No ano passado, Andy Mallon fez um blog sobre o aumento de uma coluna de
int para bigint sem tempo de inatividade. (Por que essa não é uma operação somente de metadados nas versões modernas do SQL Server está além de mim, mas isso é outro post.) Normalmente, quando lidamos com esse problema, elas são tabelas largas e massivas (tanto na contagem de linhas quanto no tamanho absoluto), e a coluna que precisamos alterar é a única/principal coluna na chave de clustering. Normalmente, também há outras complicações envolvidas - restrições de chave estrangeira de entrada, muitos índices não clusterizados e um banco de dados ocupado que é ultrassensível à atividade de log (porque está envolvido no controle de alterações, replicação, grupos de disponibilidade ou todos os três ).
Por esse motivo, precisamos adotar uma abordagem como a descrita por Andy, na qual construímos uma tabela de sombra com o novo esquema, criamos gatilhos para manter as duas cópias sincronizadas e, em seguida, lote/preenchimento no próprio ritmo dessa equipe até que eles estejam prontos para trocar na cópia como o negócio real.
Mas eu sou preguiçoso!
Existem alguns casos em que você pode alterar a coluna diretamente, se puder pagar uma pequena janela de tempo de inatividade/bloqueio, e isso se tornará uma operação muito mais simples. Na semana passada, um desses casos surgiu, com uma tabela com mais de 1 TB, mas apenas 100 mil linhas. Quase todos os dados estavam fora de linha (LOB), eles podiam arcar com uma pequena janela de tempo de inatividade, se necessário, e planejavam desabilitar o controle de alterações e reconfigurá-lo de qualquer maneira. Confiante de que a recriação do PK clusterizado não teria que mexer nos dados LOB (muito), sugeri que esse poderia ser um caso em que podemos aplicar a alteração diretamente.
Em um cenário isolado (sem chaves estrangeiras de entrada, sem índices adicionais, sem atividades dependendo do leitor de log e sem preocupações com simultaneidade), montei alguns testes para ver, no vácuo, o que essa mudança exigiria em termos de duração e impacto no log de transações. A principal pergunta que eu não sabia como responder com antecedência era:"Qual é o custo incremental da atualização de tabelas no local quando há grandes quantidades de dados não-chave?"
Vou tentar reunir muito em um post aqui. Fiz muitos testes e está tudo relacionado, mesmo que nem todos os cenários de teste se apliquem a você. Por favor, tenha paciência comigo.
As tabelas
Criei 6 tabelas, incluindo uma linha de base que somente tinha a coluna de chave, uma tabela com 4K armazenados em linha e, em seguida, quatro tabelas, cada uma com uma coluna varchar(max) preenchida com quantidades variadas de dados de string (4K, 16K, 64K e 256K).
CREATE TABLE dbo.withJustId( id int NOT NULL, CONSTRAINT pk_withJustId PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withoutLob( id int NOT NULL, extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob004( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob016( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)), CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob064 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)), CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob256 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)), CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id));
Eu preenchi cada uma com 100.000 linhas:
INSERT dbo.withJustId (id) SELECT TOP (100000) id =ROW_NUMBER() OVER (ORDER BY c1.name) FROM sys.all_columns AS c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob064 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
Reconheço que o acima é irreal; com que frequência temos uma tabela que é apenas um identificador + dados LOB? Executei os testes novamente com essas quatro colunas adicionais para dar às páginas de dados não LOB um pouco mais de substância do mundo real:
fill1 char(320) NOT NULL DEFAULT ('x'), count1 int NOT NULL DEFAULT (0), count2 int NOT NULL DEFAULT (0), dt datetime2 NOT NULL DEFAULT sysutcdatetime(),
Essas tabelas são apenas um pouco maiores em termos de tamanho geral, mas o aumento proporcional na quantidade de dados não LOB (não ilustrados neste gráfico) é a grande, mas oculta diferença:
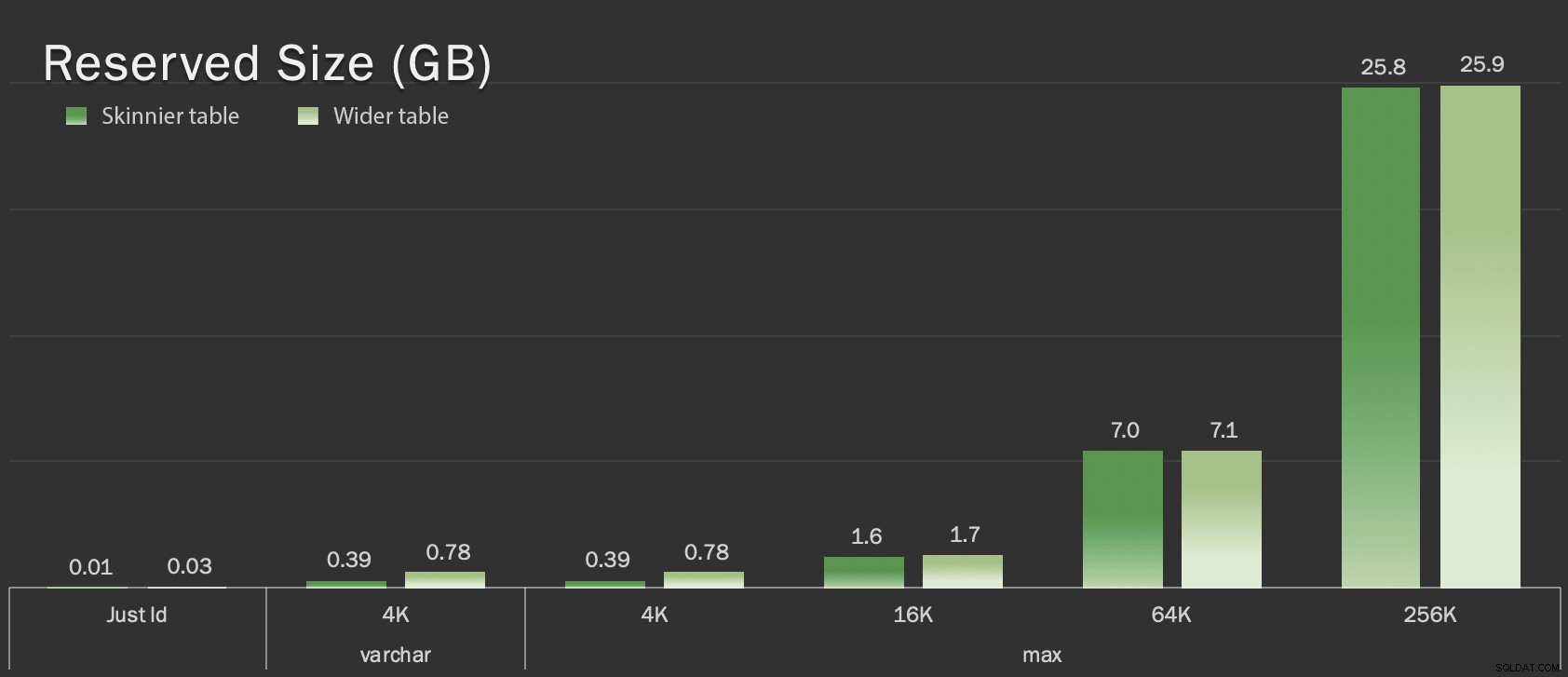 Tamanho reservado das tabelas, em GB
Tamanho reservado das tabelas, em GB
Os testes
Em seguida, cronometrei e coletei dados de log para cada uma dessas operações (com e sem ONLINE = ON ) contra cada variação da tabela:
ALTER TABLE dbo. DROP CONSTRAINT pk_; ALTER TABLE dbo. ALTER COLUMN id bigint NOT NULL; -- COM (ONLINE =ATIVADO); ALTER TABLE dbo. ADD CONSTRAINT pk_ PRIMARY KEY CLUSTERED (id);
Na realidade, eu usei SQL dinâmico para gerar todos esses testes, para que eu não ficasse mexendo nos scripts manualmente antes de cada teste.
Em outro post, compartilharei o SQL dinâmico que usei para gerar esses testes e coletar os tempos em cada etapa.
Para comparação, também testei o método de Andy (embora sem lotes, e apenas na versão magra da tabela):
CREATE TABLE dbo._copy ( id bigint NOT NULL -- <, coluna extradata quando relevante> CONSTRAINT pk_copy_ PRIMARY KEY CLUSTERED (id)); INSERT dbo._copy SELECT * FROM dbo.; EXEC sys.sp_rename N'dbo.', N'dbo._old', N'OBJECT';EXEC sys.sp_rename N'dbo._copy', N'dbo.' , N'OBJETO';
Eu pulei as mesas mais largas aqui; Eu não queria apresentar a complexidade de codificar e medir operações em lote. O ponto problemático óbvio aqui é que, ao contrário de alterar a coluna no local, com o método shadow, você precisa copiar cada byte desses dados LOB. O lote pode minimizar o grande impacto de tentar fazer isso em uma única transação, mas todo esse embaralhamento terá que ser refeito posteriormente. O lote na origem não pode controlar completamente o quanto isso prejudicará no destino.
Os resultados
Os primeiros resultados que vou mostrar são apenas as durações médias para alterações no local, para todas as 12 configurações de tabela, e com e sem ONLINE = ON :
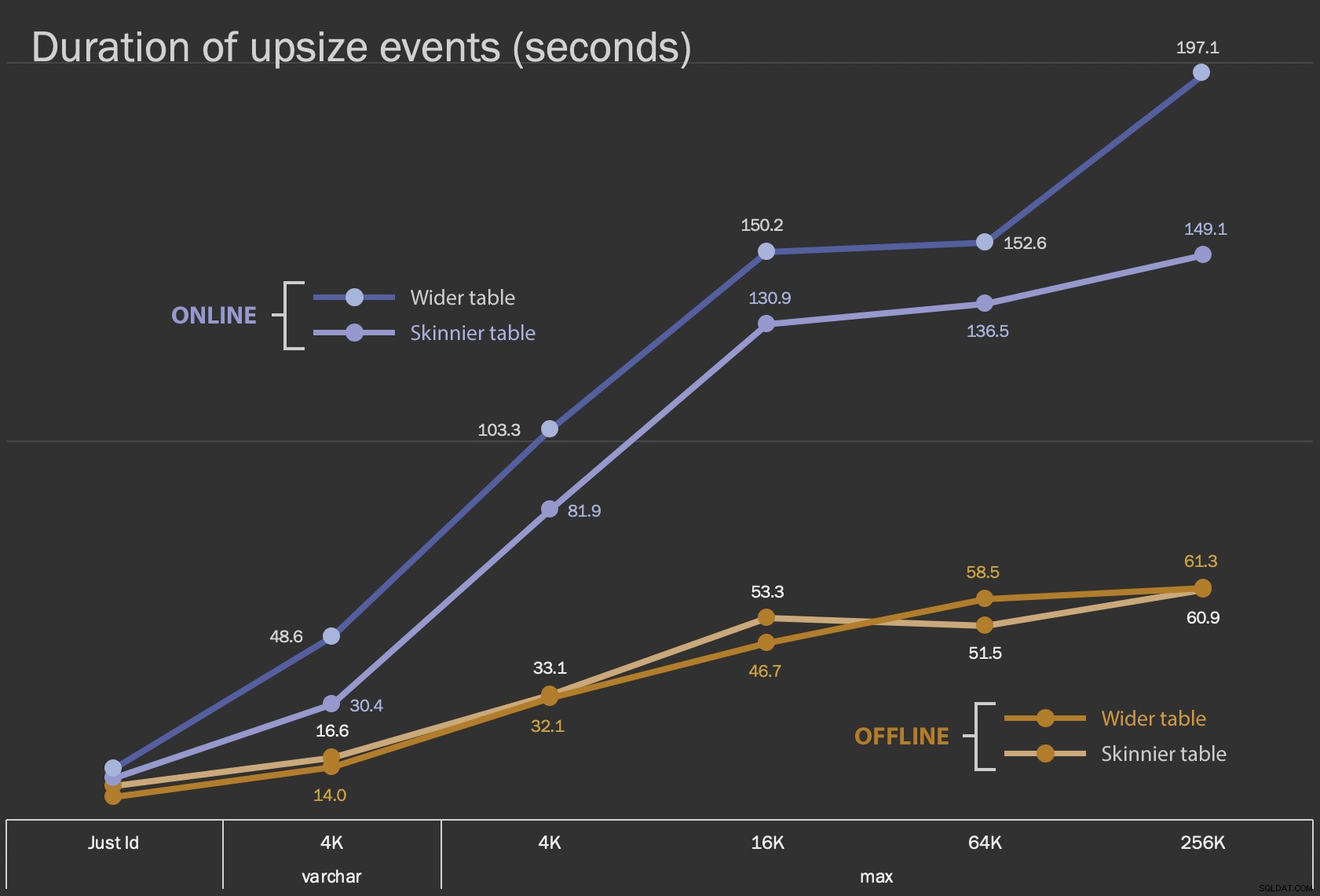 Duração, em segundos, da alteração da coluna no local
Duração, em segundos, da alteração da coluna no local
Executar isso como uma operação online leva mais tempo (200 segundos no pior caso), mas não bloqueia os usuários. Parece aumentar ao longo do tamanho, mas não de forma linear. Executar essa operação offline causa bloqueio, mas é muito mais rápido e não muda tão drasticamente à medida que a tabela aumenta (mesmo no tamanho maior, isso ainda aconteceu em cerca de um minuto).
Comparar essas operações in-loco com a operação de troca e descarte é difícil usando um gráfico de linhas devido à enorme diferença de escala. Em vez disso, mostrarei um gráfico de barras horizontais para a duração envolvida em cada configuração de tabela. Quando a recriação for mais rápida, pintarei o plano de fundo dessa linha de verde; quando é mais lento (ou fica entre os métodos offline e online), provavelmente não preciso, mas pintarei o plano de fundo dessa linha de vermelho.
| Tamanho do LOB | Abordagem | Configuração da tabela | Duração (segundos) | ||
|---|---|---|---|
| Apenas ID | ALTER off-line | Mesa mais fina (10 MB) | 8,8 |
| Tabela mais ampla (30 MB) | 6.3 | ||
| ALTER Online | Mesa mais fina | 11.0 | |
| Tabela mais ampla | 13,6 | ||
| Recriar | Mesa mais fina | 3.4 | |
| varchar 4K | Off-line | Mesa mais fina (390 MB) | 16,6 |
| Tabela mais ampla (780 MB) | 14.0 | ||
| On-line | Mesa mais fina | 30,4 | |
| Tabela mais ampla | 48,6 | ||
| Recriar | Mesa mais fina | 1.290,0 | |
| máximo de 4k | Off-line | Mesa mais fina (390 MB) | 33.1 |
| Tabela mais ampla (780 MB) | 32,1 | ||
| On-line | Mesa mais fina | 81,9 | |
| Tabela mais ampla | 103,3 | ||
| Recriar | Mesa mais fina | 28,9 | |
| máximo de 16k | Off-line | Mesa mais fina (1,6 GB) | 53,3 |
| Tabela mais ampla (1,7 GB) | 46,7 | ||
| On-line | Mesa mais fina | 130,9 | |
| Tabela mais ampla | 150,2 | ||
| Recriar | Mesa mais fina | 81,8 | |
| máximo de 64 mil | Off-line | Mesa mais fina (7,0 GB) | 51,5 |
| Tabela mais ampla (7,1 GB) | 58,5 | ||
| On-line | Mesa mais fina | 136,5 | |
| Tabela mais ampla | 152,6 | ||
| Recriar | Mesa mais fina | 226,5 | |
| máximo de 256 mil | Off-line | Mesa mais fina (25,8 GB) | 60,9 |
| Tabela mais ampla (25,9 GB) | 61,3 | ||
| On-line | Mesa mais fina | 149,1 | |
| Tabela mais ampla | 197,1 | ||
| Recriar | Mesa mais fina | 1.576,7 | |
Este é um golpe injusto no método de Andy, porque – no mundo real – você não estaria realizando toda a operação de uma só vez. Eu não mostrei o uso do log de transações aqui para brevidade, mas seria mais fácil controlar isso por meio de lotes em uma operação lado a lado também. Embora sua abordagem exija mais trabalho inicial, é muito mais segura em termos de tempo de inatividade e/ou bloqueio. Mas você pode ver nos casos em que você tem muitos dados fora da linha e pode pagar uma breve interrupção, que alterar a coluna diretamente é muito menos doloroso. "Grande demais para mudar no local" é subjetivo e pode produzir resultados diferentes, dependendo do significado de "grande". Antes de se comprometer com uma abordagem, pode fazer sentido testar a alteração em relação a uma cópia razoável, porque a operação no local pode representar uma compensação aceitável.
Conclusão
Não escrevi isso para discutir com Andy. A abordagem no post original é sólida, 100% confiável e a usamos o tempo todo. No entanto, quando a força bruta é mais valorizada do que a precisão cirúrgica, e especialmente se você puder reduzir o tempo de inatividade, pode haver valor na abordagem mais simples para determinados formatos de mesa.