Ter tabelas de referência em seu banco de dados não é grande coisa, certo? Você só precisa vincular um código ou ID a uma descrição para cada tipo de referência. Mas e se você literalmente tiver dezenas e dezenas de tabelas de referência? Existe uma alternativa para a abordagem de uma tabela por tipo? Continue lendo para descobrir um genérico e extensível design de banco de dados para lidar com todos os seus dados de referência.
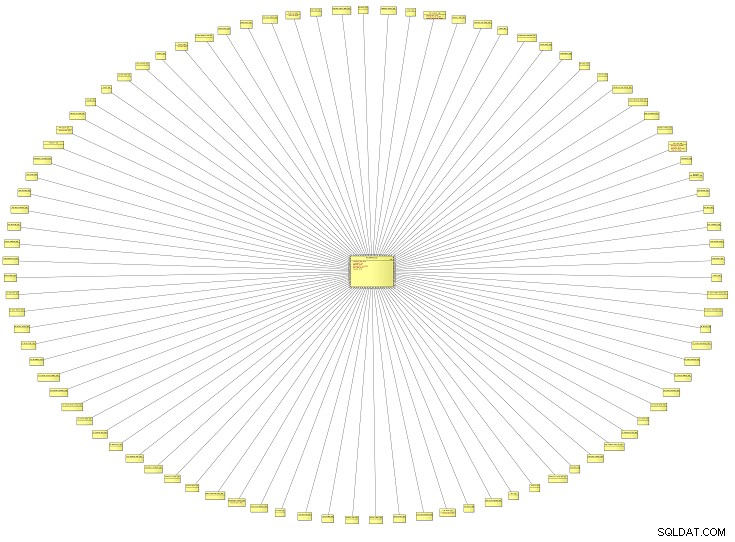
Este diagrama de aparência incomum é uma visão panorâmica de um modelo de dados lógicos (LDM) contendo todos os tipos de referência para um sistema corporativo. É de uma instituição de ensino, mas pode se aplicar ao modelo de dados de qualquer tipo de organização. Quanto maior o modelo, mais tipos de referência você provavelmente descobrirá.
Por tipos de referência quero dizer dados de referência, ou valores de pesquisa, ou – se você quiser ser flash – taxonomias . Normalmente, os valores definidos aqui são usados em listas suspensas na interface do usuário do seu aplicativo. Eles também podem aparecer como títulos em um relatório.
Este modelo de dados em particular tinha cerca de 100 tipos de referência. Vamos ampliar e ver apenas dois deles.
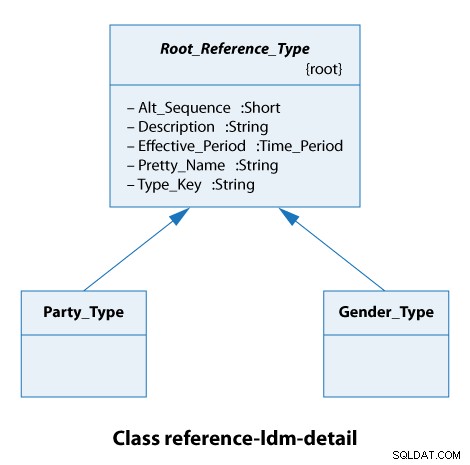
A partir deste diagrama de classes, vemos que todos os tipos de referência estendem o Root_Reference_Type . Na prática, isso significa apenas que todos os nossos tipos de referência têm os mesmos atributos de Alt_Sequence até Type_Key inclusive, como mostrado abaixo.
| Atributo | Descrição |
|---|---|
Alt_Sequence | Usado para definir uma sequência alternativa quando uma ordem não alfabética é necessária. |
Description | A descrição do tipo. |
Effective_Period | Define efetivamente se a entrada de referência está habilitada ou não. Uma vez que uma referência tenha sido usada, ela não pode ser excluída devido a restrições referenciais; ele só pode ser desativado. |
| O nome bonito para o tipo. Isso é o que o usuário vê na tela. |
Type_Key | A KEY interna exclusiva para o tipo. Isso está oculto para o usuário, mas os desenvolvedores de aplicativos podem fazer uso extensivo disso em seu SQL. |
O tipo de partido aqui é uma organização ou uma pessoa. Os tipos de gênero são masculino e feminino. Então, esses são casos muito simples.
A solução de tabela de referência tradicional
Então, como vamos implementar o modelo lógico no mundo físico de um banco de dados real?
Poderíamos considerar que cada tipo de referência será mapeado para sua própria tabela. Você pode se referir a isso como o mais tradicional uma tabela por classe solução. É bastante simples e ficaria mais ou menos assim:
A desvantagem disso é que pode haver dezenas e dezenas dessas tabelas, todas com as mesmas colunas, todas fazendo praticamente a mesma coisa.
Além disso, podemos estar criando muito mais trabalho de desenvolvimento . Se uma interface do usuário para cada tipo for necessária para que os administradores mantenham os valores, a quantidade de trabalho se multiplicará rapidamente. Não há regras rígidas e rápidas para isso - realmente depende do seu ambiente de desenvolvimento - então você precisará conversar com seus desenvolvedores para entender o impacto que isso tem.
Mas dado que todos os nossos tipos de referência têm os mesmos atributos, ou colunas, existe uma maneira mais genérica de implementar nosso modelo de dados lógicos? Sim existe! E requer apenas duas tabelas .
A solução de duas mesas
A primeira discussão que tive sobre esse assunto foi em meados dos anos 90, quando eu trabalhava para uma seguradora do London Market. Naquela época, fomos direto para o design físico e usamos principalmente chaves naturais/de negócios, não IDs. Onde existiam dados de referência, decidimos manter uma tabela por tipo composta por um código único (o VARCHAR PK) e uma descrição. Na verdade, havia muito menos tabelas de referência na época. Na maioria das vezes, um conjunto restrito de códigos de negócios seria usado em uma coluna, possivelmente com uma restrição de verificação de banco de dados definida; não haveria nenhuma tabela de referência.
Mas o jogo mudou desde então. Isto é o que uma solução de duas tabelas pode parecer:
Como você pode ver, esse modelo de dados físico é muito simples. Mas é bem diferente do modelo lógico, e não porque algo ficou em forma de pêra. É porque várias coisas foram feitas como parte do design físico .
O
reference_type table representa cada classe de referência individual do LDM. Portanto, se você tiver 20 tipos de referência em seu LDM, terá 20 linhas de metadados na tabela. O reference_value tabela contém os valores permitidos para todos os tipos de referência. Na época deste projeto, havia algumas discussões bastante animadas entre os desenvolvedores. Alguns preferiram a solução de duas tabelas e outros preferiram a uma tabela por tipo método.
Existem prós e contras para cada solução. Como você pode imaginar, os desenvolvedores estavam principalmente preocupados com a quantidade de trabalho que a interface do usuário levaria. Alguns pensaram que montar uma interface de usuário de administração para cada tabela seria bem rápido. Outros pensaram que construir uma única interface de usuário de administrador seria mais complexo, mas acabaria valendo a pena.
Neste projeto em particular, a solução de duas mesas foi favorecida. Vejamos com mais detalhes.
O padrão de dados de referência extensível e flexível
À medida que seu modelo de dados evolui com o tempo e novos tipos de referência são necessários, você não precisa continuar fazendo alterações em seu banco de dados para cada novo tipo de referência. Você só precisa definir novos dados de configuração. Para fazer isso, você adiciona uma nova linha ao
reference_type tabela e adicione sua lista controlada de valores permitidos ao reference_value tabela. Um conceito importante contido nesta solução é o de definir períodos de tempo efetivos para determinados valores. Por exemplo, sua organização pode precisar capturar um novo
reference_value de 'Prova de identidade' que será aceitável em alguma data futura. É uma simples questão de adicionar esse novo reference_value com o effective_period_from data definida corretamente. Isso pode ser feito com antecedência. Até essa data chegar, a nova entrada não aparecerá na lista suspensa de valores que os usuários do seu aplicativo veem. Isso ocorre porque seu aplicativo exibe apenas os valores atuais ou ativados. Por outro lado, pode ser necessário impedir que os usuários usem um determinado
reference_value . Nesse caso, basta atualizá-lo com o effective_period_to data definida corretamente. Quando esse dia passar, o valor não aparecerá mais na lista suspensa. Torna-se desabilitado a partir desse ponto. Mas como ainda existe fisicamente como uma linha na tabela, a integridade referencial é mantida para aquelas tabelas onde já foi referenciado. Agora que estávamos trabalhando na solução de duas tabelas, ficou claro que algumas colunas adicionais seriam úteis no
reference_type tabela. Estes centraram-se principalmente em preocupações com a interface do usuário. Por exemplo,
pretty_name no reference_type A tabela foi adicionada para uso na interface do usuário. É útil para grandes taxonomias usar uma janela com uma função de pesquisa. Então pretty_name poderia ser usado para o título da janela. Por outro lado, se uma lista suspensa de valores for suficiente,
pretty_name pode ser usado para o prompt LOV. De maneira semelhante, a descrição pode ser usada na interface do usuário para preencher a ajuda de rollover. Dando uma olhada no tipo de configuração ou metadados que vão para essas tabelas ajudará a esclarecer um pouco as coisas.
Como gerenciar tudo isso
Embora o exemplo usado aqui seja muito simples, os valores de referência para um grande projeto podem rapidamente se tornar bastante complexos. Portanto, pode ser aconselhável manter tudo isso em uma planilha. Nesse caso, você pode usar a própria planilha para gerar o SQL usando a concatenação de strings. Isso é colado em scripts, que são executados nos bancos de dados de destino que suportam o ciclo de vida de desenvolvimento e o banco de dados de produção (ao vivo). Isso semeia o banco de dados com todos os dados de referência necessários.
Aqui estão os dados de configuração para os dois tipos de LDM,
Gender_Type e Party_Type :PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
Há uma linha em reference_type para cada subtipo LDM de Root_Reference_Type . A descrição em reference_type é retirado da descrição da classe LDM. Para Gender_Type , isso seria "Identifica o gênero de uma pessoa". Os snippets DML mostram as diferenças nas descrições entre tipo e valor, que podem ser usadas na interface do usuário ou em relatórios.
Você verá que reference_type chamado Gender_Type foi alocado um intervalo de 13000000 a 13999999 para seu reference_value.ids associado . Neste modelo, cada reference_type é alocado um intervalo de IDs exclusivo e não sobreposto. Isso não é estritamente necessário, mas nos permite agrupar IDs de valor relacionados. Isso meio que imita o que você obteria se tivesse mesas separadas. É bom ter, mas se você acha que não há nenhum benefício nisso, pode dispensá-lo.
Outra coluna que foi adicionada ao PDM é admin_role . Aqui está o porquê.
Quem são os administradores
Algumas taxonomias podem ter valores adicionados ou removidos com pouco ou nenhum impacto. Isso ocorrerá quando nenhum programa fizer uso dos valores em sua lógica ou quando o tipo não tiver interface com outros sistemas. Nesses casos, é seguro para os administradores de usuários mantê-los atualizados.
Mas em outros casos, muito mais cuidado precisa ser exercido. Um novo valor de referência pode causar consequências não intencionais à lógica do programa ou aos sistemas downstream.
Por exemplo, suponha que adicionamos o seguinte à taxonomia Gender Type:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
Isso rapidamente se torna um problema se tivermos a seguinte lógica incorporada em algum lugar:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Claramente, a lógica "se você não é homem, deve ser mulher" não se aplica mais à taxonomia estendida.
É aqui que o admin_role coluna entra em jogo. Nasceu de discussões com os desenvolvedores sobre o design físico e funcionou em conjunto com a solução de interface do usuário. Mas se a solução de uma tabela por classe foi escolhida, então reference_type não teria existido. Os metadados contidos nele teriam sido codificados no aplicativo Gender_Type table – , que não é nem flexível nem extensível.
Somente usuários com o privilégio correto podem administrar a taxonomia. É provável que isso se baseie no conhecimento do assunto (PME ). Por outro lado, algumas taxonomias podem precisar ser administradas pela TI para permitir análise de impacto, testes completos e que quaisquer alterações de código sejam liberadas harmoniosamente a tempo para a nova configuração. (Se isso é feito por solicitações de mudança ou de alguma outra forma, depende da sua organização.)
Você deve ter notado que as colunas de auditoria created_by , created_date , updated_by e updated_date não são referenciados no script acima. Novamente, se você não estiver interessado neles, não precisará usá-los. Essa organização em particular tinha um padrão que obrigava a ter colunas de auditoria em todas as tabelas.
Acionadores:manter as coisas consistentes
Os acionadores garantem que essas colunas de auditoria sejam atualizadas de forma consistente, independentemente da origem do SQL (scripts, seu aplicativo, atualizações em lote agendadas, atualizações ad-hoc etc.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Minha formação é principalmente Oracle e, infelizmente, a Oracle limita os identificadores a 30 bytes. Para evitar exceder isso, cada tabela recebe um alias curto de três a cinco caracteres e outros artefatos relacionados à tabela usam esse alias em seus nomes. Então, reference_value o alias de é reva – os dois primeiros caracteres de cada palavra. Antes da inserção da linha e antes que a atualização de linha seja abreviada para bri e bru respectivamente. O nome da sequência reva_seq , e assim por diante.
Gatilhos de codificação manual como esse, tabela após tabela, exigem muito trabalho desmoralizante para os desenvolvedores. Felizmente, esses acionadores podem ser criados por meio da geração de código , mas isso é assunto para outro artigo!
A Importância das Chaves
A
ref_type_key e type_key colunas são limitadas a 30 bytes. Isso permite que eles sejam usados em consultas SQL do tipo PIVOT (no Oracle. Outros bancos de dados podem não ter a mesma restrição de comprimento de identificador). Como a exclusividade da chave é garantida pelo banco de dados e o gatilho garante que seu valor permaneça o mesmo para sempre, essas chaves podem – e devem – ser usadas em consultas e códigos para torná-las mais legíveis . O que quero dizer com isso? Bem, em vez de:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Você escreve:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
Basicamente, a chave explica claramente o que a consulta está fazendo .
Do LDM ao PDM, com espaço para crescer
A viagem de LDM para PDM não é necessariamente uma estrada reta. Nem é uma transformação direta de um para o outro. É um processo separado que apresenta suas próprias considerações e suas próprias preocupações.
Como você modela os dados de referência em seu banco de dados?