Recentemente, escrevemos vários blogs sobre como diferentes provedores de nuvem lidam com failover de banco de dados. Comparamos o desempenho de failover no Amazon Aurora, Amazon RDS e ClusterControl, testamos o comportamento de failover no Amazon RDS e também no Google Cloud Platform. Embora esses serviços ofereçam ótimas opções quando se trata de failover, eles podem não ser adequados para todos os aplicativos.
Nesta postagem de blog, gastaremos um pouco de tempo analisando os prós e contras de usar as soluções DBaaS em comparação com o design de um ambiente manualmente ou usando uma plataforma de gerenciamento de banco de dados, como ClusterControl.
Implementação de bancos de dados de alta disponibilidade com soluções gerenciadas
A principal razão para usar as soluções existentes é a facilidade de uso. Você pode implantar uma solução altamente disponível com failover automatizado em apenas alguns cliques. Não há necessidade de combinar diferentes ferramentas, gerenciar os bancos de dados manualmente, implantar ferramentas, escrever scripts, projetar o monitoramento ou qualquer outra operação de gerenciamento de banco de dados. Tudo já está no lugar. Isso pode reduzir seriamente a curva de aprendizado e requer menos experiência para configurar um ambiente altamente disponível para os bancos de dados; permitindo que basicamente todos implementem tais configurações.
Na maioria dos casos com essas soluções, o processo de failover é executado em um tempo razoável. Pode ser extremamente rápido como no Amazon Aurora ou um pouco mais lento como nos nós SQL do Google Cloud Platform. Para a maioria dos casos, esses tipos de resultados são aceitáveis.
A linha de fundo. Se você puder aceitar de 30 a 60 segundos de tempo de inatividade, deverá usar qualquer uma das plataformas DBaaS.
A desvantagem de usar uma solução gerenciada para HA
Embora as soluções DBaaS sejam simples de usar, elas também apresentam algumas desvantagens sérias. Para começar, sempre há um componente de dependência do fornecedor a ser considerado. Depois de implantar um cluster no Amazon Web Services, é bastante complicado migrar para fora desse provedor. Não há métodos fáceis para baixar o conjunto de dados completo por meio de um backup físico. Com a maioria dos provedores, apenas backups lógicos executados manualmente estão disponíveis. Claro, sempre há opções para conseguir isso, mas normalmente é um processo complexo e demorado, que ainda pode exigir algum tempo de inatividade.
O uso de um provedor como o Amazon RDS também tem limitações. Algumas ações não podem ser executadas facilmente, o que seria muito simples de realizar em ambientes implantados de maneira totalmente controlada pelo usuário (por exemplo, AWS EC2). Algumas dessas limitações já foram abordadas em outros blogs, mas para resumir é que nenhum serviço DBaaS oferece o mesmo nível de flexibilidade que a replicação regular baseada em MySQL GTID. Você pode promover qualquer escravo, você pode re-escravizar cada nó de qualquer outro... praticamente todas as ações são possíveis. Com ferramentas como o RDS, você enfrenta limitações induzidas pelo design que não podem ser contornadas.
O problema também está na capacidade de entender os detalhes de desempenho. Ao projetar sua própria configuração altamente disponível, você se familiariza com os possíveis problemas de desempenho que podem aparecer. Por outro lado, RDS e ambientes semelhantes são praticamente “caixas pretas”. Sim, aprendemos que o Amazon RDS usa o DRBD para criar uma cópia de sombra do mestre, sabemos que o Aurora usa armazenamento compartilhado e replicado para implementar failovers muito rápidos. Isso é apenas um conhecimento geral. Não podemos dizer quais são as implicações de desempenho dessas soluções além do que podemos notar casualmente. Quais são os problemas comuns associados a eles? Quão estáveis são essas soluções? Apenas os desenvolvedores por trás da solução sabem com certeza.
Qual é a alternativa às soluções DBaaS?
Você pode se perguntar, existe uma alternativa ao DBaaS? Afinal, é muito conveniente executar o serviço gerenciado onde você pode acessar a maioria das ações típicas via interface do usuário. Você pode criar e restaurar backups, o failover é tratado automaticamente para você. O ambiente é fácil de usar, o que pode ser atraente para empresas que não possuem funcionários dedicados e experientes para lidar com bancos de dados.
ClusterControl oferece uma ótima alternativa para serviços DBaaS baseados em nuvem. Ele fornece uma interface gráfica do usuário, que pode ser usada para implantar, gerenciar e monitorar bancos de dados de código aberto.
Em alguns cliques, você pode implantar facilmente um cluster de banco de dados altamente disponível, com failover automatizado (mais rápido que a maioria das ofertas de DBaaS), gerenciamento de backup, monitoramento avançado e outros recursos, como integração com ferramentas externas (por exemplo, Slack ou PagerDuty) ou gerenciamento de atualização. Tudo isso evitando completamente o aprisionamento do fornecedor.
ClusterControl não se importa onde seus bancos de dados estão localizados, desde que possa se conectar a eles usando SSH. Você pode ter configurações na nuvem, no local ou em um ambiente misto de vários provedores de nuvem. Enquanto houver conectividade, o ClusterControl poderá gerenciar o ambiente. Utilizar as soluções que você deseja (e não aquelas que você não conhece ou conhece) permite que você assuma o controle total sobre o ambiente a qualquer momento.
Qualquer que seja a configuração implantada com o ClusterControl, você pode gerenciá-la facilmente de maneira mais tradicional, manual ou com script. O ClusterControl ainda fornece uma interface de linha de comando, que permite incorporar tarefas executadas pelo ClusterControl em seus scripts de shell. Você tem todo o controle que deseja - nada é uma caixa preta, cada parte do ambiente seria construída usando soluções de código aberto combinadas e implantadas pelo ClusterControl.
Vamos dar uma olhada na facilidade com que você pode implantar um cluster de replicação MySQL usando o ClusterControl. Vamos supor que você tenha o ambiente preparado com o ClusterControl instalado em uma instância e todos os outros nós acessíveis via SSH do host do ClusterControl.
Vamos começar escolhendo o assistente “Deploy”.
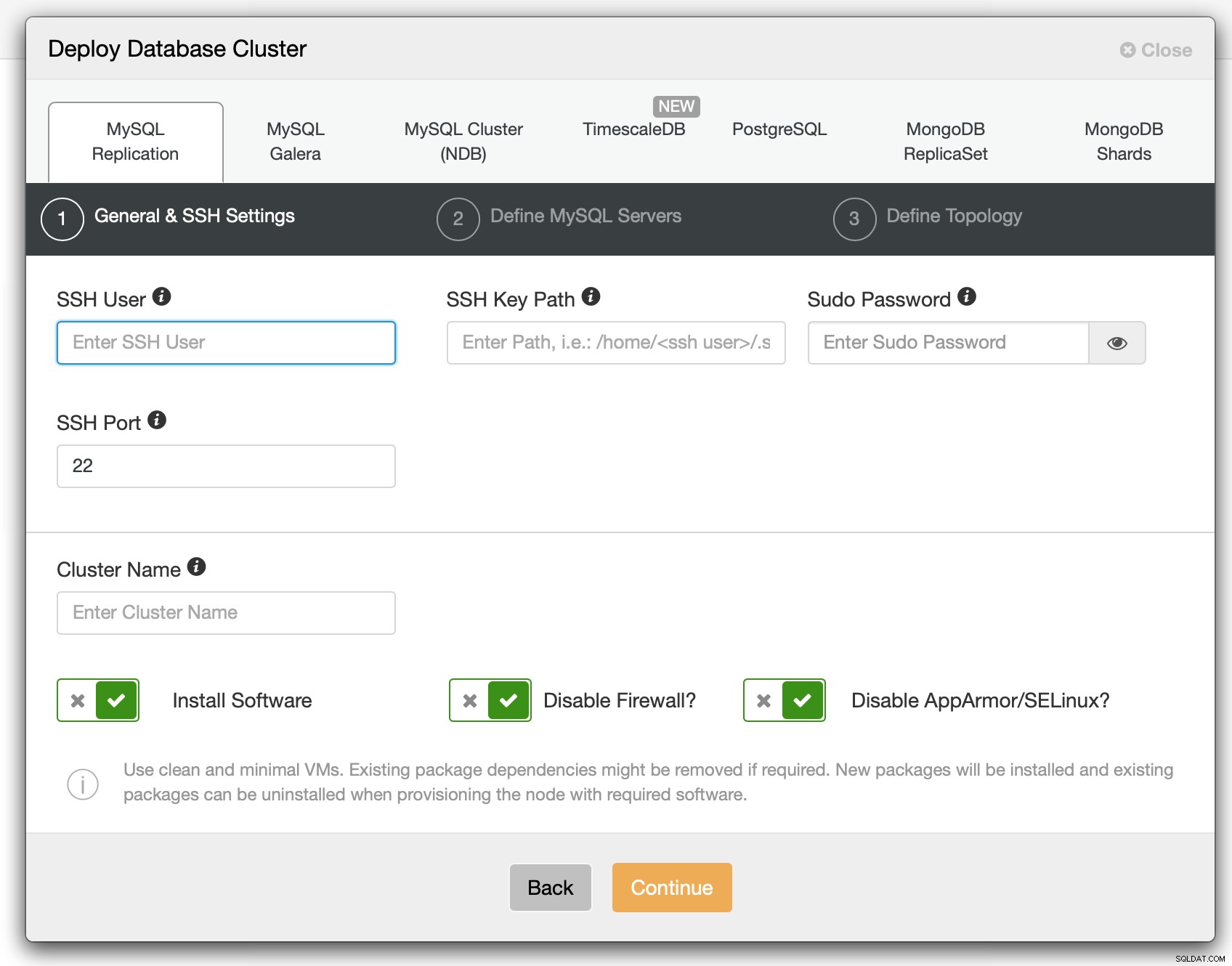
No primeiro passo temos que definir como ClusterControl deve se conectar aos nós em quais bancos de dados devem ser implantados. Tanto o acesso root quanto o sudo (com ou sem a senha) são suportados.
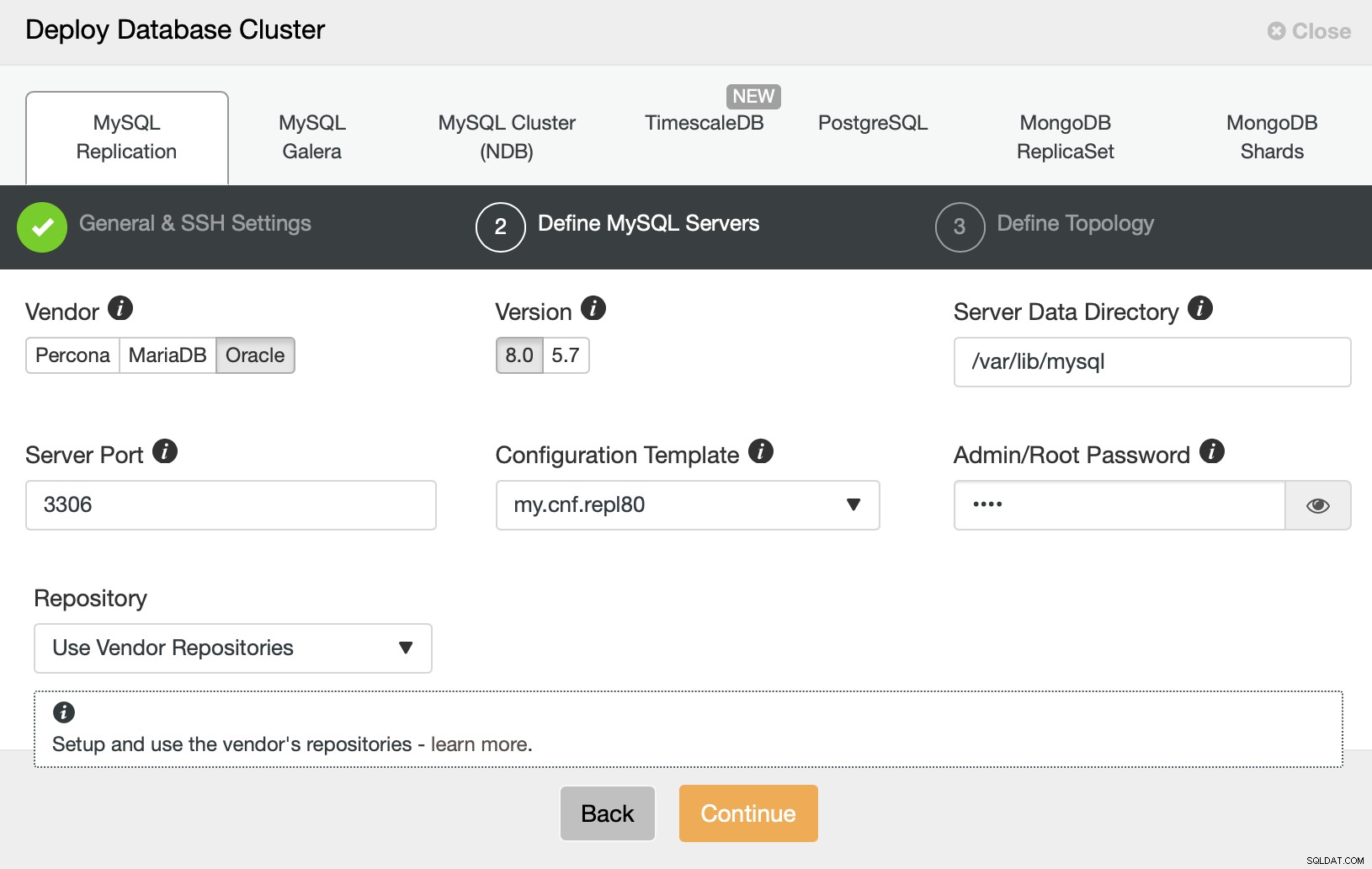
Então, queremos escolher um fornecedor, versão e passar a senha para o usuário administrativo em nosso banco de dados MySQL.
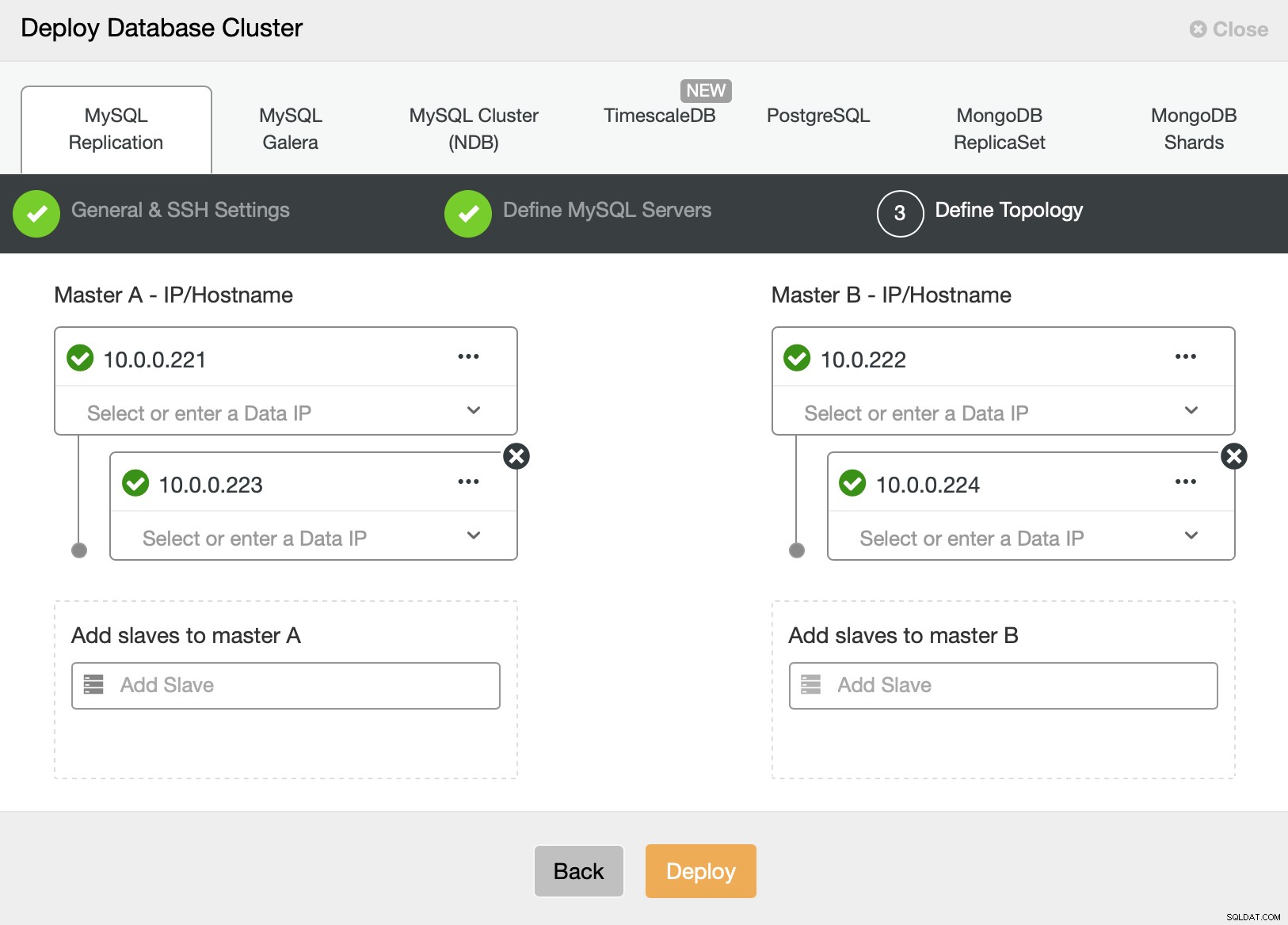
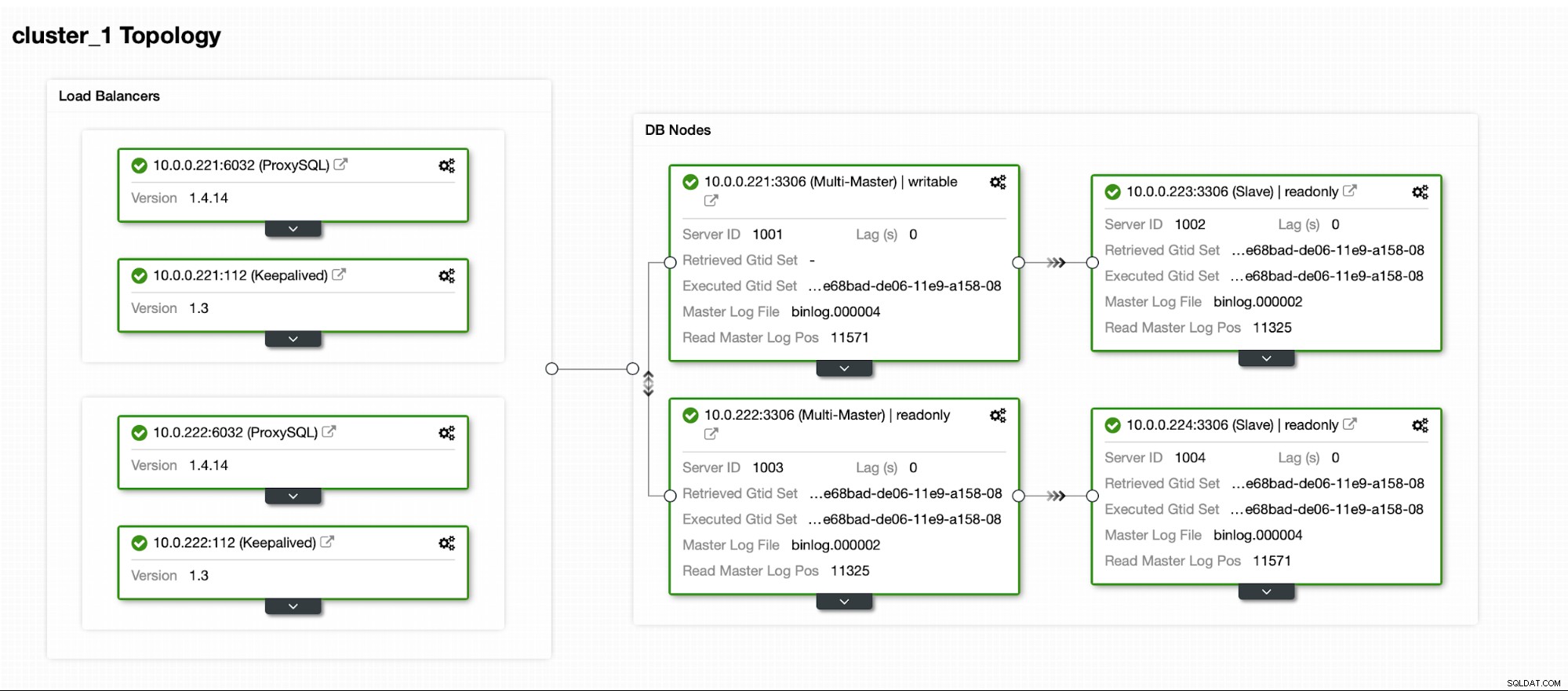
Por fim, queremos definir a topologia para nosso novo cluster. Como você pode ver, isso já é uma configuração bastante complexa, diferente de algo que você pode implantar usando o nó AWS RDS ou GCP SQL.
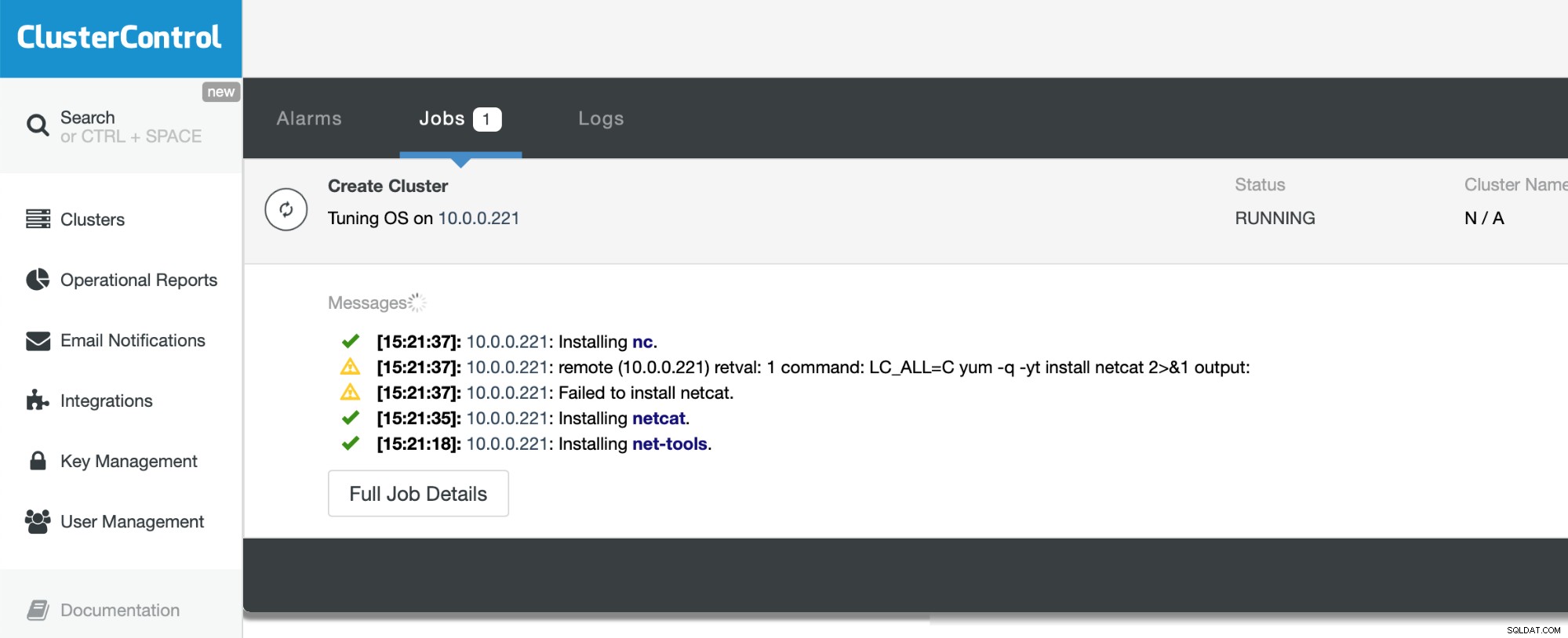
Tudo o que temos a fazer agora é aguardar a conclusão do processo. O ClusterControl fará o possível para entender o ambiente no qual está implantando e instalar o conjunto de pacotes necessários, incluindo o próprio banco de dados.

Depois que o cluster estiver funcionando, você poderá prosseguir com a implantação a camada de proxy (que fornecerá ao seu aplicativo um único ponto de entrada na camada de banco de dados). Isso é mais ou menos o que acontece nos bastidores com DBaaS, onde você também tem endpoints para se conectar ao cluster de banco de dados. É bastante comum usar um único endpoint para gravações e vários endpoints para alcançar réplicas específicas.
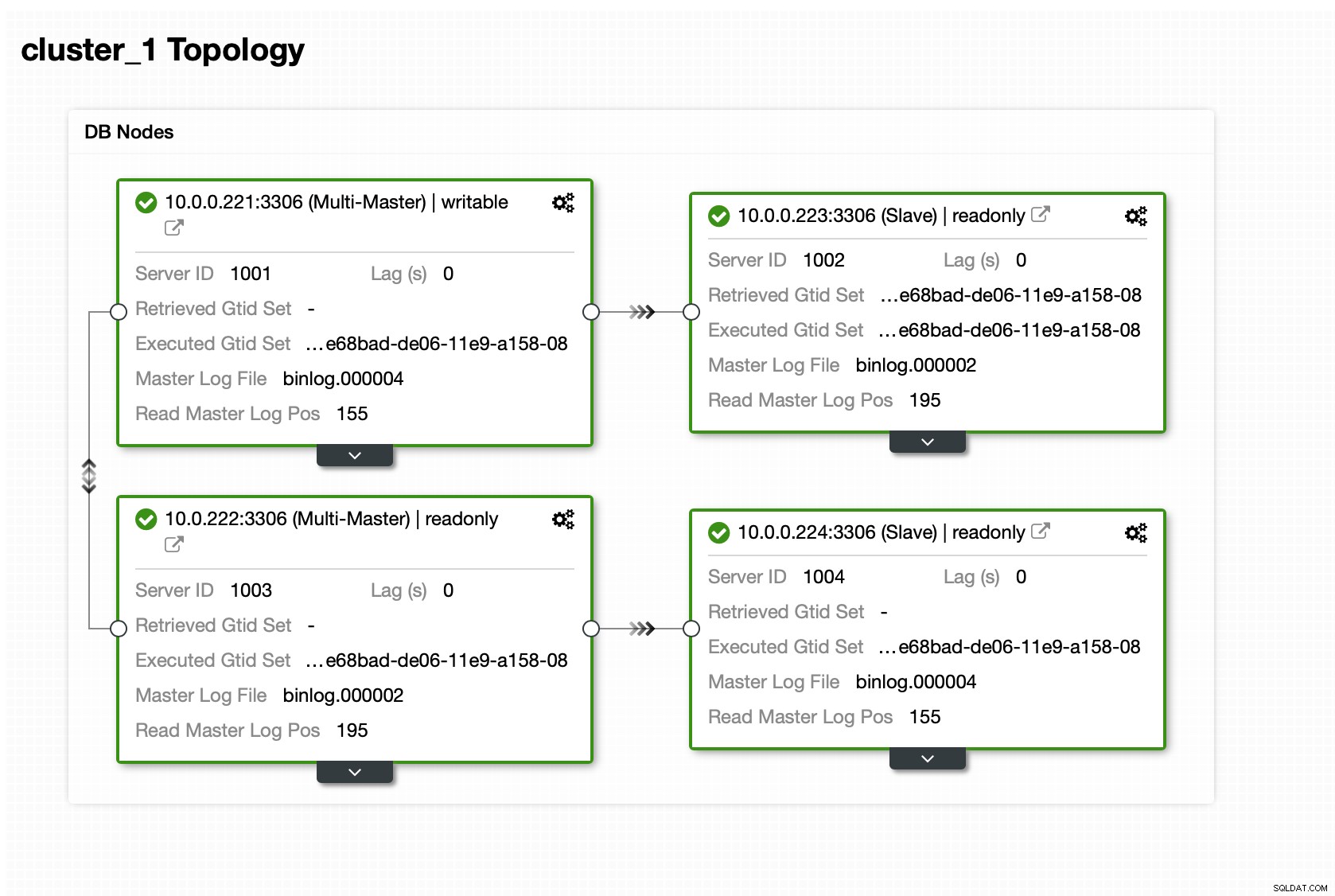
Aqui usaremos ProxySQL, que fará o trabalho sujo para nós - ele entenderá a topologia, enviará gravações apenas para o mestre e balanceará a carga de consultas somente leitura em todas as réplicas que temos.
Para implantar o ProxySQL, iremos para Manage -> Load Balancers.
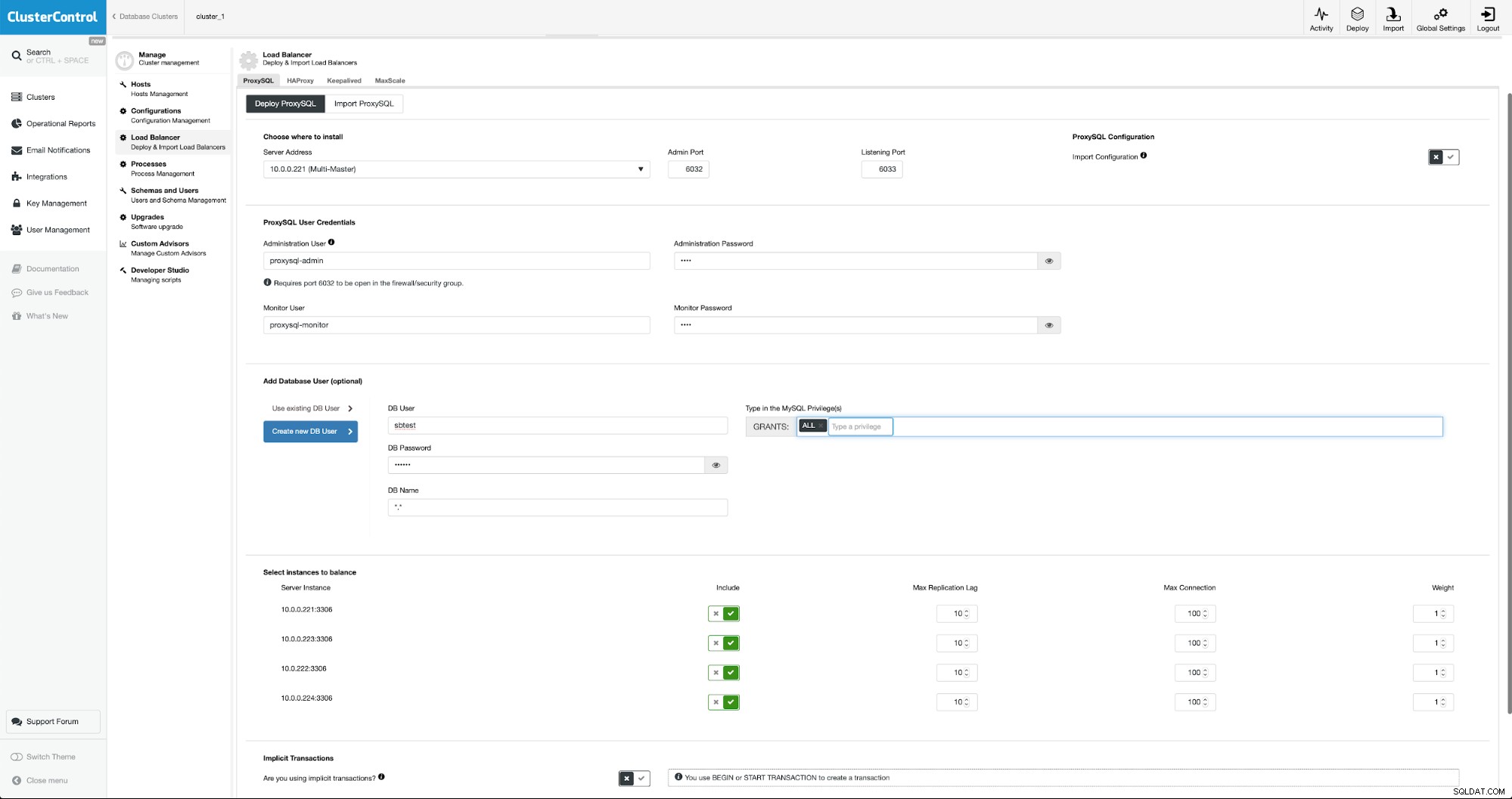
Precisamos preencher todos os campos obrigatórios:hosts para implantação, credenciais para o usuário administrativo e de monitoramento, podemos importar o usuário existente do MySQL para o ProxySQL ou criar um novo. Todos os detalhes sobre ProxySQL podem ser facilmente encontrados em vários blogs em nossa seção de blogs.
Queremos que pelo menos dois nós ProxySQL sejam implantados para garantir alta disponibilidade. Então, uma vez implantados, implantaremos o Keepalived no ProxySQL. Isso garantirá que o IP virtual seja configurado e aponte para uma das instâncias do ProxySQL, desde que haja pelo menos um nó íntegro.
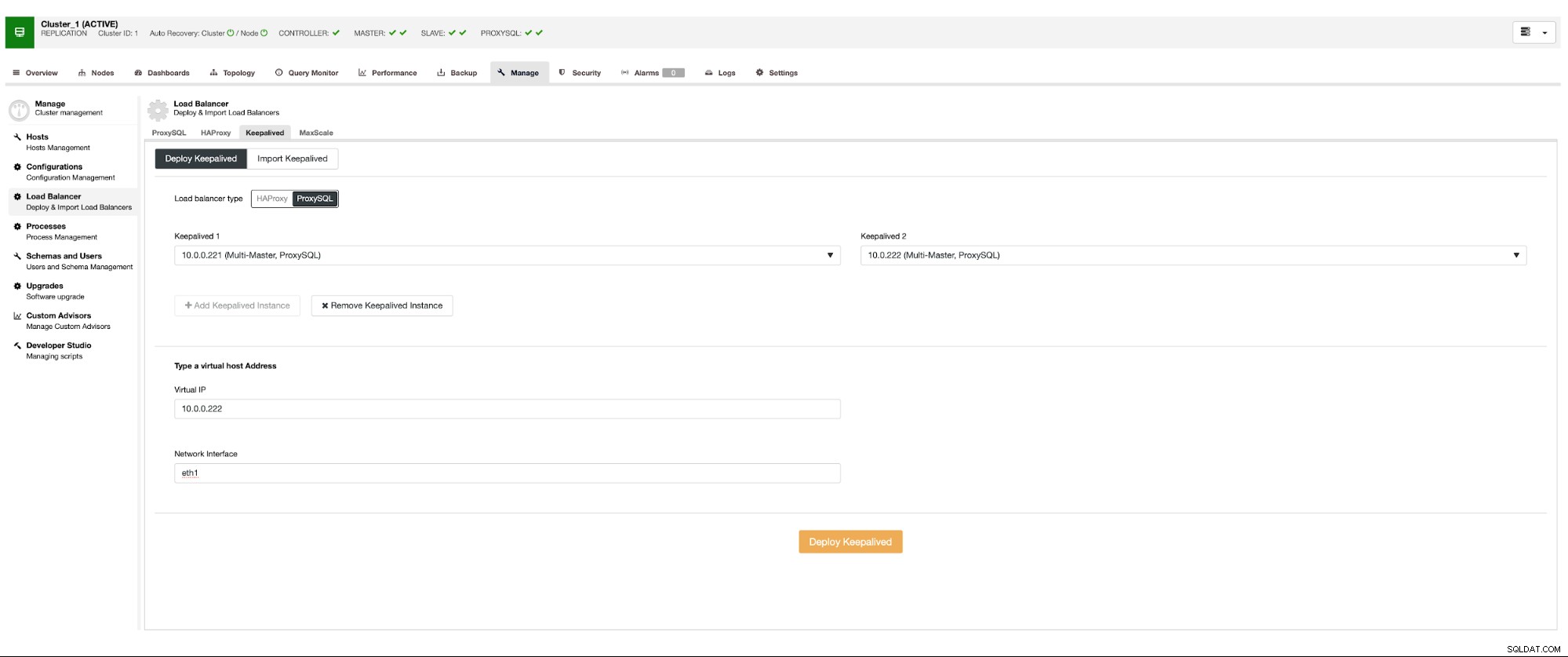
Aqui está o único problema em potencial se você for com ambientes de nuvem onde o roteamento funciona de uma forma que você não pode facilmente abrir uma interface de rede. Nesse caso, você terá que modificar a configuração do Keepalived, introduzir o script 'notify_master' e usar um script, que fará as alterações de IP necessárias - no caso do EC2, seria necessário desanexar o Elastic IP de um host e anexá-lo ao outro hospedeiro.
Há muitas instruções sobre como fazer isso usando software de código aberto amplamente testado em configurações implantadas pelo ClusterControl. Você pode encontrar facilmente informações adicionais, dicas e instruções relevantes para seu ambiente específico.
Conclusão
Esperamos que você tenha achado esta postagem do blog perspicaz. Se você quiser testar o ClusterControl, ele vem com um teste corporativo de 30 dias, onde você tem todos os recursos disponíveis. Você pode baixá-lo gratuitamente e testar se ele se encaixa no seu ambiente.



