No meu último post ("Cara, quem é o dono dessa tabela #temp?"), sugeri que no SQL Server 2012 e acima, você pudesse usar Eventos Estendidos para monitorar a criação de tabelas #temp. Isso permitiria correlacionar objetos específicos que ocupam muito espaço no tempdb com a sessão que os criou (por exemplo, para determinar se a sessão pode ser encerrada para tentar liberar espaço). O que não discuti é a sobrecarga desse rastreamento – esperamos que os Eventos Estendidos sejam mais leves que o rastreamento, mas nenhum monitoramento é totalmente gratuito.
Como a maioria das pessoas deixa o rastreamento padrão ativado, deixaremos isso no lugar. Testaremos os dois heaps usando
SELECT INTO (que o rastreamento padrão não coletará) e índices clusterizados (que coletará), e cronometraremos o lote por conta própria como uma linha de base e, em seguida, executaremos o lote novamente com a sessão de eventos estendidos em execução. Também testaremos no SQL Server 2012 e no SQL Server 2014. O lote em si é bem simples:SET NOCOUNT ON; SELECT SYSDATETIME();GO -- executa esta parte apenas para o lote de heap:SELECT TOP (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id];DROP TABLE #foo; -- executa esta parte apenas para o lote CIX:CREATE TABLE #bar(id INT PRIMARY KEY);INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id];DROP TABLE #bar; GO 100000 SELECT SYSDATETIME();
Ambas as instâncias possuem tempdb configurado com quatro arquivos de dados e com TF 1117 e TF 1118 habilitados, em uma VM com quatro CPUs, 16GB de memória e apenas SSD. Criei intencionalmente pequenas tabelas #temp para amplificar qualquer impacto observado no próprio lote (que seria abafado se a criação das tabelas #temp demorasse muito ou causasse eventos de crescimento automático excessivos).
Executei esses lotes em cada cenário e aqui estavam os resultados, medidos em duração do lote em segundos:
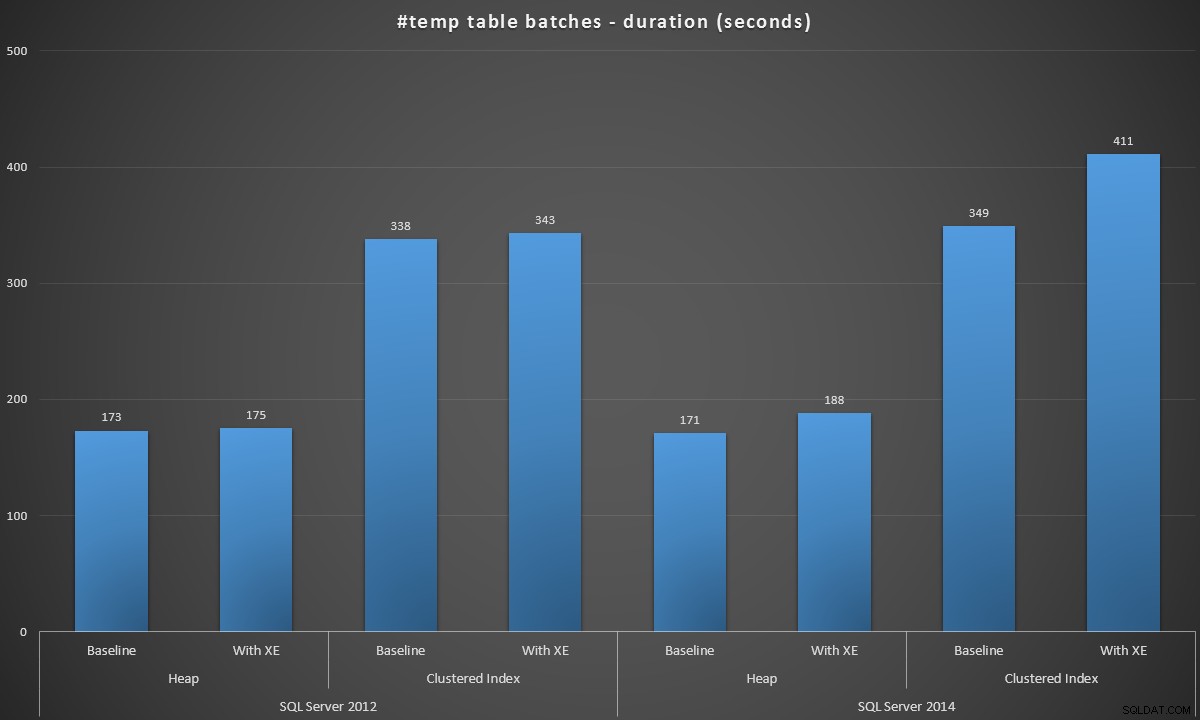
Duração do lote, em segundos, da criação de 100.000 #tabelas temporárias
Expressando os dados de forma um pouco diferente, se dividirmos 100.000 pela duração, podemos mostrar o número de tabelas #temp que podemos criar por segundo em cada cenário (leia-se:throughput). Aqui estão esses resultados:
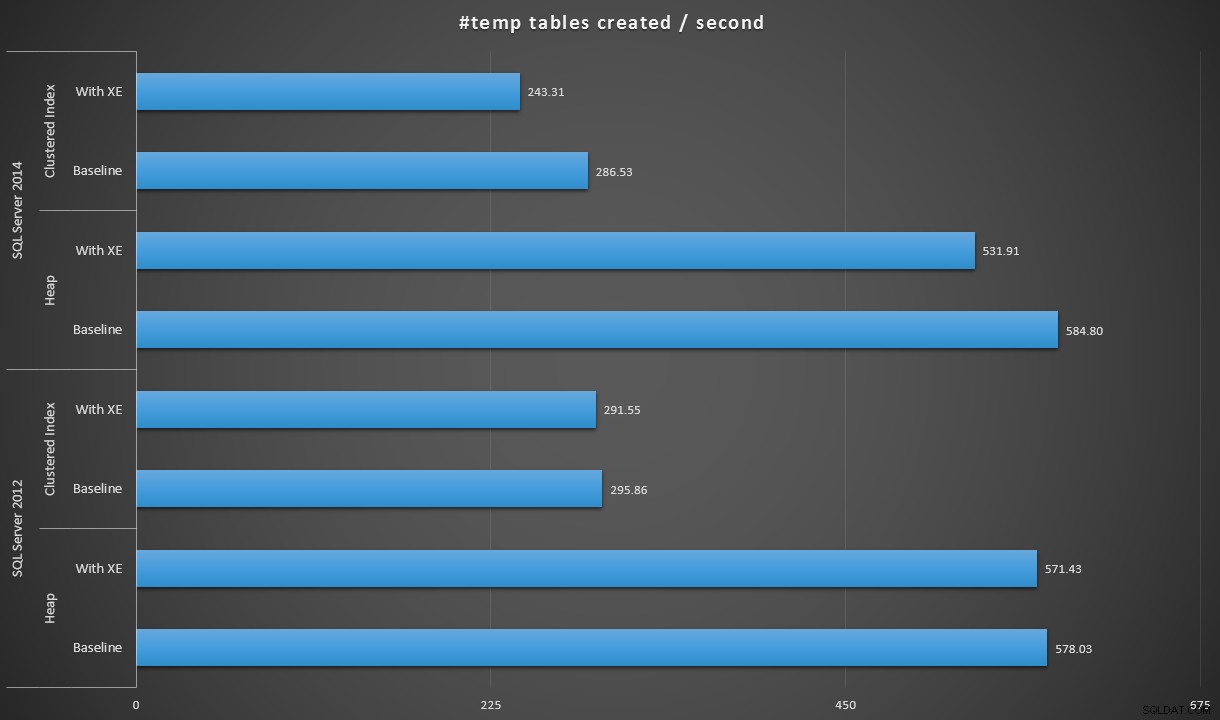
#temp tabelas criadas por segundo em cada cenário
Os resultados foram um pouco surpreendentes para mim – eu esperava que, com as melhorias do SQL Server 2014 na lógica de escrita ansiosa, a população de heap, no mínimo, fosse muito mais rápida. O heap em 2014 foi dois míseros segundos mais rápido que 2012 na configuração de linha de base, mas os Eventos Estendidos aumentaram bastante o tempo (um aumento de aproximadamente 10% em relação à linha de base); enquanto o tempo do índice clusterizado era comparável a 2012 na linha de base, mas aumentou quase 18% com os eventos estendidos ativados. Em 2012, os deltas para heaps e índices clusterizados foram bem mais modestos – 1,1% e 1,5%, respectivamente. (E para ser claro, nenhum evento de crescimento automático ocorreu durante nenhum dos testes.)
Então, pensei, e se eu criasse uma sessão de Eventos Estendidos mais enxuta e mesquinha? Certamente eu poderia remover algumas dessas colunas de ação - talvez eu só precise de nome de login e spid e possa ignorar o nome do aplicativo, o nome do host e o sql_text potencialmente caro. Talvez eu possa descartar o filtro adicional no commit (coletando o dobro de eventos, mas menos CPU gasta na filtragem) e permitir a perda de vários eventos para reduzir o impacto potencial na carga de trabalho. Esta sessão mais enxuta se parece com isso:
CRIAR SESSÃO DO EVENTO [TempTableCreation2014_LeanerMeaner] NO SERVIDOR ADICIONAR EVENTO sqlserver.object_created( ACTION ( sqlserver.server_principal_name, sqlserver.session_id ) WHERE ( sqlserver.like_i_sql_unicode_string([object_name], N'#%') ))ADICIONAR TARGET package0.asynchronous_file_target ( SET FILENAME ='c:\temp\TempTableCreation2014_LeanerMeaner.xel', MAX_FILE_SIZE =32768, MAX_ROLLOVER_FILES =10)WITH ( EVENT_RETENTION_MODE =ALLOW_MULTIPLE_EVENT_LOSS);GOALTER EVENT SESSION [TempTable>Creation2014_LeanerMeaner] NO SERVER STATE
Infelizmente, não, mesmos resultados. Pouco mais de três minutos para o heap e pouco menos de sete minutos para o índice clusterizado. Para aprofundar onde o tempo extra estava sendo gasto, observei a instância de 2014 com o SQL Sentry e executei apenas o lote de índice clusterizado sem nenhuma sessão de eventos estendidos configurada. Em seguida, executei o lote novamente, desta vez com a sessão XE mais leve configurada. Os tempos de lote foram 5:47 (347 segundos) e 6:55 (415 segundos) – muito em linha com o lote anterior (fiquei feliz em ver que nosso monitoramento não contribuiu mais para a duração :-)) . Validei que nenhum evento foi descartado e, novamente, que nenhum evento de crescimento automático ocorreu.
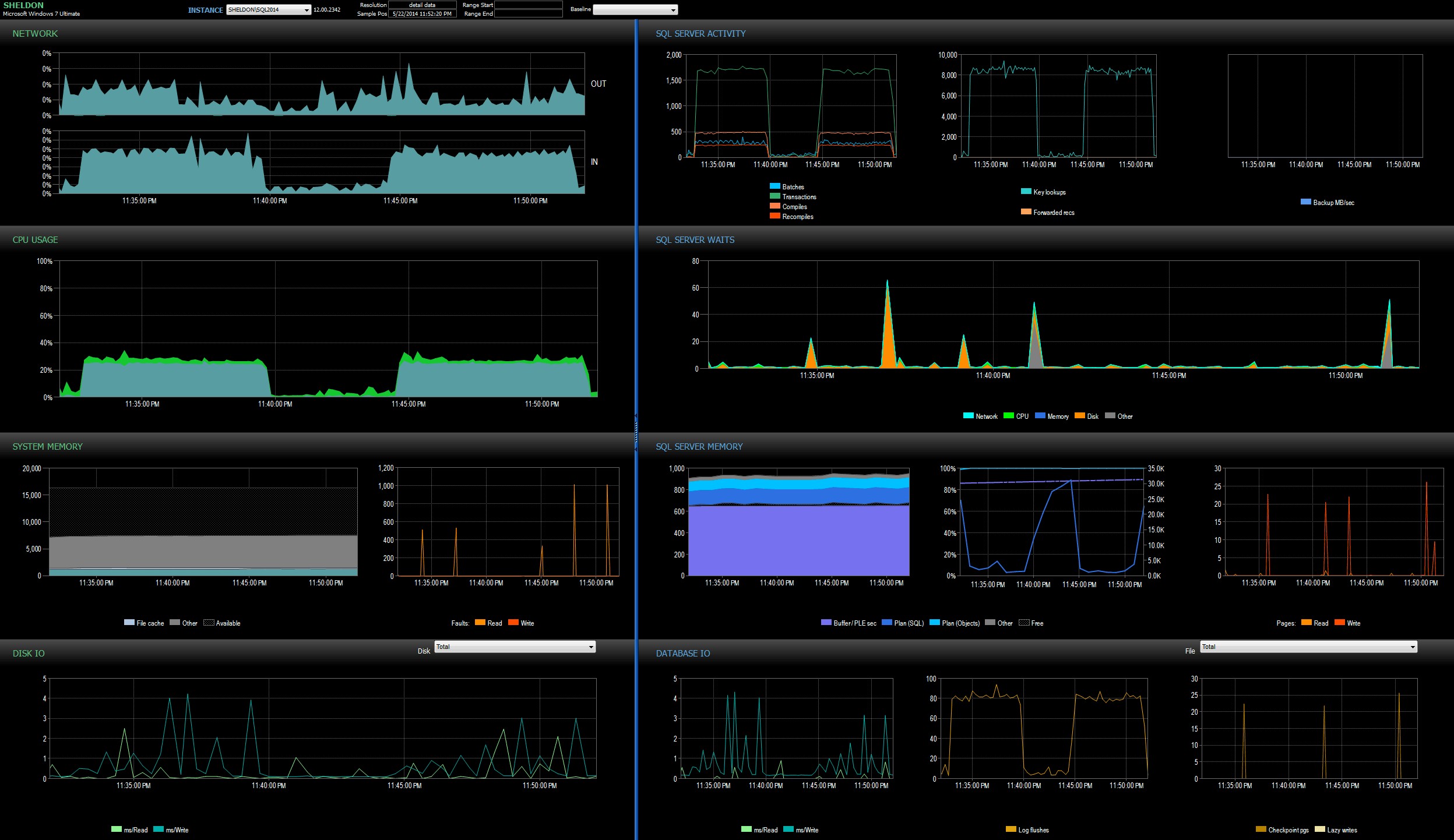
Examinei o painel do SQL Sentry no modo de histórico, o que me permitiu visualizar rapidamente as métricas de desempenho de ambos os lotes lado a lado:
Painel do SQL Sentry, no modo histórico, mostrando os dois lotes em>
Ambos os lotes foram virtualmente idênticos em termos de rede, CPU, transações, compilações, pesquisas de chave, etc. Segundo lote. Minha teoria de trabalho bem depois da meia-noite é que talvez uma boa parte do atraso observado foi devido à mudança de contexto causada pelo processo de Eventos Estendidos. Como não temos nenhuma visibilidade exata do que o XE está fazendo nos bastidores, nem sabemos quais mecânicas subjacentes mudaram no XE entre 2012 e 2014, essa é a história que vou seguir por enquanto, até mais confortável com xperf e/ou WinDbg.
Conclusão
De qualquer forma, fica claro que acompanhar a criação de tabelas #temp não é gratuito, e o custo pode variar dependendo do tipo de tabelas #temp que você está criando, da quantidade de informações que você está coletando em suas sessões XE e até mesmo da versão do SQL Server que você está usando. Assim, você pode executar testes semelhantes aos que fiz aqui e decidir o valor da coleta dessas informações em seu ambiente.