonte prodigiosa de informações quando se trata de ajuste de desempenho, e não me refiro simplesmente à solução de problemas e à tentativa de entender o que está sendo executado em um sistema. Nesse caso, estou falando sobre a mineração de informações dos próprios planos, que são encontrados em sys.dm_exec_query_plan, armazenados como XML na coluna query_plan.
Ao combinar esses dados com informações de sys.dm_exec_sql_text (para que você possa visualizar facilmente o texto da consulta) e sys.dm_exec_query_stats (estatísticas de execução), de repente você pode começar a procurar não apenas as consultas que são as mais pesadas ou as que executam com mais freqüência, mas os planos que contêm um tipo de junção específico, ou varredura de índice, ou aqueles que têm o custo mais alto. Isso é comumente chamado de mineração do cache do plano, e existem várias postagens no blog que falam sobre como fazer isso. Meu colega, Jonathan Kehayias, diz que odeia escrever XML, mas tem vários posts com consultas para minerar o cache do plano:
- Ajustando o 'limite de custo para paralelismo' do cache do plano
- Encontrar conversões de colunas implícitas no cache do plano
- Encontrar quais consultas no cache do plano usam um índice específico
- Aprofundando no cache do plano SQL:encontrando índices ausentes
- Encontrando pesquisas de chave dentro do cache do plano
Se você nunca explorou o que está no cache do seu plano, as consultas nesses posts são um bom começo. No entanto, o cache do plano tem suas limitações. Por exemplo, é possível executar uma consulta e não fazer com que o plano vá para o cache. Se você tiver a opção Otimizar para cargas de trabalho adhoc habilitada, por exemplo, na primeira execução, o stub do plano compilado será armazenado no cache do plano, não no plano compilado completo. Mas o maior desafio é que o cache do plano é temporário. Há muitos eventos no SQL Server que podem limpar completamente o cache do plano ou limpá-lo para um banco de dados, e os planos podem ficar sem cache se não forem usados ou removidos após uma recompilação. Para combater isso, normalmente você precisa consultar o cache do plano regularmente ou fazer um instantâneo do conteúdo em uma tabela de forma programada.
Isso muda no SQL Server 2016 com Repositório de Consultas.
Quando um banco de dados de usuário tem o Repositório de Consultas habilitado, o texto e os planos para consultas executadas nesse banco de dados são capturados e retidos em tabelas internas. Em vez de uma visão temporária do que está sendo executado no momento, temos uma imagem de longo prazo do que foi executado anteriormente. A quantidade de dados retidos é determinada pela configuração CLEANUP_POLICY, cujo padrão é 30 dias. Em comparação com um cache de plano que pode representar apenas algumas horas de execução de consulta, os dados do Query Store são um divisor de águas.
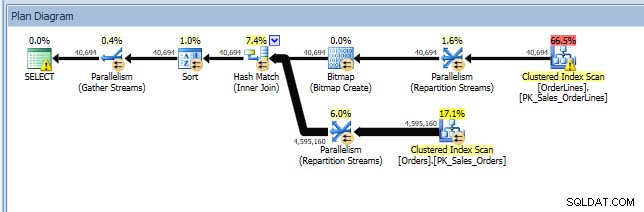
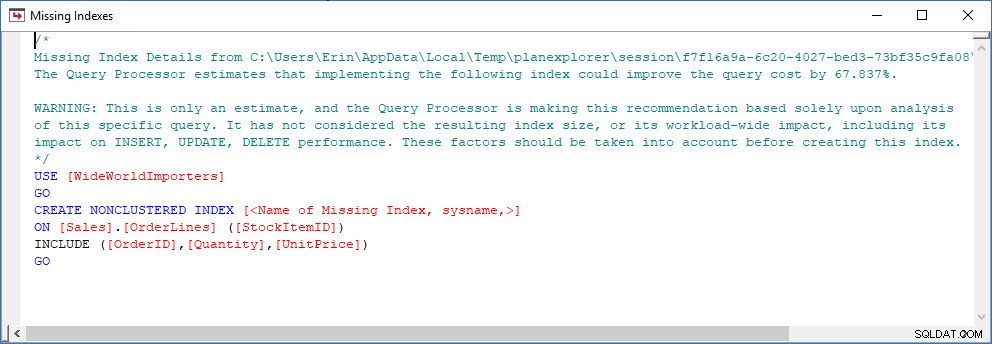
Considere um cenário em que você está fazendo alguma análise de índice – você tem alguns índices que não estão sendo usados e algumas recomendações dos DMVs de índice ausentes. As DMVs de índice ausentes não fornecem nenhum detalhe sobre qual consulta gerou a recomendação de índice ausente. Você pode consultar o cache do plano, usando a consulta do post Finding Missing Indexes de Jonathan. Se eu executar isso em minha instância local do SQL Server, recebo algumas linhas de saída relacionadas a algumas consultas que executei anteriormente.

Posso abrir o plano no Plan Explorer e vejo que há um aviso no operador SELECT, que é para o índice ausente:
Este é um ótimo começo, mas, novamente, minha saída depende do que estiver no cache. Posso pegar a consulta de Jonathan e modificar para o Query Store e executá-la no meu banco de dados de demonstração WideWorldImporters:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; 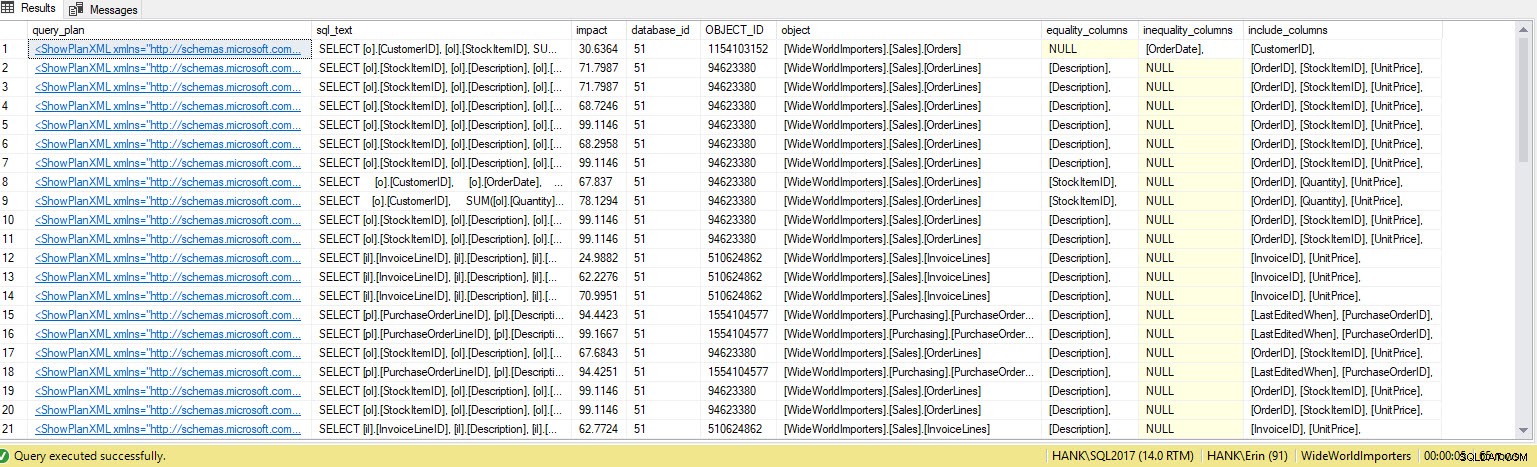
Recebo muito mais linhas na saída. Novamente, os dados do Repositório de Consultas representam uma visão maior das consultas executadas no sistema e o uso desses dados nos fornece um método abrangente para determinar não apenas quais índices estão faltando, mas quais consultas esses índices suportariam. A partir daqui, podemos nos aprofundar no Query Store e observar as métricas de desempenho e a frequência de execução para entender o impacto da criação do índice e decidir se a consulta é executada com frequência suficiente para garantir o índice.
Se você não estiver usando o Query Store, mas estiver usando o SentryOne, poderá extrair essas mesmas informações do banco de dados do SentryOne. O plano de consulta é armazenado na tabela dbo.PerformanceAnalysisPlan em um formato compactado, portanto, a consulta que usamos é uma variação semelhante à anterior, mas você notará que a função DECOMPRESS também é usada:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; Em um sistema SentryOne, tive a seguinte saída (e, é claro, clicar em qualquer um dos valores query_plan abrirá o plano gráfico):

Algumas vantagens que o SentryOne oferece sobre o Query Store é que você não precisa habilitar esse tipo de coleta por banco de dados, e o banco de dados monitorado não precisa suportar os requisitos de armazenamento, pois todos os dados são armazenados no repositório. Você também pode capturar essas informações em todas as versões com suporte do SQL Server, não apenas naquelas que oferecem suporte ao Repositório de Consultas. Observe que o SentryOne coleta apenas consultas que excedem limites, como duração e leituras. Você pode ajustar esses limites padrão, mas é um item a ser observado ao minerar o banco de dados SentryOne:nem todas as consultas podem ser coletadas. Além disso, a função DECOMPRESS não está disponível até o SQL Server 2016; para versões mais antigas do SQL Server, você desejará:
- Faça backup do banco de dados SentryOne e restaure-o no SQL Server 2016 ou superior para executar as consultas;
- copie os dados da tabela dbo.PerformanceAnalysisPlan e importe-os para uma nova tabela em uma instância do SQL Server 2016;
- consultar o banco de dados SentryOne por meio de um servidor vinculado de uma instância do SQL Server 2016; ou,
- consultar o banco de dados a partir do código do aplicativo que pode analisar coisas específicas após a descompactação.
Com o SentryOne, você tem a capacidade de minerar não apenas o cache do plano, mas também os dados retidos no repositório do SentryOne. Se você estiver executando o SQL Server 2016 ou superior e tiver o Repositório de consultas habilitado, também poderá encontrar essas informações em
sys.query_store_plan . Você não está limitado apenas a este exemplo de localização de índices ausentes; todas as consultas das outras postagens de cache do plano de Jonathan podem ser modificadas para serem usadas para extrair dados do SentryOne ou do Query Store. Além disso, se você estiver familiarizado o suficiente com XQuery (ou estiver disposto a aprender), poderá usar o Showplan Schema para descobrir como analisar o plano para encontrar as informações desejadas. Isso oferece a capacidade de encontrar padrões e antipadrões em seus planos de consulta que sua equipe pode corrigir antes que se tornem um problema.