Esta é a quarta parte de uma série de cinco partes que se aprofunda na maneira como os planos paralelos do modo de linha do SQL Server começam a ser executados. A parte 1 inicializou o contexto de execução zero para a tarefa pai e a parte 2 criou a árvore de verificação de consulta. A parte 3 iniciou a verificação de consulta, executou algumas fase inicial processamento e iniciou as primeiras tarefas paralelas adicionais na ramificação C.
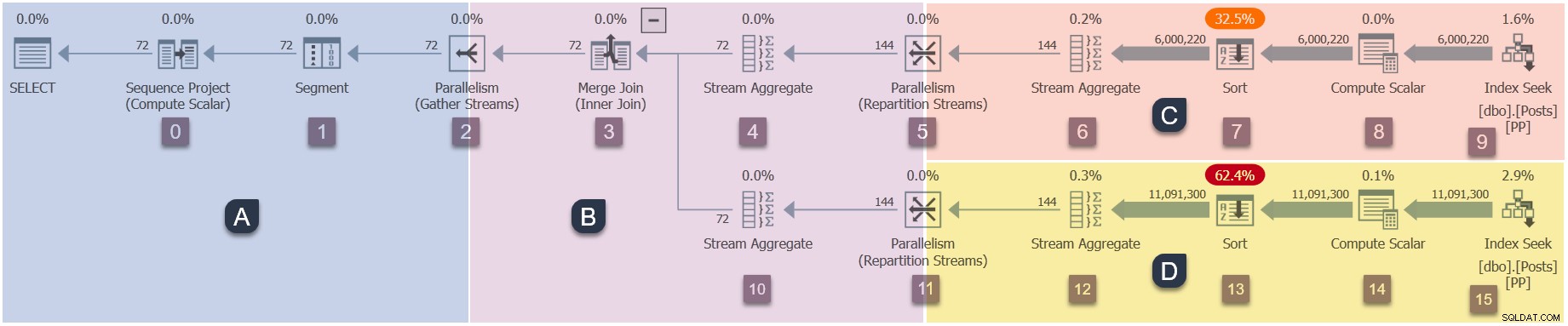
Detalhes de execução da ramificação C
Este é o segundo passo da sequência de execução:
- Ramo A (tarefa pai).
- Ramo C (tarefas paralelas adicionais).
- Ramo D (tarefas paralelas adicionais).
- Ramo B (tarefas paralelas adicionais).
Um lembrete das filiais em nosso plano paralelo (clique para ampliar)
Pouco tempo depois das novas tarefas para a ramificação C enfileirada, o SQL Server anexa um trabalhador para cada tarefa e coloca o trabalhador em um agendador pronto para execução. Cada nova tarefa é executada dentro de um novo contexto de execução. No DOP 2, há duas novas tarefas, duas threads de trabalho e dois contextos de execução para a ramificação C. Cada tarefa executa sua própria cópia dos iteradores na ramificação C em sua própria thread de trabalho:

As duas novas tarefas paralelas começam a ser executadas em um subprocedimento ponto de entrada, que inicialmente leva a um
Open chame no lado do produtor da troca (CQScanXProducerNew::Open ). Ambas as tarefas têm pilhas de chamadas idênticas no início de suas vidas: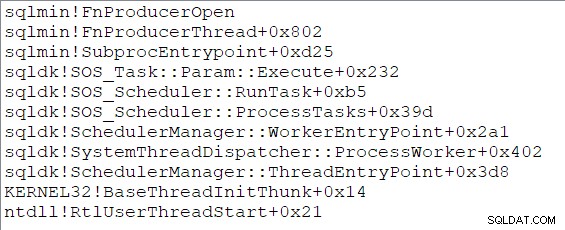
Sincronização do Exchange
Enquanto isso, a tarefa pai (executando em seu próprio thread de trabalho) registra os novos subprocessos com o gerenciador de subprocessos e aguarda no lado do consumidor dos fluxos de repartição são trocados no nó 5. A tarefa pai aguarda em
CXPACKET * até todos das tarefas paralelas da ramificação C completam seu Open chamadas e retornar ao lado do produtor da troca. As tarefas paralelas abrirão cada iterador em sua subárvore (ou seja, até a busca de índice no nó 9 e de volta) antes de retornar à troca de fluxos de repartição no nó 5. A tarefa pai aguardará em CXPACKET enquanto isso acontece. Lembre-se de que a tarefa pai está executando chamadas de fases iniciais. Podemos ver essa espera no DMV de tarefas em espera:

O contexto de execução zero (a tarefa pai) é bloqueado por ambos os novos contextos de execução. Esses contextos de execução são os primeiros adicionais a serem criados após o contexto zero, então eles recebem os números um e dois. Para enfatizar:Ambos os novos contextos de execução precisam abrir suas subárvores e retornar à troca do
CXPACKET da tarefa pai espere terminar. Você pode estar esperando ver
CXCONSUMER espera aqui, mas essa espera é reservada para aguardar em dados de linha chegar. A espera atual não é para linhas — cabe ao produtor abrir , então obtemos um CXPACKET genérico * esperar. * O Banco de Dados SQL do Azure e a Instância Gerenciada usam o novo
CXSYNC_PORT aguarde em vez de CXPACKET aqui, mas essa melhoria ainda não chegou ao SQL Server (a partir de 2019 CU9). Inspecionando as novas tarefas paralelas
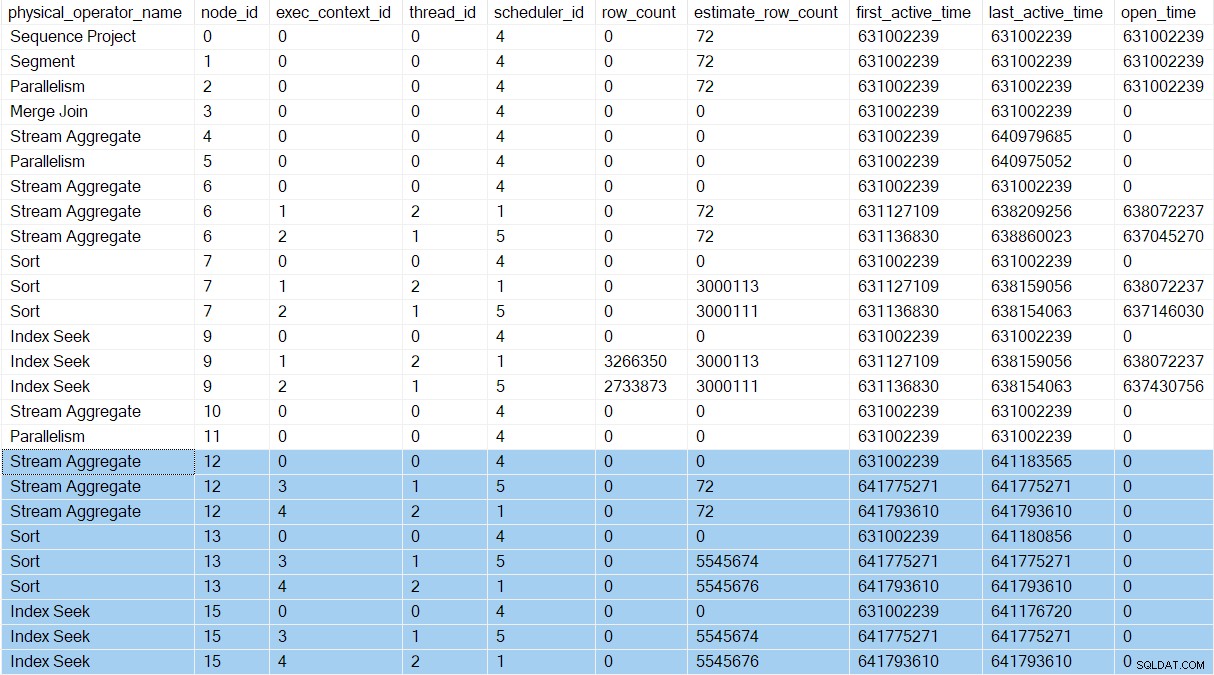
Podemos ver as novas tarefas nos perfis de consulta DMV. As informações de criação de perfil para as novas tarefas aparecem na DMV porque seus contextos de execução foram derivados (clonados e atualizados) do pai (contexto de execução zero):
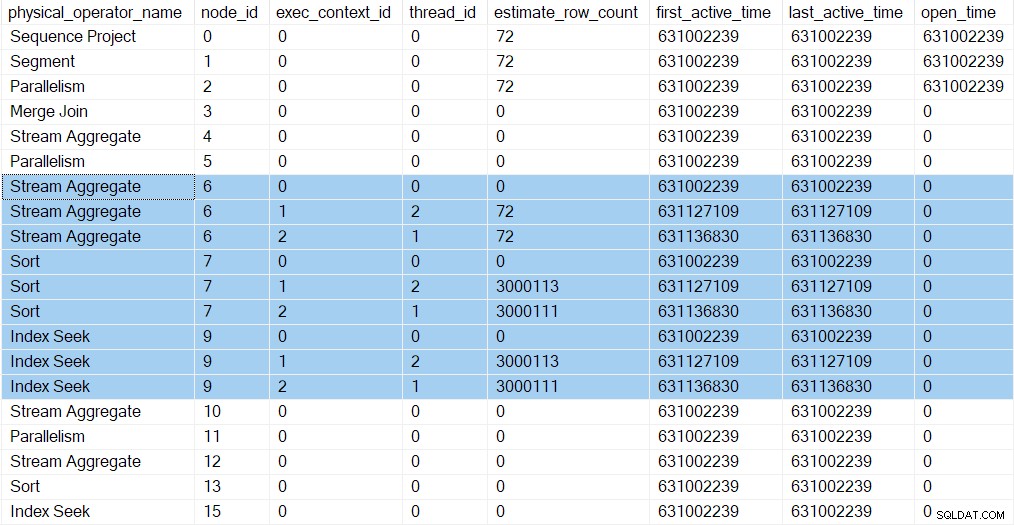
Existem agora três entradas para cada iterador no Ramo C (destacado). Um para a tarefa pai (contexto de execução zero) e um para cada nova tarefa paralela adicional (contextos 1 e 2). Observe que as contagens de linhas estimadas por thread (veja a parte 1) chegaram agora e são mostrados apenas para as tarefas paralelas. O primeiro e o último horário ativo pois as tarefas paralelas representam o momento em que seus contextos de execução foram criados. Nenhuma das novas tarefas foi aberta quaisquer iteradores ainda.
Os fluxos de partição exchange no nó 5 ainda possui apenas uma única entrada na saída do DMV. Isso ocorre porque o criador de perfil invisível associado monitora o consumidor lado da troca. As tarefas paralelas adicionais estão no produtor lado da troca. O lado do consumidor do nó 5 irá eventualmente temos tarefas paralelas, mas ainda não chegamos a esse ponto.
Ponto de verificação
Este parece ser um bom ponto para fazer uma pausa para respirar e resumir onde tudo está no momento. Haverá mais desses pontos de parada à medida que avançamos.
- A tarefa principal está no lado do consumidor da troca de fluxos de repartição no nó 5 , aguardando
CXPACKET. Está no meio da execução de chamadas de fases iniciais. Ele fez uma pausa para iniciar a Filial C porque essa ramificação contém uma classificação de bloqueio. A espera da tarefa pai continuará até que ambas as tarefas paralelas concluam a abertura de suas subárvores. - Duas novas tarefas paralelas no lado do produtor da troca do nó 5 estão prontos para abrir os iteradores na Filial C.
Nada fora do Ramo C deste plano de execução paralela pode avançar até que a tarefa pai seja liberada de seu
CXPACKET esperar. Lembre-se de que criamos apenas um conjunto de trabalhadores paralelos adicionais até agora, para a Filial C. A única outra thread é a tarefa pai, e ela está bloqueada. Execução paralela do Ramo C
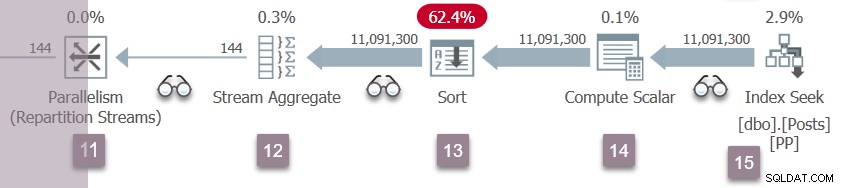
As duas tarefas paralelas começam no lado do produtor dos fluxos de repartição são trocados no nó 5. Cada um tem um plano separado (serial) com sua própria agregação de fluxo, classificação e busca de índice. A computação escalar não aparece no plano de tempo de execução porque seus cálculos são adiados para a classificação.
Cada instância da busca de índice tem reconhecimento paralelo e opera em conjuntos disjuntos de linhas. Esses conjuntos são gerados sob demanda do conjunto de linhas pai criado anteriormente pela tarefa pai (abordado na parte 1). Quando qualquer instância da busca precisa de um novo subintervalo de linhas, ela sincroniza com os outros threads de trabalho, de modo que apenas um esteja alocando um novo subintervalo ao mesmo tempo. O objeto de sincronização usado também foi criado anteriormente pela tarefa pai. Quando uma tarefa aguarda o acesso exclusivo ao conjunto de linhas pai para adquirir um novo subintervalo, ela aguarda
CXROWSET_SYNC . Tarefas da filial C abertas
A sequência de
Open chamadas para cada tarefa na Filial C é:CQScanXProducerNew::Open. Observe que não há um criador de perfil anterior no lado do produtor de uma troca. Isso é lamentável para os sintonizadores de consulta.CXTransLocal::OpenCXPort::RegisterCXTransLocal::ActivateWorkersCQScanProfileNew::Open. O criador de perfil acima do nó 6.CQScanStreamAggregateNew::Open(nó 6)CQScanProfileNew::Open. O criador de perfil acima do nó 7.CQScanSortNew::Open(nó 7)
A classificação é um operador totalmente bloqueador . Ele consome toda a sua entrada durante o
Open ligar. Há um grande número de detalhes internos interessantes para explorar aqui, mas o espaço é curto, então vou cobrir apenas os destaques:A classificação constrói sua tabela de classificação abrindo sua subárvore e consumindo todas as linhas que seus filhos podem fornecer. Depois que a classificação estiver concluída, a classificação estará pronta para fazer a transição para o modo de saída e retornará o controle ao pai. A classificação responderá posteriormente a
GetRow() chamadas, retornando a próxima linha classificada a cada vez. Uma pilha de chamadas ilustrativa durante a entrada de classificação é: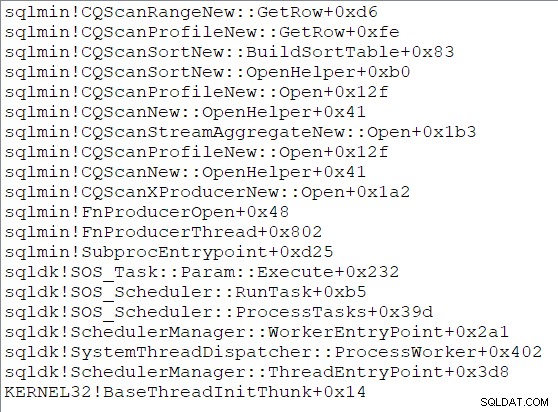
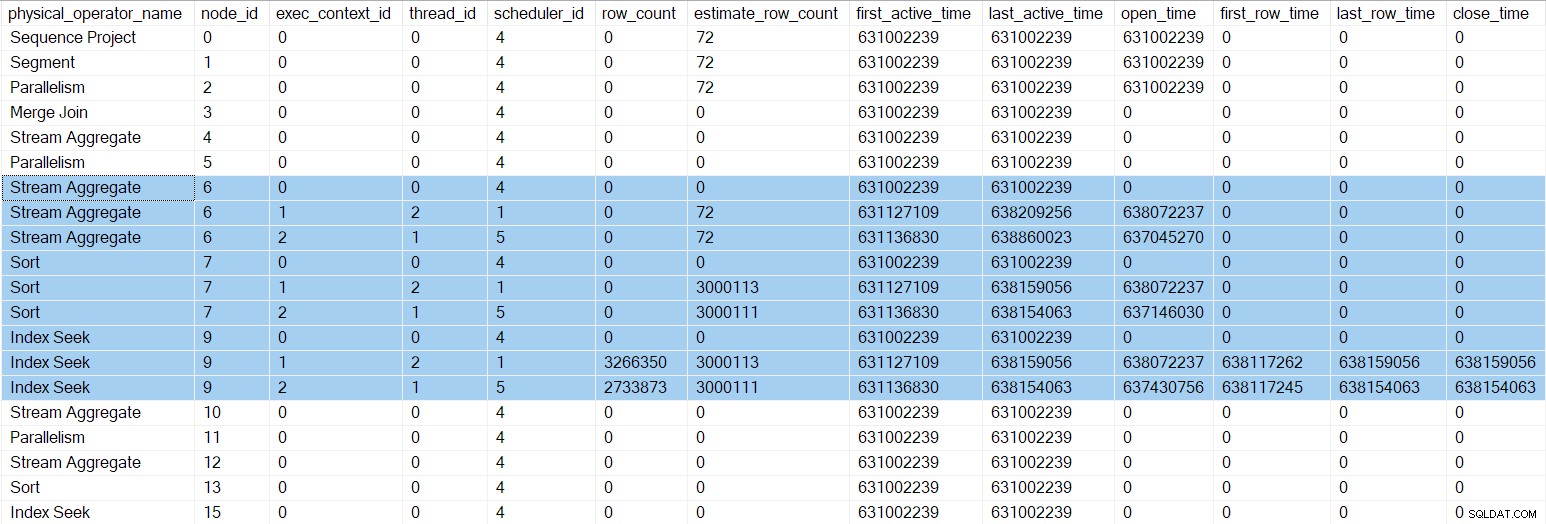
A execução continua até que cada classificação tenha consumido todas as (intervalos disjuntos de) linhas disponíveis de seu filho busca de índice . As ordenações então chamam
Close nas buscas de índice e retornar o controle ao agregado de fluxo pai . Os agregados de stream inicializam seus contadores e retornam o controle ao produtor lado da troca de repartição no nó 5. A sequência de Open agora está completo neste branch. O DMV de criação de perfil neste momento mostra números de tempo atualizados e horários de fechamento para o índice paralelo procura:
Mais sincronização de troca
Lembre-se de que a tarefa pai está aguardando o consumidor lado do nó 5 para todos os produtores abrirem. Um processo de sincronização semelhante agora acontece entre as tarefas paralelas no produtor lado da mesma troca:
Cada tarefa do produtor sincroniza com as outras via
CXTransLocal::Synchronize . Os produtores chamam CXPort::Open , então aguarde CXPACKET para todos lado do consumidor tarefas paralelas para abrir. Quando a primeira tarefa paralela da Filial C chega de volta ao lado do produtor da troca e espera, o DMV das tarefas em espera se parece com isso:
Ainda temos as esperas do lado do consumidor da tarefa pai. O novo
CXPACKET destaque é nossa primeira tarefa paralela do lado do produtor aguardando todas as tarefas paralelas do lado do consumidor para abrir a porta de câmbio. As tarefas paralelas do lado do consumidor (na Filial B) ainda não existem, portanto, a tarefa do produtor exibe NULL para o contexto de execução pelo qual está bloqueada. A tarefa atualmente aguardando no lado do consumidor da troca de fluxos de repartição é a tarefa pai (não uma tarefa paralela!) executando
EarlyPhases código, então não conta. A espera de CXPACKET da tarefa pai termina
Quando o segundo a tarefa paralela na Filial C chega de volta ao lado do produtor da troca de seu
Open chamadas, todos os produtores abriram a porta de troca, então a tarefa pai no lado do consumidor da troca é lançado de seu CXPACKET esperar. Os trabalhadores do lado do produtor continuam esperando que as tarefas paralelas do lado do consumidor sejam criadas e abram a porta de troca:

Ponto de verificação
Neste momento:
- Há um total de três tarefas:duas na Filial C, mais a tarefa pai.
- Ambos os produtores na troca do nó 5 foram abertos e estão aguardando em
CXPACKETpara que as tarefas paralelas do lado do consumidor sejam abertas. Grande parte da maquinaria de troca (incluindo buffers de linha) é criada pelo lado do consumidor, então não há lugar para os produtores colocarem linhas ainda. - As classificações na Filial C consumiram toda a entrada e estão prontos para fornecer saída classificada.
- As pesquisas de índice na Filial C concluíram seu trabalho e fecharam.
- A tarefa principal acaba de ser liberado da espera em
CXPACKETno lado do consumidor da troca de fluxos de repartição do nó 5. É ainda executandoEarlyPhasesaninhadas chamadas.
Início das tarefas paralelas do Ramo D
Este é o terceiro passo na sequência de execução:
- Ramo A (tarefa pai).
- Ramo C (tarefas paralelas adicionais).
- Ramo D (tarefas paralelas adicionais).
- Ramo B (tarefas paralelas adicionais).
Liberado de seu
CXPACKET aguarde no lado do consumidor da troca de fluxos de repartição no nó 5, a tarefa pai ascende a árvore de varredura de consulta do Ramo B. Ele retorna de EarlyPhases aninhadas chamadas para os vários iteradores e criadores de perfil na entrada externa (superior) da junção de mesclagem. Como mencionado, ascendente a árvore atualiza os tempos decorridos e de CPU registrados pelos iteradores de criação de perfil invisíveis. Estamos executando o código usando a tarefa pai, então esses números são registrados no contexto de execução zero. Esta é a fonte final dos números de tempo do “thread 0” mencionados em meu artigo anterior, Compreendendo os Tempos do Operador do Plano de Execução.
Uma vez de volta à junção de mesclagem, a tarefa pai chama
EarlyPhases para os iteradores e criadores de perfil na entrada interna (inferior) para a junção de mesclagem. Estes são nós de 10 a 15 (excluindo 14, que é diferido):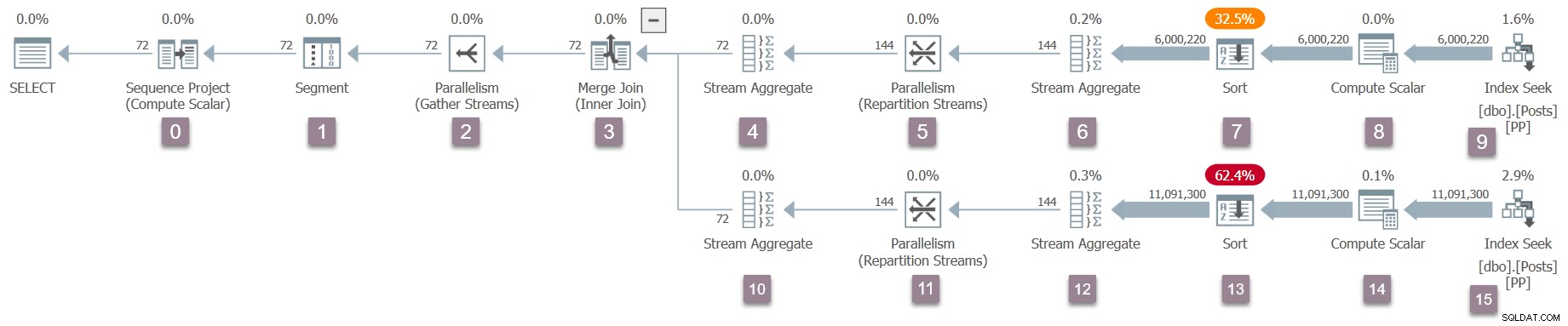
Uma vez que as chamadas de fases iniciais da tarefa pai atingem a busca de índice no nó 15, ela começa a subir na árvore novamente (definindo tempos de criação de perfil) até atingir a troca de fluxos de repartição no nó 11.
Então, assim como fez na entrada externa (superior) para a junção de mesclagem, ela inicia o lado do produtor da troca no nó 11 , criando duas novas tarefas paralelas .
Isso coloca o Ramo D em movimento (mostrado abaixo). A Filial D executa exatamente como já descrito em detalhes para a Filial C.
Imediatamente após iniciar as tarefas da Filial D, a tarefa pai aguarda em
CXPACKET no nó 11 para os novos produtores abrirem o porto de troca:
O novo
CXPACKET esperas são destacadas. Observe que o ID do nó relatado pode ser um pouco enganoso. A tarefa pai realmente está esperando no lado do consumidor do nó 11 (repartição de fluxos), não no nó 2 (reunir fluxos). Esta é uma peculiaridade do processamento de fase inicial. Enquanto isso, os threads do produtor no Branch C continuam aguardando em
CXPACKET para o lado do consumidor do nó 5 troca de fluxos de repartição para abrir. Abertura da filial D
Logo após a tarefa pai iniciar os produtores da Filial D, o perfil de consulta DMV mostra os novos contextos de execução (3 e 4):
As duas novas tarefas paralelas no Ramo D procedem exatamente como os do Ramo C. As ordenações consomem todas as suas entradas e as tarefas da Filial D retornam à troca. Isso libera a tarefa pai de seu
CXPACKET esperar. Os trabalhadores da Filial D aguardam em CXPACKET no lado do produtor do nó 11 para que as tarefas paralelas do lado do consumidor sejam abertas. Esses trabalhadores paralelos (na Filial B) ainda não existem. Ponto de verificação
As tarefas em espera neste ponto são mostradas abaixo:

Ambos os conjuntos de tarefas paralelas nas ramificações C e D estão aguardando em
CXPACKET para que seus consumidores de tarefas paralelas abram, nos nós de troca de fluxos de repartição 5 e 11, respectivamente. A única tarefa executável em toda a consulta agora está a tarefa pai . O DMV do criador de perfil de consulta neste momento é mostrado abaixo, com os operadores nos ramos C e D destacados:
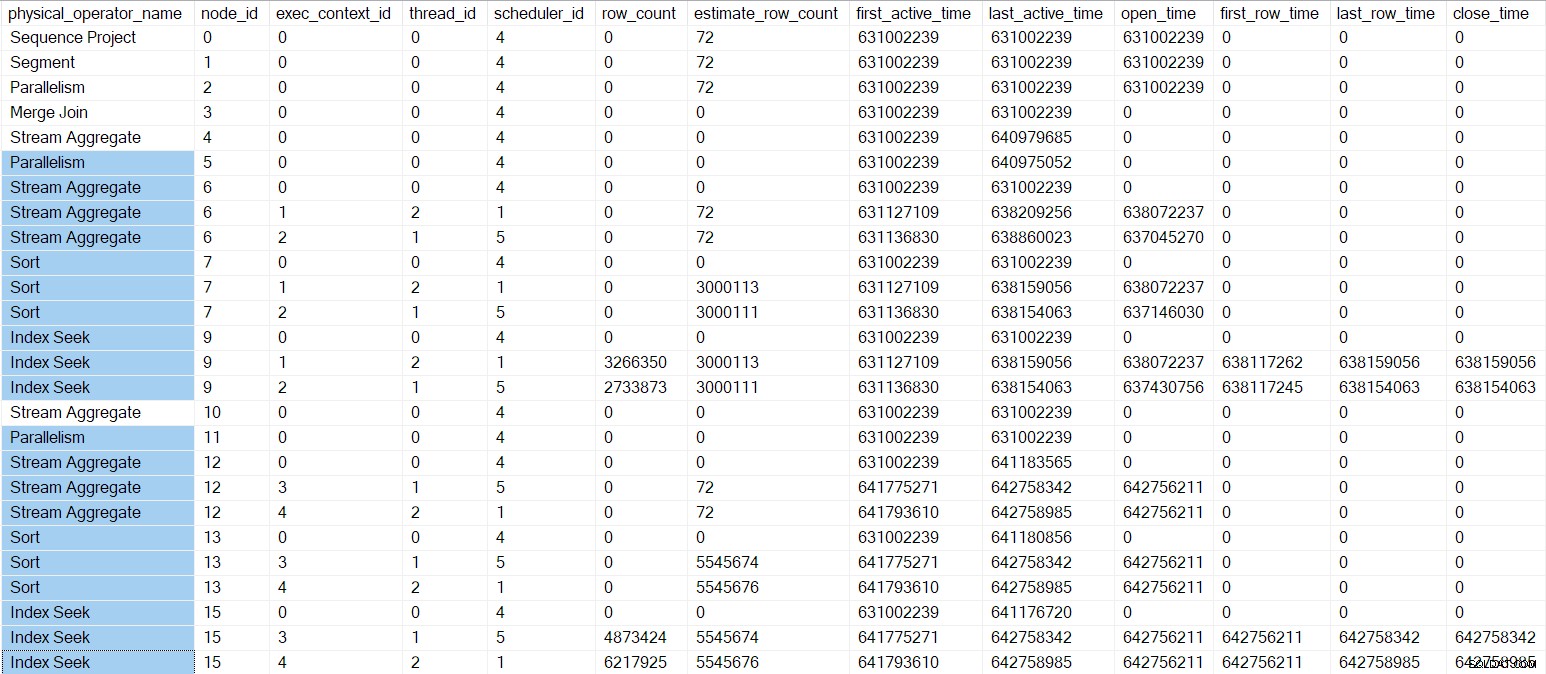
As únicas tarefas paralelas que ainda não iniciamos estão na Filial B. Todo o trabalho na Filial B até agora foram fases iniciais chamadas realizadas pela tarefa pai .
Fim da Parte 4
Na parte final desta série, descreverei como o restante desse plano de execução paralela específico é iniciado e abordarei brevemente como o plano retorna resultados. Concluirei com uma descrição mais geral que se aplica a planos paralelos de complexidade arbitrária.