Você já se deparou com uma situação em que precisa gerenciar o estado de uma entidade que muda ao longo do tempo? Há muitos exemplos por aí. Vamos começar com uma fácil:mesclar registros de clientes.
Suponha que estamos mesclando listas de clientes de duas fontes diferentes. Podemos ter qualquer um dos seguintes estados:Identificados de duplicatas – o sistema encontrou duas entidades potencialmente duplicadas; Duplicações confirmadas – um usuário valida que as duas entidades são de fato duplicatas; ou Exclusivo confirmado – o usuário decide que as duas entidades são únicas. Em qualquer uma dessas situações, o usuário tem apenas uma decisão sim ou não a tomar.
Mas e as situações mais complexas? Existe uma maneira de definir o fluxo de trabalho real entre os estados? Leia…
Como as coisas podem facilmente dar errado
Muitas organizações precisam gerenciar solicitações de emprego. Em um modelo simples, você pode ter uma tabela chamada
JOB_APPLICATION , e você pode rastrear o estado do aplicativo usando uma tabela de dados de referência contendo valores como estes:| Status do aplicativo |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Esses valores podem ser selecionados em qualquer ordem a qualquer momento. Ele depende dos usuários finais para garantir que uma seleção lógica e correta seja feita em cada estágio. Nada proíbe uma sequência ilógica de estados.
Por exemplo, digamos que um pedido foi rejeitado. O status atual obviamente seria
APPLICATION_REJECTED . Não há nada que possa ser feito no nível do aplicativo para evitar que um usuário inexperiente selecione posteriormente INVITED_TO_INTERVIEW ou algum outro estado ilógico. O que é necessário é algo para orientar o usuário na seleção do próximo estado lógico, algo que defina um fluxo de trabalho lógico .
E se você tiver requisitos diferentes para diferentes tipos de pedidos de emprego? Por exemplo, alguns empregos podem exigir que o candidato faça um teste de aptidão. Claro, você pode adicionar mais valores à lista para cobri-los, mas não há nada no design atual que impeça o usuário final de fazer uma seleção incorreta para o tipo de aplicativo em questão. A realidade é que existem fluxos de trabalho diferentes para contextos diferentes .
Outro ponto a se pensar:as opções listadas são realmente todos os estados ? Ou alguns são de fato resultados ? Por exemplo, a oferta de um emprego pode ser aceita ou rejeitada pelo candidato. Portanto,
JOB_OFFER_MADE realmente tem dois resultados:JOB_OFFER_ACCEPTED e JOB_OFFER_DECLINED . Outro resultado pode ser a retirada de uma oferta de emprego. Você pode querer registrar o motivo pelo qual foi retirado usando um qualificador. Se você apenas adicionar esses motivos à lista acima, nada orientará o usuário final a fazer seleções lógicas.
Então, quanto mais complexos os estados, resultados e qualificadores se tornam, mais você precisa definir o fluxo de trabalho de um processo .
Organização de processos, estados e resultados
É importante entender o que está acontecendo com seus dados antes de tentar modelá-los. A princípio, você pode estar inclinado a pensar que há uma hierarquia estrita de tipos aqui:
Quando olhamos mais de perto o exemplo acima, vemos que o
INVITED_TO_INTERVIEW e o JOB_OFFER_MADE estados compartilham os mesmos resultados possíveis, ou seja, ACCEPTED e DECLINED . Isso nos diz que há um relacionamento de muitos para muitos entre estados e resultados. Isso geralmente é verdade para outros estados, resultados e qualificadores. Em um nível conceitual, então, isso é o que realmente está acontecendo com nossos metadados:
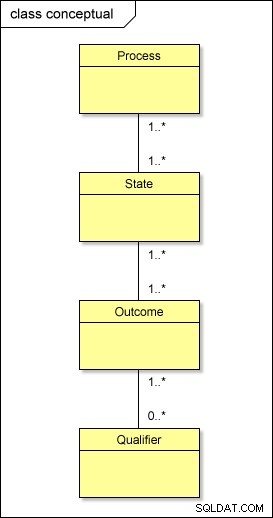
Se você transformasse esse modelo no mundo físico usando a abordagem padrão, você teria tabelas chamadas PROCESS , STATE , OUTCOME e QUALIFIER; você também precisaria ter tabelas intermediárias entre eles – PROCESS_STATE , STATE_OUTCOME e OUTCOME_QUALIFIER – para resolver os relacionamentos muitos-para-muitos . Isso complica o projeto.
Embora a hierarquia lógica de níveis (processo → estado → resultado → qualificador) deva ser mantida, existe uma maneira mais simples de organizar fisicamente nossos metadados.
O padrão de fluxo de trabalho
O diagrama abaixo define os principais componentes de um modelo de banco de dados de fluxo de trabalho:
As tabelas amarelas à esquerda contêm metadados de fluxo de trabalho e as tabelas azuis à direita contêm dados corporativos.
A primeira coisa a destacar é que qualquer entidade pode ser gerenciada sem exigir grandes mudanças neste modelo. O
YOUR_ENTITIY_TO_MANAGE table é a que está sob gerenciamento de fluxo de trabalho. Em termos de nosso exemplo, este seria o JOB_APPLICATION tabela. Em seguida, basta adicionar o
wf_state_type_process_id coluna para qualquer tabela que queremos gerenciar. Esta coluna aponta para o processo do fluxo de trabalho real sendo usado para gerenciar a entidade. Esta não é estritamente uma coluna de chave estrangeira, mas nos permite consultar rapidamente WORKFLOW_STATE_TYPE para o processo correto. A tabela que conterá o histórico de estado é MANAGED_ENTITY_STATE . Novamente, você escolheria seu próprio nome de tabela específico aqui e o modificaria para seus próprios requisitos. Os metadados
Os diferentes níveis de fluxo de trabalho são definidos em
WORKFLOW_LEVEL_TYPE . Esta tabela contém o seguinte:| Chave de tipo | Descrição |
|---|---|
| PROCESSO | Processo de fluxo de trabalho de alto nível. |
| ESTADO | Um estado no processo. |
| RESULTADO | Como termina um estado, seu resultado. |
| QUALIFICADOR | Um qualificador opcional e mais detalhado para um resultado. |
WORKFLOW_STATE_TYPE e WORKFLOW_STATE_HIERARCHY formar uma estrutura clássica de lista de materiais (BOM) . Essa estrutura, que é muito descritiva de uma lista de materiais de fabricação real, é bastante comum na modelagem de dados. Ele pode definir hierarquias ou ser aplicado a muitas situações recursivas. Vamos usá-lo aqui para definir nossa hierarquia lógica de processos, estados, resultados e qualificadores opcionais. Antes de podermos definir uma hierarquia, precisamos definir os componentes individuais. Estes são os nossos blocos de construção básicos. Vou apenas fazer referência a eles por
TYPE_KEY (que é único) por uma questão de brevidade. Para o nosso exemplo, temos:| Tipo de nível de fluxo de trabalho | Tipo de estado do fluxo de trabalho.Chave de tipo |
|---|---|
| RESULTADO | APROVADO |
| RESULTADO | FALHOU |
| RESULTADO | ACEITO |
| RESULTADO | RECUSADO |
| RESULTADO | CANDIDATE_CANCELLED |
| RESULTADO | EMPLOYER_CANCELLED |
| RESULTADO | REJEITADO |
| RESULTADO | EMPLOYER_WITHDRAWN |
| RESULTADO | NO_SHOW |
| RESULTADO | CONTRATADO |
| RESULTADO | NOT_HIRED |
| ESTADO | APPLICATION_RECEIVED |
| ESTADO | APPLICATION_REVIEW |
| ESTADO | INVITED_TO_INTERVIEW |
| ESTADO | ENTREVISTA |
| ESTADO | TEST_APTITUDE |
| ESTADO | SEEK_REFERENCES |
| ESTADO | MAKE_OFFER |
| ESTADO | APPLICATION_CLOSED |
| PROCESSO | STANDARD_JOB_APPLICATION |
| PROCESSO | TECHNICAL_JOB_APPLICATION |
Agora podemos começar a definir nossa hierarquia. É aqui que pegamos nossos blocos de construção e definimos nossa estrutura. Para cada estado, definimos os resultados possíveis. Na verdade, é uma regra desse sistema de fluxo de trabalho que cada estado deve terminar com um resultado:
| Tipo pai – ESTADOS | Tipo filho – RESULTADOS |
|---|---|
| APPLICATION_RECEIVED | ACEITO |
| APPLICATION_RECEIVED | REJEITADO |
| APLICAÇÃO_REVISÃO | APROVADO |
| APLICAÇÃO_REVISÃO | FALHOU |
| INVITED_TO_INTERVIEW | ACEITO |
| INVITED_TO_INTERVIEW | RECUSADO |
| ENTREVISTA | APROVADO |
| ENTREVISTA | FALHOU |
| ENTREVISTA | CANDIDATE_CANCELLED |
| ENTREVISTA | NO_SHOW |
| MAKE_OFFER | ACEITO |
| MAKE_OFFER | RECUSADO |
| SEEK_REFERENCES | APROVADO |
| SEEK_REFERENCES | FALHOU |
| APPLICATION_CLOSED | CONTRATADO |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | APROVADO |
| TEST_APTITUDE | FALHOU |
Nossos processos são simplesmente um conjunto de estados em que cada um existe por um período de tempo. Na tabela abaixo eles são apresentados em uma ordem lógica, mas isso não define a ordem real de processamento.
| Tipo pai – PROCESSOS | Tipo filho – ESTADOS |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | ENTREVISTA |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | ENTREVISTA |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_CLOSED |
Há um ponto importante a ser feito em relação a uma hierarquia de BOM. Assim como uma lista física de materiais define montagens e submontagens até os menores componentes, temos um arranjo semelhante em nossa hierarquia. Isso significa que podemos reutilizar 'montagens' e 'submontagens'.
A título de exemplo:Tanto o
STANDARD_JOB_APPLICATION e TECHNICAL_JOB_APPLICATION processos tem a INTERVIEW estado . Por sua vez, a INTERVIEW estado tem o PASSED , FAILED , CANDIDATE_CANCELLED e NO_SHOW resultados definido para isso. Quando você usa um estado em um processo, obtém automaticamente seus resultados filho com ele porque já é um assembly. Isso significa que existem os mesmos resultados para ambos os tipos de candidatura a emprego no
INTERVIEW etapa. Se você deseja resultados de entrevistas diferentes para diferentes tipos de candidaturas a empregos, você precisa definir, digamos, TECHNICAL_INTERVIEW e STANDARD_INTERVIEW afirma que cada um tem seus próprios resultados específicos. Neste exemplo, a única diferença entre os dois tipos de solicitação de emprego é que uma solicitação de emprego técnico inclui um teste de aptidão.
Antes de ir
A parte 1 deste artigo de duas partes introduziu o padrão de banco de dados de fluxo de trabalho. Mostrou como você pode incorporá-lo para gerenciar o ciclo de vida de qualquer entidade em seu banco de dados.
A Parte 2 mostrará como definir o fluxo de trabalho real usando tabelas de configuração adicionais. É aqui que o usuário verá as próximas etapas permitidas. Também demonstraremos uma técnica para contornar a reutilização estrita de 'montagens' e 'submontagens' em BOMs.