[ Parte 1 | Parte 2 | Parte 3]
Na parte 1, mostrei como a compactação de página e coluna pode reduzir o tamanho de uma tabela de 1 TB em 80% ou mais. Embora tenha ficado impressionado por poder reduzir uma tabela de 1 TB para 50 GB, não fiquei muito feliz com o tempo que levou (de 2 a 14 horas). Com algumas dicas gentilmente emprestadas de pessoas como Joe Obbish, Lonny Niederstadt, Niko Neugebauer e outros, neste post tentarei fazer algumas mudanças na minha tentativa original de obter um melhor desempenho de carregamento. Como o índice columnstore regular não foi compactado melhor do que a compactação de página neste conjunto de dados , e levou 13 horas a mais para chegar lá, vou me concentrar apenas na solução mais avançada usando
COLUMNSTORE_ARCHIVE compressão. Alguns dos problemas que acho que afetaram o desempenho incluem o seguinte:
- Escolhas de layout de arquivo ruins – Coloquei 8 arquivos em um grupo de arquivos, com paralelismo, mas sem particionamento (ou abaixo do ideal), espalhando E/S em vários arquivos com abandono imprudente. Para resolver isso, vou:
- particione a tabela em 8 partições (uma por núcleo)
- coloque o arquivo de dados de cada partição em seu próprio grupo de arquivos
- use 8 processos separados para se afinizar com cada partição
- usar compactação de arquivo em todas as partições, exceto a "ativa"
- muitos lotes pequenos e população de grupos de linhas abaixo do ideal – processando 10 milhões de linhas por vez, eu estava preenchendo nove rowgroups com 1.048.576 linhas, e as 562.816 linhas restantes terminariam em outro rowgroup menor. E quaisquer distribuições desiguais que deixassem um resto <102.400 linhas levariam inserções para a estrutura de armazenamento delta menos eficiente. Para distribuir as linhas de maneira mais uniforme e evitar o armazenamento delta, vou:
- processe o máximo de dados possível em múltiplos exatos de 1.048.576 linhas
- distribua-os em 8 partições da maneira mais uniforme possível
- use um tamanho de lote mais próximo de 10x -> 100 milhões de linhas
- empilhamento do agendador – embora eu não tenha verificado isso, é possível que parte da lentidão tenha sido causada por um agendador assumindo muito trabalho e outro agendador insuficiente, devido ao round-robining do agendador. Agora que estarei carregando intencionalmente os dados com 8 processos maxdop 1 em vez de um processo maxdop 8, para manter todos os agendadores igualmente ocupados, vou:
- usar um procedimento armazenado que tenta equilibrar uniformemente os agendadores (consulte as páginas 189-191 no Guia do SQLCAT para:Mecanismo Relacional para obter a inspiração por trás dessa ideia)
- ative o sinalizador de rastreamento global 2467 e 2469, conforme alertado na documentação
- tarefa de compactação de armazenamento de colunas em segundo plano – foi um desperdício permitir que isso fosse executado durante a população, já que eu planejava reconstruir no final de qualquer maneira. Desta vez eu vou:
- desative esta tarefa usando o sinalizador de rastreamento global 634
Eu descartei a função e o esquema de partição inicial e construí um novo baseado em uma distribuição mais uniforme dos dados. Eu quero que 8 partições correspondam ao número de núcleos e ao número de arquivos de dados, para maximizar o "paralelismo do pobre homem" que pretendo usar.
Primeiro, precisamos criar um novo conjunto de grupos de arquivos, cada um com seu próprio arquivo:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
Em seguida, observei o número de linhas na tabela:3.754.965.954. Para distribuir esses exatamente uniformemente em 8 partições, seriam 469.370.744,25 linhas por partição. Para que funcione bem, vamos fazer com que os limites da partição acomodem o próximo múltiplo de 1.048.576 linhas. Este é
1,048,576 x 448 = 469,762,048 – que seria o número de linhas que disparamos nas primeiras 7 partições, deixando 466.631.618 linhas na última partição. Para ver o OID real valores que serviriam como limites para conter o número ideal de linhas em cada partição, executei essa consulta na tabela original (já que demorou 25 minutos para ser executada, aprendi rapidamente a despejar esses resultados em uma tabela separada):;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0; 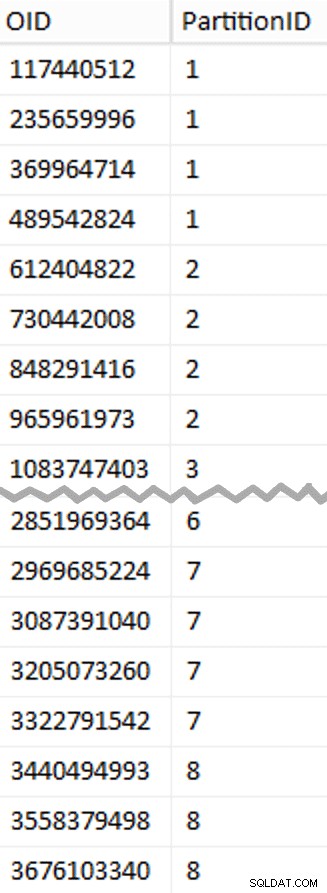 Mais para descompactar aqui do que você poderia esperar. O CTE faz todo o trabalho pesado, já que ele precisa escanear toda a tabela de 1,14 TB e atribuir um número de linha a cada linha . Eu só quero retornar a cada
Mais para descompactar aqui do que você poderia esperar. O CTE faz todo o trabalho pesado, já que ele precisa escanear toda a tabela de 1,14 TB e atribuir um número de linha a cada linha . Eu só quero retornar a cada (1048576*112)th linha, no entanto, como essas são minhas linhas de limite de lote, então é isso que o WHERE cláusula faz. Lembre-se de que quero dividir o trabalho em lotes mais próximos de 100 milhões de linhas por vez, mas também não quero processar 469 milhões de linhas de uma só vez. Portanto, além de dividir os dados em 8 partições, quero dividir cada uma dessas partições em quatro lotes de 117.440.512 (1,048,576*112) linhas. Cada conjunto adjacente de quatro lotes pertence a uma partição, então o PartitionID Eu derivo apenas adiciona um ao resultado do número da linha atual inteiro dividido por (1,048,576*448) , que garante que o limite esteja sempre no conjunto "esquerdo". Em seguida, adicionamos um ao resultado porque, caso contrário, estaríamos nos referindo a uma coleção de partições baseada em 0, e ninguém quer isso. Ok, isso foi um monte de palavras. À direita está uma imagem mostrando o conteúdo (abreviado) do
stage tabela (clique para mostrar o resultado completo, destacando os valores de limite de partição). Podemos então derivar outra consulta dessa tabela de preparo que nos mostra os valores mínimo e máximo para cada lote dentro de cada partição, bem como o lote extra não contabilizado (as linhas na tabela original com
OID maior que o valor limite mais alto):;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); Esses valores ficam assim:
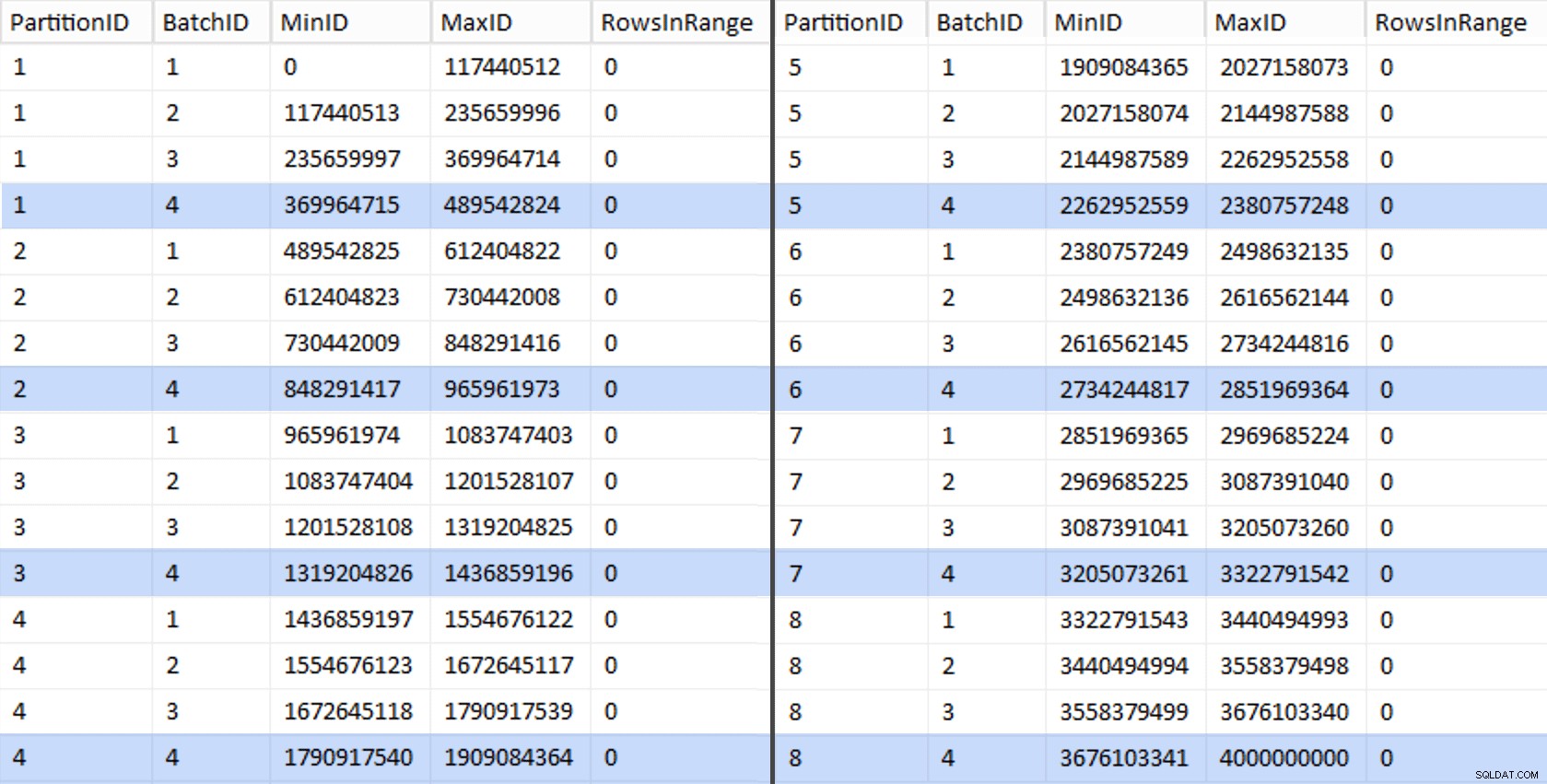
Para testar nosso trabalho, podemos derivar daí um conjunto de consultas que atualizarão
BatchQueue com as contagens de linhas reais da tabela. DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; Isso levou cerca de 6 minutos no meu sistema. Em seguida, você pode executar a seguinte consulta para mostrar que cada lote, exceto o último, é capaz de preencher totalmente os rowgroups e não deixar nenhum restante para o uso potencial do armazenamento delta:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Agora a tabela está assim:
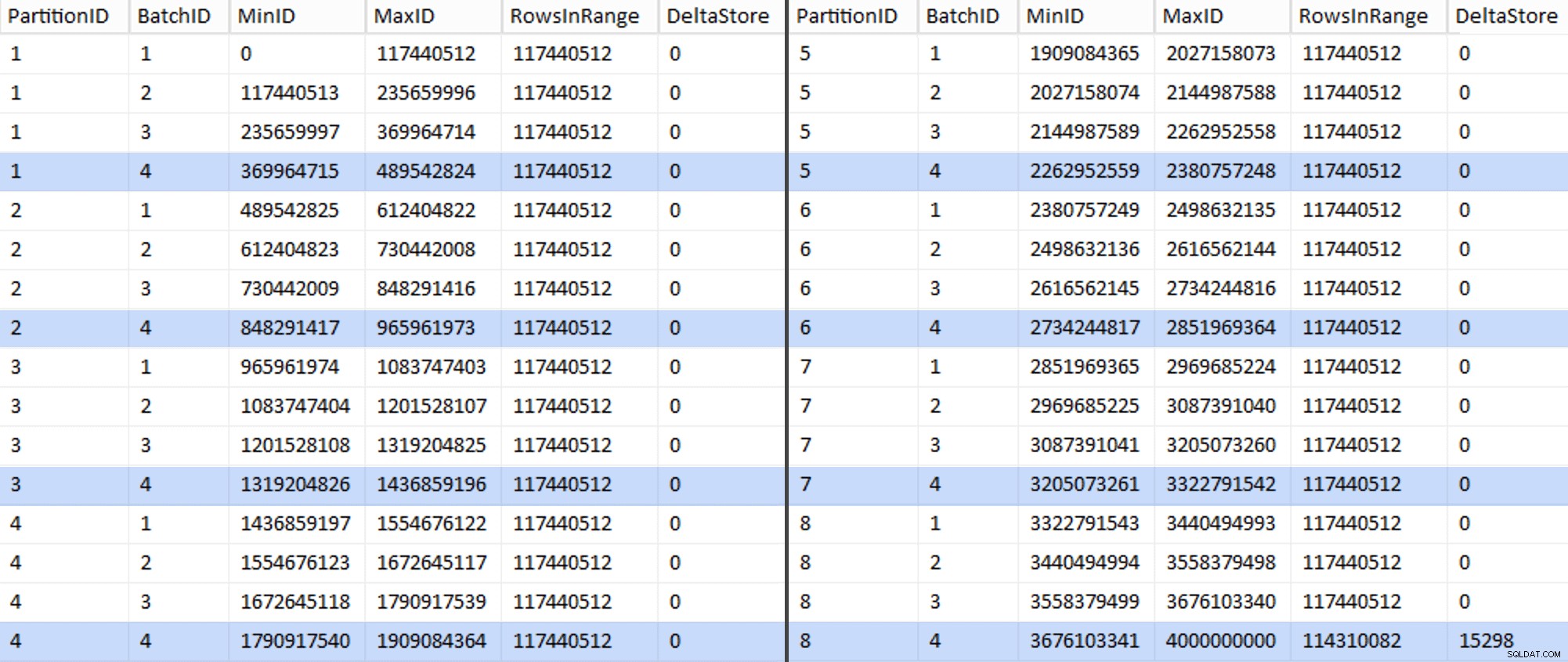
Com certeza, cada lote tem as 117.440.512 milhões de linhas calculadas, exceto a última que conterá, pelo menos idealmente, nosso único armazenamento delta não compactado. Provavelmente podemos evitar isso também, alterando o tamanho do lote ligeiramente para esta partição para que todos os quatro lotes sejam executados com o mesmo tamanho, ou alterando o número de lotes para acomodar algum outro múltiplo de 102.400 ou 1.048.576. Como isso exigiria a obtenção de um novo
OID valores da tabela base, adicionando mais 25 minutos ao nosso esforço de migração, vou deixar essa partição imperfeita deslizar - especialmente porque não estamos obtendo o benefício total da compactação de arquivamento dela de qualquer maneira. A
BatchQueue table está começando a mostrar sinais de ser útil para processar nossos lotes para migrar dados para nossa nova tabela columnstore particionada e clusterizada. Que precisamos criar, agora que conhecemos os limites. Existem apenas 7 limites, então você certamente poderia fazer isso manualmente, mas eu gosto de fazer o SQL dinâmico fazer meu trabalho para mim:DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; Resultados:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
Uma vez criado, podemos criar nosso esquema de partição e atribuir cada partição sucessiva ao seu arquivo dedicado:
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
Agora podemos criar a tabela e prepará-la para migração:
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
Na Parte 3, configurarei ainda mais o
BatchQueue tabela, crie um procedimento para que os processos enviem os dados para a nova estrutura e analise os resultados. [ Parte 1 | Parte 2 | Parte 3]