Em abril, escrevi sobre alguns métodos nativos no SQL Server que podem ser usados para rastrear atualizações automáticas de estatísticas. As três opções que forneci foram SQL Trace, Extended Events e snapshots de sys.dm_db_stats_properties. Embora essas três opções permaneçam viáveis (mesmo no SQL Server 2014, embora minha principal recomendação ainda seja o XE), uma opção adicional que notei ao executar alguns testes recentemente é o SQL Sentry Plan Explorer.
Muitos de vocês usam o Plan Explorer simplesmente para ler os planos em execução, o que é ótimo. Ele tem vários benefícios sobre o Management Studio quando se trata de revisar planos - desde pequenas coisas, como classificar os principais operadores e ver facilmente problemas de estimativa de cardinalidade, até benefícios maiores, como lidar com planos complexos e grandes e poder selecionar um declaração dentro de um lote para facilitar a revisão do plano. Mas por trás dos visuais que facilitam a dissecação dos planos, o Plan Explorer também oferece a capacidade de executar uma consulta e visualizar o plano real (em vez de executá-lo no Management Studio e salvá-lo). Além disso, quando você executa o plano do PE, há informações adicionais capturadas que podem ser úteis.
Vamos começar com a demonstração que usei em meu post recente, Como as atualizações automáticas nas estatísticas podem afetar o desempenho da consulta. Comecei com o banco de dados AdventureWorks2012 e criei uma cópia da tabela SalesOrderHeader com mais de 200 milhões de linhas. A tabela tem um índice clusterizado em SalesOrderID e um índice não clusterizado em CustomerID, OrderDate, SubTotal. [Novamente:se você for fazer testes repetidos, faça um backup deste banco de dados neste momento para economizar algum tempo.] Primeiro verifiquei o número atual de linhas na tabela e o número de linhas que precisariam ser alteradas para invocar uma atualização automática:
SELECT OBJECT_NAME([p].[object_id]) [TableName], [si].[name] [IndexName], [au].[type_desc] [Type], [p].[rows] [RowCount], ([p].[rows]*.20) + 500 [UpdateThreshold], [au].total_pages [PageCount], (([au].[total_pages]*8)/1024)/1024 [TotalGB] FROM [sys].[partitions] [p] JOIN [sys].[allocation_units] [au] ON [p].[partition_id] = [au].[container_id] JOIN [sys].[indexes] [si] on [p].[object_id] = [si].object_id and [p].[index_id] = [si].[index_id] WHERE [p].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Big_SalesOrderHeader Informações CIX e NCI
Também verifiquei o cabeçalho de estatísticas atual para o índice:
DBCC SHOW_STATISTICS ('Sales.Big_SalesOrderHeader',[IX_Big_SalesOrderHeader_CustomerID_OrderDate_SubTotal]); 
Estatísticas do NCI:no início
O procedimento armazenado que utilizo para teste já foi criado, mas para completar o código está listado abaixo:
CREATE PROCEDURE Sales.usp_GetCustomerStats
@CustomerID INT,
@StartDate DATETIME,
@EndDate DATETIME
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate), COUNT([SalesOrderID]) as Computed
FROM [Sales].[Big_SalesOrderHeader]
WHERE CustomerID = @CustomerID
AND OrderDate BETWEEN @StartDate and @EndDate
GROUP BY CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate)
ORDER BY DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate);
END Anteriormente, eu iniciava uma sessão de Trace ou Extended Events ou configurava meu método para capturar sys.dm_db_stats_properties em uma tabela. Para este exemplo, acabei de executar o procedimento armazenado acima algumas vezes:
EXEC Sales.usp_GetCustomerStats 11331, '2012-08-01 00:00:00.000', '2012-08-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11330, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11506, '2012-11-01 00:00:00.000', '2012-11-30 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 17061, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11711, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15131, '2013-02-01 00:00:00.000', '2013-02-28 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 29837, '2012-10-01 00:00:00.000', '2012-10-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15750, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO
Em seguida, verifiquei o cache do procedimento para verificar a contagem de execução e também verifiquei o plano que foi armazenado em cache:
SELECT OBJECT_NAME([st].[objectid]), [st].[text], [qs].[execution_count], [qs].[creation_time], [qs].[last_execution_time], [qs].[min_worker_time], [qs].[max_worker_time], [qs].[min_logical_reads], [qs].[max_logical_reads], [qs].[min_elapsed_time], [qs].[max_elapsed_time], [qp].[query_plan] FROM [sys].[dm_exec_query_stats] [qs] CROSS APPLY [sys].[dm_exec_sql_text]([qs].plan_handle) [st] CROSS APPLY [sys].[dm_exec_query_plan]([qs].plan_handle) [qp] WHERE [st].[text] LIKE '%usp_GetCustomerStats%' AND OBJECT_NAME([st].[objectid]) IS NOT NULL;

Planejar informações de cache para o SP:no início
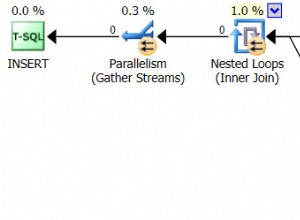
Plano de consulta para procedimento armazenado, usando SQL Sentry Plan Explorer
O plano foi criado em 29/09/2014 23:23.01.
Em seguida, adicionei 61 milhões de linhas à tabela para invalidar as estatísticas atuais e, assim que a inserção foi concluída, verifiquei as contagens de linhas:

Big_SalesOrderHeader Informações CIX e NCI:Após a inserção de 61 milhões linhas
Antes de executar o procedimento armazenado novamente, verifiquei que a contagem de execução não foi alterada, que o tempo de criação ainda era 2014-09-29 23:23.01 para o plano e que as estatísticas não foram atualizadas:
Planejar informações de cache para o SP:imediatamente após a inserção

Estatísticas NCI:após inserção
Agora, na postagem anterior do blog, executei a instrução no Management Studio, mas desta vez, executei a consulta diretamente do Plan Explorer e capturei o Plano Real via PE (opção circulada em vermelho na imagem abaixo).
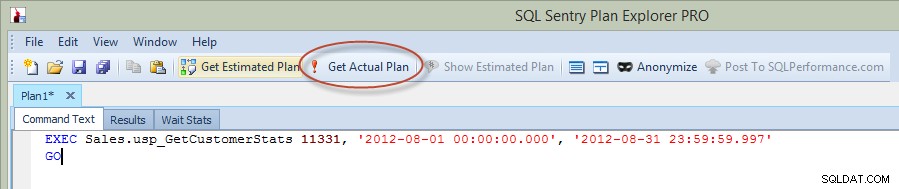
Executar procedimento armazenado a partir do Plan Explorer
Ao executar uma instrução do PE, você deve inserir a instância e o banco de dados aos quais deseja se conectar e, em seguida, será notificado de que a consulta será executada e o plano real será retornado, mas os resultados não serão retornados. Observe que isso é diferente do Management Studio, onde você vê os resultados.
Depois de executar o procedimento armazenado, na saída, não apenas recebo o plano, mas vejo quais instruções foram executadas:
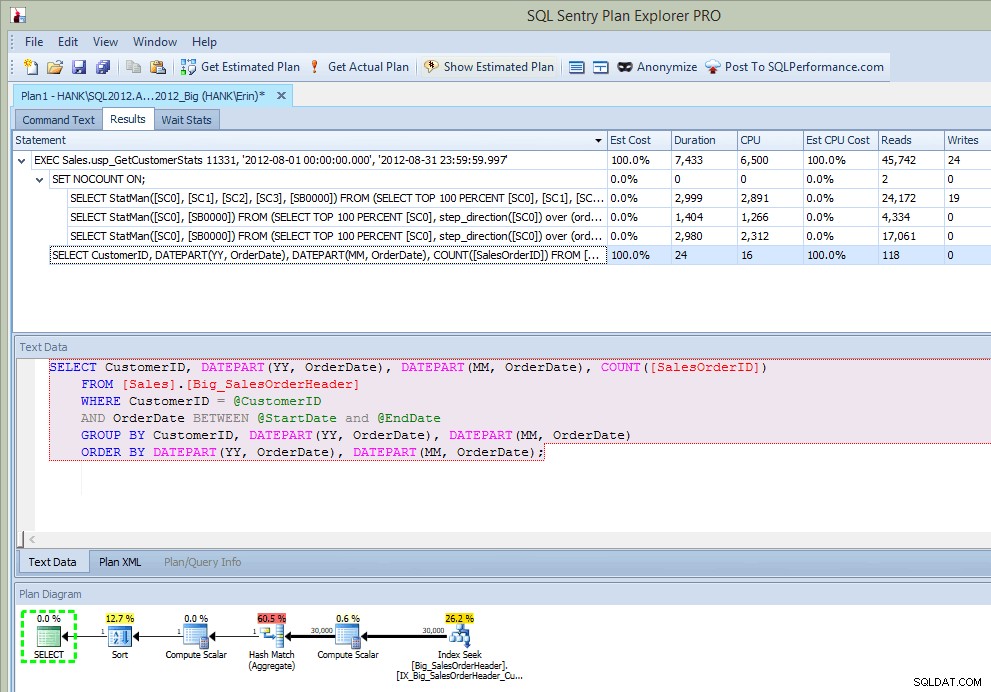
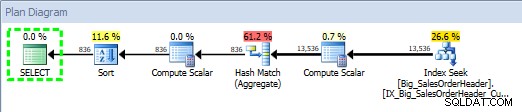
Planeje a saída do Explorer após a execução SP (após a inserção)
Isso é muito legal…além de ver a instrução executada no procedimento armazenado, também vejo as atualizações nas estatísticas, assim como fiz quando capturei as atualizações usando Extended Events ou SQL Trace. Junto com a execução da instrução, também podemos ver informações de CPU, duração e IO. Agora – a ressalva aqui é que posso ver essas informações se Eu executo a instrução que chama a atualização de estatísticas do Plan Explorer. Isso provavelmente não acontecerá com frequência em seu ambiente de produção, mas você pode ver isso quando estiver testando (porque esperamos que seu teste não envolva apenas a execução de consultas SELECT, mas também envolva consultas INSERT/UPDATE/DELETE como você faria ver em uma carga de trabalho normal). No entanto, se você estiver monitorando seu ambiente com uma ferramenta como o SQL Sentry, poderá ver essas atualizações no SQL principal desde que excedam o limite de coleta do SQL principal. O SQL Sentry tem limites padrão que as consultas devem exceder antes de serem capturadas como Top SQL (por exemplo, a duração deve exceder cinco (5) segundos), mas você pode alterá-los e adicionar outros limites, como leituras. Neste exemplo, apenas para fins de teste , alterei meu limite de duração mínima do Top SQL para 10 milissegundos e meu limite de leitura para 500, e o SQL Sentry conseguiu capturar algumas das atualizações de estatísticas:
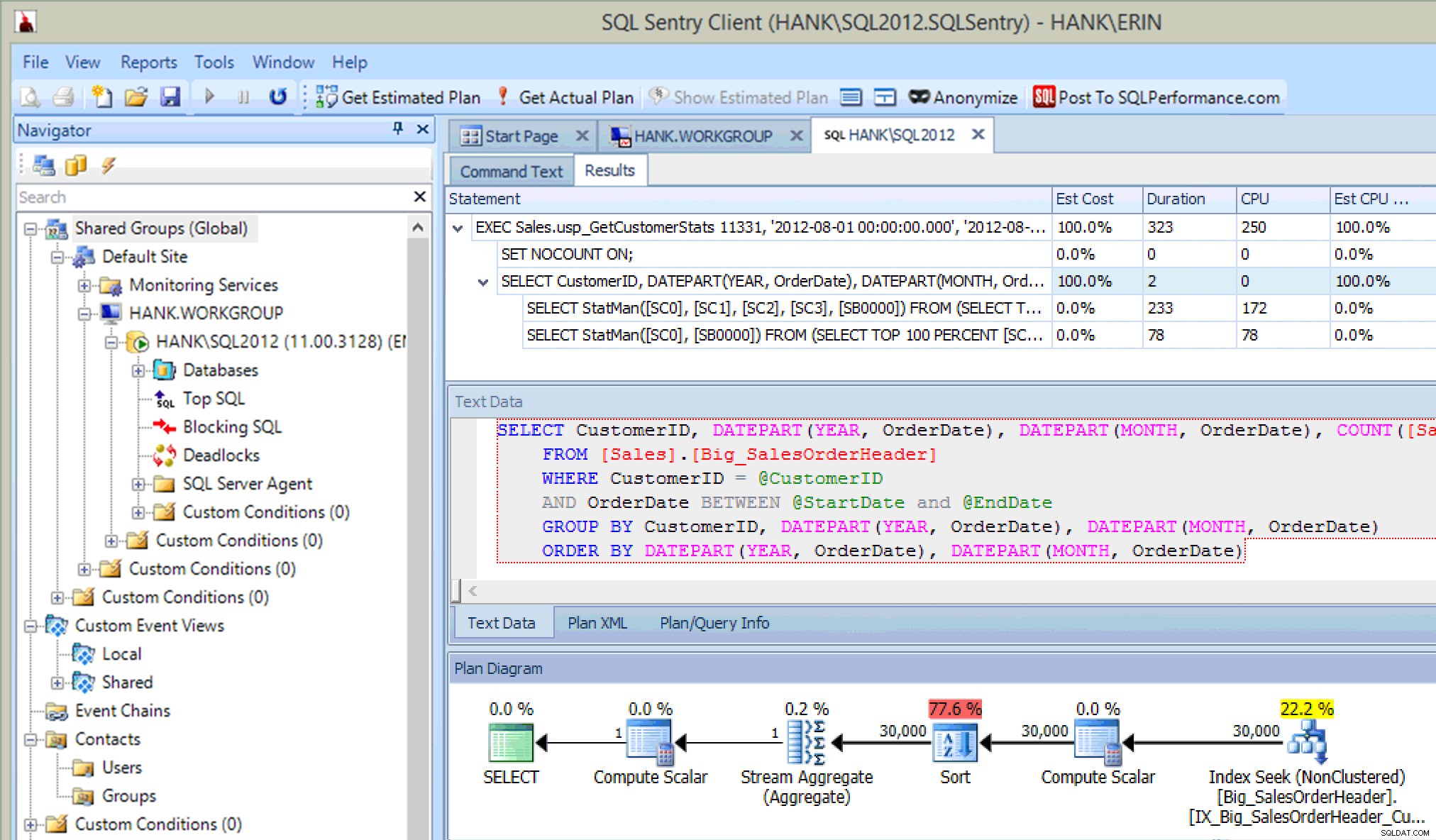
Atualizações de estatísticas capturadas pelo SQL Sentry
Dito isso, se o monitoramento pode capturar esses eventos dependerá, em última análise, dos recursos do sistema e da quantidade de dados que devem ser lidos para atualizar a estatística. Suas atualizações de estatísticas não podem exceder esses limites, portanto, talvez seja necessário fazer uma busca mais proativa para encontrá-los.
Resumo
Eu sempre encorajo os DBAs a gerenciar estatísticas de forma proativa – o que significa que existe um trabalho para atualizar as estatísticas regularmente. No entanto, mesmo que esse trabalho seja executado todas as noites (o que não estou necessariamente recomendando), ainda é bem possível que as atualizações nas estatísticas ocorram automaticamente ao longo do dia, porque algumas tabelas são mais voláteis que outras e têm um grande número de modificações. Isso não é anormal e, dependendo do tamanho da tabela e da quantidade de modificações, as atualizações automáticas podem não interferir significativamente nas consultas dos usuários. Mas a única maneira de saber é monitorar essas atualizações – esteja você usando ferramentas nativas ou ferramentas de terceiros – para que você possa ficar à frente de possíveis problemas e resolvê-los antes que eles aumentem.