A crescente demanda por sistemas de alta disponibilidade e SLAs rigorosos nos leva a substituir procedimentos manuais por soluções automatizadas. Mas você tem o tempo e os recursos necessários para lidar sozinho com a complexidade das operações de failover? Você sacrificará o tempo de inatividade do banco de dados de produção para aprender da maneira mais difícil?
O ClusterControl fornece suporte avançado para detecção e tratamento de falhas. É usado por muitas organizações empresariais, mantendo os sistemas de produção mais críticos em funcionamento no modo 24 horas por dia, 7 dias por semana.
Esta solução de gerenciamento de banco de dados também oferece suporte para a implantação de diferentes proxies de carga. Esses proxies desempenham um papel fundamental na pilha de alta disponibilidade, portanto, não há necessidade de ajustar a cadeia de conexão do aplicativo ou a entrada DNS para redirecionar as conexões do aplicativo para o novo nó mestre.
Quando a falha é detectada, o ClusterControl faz todo o trabalho em segundo plano para eleger um novo mestre, implantar servidores escravos de failover e configurar balanceadores de carga. Neste blog, você aprenderá como obter failover automático do TimescaleDB em seus sistemas de produção.
Implantando topologias de replicação inteiras
A partir do ClusterControl 1.7.2, você pode implantar uma configuração de replicação inteira do TimescaleDB da mesma maneira que implantaria o PostgreSQL:você pode usar o menu “Deploy Cluster” para implantar um servidor primário e um ou mais em espera do TimescaleDB. Vamos ver como é.
Primeiro, você precisa definir os detalhes de acesso ao implantar novos clusters usando o ClusterControl. Ele requer acesso por senha root ou sudo a todos os nós nos quais seu novo cluster será implantado.
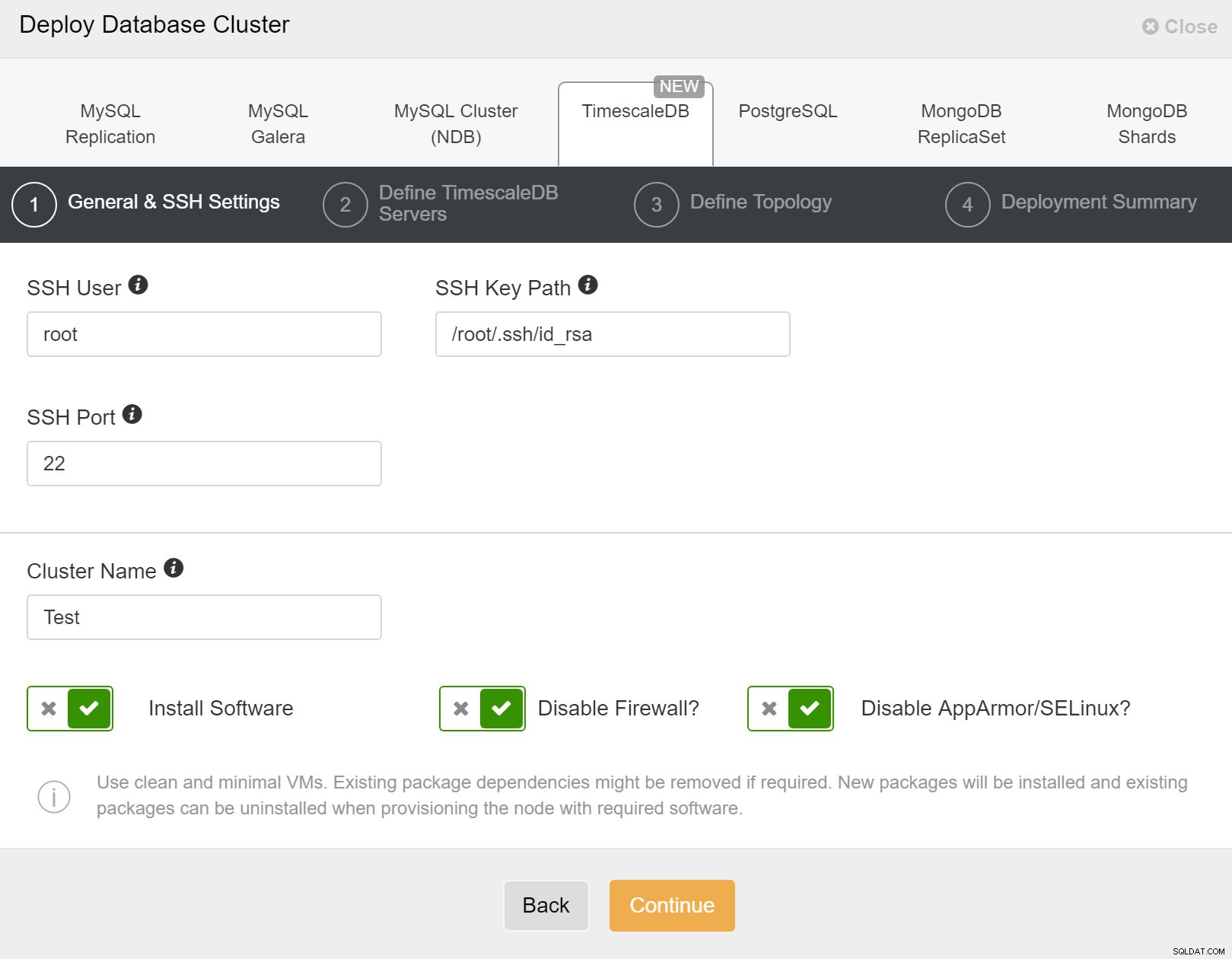 ClusterControl:implantar novo cluster
ClusterControl:implantar novo cluster Em seguida, precisamos definir o usuário e a senha para o usuário TimescaleDB.
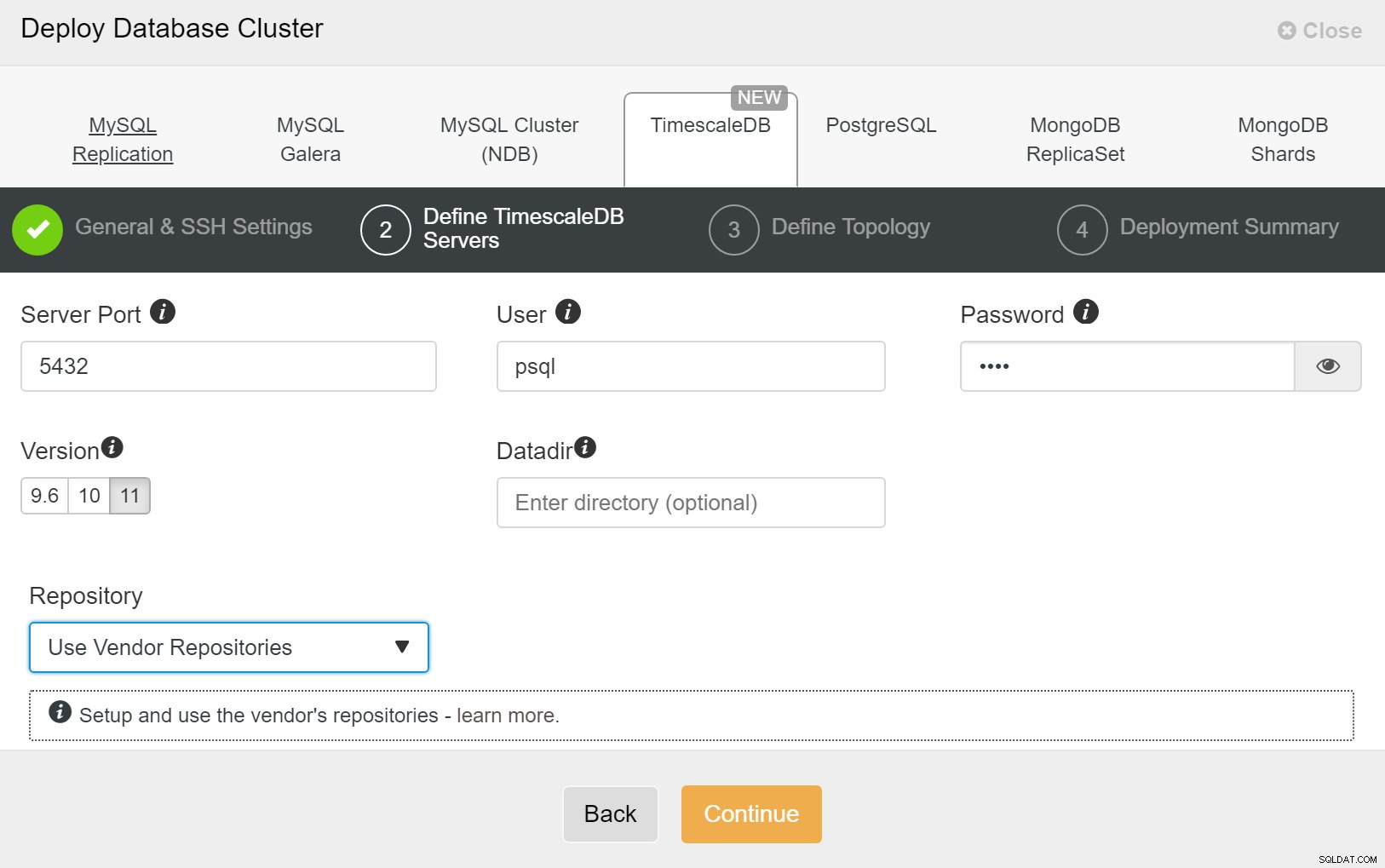 ClusterControl:implantar cluster de banco de dados
ClusterControl:implantar cluster de banco de dados Finalmente, você deseja definir a topologia - qual host deve ser o principal e quais hosts devem ser configurados como standby. Enquanto você define hosts na topologia, o ClusterControl verificará se o acesso ssh funciona conforme o esperado - isso permite detectar quaisquer problemas de conectividade antecipadamente. Na última tela, você será questionado sobre o tipo de replicação síncrona ou assíncrona.
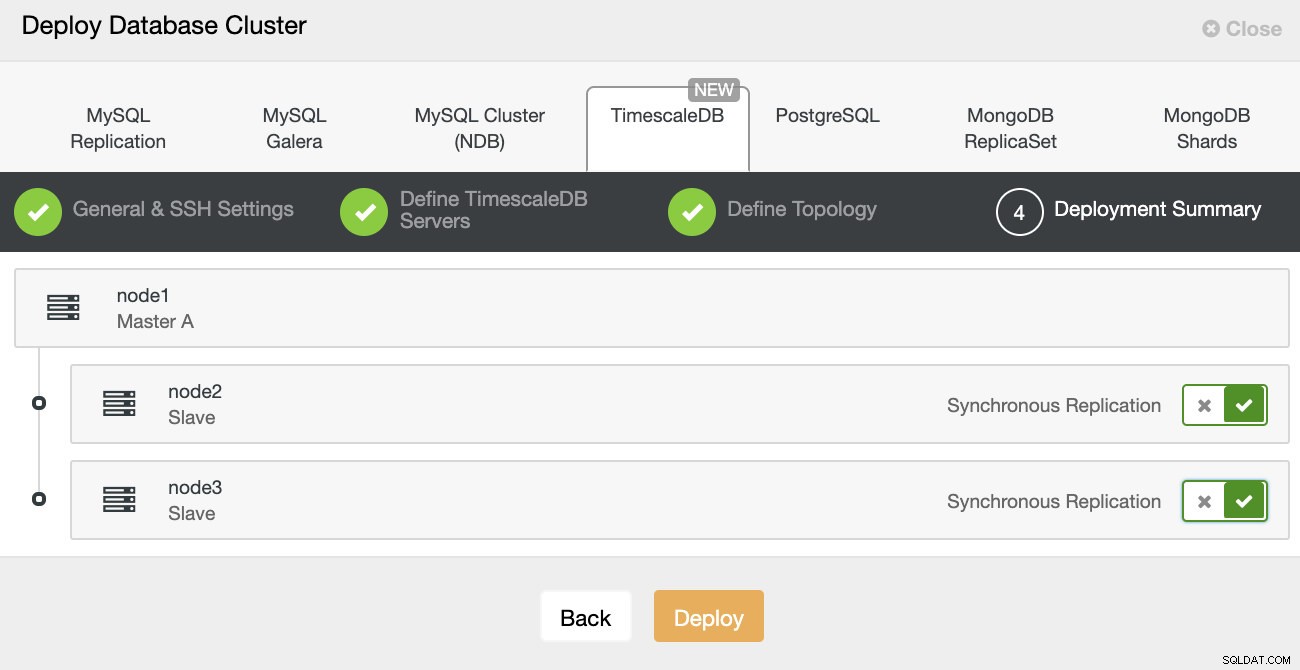 Implantação do ClusterControl
Implantação do ClusterControl É isso, é então uma questão de iniciar a implantação. Um trabalho é criado no ClusterControl e você poderá acompanhar o andamento.
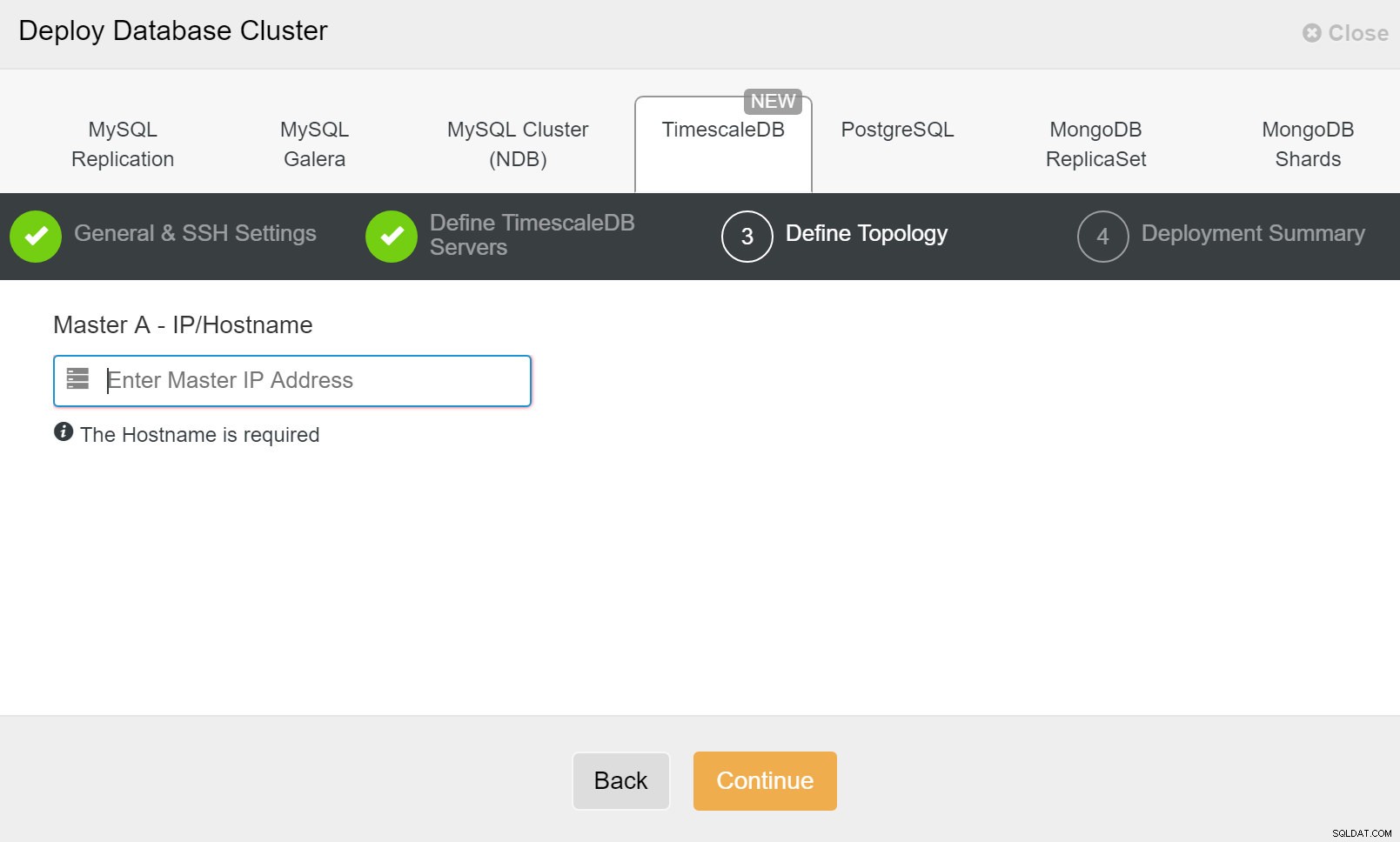 ClusterControl:Definir topologia para cluster TimescleDb
ClusterControl:Definir topologia para cluster TimescleDb Quando terminar, você verá a configuração da topologia com funções no cluster. Observe que também adicionamos um balanceador de carga (HAProxy) na frente das instâncias do banco de dados para que o failover automático não exija alterações nas configurações de conexão do banco de dados.
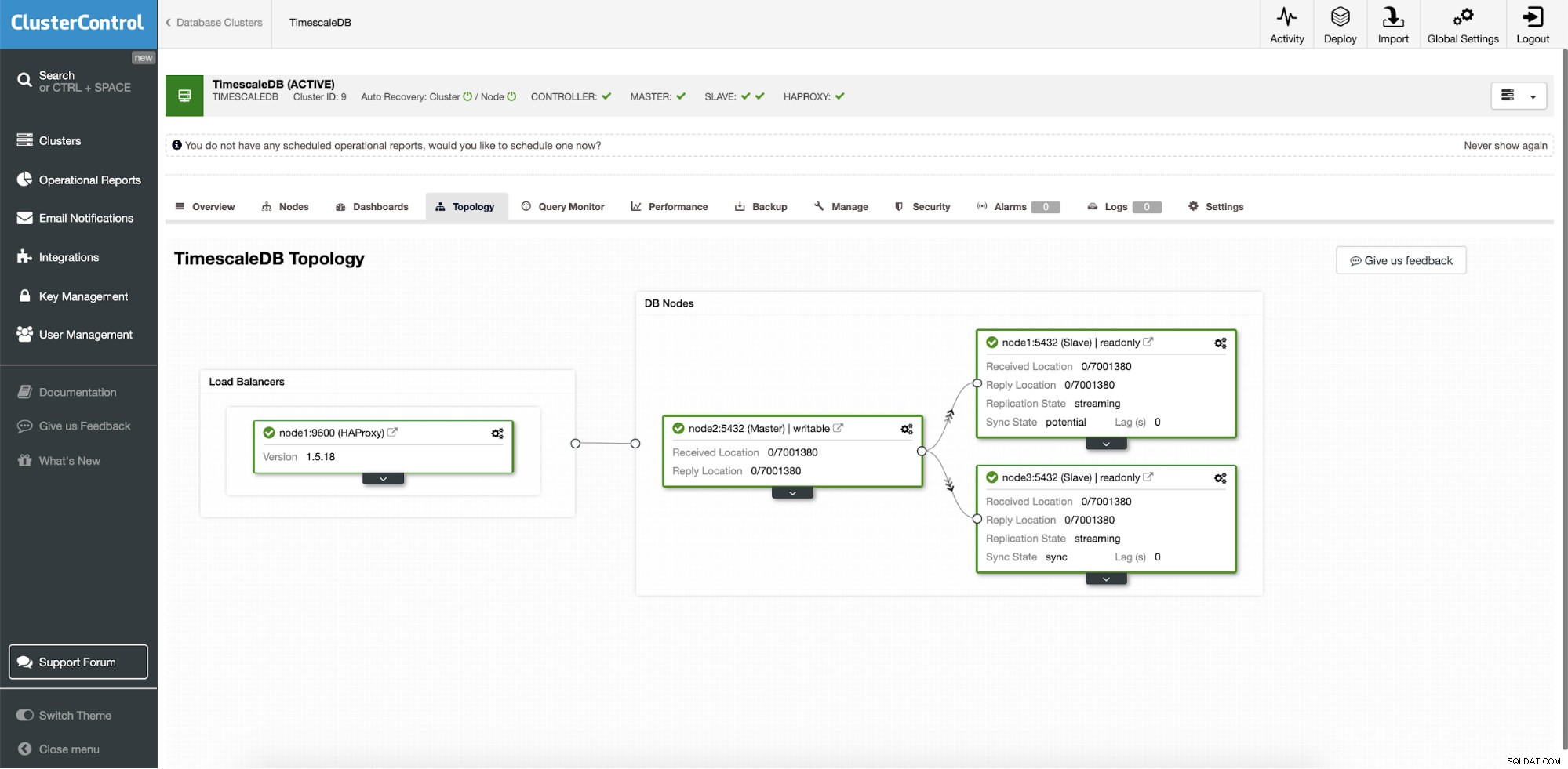 ClusterControl:Topology
ClusterControl:Topology Quando a escala de tempo é implantada pelo ClusterControl, a recuperação automática é habilitada por padrão. O estado pode ser verificado na barra do cluster.
 ClusterControl:Cluster de recuperação automática e estado do nó
ClusterControl:Cluster de recuperação automática e estado do nó Configuração de failover
Depois que a configuração da replicação é implantada, o ClusterControl pode monitorar a configuração e recuperar automaticamente quaisquer servidores com falha. Ele também pode orquestrar alterações na topologia.
O failover automático do ClusterControl foi projetado com os seguintes princípios:
- Certifique-se de que o mestre esteja realmente morto antes do failover
- Failover apenas uma vez
- Não faça failover para um escravo inconsistente
- Escrever apenas para o mestre
- Não recupere automaticamente o mestre com falha
Com os algoritmos integrados, o failover geralmente pode ser executado muito rapidamente para que você possa garantir os SLAs mais altos para seu ambiente de banco de dados.
O processo é configurável. Ele vem com vários parâmetros que você pode usar para adotar a recuperação para as especificidades do seu ambiente.
| max_replication_lag | Máximo de atraso de replicação permitido em segundos antes |
| replication_stop_on_error | Os procedimentos de failover/troca falharão se forem encontrados erros que possam causar perda de dados. Ativado por padrão. 0 significa desabilitar, |
| replication_auto_rebuild_slave | Se o SQL THREAD for interrompido e o código de erro for diferente de zero, o escravo será reconstruído automaticamente. 1 significa habilitar, 0 significa desabilitar (padrão). |
| replication_failover_blacklist | Lista separada por vírgulas de pares hostname:port. Os servidores na lista negra não serão considerados candidatos durante o failover. Replication_failover_blacklist será ignorado se replication_failover_whitelist estiver definido. |
| replication_failover_whitelist | Lista separada por vírgulas de pares hostname:port. Somente servidores na lista de permissões serão considerados candidatos durante o failover. Se nenhum servidor na lista branca estiver disponível (ativo/conectado), o failover falhará. Replication_failover_blacklist será ignorado se replication_failover_whitelist estiver definido. |
Tratamento de failover
Quando uma falha de mestre é detectada, uma lista de candidatos a mestre é criada e um deles é escolhido para ser o novo mestre. É possível ter uma lista branca de servidores a serem promovidos a primários, bem como uma lista negra de servidores que não podem ser promovidos a primários. Os escravos restantes agora são escravizados no novo primário e o antigo primário não é reiniciado.
Abaixo podemos ver uma simulação de falha do nó.
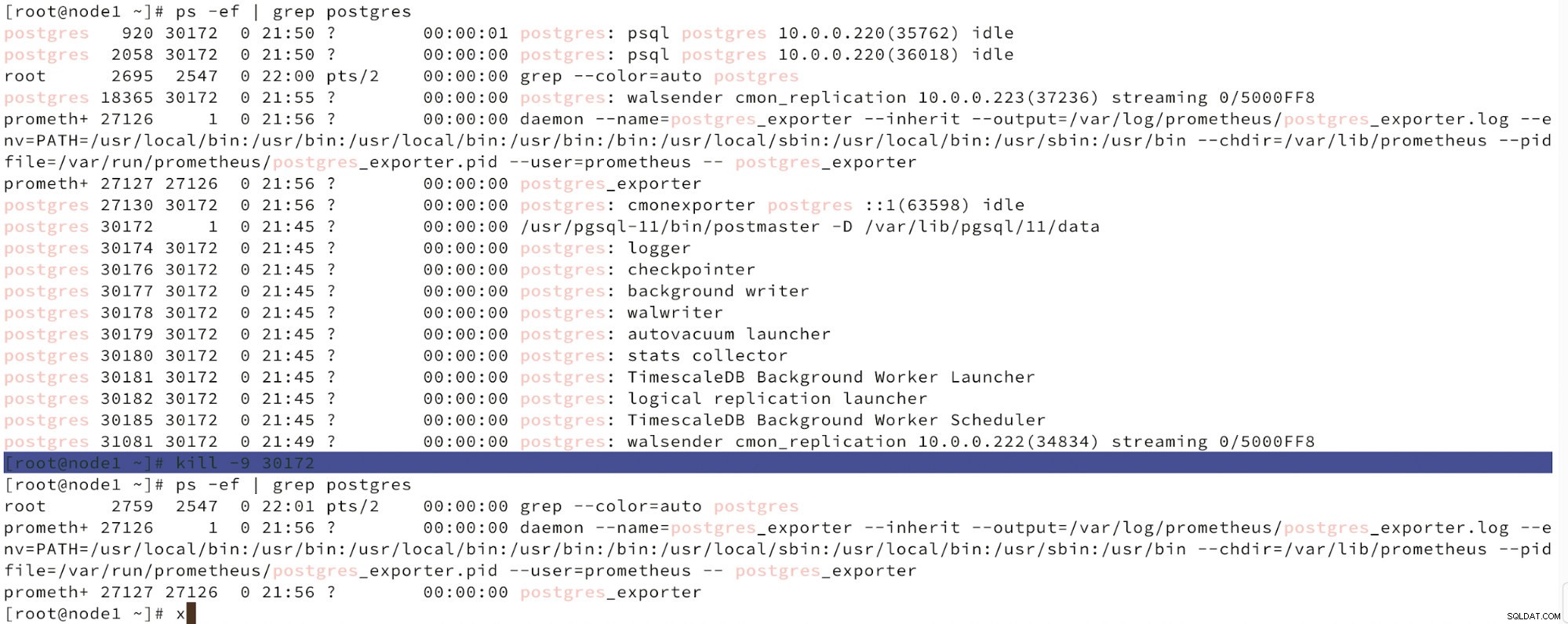 Simular falha do nó mestre com kill
Simular falha do nó mestre com kill Quando o mau funcionamento dos nós é detectado e a recuperação automática é detectada, o ClusterControl aciona o trabalho para executar o failover. Abaixo podemos ver as ações tomadas para recuperar o cluster.
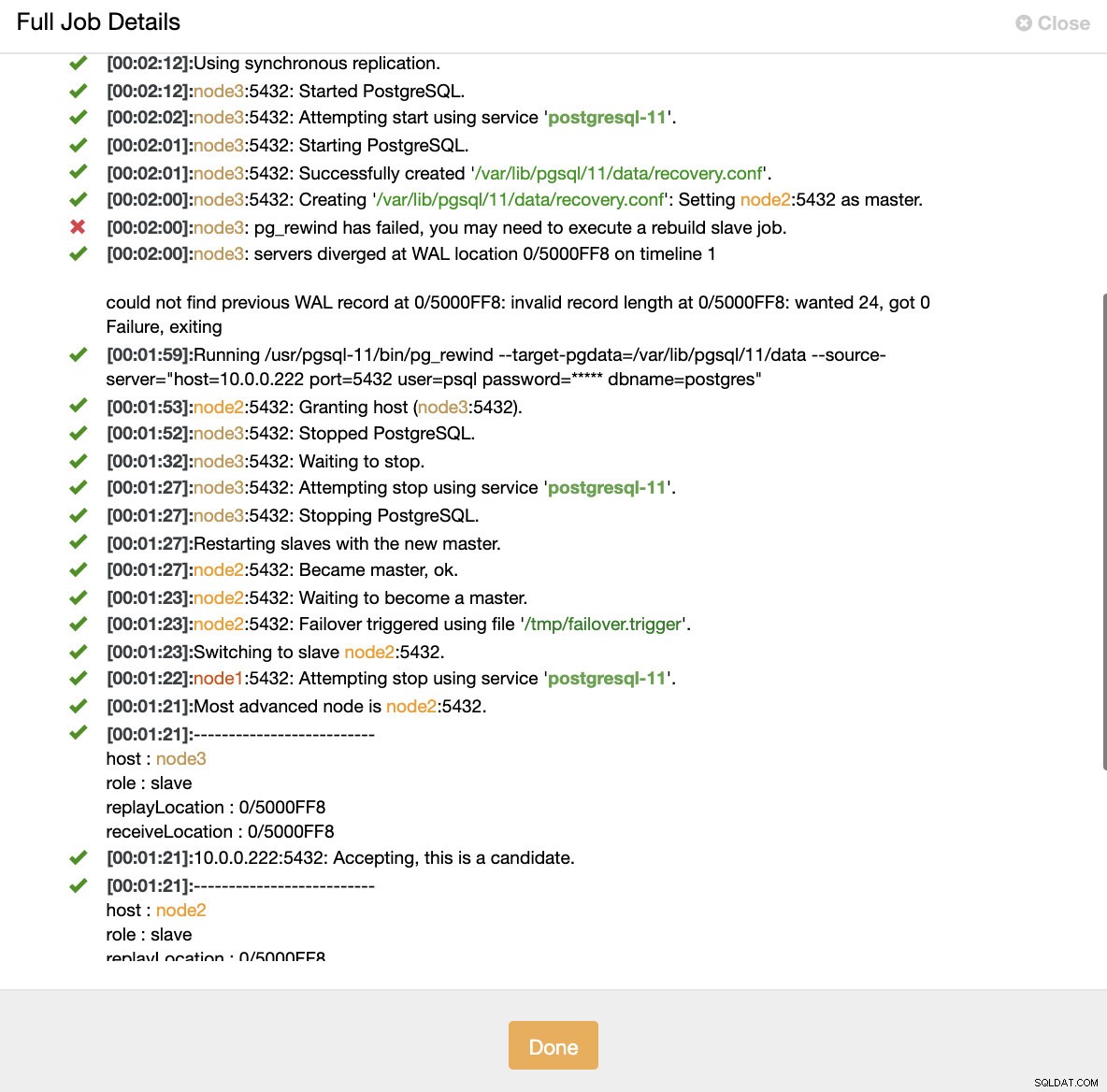 ClusterControl:Job acionado para reconstruir o cluster
ClusterControl:Job acionado para reconstruir o cluster O ClusterControl mantém intencionalmente o antigo primário offline porque pode acontecer que alguns dos dados não tenham sido transferidos para os servidores em espera. Nesse caso, o principal é o único host que contém esses dados e talvez você queira recuperar os dados ausentes manualmente. Para aqueles que desejam que o primário com falha seja reconstruído automaticamente, existe uma opção no arquivo de configuração do cmon:replication_auto_rebuild_slave. Por padrão, está desabilitado, mas quando o usuário o habilita, o primário com falha será reconstruído como escravo do novo primário. Obviamente, se houver dados ausentes que existam apenas no primário com falha, esses dados serão perdidos.
Reconstruindo servidores em espera
Um recurso diferente é o trabalho “Reconstruir Escravo de Replicação” que está disponível para todos os escravos (ou servidores em espera) na configuração de replicação. Isso deve ser usado, por exemplo, quando você deseja limpar os dados no modo de espera e reconstruí-los novamente com uma nova cópia dos dados do primário. Pode ser benéfico se um servidor em espera não puder se conectar e replicar a partir do primário por algum motivo.
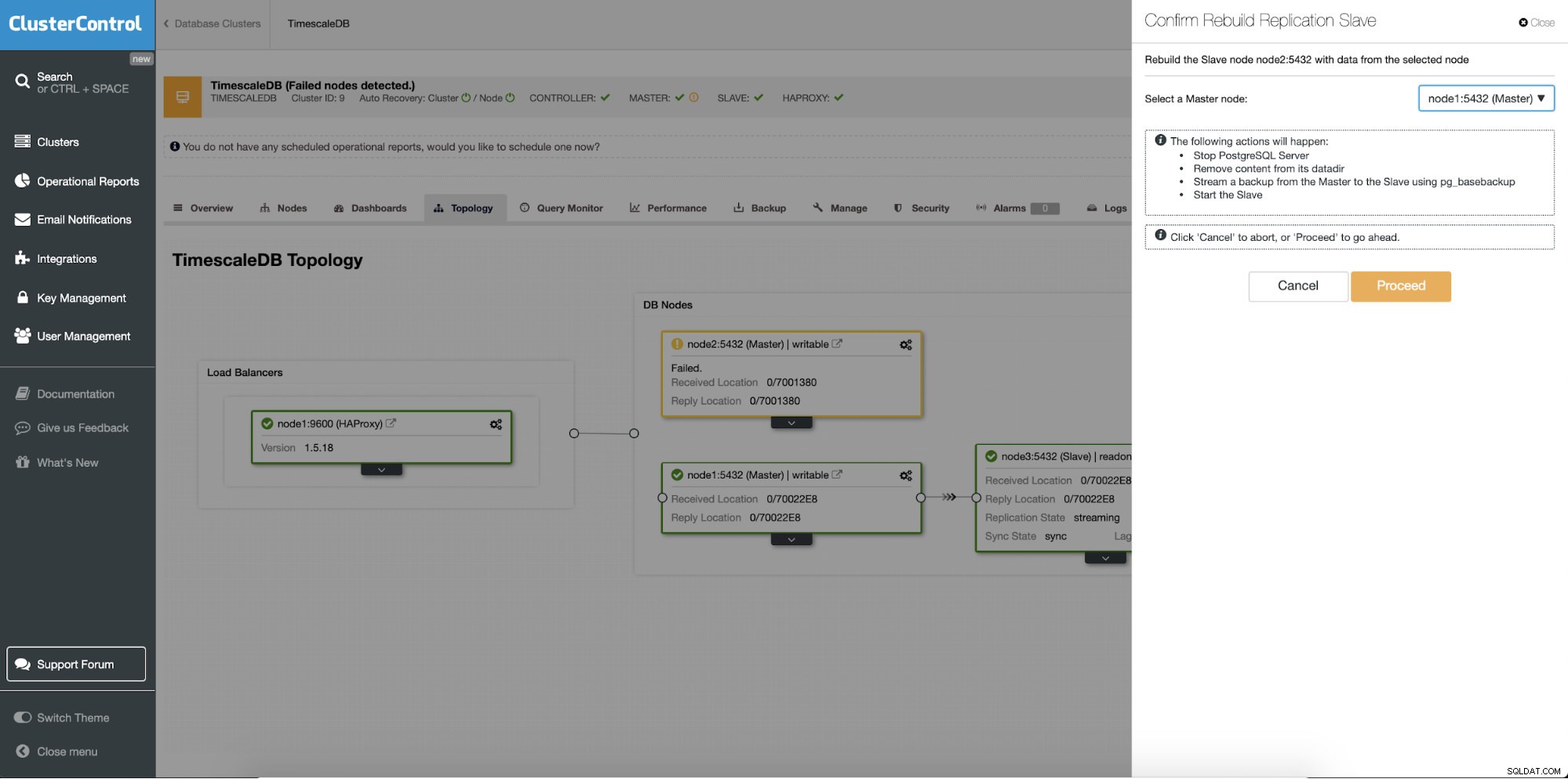 ClusterControl:Reconstruir o slave de replicação
ClusterControl:Reconstruir o slave de replicação 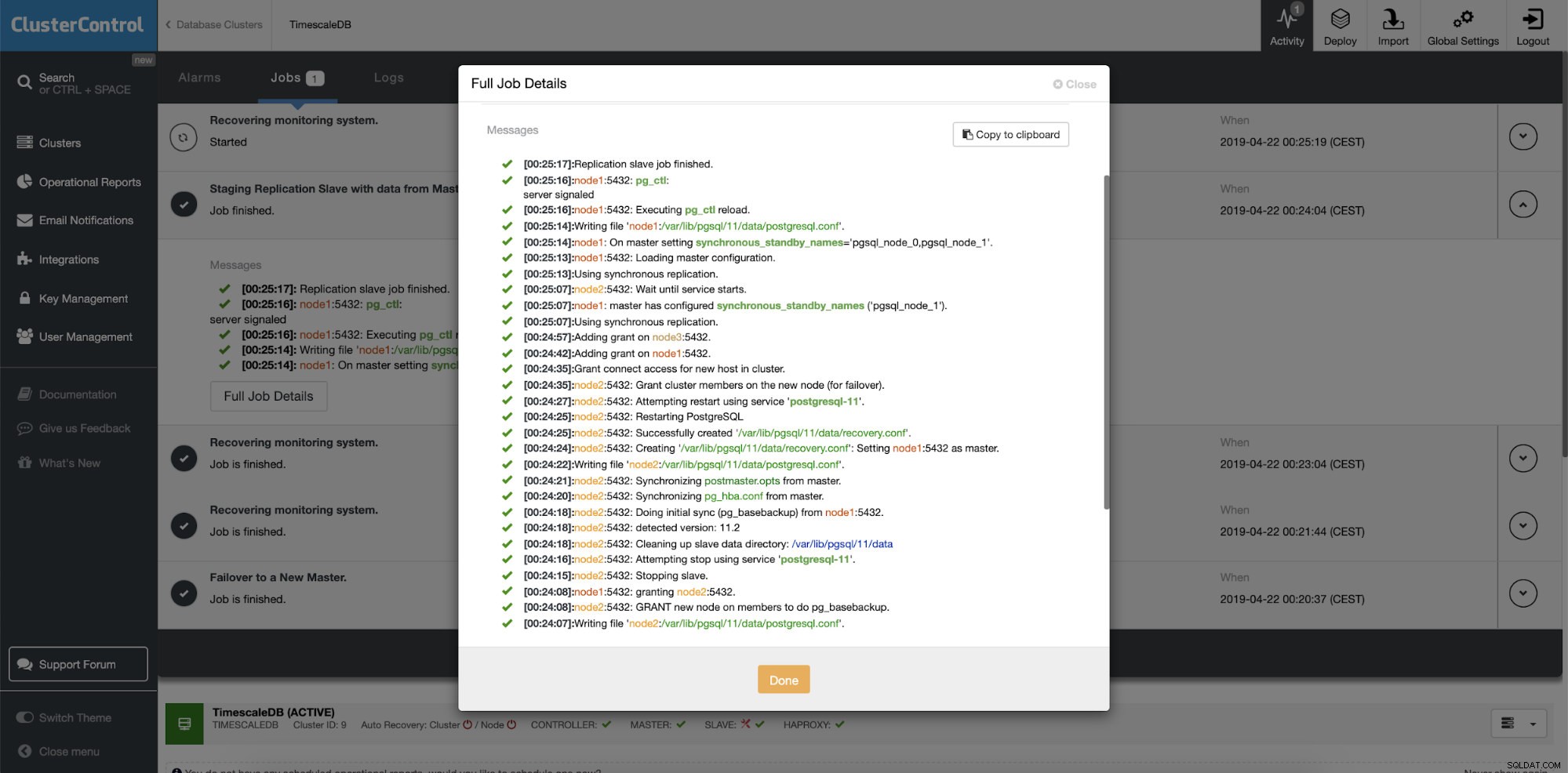 ClusterControl:Reconstruir escravo
ClusterControl:Reconstruir escravo