O particionamento é um recurso do SQL Server frequentemente implementado para aliviar os desafios relacionados à capacidade de gerenciamento, tarefas de manutenção ou bloqueio e bloqueio. A administração de tabelas grandes pode se tornar mais fácil com o particionamento e pode melhorar a escalabilidade e a disponibilidade. Além disso, um subproduto do particionamento pode melhorar o desempenho da consulta. Não é uma garantia ou um dado, e não é o motivo principal para implementar o particionamento, mas é algo que vale a pena revisar quando você particiona uma tabela grande.
Plano de fundo
Como uma revisão rápida, o recurso de particionamento do SQL Server está disponível apenas nas edições Enterprise e Developer. O particionamento pode ser implementado durante o projeto inicial do banco de dados ou pode ser implementado depois que uma tabela já contém dados. Entenda que alterar uma tabela existente com dados para uma tabela particionada nem sempre é rápido e simples, mas é bastante viável com um bom planejamento e os benefícios podem ser percebidos rapidamente.
Uma tabela particionada é aquela em que os dados são separados em estruturas físicas menores com base no valor de uma coluna específica (chamada de coluna de particionamento, que é definida na função de partição). Se você quiser separar os dados por ano, poderá usar uma coluna chamada DateSold como coluna de particionamento, e todos os dados de 2013 residiriam em uma estrutura, todos os dados de 2012 residiriam em uma estrutura diferente etc. Esses conjuntos separados de dados permitir a manutenção focada (você pode reconstruir apenas uma partição de um índice, em vez de todo o índice) e permitir que os dados sejam adicionados e removidos rapidamente porque podem ser preparados antes de serem adicionados ou removidos da tabela.
A configuração
Para examinar as diferenças no desempenho da consulta para uma tabela particionada versus uma não particionada, criei duas cópias da tabela Sales.SalesOrderHeader do banco de dados AdventureWorks2012. A tabela não particionada foi criada apenas com um índice clusterizado em SalesOrderID, a chave primária tradicional da tabela. A segunda tabela foi particionada em OrderDate, com OrderDate e SalesOrderID como a chave de cluster e não tinha índices adicionais. Observe que há vários fatores a serem considerados ao decidir qual coluna usar para particionamento. O particionamento frequentemente, mas certamente nem sempre, usa um campo de data para definir os limites da partição. Como tal, OrderDate foi selecionado para este exemplo e consultas de amostra foram usadas para simular a atividade típica na tabela SalesOrderHeader. As instruções para criar e preencher ambas as tabelas podem ser baixadas aqui.
Após criar as tabelas e adicionar os dados, os índices existentes foram verificados e as estatísticas atualizadas com o FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Além disso, ambas as tabelas têm exatamente a mesma distribuição de dados e fragmentação mínima.
Desempenho para uma consulta simples
Antes que quaisquer índices adicionais fossem adicionados, uma consulta básica foi executada em ambas as tabelas para calcular os totais ganhos pelo vendedor para pedidos feitos em dezembro de 2012:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOSAÍDA DE ESTATÍSTICAS IO
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Big_SalesOrderHeader'. Contagem de varredura 9, leituras lógicas 2710440, leituras físicas 2226, leituras antecipadas 2658769, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Part_SalesOrderHeader'. Contagem de varredura 9, leituras lógicas 248128, leituras físicas 3, leituras antecipadas 245030, leituras lógicas lob 0, leituras físicas 0, leituras antecipadas lob 0.

Totais por vendedor para dezembro – tabela não particionada
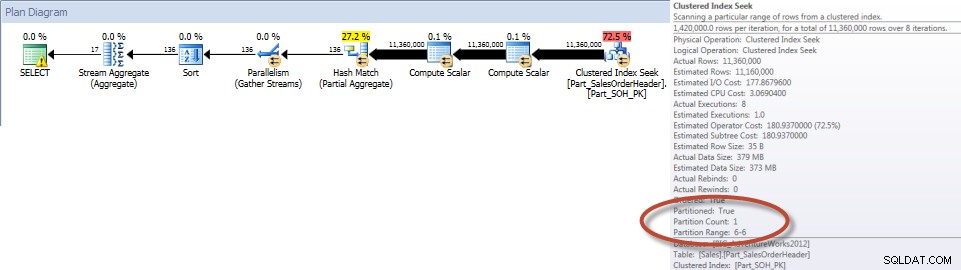
Totais por vendedor para dezembro – tabela particionada
Como esperado, a consulta na tabela não particionada teve que executar uma varredura completa da tabela, pois não havia índice para suportá-la. Por outro lado, a consulta na tabela particionada só precisava acessar uma partição da tabela.
Para ser justo, se esta fosse uma consulta executada repetidamente com diferentes intervalos de datas, o índice não clusterizado apropriado existiria. Por exemplo:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Com esse índice criado, quando a consulta é executada novamente, as estatísticas de E/S caem e o plano muda para usar o índice não clusterizado:
SAÍDA DE ESTATÍSTICAS IO
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Big_SalesOrderHeader'. Contagem de varredura 9, leituras lógicas 42901, leituras físicas 3, leituras antecipadas 42346, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.

Totais por vendedor para dezembro – NCI em tabela não particionada
Com um índice de suporte, a consulta em Sales.Big_SalesOrderHeader requer significativamente menos leituras do que a varredura de índice clusterizado em Sales.Part_SalesOrderHeader, o que não é inesperado, pois o índice clusterizado é muito mais amplo. Se criarmos um índice não clusterizado comparável para Sales.Part_SalesOrderHeader, veremos números de E/S semelhantes:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);SAÍDA DE ESTATÍSTICAS IO
Tabela 'Part_SalesOrderHeader'. Contagem de varredura 9, leituras lógicas 42894, leituras físicas 1, leituras antecipadas 42378, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
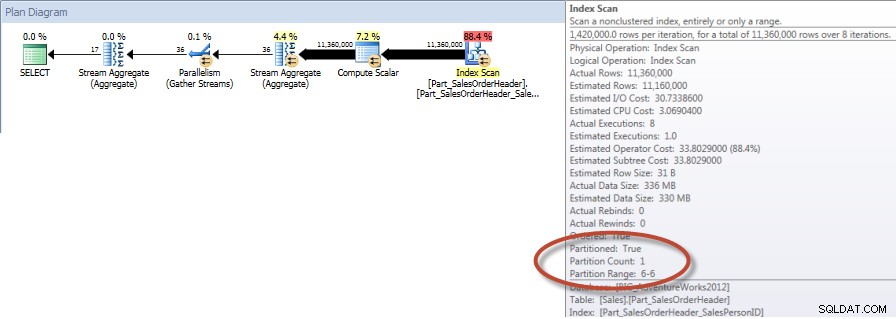
Totais por vendedor para dezembro – NCI em tabela particionada com eliminação
E se observarmos as propriedades do Index Scan não clusterizado, podemos verificar que o mecanismo acessou apenas uma partição (6).
Conforme declarado originalmente, o particionamento normalmente não é implementado para melhorar o desempenho. No exemplo mostrado acima, a consulta na tabela particionada não tem um desempenho significativamente melhor enquanto o índice não clusterizado apropriado existir.
Desempenho para uma consulta ad-hoc
Uma consulta na tabela particionada pode superam a mesma consulta em relação à tabela não particionada em alguns casos, por exemplo, quando a consulta precisa usar o índice clusterizado. Embora seja ideal ter a maioria das consultas suportadas por índices não clusterizados, alguns sistemas permitem consultas ad-hoc de usuários e outros têm consultas que podem ser executadas com tanta frequência que não justificam índices de suporte. Na tabela SalesOrderHeader, um usuário pode executar a seguinte consulta para localizar pedidos de dezembro de 2012 que precisavam ser enviados até o final do ano, mas não o fizeram, para um determinado conjunto de clientes e com um TotalDue superior a US$ 1.000:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOSAÍDA DE ESTATÍSTICAS IO
Tabela 'Big_SalesOrderHeader'. Contagem de varredura 9, leituras lógicas 2711220, leituras físicas 8386, leituras antecipadas 2662400, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Part_SalesOrderHeader'. Contagem de varredura 9, leituras lógicas 248128, leituras físicas 0, leituras antecipadas 243792, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
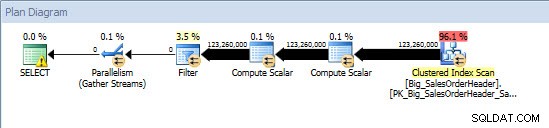
Consulta Ad-Hoc – Tabela não particionada
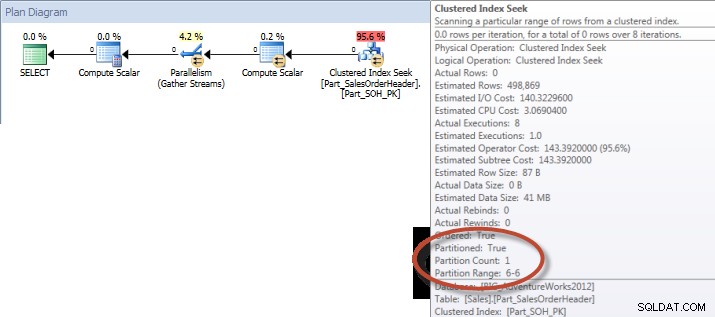
Consulta Ad-Hoc – Tabela Particionada
Na tabela não particionada, a consulta exigia uma verificação completa no índice clusterizado, mas na tabela particionada, a consulta executou uma busca de índice do índice clusterizado, pois o mecanismo usava a eliminação de partição e lia apenas os dados absolutamente necessários. Neste exemplo, é uma diferença significativa em termos de E/S e, dependendo do hardware, pode ser uma diferença dramática no tempo de execução. A consulta pode ser otimizada adicionando o índice apropriado, mas normalmente não é viável indexar para todos único inquerir. Em particular, para soluções que permitem consultas ad-hoc, é justo dizer que você nunca sabe o que os usuários vão fazer. Uma consulta pode ser executada uma vez e nunca mais ser executada, e criar um índice após o fato é inútil. Portanto, ao mudar de uma tabela não particionada para uma tabela particionada, é importante aplicar o mesmo esforço e abordagem do ajuste de índice regular; você deseja verificar se os índices apropriados existem para dar suporte à maioria das consultas.
Desempenho e alinhamento de índice
Um fator adicional a ser considerado ao criar índices para uma tabela particionada é alinhar o índice ou não. Os índices devem estar alinhados com a tabela se você planeja alternar dados para dentro e fora de partições. A criação de um índice não clusterizado em uma tabela particionada cria um índice alinhado por padrão, em que a coluna de particionamento é adicionada como uma coluna incluída ao índice.
Um índice não alinhado é criado especificando um esquema de partição diferente ou um grupo de arquivos diferente. A coluna de particionamento pode fazer parte do índice como uma coluna de chave ou uma coluna incluída, mas se o esquema de partição da tabela não for usado ou um grupo de arquivos diferente for usado, o índice não será alinhado.
Um índice alinhado é particionado exatamente como a tabela – os dados existirão em estruturas separadas – e, portanto, a eliminação da partição pode ocorrer. Um índice desalinhado existe como uma estrutura física e pode não fornecer o benefício esperado para uma consulta, dependendo do predicado. Considere uma consulta que conta as vendas por número de conta, agrupadas por mês:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Se você não estiver familiarizado com particionamento, poderá criar um índice como este para dar suporte à consulta (observe que o grupo de arquivos PRIMARY é especificado):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Este índice não está alinhado, embora inclua OrderDate porque faz parte da chave primária. As colunas também são incluídas se criarmos um índice alinhado, mas observe a diferença na sintaxe:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Podemos verificar quais colunas existem no índice usando o sp_helpindex da Kimberly Tripp:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex for Sales.Part_SalesOrderHeader
Quando executamos nossa consulta e a forçamos a usar o índice não alinhado, todo o índice é verificado. Embora OrderDate faça parte do índice, não é a coluna principal, portanto, o mecanismo deve verificar o valor OrderDate para cada AccountNumber para ver se ele cai entre 1º de janeiro de 2013 e 31 de julho de 2013:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);SAÍDA DE ESTATÍSTICAS IO
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Part_SalesOrderHeader'. Contagem de varredura 9, leituras lógicas 786861, leituras físicas 1, leituras antecipadas 770929, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
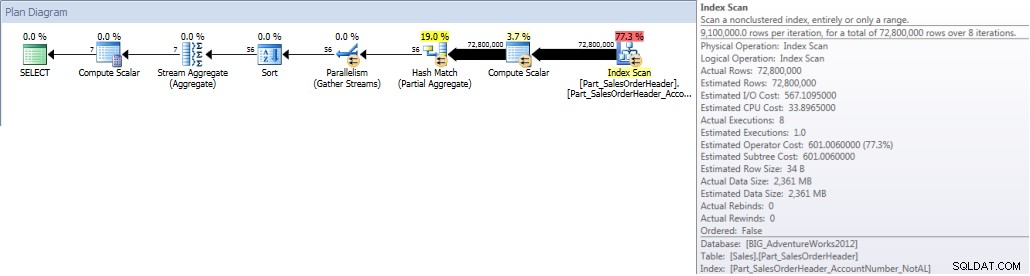
Totais da conta por mês (janeiro – julho de 2013) usando não NCI alinhado (forçado)
Por outro lado, quando a consulta é forçada a usar o índice alinhado, a eliminação de partição pode ser usada e menos E/Ss são necessárias, mesmo que OrderDate não seja uma coluna inicial no índice.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);SAÍDA DE ESTATÍSTICAS IO
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Part_SalesOrderHeader'. Contagem de varredura 9, leituras lógicas 456258, leituras físicas 16, leituras antecipadas 453241, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
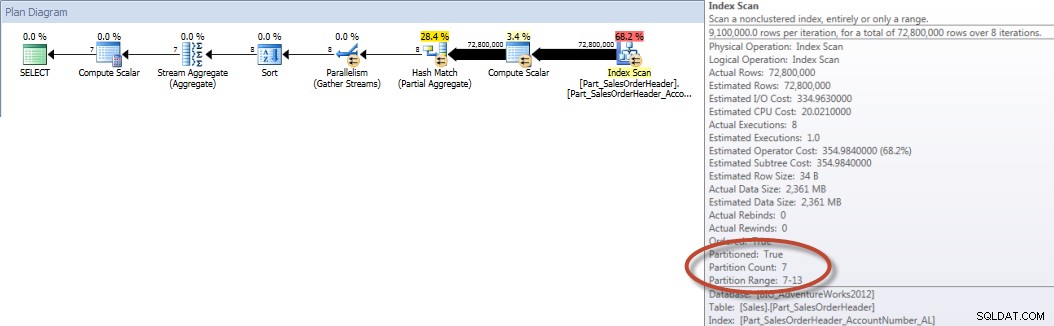
Totais da conta por mês (janeiro a julho de 2013) usando NCI alinhado (forçado)
Resumo
A decisão de implementar o particionamento requer a devida consideração e planejamento. Facilidade de gerenciamento, escalabilidade e disponibilidade aprimoradas e redução no bloqueio são motivos comuns para particionar tabelas. Melhorar o desempenho da consulta não é um motivo para empregar o particionamento, embora possa ser um efeito colateral benéfico em alguns casos. Em termos de desempenho, é importante garantir que seu plano de implementação inclua uma revisão do desempenho da consulta. Confirme se seus índices continuam a oferecer suporte adequado às suas consultas depois a tabela é particionada e verifique se as consultas que usam os índices clusterizados e não clusterizados se beneficiam da eliminação da partição, quando aplicável.



