Os bancos de dados são projetados de maneiras diferentes. Na maioria das vezes podemos usar “exemplos escolares”:normalize o banco de dados e tudo funcionará bem. Mas há situações que exigirão outra abordagem. Podemos remover referências para ganhar mais flexibilidade. Mas e se tivermos que melhorar o desempenho quando tudo foi feito de acordo com o livro? Nesse caso, a desnormalização é uma técnica que devemos considerar. Neste artigo, discutiremos os benefícios e as desvantagens da desnormalização e quais situações podem justificá-la.
O que é desnormalização?
A desnormalização é uma estratégia usada em um banco de dados previamente normalizado para aumentar o desempenho. A ideia por trás disso é adicionar dados redundantes onde achamos que mais nos ajudarão. Podemos usar atributos extras em uma tabela existente, adicionar novas tabelas ou até mesmo criar instâncias de tabelas existentes. O objetivo usual é diminuir o tempo de execução de consultas selecionadas, tornando os dados mais acessíveis às consultas ou gerando relatórios resumidos em tabelas separadas. Este processo pode trazer alguns novos problemas, e vamos discuti-los mais tarde.
Um banco de dados normalizado é o ponto de partida para o processo de desnormalização. É importante diferenciar o banco de dados que não foi normalizado e o banco de dados que foi normalizado primeiro e depois desnormalizado. O segundo está bem; o primeiro é muitas vezes o resultado de um design de banco de dados ruim ou falta de conhecimento.
Exemplo:um modelo normalizado para um CRM muito simples
O modelo abaixo servirá como nosso exemplo:
Vamos dar uma olhada rápida nas tabelas:
- A
user_accounttable armazena dados sobre usuários que fazem login em nosso aplicativo (simplificando o modelo, as funções e os direitos do usuário são excluídos). - O
clienttabela contém alguns dados básicos sobre nossos clientes. - O
producttabela lista os produtos oferecidos aos nossos clientes. - A
tasktabela contém todas as tarefas que criamos. Você pode pensar em cada tarefa como um conjunto de ações relacionadas aos clientes. Cada tarefa tem suas chamadas relacionadas, reuniões e listas de produtos oferecidos e vendidos. - A
callemeetingas tabelas armazenam dados sobre todas as chamadas e reuniões e as relacionam com tarefas e usuários. - Os dicionários
task_outcome,meeting_outcomeecall_outcomecontêm todas as opções possíveis para o estado final de uma tarefa, reunião ou chamada. - O
product_offeredarmazena uma lista de todos os produtos que foram oferecidos aos clientes em determinadas tarefas enquantoproduct_soldcontém uma lista de todos os produtos que o cliente realmente comprou. - O
supply_orderA tabela armazena dados sobre todos os pedidos que fizemos e oproducts_on_ordertabela lista os produtos e suas quantidades para pedidos específicos. - A
writeofftabela é uma lista de produtos que foram baixados devido a acidentes ou similares (por exemplo, espelhos quebrados).
O banco de dados é simplificado, mas perfeitamente normalizado. Você não encontrará redundâncias e deve fazer o trabalho. Não devemos ter problemas de desempenho em nenhum caso, desde que trabalhemos com uma quantidade relativamente pequena de dados.
Quando e por que usar a desnormalização
Como em quase tudo, você deve ter certeza do motivo pelo qual deseja aplicar a desnormalização. Você também precisa ter certeza de que o lucro de usá-lo supera qualquer dano. Existem algumas situações em que você definitivamente deve pensar em desnormalização:
- Manter o histórico: Os dados podem mudar com o tempo e precisamos armazenar valores que eram válidos quando um registro foi criado. Que tipo de mudanças queremos dizer? Bem, o nome e o sobrenome de uma pessoa podem mudar; um cliente também pode alterar seu nome comercial ou quaisquer outros dados. Os detalhes da tarefa devem conter valores reais no momento em que uma tarefa foi gerada. Não seríamos capazes de recriar dados anteriores corretamente se isso não acontecesse. Poderíamos resolver esse problema adicionando uma tabela contendo o histórico dessas alterações. Nesse caso, uma consulta select retornando a tarefa e um nome de cliente válido se tornaria mais complicada. Talvez uma mesa extra não seja a melhor solução.
- Melhorando o desempenho da consulta: Algumas das consultas podem usar várias tabelas para acessar dados de que precisamos com frequência. Pense em uma situação em que precisaríamos juntar 10 mesas para retornar o nome do cliente e os produtos que foram vendidos a ele. Algumas tabelas ao longo do caminho também podem conter grandes quantidades de dados. Nesse caso, talvez seja sensato adicionar um
client_idatribua diretamente aoproducts_soldtabela. - Agilizando a geração de relatórios: Precisamos de certas estatísticas com muita frequência. Criá-los a partir de dados em tempo real é bastante demorado e pode afetar o desempenho geral do sistema. Digamos que queremos acompanhar as vendas de clientes ao longo de determinados anos para alguns ou todos os clientes. A geração desses relatórios a partir de dados ao vivo “cava” quase todo o banco de dados e o retardaria muito. E o que acontece se usarmos essa estatística com frequência?
- Cálculo antecipado de valores normalmente necessários: Queremos ter alguns valores já computados para que não precisemos gerá-los em tempo real.
É importante ressaltar que você não precisa usar a desnormalização se não houver problemas de desempenho na aplicação. Mas se você perceber que o sistema está desacelerando – ou se estiver ciente de que isso pode acontecer – então você deve pensar em aplicar essa técnica. Antes de prosseguir, porém, considere outras opções, como otimização de consulta e indexação adequada. Você também pode usar a desnormalização se já estiver em produção, mas é melhor resolver problemas na fase de desenvolvimento.
Quais são as desvantagens da desnormalização?
Obviamente, a maior vantagem do processo de desnormalização é o aumento do desempenho. Mas temos que pagar um preço por isso, e esse preço pode consistir em:
- Espaço em disco: Isso é esperado, pois teremos dados duplicados.
- Anomalias de dados: Temos que estar muito cientes do fato de que os dados agora podem ser alterados em mais de um lugar. Devemos ajustar cada parte dos dados duplicados de acordo. Isso também se aplica a valores calculados e relatórios. Podemos conseguir isso usando gatilhos, transações e/ou procedimentos para todas as operações que devem ser concluídas em conjunto.
- Documentação: Devemos documentar adequadamente todas as regras de desnormalização que aplicamos. Se modificarmos o design do banco de dados posteriormente, teremos que analisar todas as nossas exceções e levá-las em consideração novamente. Talvez não precisemos mais deles porque resolvemos o problema. Ou talvez precisemos adicionar regras de desnormalização existentes. (Por exemplo:adicionamos um novo atributo à tabela cliente e queremos armazenar seu valor de histórico junto com tudo o que já armazenamos. Teremos que alterar as regras de desnormalização existentes para conseguir isso).
- Retardar outras operações: Podemos esperar que desaceleraremos as operações de inserção, modificação e exclusão de dados. Se essas operações acontecerem relativamente raramente, isso pode ser um benefício. Basicamente, dividiríamos uma seleção lenta em um número maior de consultas de inserção/atualização/exclusão mais lentas. Embora uma consulta de seleção muito complexa tecnicamente possa desacelerar notavelmente todo o sistema, desacelerar várias operações “menores” não deve prejudicar a usabilidade do nosso aplicativo.
- Mais codificação: As regras 2 e 3 exigirão codificação adicional, mas ao mesmo tempo simplificarão muito algumas consultas selecionadas. Se estivermos desnormalizando um banco de dados existente, teremos que modificar essas consultas selecionadas para obter os benefícios do nosso trabalho. Também teremos que atualizar valores em atributos recém-adicionados para registros existentes. Isso também exigirá um pouco mais de codificação.
O modelo de exemplo, desnormalizado
No modelo abaixo, apliquei algumas das regras de desnormalização mencionadas anteriormente. As mesas rosa foram modificadas, enquanto a mesa azul claro é completamente nova.
Quais alterações são aplicadas e por quê?

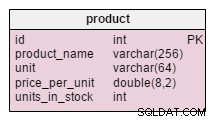
A única alteração no product table é a adição do units_in_stock atributo. Em um modelo normalizado, poderíamos calcular esses dados como unidades encomendadas – unidades vendidas – (unidades oferecidas) – unidades baixadas . Repetiríamos o cálculo cada vez que um cliente solicitasse aquele produto, o que consumiria muito tempo. Em vez disso, calcularemos o valor antecipadamente; quando um cliente nos pede, nós o preparamos. Claro, isso simplifica muito a consulta de seleção. Por outro lado, o units_in_stock atributo deve ser ajustado após cada inserção, atualização ou exclusão no products_on_order , writeoff , product_offered e product_sold mesas.
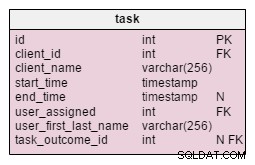
Na task tabela, encontramos dois novos atributos:client_name e user_first_last_name . Ambos armazenam valores quando a tarefa foi criada. A razão é que ambos os valores podem mudar com o tempo. Também manteremos uma chave estrangeira que os relacione ao cliente original e ao ID do usuário. Existem mais valores que gostaríamos de armazenar, como endereço do cliente, ID do IVA, etc.




O product_offered tabela tem dois novos atributos, price_per_unit e price . O price_per_unit O atributo é armazenado porque precisamos armazenar o preço real quando o produto foi oferecido . O modelo normalizado mostraria apenas seu estado atual, portanto, quando o preço do produto muda, nossos preços de 'histórico' também mudam. Nossa mudança não apenas torna o banco de dados mais rápido:também o faz funcionar melhor. O price atributo é o valor calculado units_sold * price_per_unit . Eu o adicionei aqui para evitar fazer esse cálculo toda vez que quisermos dar uma olhada em uma lista de produtos oferecidos. É um custo pequeno, mas melhora o desempenho.
As alterações feitas no product_sold tabela são muito semelhantes. A estrutura da tabela é a mesma, mas armazena uma lista de itens vendidos.
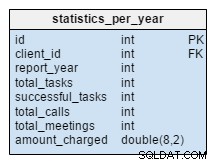
As statistics_per_year mesa é completamente nova para o nosso modelo. Devemos olhar para ela como uma tabela desnormalizada porque todos os seus dados podem ser calculados a partir de outras tabelas. A ideia por trás desta tabela é armazenar o número de tarefas, tarefas bem-sucedidas, reuniões e chamadas relacionadas a um determinado cliente. Ele também lida com a soma total cobrada por cada ano. Depois de inserir, atualizar ou excluir qualquer coisa na task , meeting , call e product_sold tabelas, devemos recalcular os dados dessa tabela para esse cliente e ano correspondente. Podemos esperar que teremos mudanças principalmente apenas para o ano atual. Os relatórios de anos anteriores não precisam ser alterados.
Os valores nesta tabela são calculados antecipadamente, portanto, gastaremos menos tempo e recursos no momento em que precisarmos do resultado do cálculo. Pense nos valores que você precisará com frequência. Talvez você não precise de todos eles regularmente e possa arriscar computar alguns deles ao vivo.
A desnormalização é um conceito muito interessante e poderoso. Embora não seja o primeiro que você deve ter em mente para melhorar o desempenho, em algumas situações pode ser a melhor ou mesmo a única solução.
Antes de optar por usar a desnormalização, certifique-se de que a deseja. Faça algumas análises e acompanhe o desempenho. Você provavelmente decidirá seguir com a desnormalização depois de já ter entrado no ar. Não tenha medo de usá-lo, mas acompanhe as alterações e você não deve ter problemas (ou seja, as temidas anomalias de dados).