Todos os aplicativos de software interagem com dados , mais comumente por meio de um sistema de gerenciamento de banco de dados (DBMS). Algumas linguagens de programação vêm com módulos que você pode usar para interagir com um SGBD, enquanto outras requerem o uso de pacotes de terceiros. Neste tutorial, você explorará as diferentes bibliotecas Python SQL que você pode usar. Você desenvolverá um aplicativo simples para interagir com bancos de dados SQLite, MySQL e PostgreSQL.
Neste tutorial, você aprenderá a:
- Conectar para diferentes sistemas de gerenciamento de banco de dados com bibliotecas Python SQL
- Interagir com bancos de dados SQLite, MySQL e PostgreSQL
- Executar consultas comuns de banco de dados usando um aplicativo Python
- Desenvolver aplicativos em diferentes bancos de dados usando um script Python
Para tirar o máximo proveito deste tutorial, você deve ter conhecimento básico de Python, SQL e trabalhar com sistemas de gerenciamento de banco de dados. Você também deve ser capaz de baixar e importar pacotes em Python e saber como instalar e executar diferentes servidores de banco de dados local ou remotamente.
Download de PDF gratuito: Folha de dicas do Python 3
Compreendendo o esquema de banco de dados
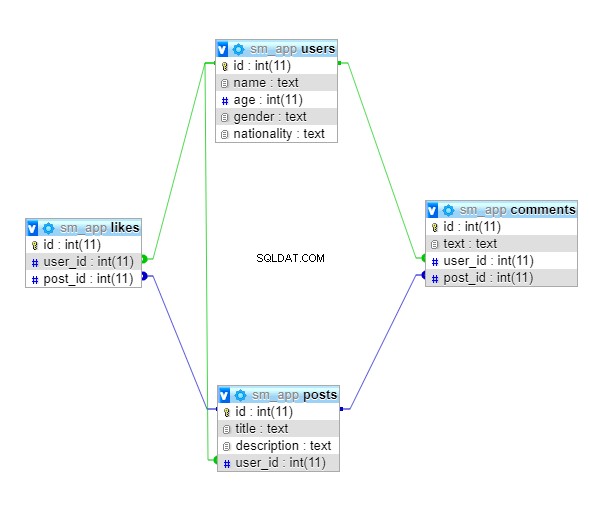
Neste tutorial, você desenvolverá um banco de dados muito pequeno para um aplicativo de mídia social. O banco de dados será composto por quatro tabelas:
userspostscommentslikes
Um diagrama de alto nível do esquema do banco de dados é mostrado abaixo:
Ambos os
users e posts terá um relacionamento de um para muitos, pois um usuário pode curtir muitas postagens. Da mesma forma, um usuário pode postar muitos comentários e uma postagem também pode ter vários comentários. Assim, ambos os users e posts também terá relacionamentos um-para-muitos com os comments tabela. Isso também se aplica aos likes tabela, então ambos os users e posts terá um relacionamento um-para-muitos com os likes tabela. Usando bibliotecas SQL do Python para se conectar a um banco de dados
Antes de interagir com qualquer banco de dados por meio de uma biblioteca SQL do Python, você precisa conectar a esse banco de dados. Nesta seção, você verá como se conectar a bancos de dados SQLite, MySQL e PostgreSQL de dentro de um aplicativo Python.
Observação: Você precisará de servidores MySQL e PostgreSQL em funcionamento antes de executar os scripts nas seções de banco de dados MySQL e PostgreSQL. Para uma introdução rápida sobre como iniciar um servidor MySQL, confira a seção MySQL de Iniciando um Projeto Django. Para aprender a criar um banco de dados no PostgreSQL, confira a seção Configurando um banco de dados de Prevenindo ataques de injeção de SQL com Python.
É recomendável que você crie três arquivos Python diferentes, para que você tenha um para cada um dos três bancos de dados. Você executará o script para cada banco de dados em seu arquivo correspondente.
SQLite
SQLite é provavelmente o banco de dados mais simples para se conectar com um aplicativo Python, já que você não precisa instalar nenhum módulo SQL externo do Python para fazer isso. Por padrão, sua instalação do Python contém uma biblioteca SQL do Python chamada
sqlite3 que você pode usar para interagir com um banco de dados SQLite. Além disso, os bancos de dados SQLite são sem servidor e independente , pois eles lêem e gravam dados em um arquivo. Isso significa que, diferentemente do MySQL e do PostgreSQL, você nem precisa instalar e executar um servidor SQLite para realizar operações de banco de dados!
Veja como você usa
sqlite3 para se conectar a um banco de dados SQLite em Python: 1import sqlite3
2from sqlite3 import Error
3
4def create_connection(path):
5 connection = None
6 try:
7 connection = sqlite3.connect(path)
8 print("Connection to SQLite DB successful")
9 except Error as e:
10 print(f"The error '{e}' occurred")
11
12 return connection
Veja como esse código funciona:
- Linhas 1 e 2 importar
sqlite3e oErrordo módulo aula. - Linha 4 define uma função
.create_connection()que aceita o caminho para o banco de dados SQLite. - Linha 7 usa
.connect()dosqlite3module e usa o caminho do banco de dados SQLite como parâmetro. Se o banco de dados existir no local especificado, uma conexão com o banco de dados será estabelecida. Caso contrário, um novo banco de dados será criado no local especificado e uma conexão será estabelecida. - Linha 8 imprime o status da conexão com o banco de dados bem-sucedida.
- Linha 9 captura qualquer exceção que possa ser lançada se
.connect()falha ao estabelecer uma conexão. - Linha 10 exibe a mensagem de erro no console.
sqlite3.connect(path) retorna uma connection objeto, que por sua vez é retornado por create_connection() . Esta connection objeto pode ser usado para executar consultas em um banco de dados SQLite. O script a seguir cria uma conexão com o banco de dados SQLite:connection = create_connection("E:\\sm_app.sqlite")
Depois de executar o script acima, você verá que um arquivo de banco de dados
sm_app.sqlite é criado no diretório raiz. Observe que você pode alterar o local para corresponder à sua configuração. MySQL
Ao contrário do SQLite, não há um módulo Python SQL padrão que você possa usar para se conectar a um banco de dados MySQL. Em vez disso, você precisará instalar um driver Python SQL para MySQL para interagir com um banco de dados MySQL de dentro de um aplicativo Python. Um desses drivers é o
mysql-connector-python . Você pode baixar este módulo Python SQL com pip :$ pip install mysql-connector-python
Observe que o MySQL é um baseado em servidor Sistema de gerenciamento de banco de dados. Um servidor MySQL pode ter vários bancos de dados. Ao contrário do SQLite, onde criar uma conexão equivale a criar um banco de dados, um banco de dados MySQL possui um processo de duas etapas para a criação do banco de dados:
- Faça uma conexão para um servidor MySQL.
- Executar uma consulta separada para criar o banco de dados.
Defina uma função que se conecte ao servidor de banco de dados MySQL e retorne o objeto de conexão:
1import mysql.connector
2from mysql.connector import Error
3
4def create_connection(host_name, user_name, user_password):
5 connection = None
6 try:
7 connection = mysql.connector.connect(
8 host=host_name,
9 user=user_name,
10 passwd=user_password
11 )
12 print("Connection to MySQL DB successful")
13 except Error as e:
14 print(f"The error '{e}' occurred")
15
16 return connection
17
18connection = create_connection("localhost", "root", "")
No script acima, você define uma função
create_connection() que aceita três parâmetros:- host_name
- user_name
- senha_usuário
O
mysql.connector O módulo Python SQL contém um método .connect() que você usa na linha 7 para se conectar a um servidor de banco de dados MySQL. Uma vez que a conexão é estabelecida, a connection objeto é retornado para a função de chamada. Finalmente, na linha 18 você chama create_connection() com o nome do host, nome de usuário e senha. Até agora, você apenas estabeleceu a conexão. O banco de dados ainda não foi criado. Para fazer isso, você definirá outra função
create_database() que aceita dois parâmetros:connectioné aconnectionobject para o servidor de banco de dados com o qual você deseja interagir.queryé a consulta que cria o banco de dados.
Veja como esta função se parece:
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as e:
print(f"The error '{e}' occurred")
Para executar consultas, você usa o
cursor objeto. A query a ser executado é passado para cursor.execute() em formato de string. Crie um banco de dados chamado
sm_app para seu aplicativo de mídia social no servidor de banco de dados MySQL:create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
Agora você criou um banco de dados
sm_app no servidor de banco de dados. No entanto, a connection objeto retornado pelo create_connection() está conectado ao servidor de banco de dados MySQL. Você precisa se conectar ao sm_app base de dados. Para fazer isso, você pode modificar create_connection() do seguinte modo: 1def create_connection(host_name, user_name, user_password, db_name):
2 connection = None
3 try:
4 connection = mysql.connector.connect(
5 host=host_name,
6 user=user_name,
7 passwd=user_password,
8 database=db_name
9 )
10 print("Connection to MySQL DB successful")
11 except Error as e:
12 print(f"The error '{e}' occurred")
13
14 return connection
Você pode ver na linha 8 que
create_connection() agora aceita um parâmetro adicional chamado db_name . Este parâmetro especifica o nome do banco de dados ao qual você deseja se conectar. Você pode passar o nome do banco de dados ao qual deseja se conectar ao chamar esta função:connection = create_connection("localhost", "root", "", "sm_app")
O script acima chama com sucesso
create_connection() e se conecta ao sm_app base de dados. PostgreSQL
Assim como o MySQL, não há uma biblioteca SQL Python padrão que você possa usar para interagir com um banco de dados PostgreSQL. Em vez disso, você precisa instalar um driver SQL Python de terceiros para interagir com o PostgreSQL. Um desses drivers SQL do Python para PostgreSQL é o
psycopg2 . Execute o seguinte comando em seu terminal para instalar o psycopg2 Módulo Python SQL:$ pip install psycopg2
Assim como nos bancos de dados SQLite e MySQL, você definirá
create_connection() para fazer uma conexão com seu banco de dados PostgreSQL:import psycopg2
from psycopg2 import OperationalError
def create_connection(db_name, db_user, db_password, db_host, db_port):
connection = None
try:
connection = psycopg2.connect(
database=db_name,
user=db_user,
password=db_password,
host=db_host,
port=db_port,
)
print("Connection to PostgreSQL DB successful")
except OperationalError as e:
print(f"The error '{e}' occurred")
return connection
Você usa
psycopg2.connect() para se conectar a um servidor PostgreSQL de dentro de seu aplicativo Python. Você pode então usar
create_connection() para criar uma conexão com um banco de dados PostgreSQL. Primeiro, você fará uma conexão com o banco de dados padrão postgres usando a seguinte string:connection = create_connection(
"postgres", "postgres", "abc123", "127.0.0.1", "5432"
)
Em seguida, você deve criar o banco de dados
sm_app dentro do padrão postgres base de dados. Você pode definir uma função para executar qualquer consulta SQL no PostgreSQL. Abaixo, você define create_database() para criar um novo banco de dados no servidor de banco de dados PostgreSQL:def create_database(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
Depois de executar o script acima, você verá o
sm_app banco de dados em seu servidor de banco de dados PostgreSQL. Antes de executar consultas no
sm_app banco de dados, você precisa se conectar a ele:connection = create_connection(
"sm_app", "postgres", "abc123", "127.0.0.1", "5432"
)
Depois de executar o script acima, uma conexão será estabelecida com o
sm_app banco de dados localizado no postgres servidor de banco de dados. Aqui, 127.0.0.1 refere-se ao endereço IP do host do servidor de banco de dados e 5432 refere-se ao número da porta do servidor de banco de dados. Criando Tabelas
Na seção anterior, você viu como se conectar a servidores de banco de dados SQLite, MySQL e PostgreSQL usando diferentes bibliotecas SQL do Python. Você criou o
sm_app banco de dados em todos os três servidores de banco de dados. Nesta seção, você verá como criar tabelas dentro desses três bancos de dados. Conforme discutido anteriormente, você criará quatro tabelas:
userspostscommentslikes
Você começará com SQLite.
SQLite
Para executar consultas no SQLite, use
cursor.execute() . Nesta seção, você definirá uma função execute_query() que usa este método. Sua função aceitará a connection objeto e uma string de consulta, que você passará para cursor.execute() . .execute() pode executar qualquer consulta passada a ele na forma de string. Você usará esse método para criar tabelas nesta seção. Nas próximas seções, você usará esse mesmo método para executar consultas de atualização e exclusão também. Observação: Este script deve ser executado no mesmo arquivo onde você criou a conexão para seu banco de dados SQLite.
Aqui está sua definição de função:
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query executed successfully")
except Error as e:
print(f"The error '{e}' occurred")
Este código tenta executar a
query fornecida e imprime uma mensagem de erro, se necessário. Em seguida, escreva sua consulta :
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
);
"""
Isso diz para criar uma tabela
users com as seguintes cinco colunas:idnameagegendernationality
Finalmente, você chamará
execute_query() para criar a tabela. Você passará a connection objeto que você criou na seção anterior, junto com o create_users_table string que contém a consulta de criação de tabela:execute_query(connection, create_users_table)
A consulta a seguir é usada para criar os
posts tabela:create_posts_table = """
CREATE TABLE IF NOT EXISTS posts(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id)
);
"""
Como há uma relação de um para muitos entre
users e posts , você pode ver uma chave estrangeira user_id nas posts tabela que faz referência ao id coluna em users tabela. Execute o seguinte script para criar os posts tabela:execute_query(connection, create_posts_table)
Finalmente, você pode criar os
comments e likes tabelas com o seguinte script:create_comments_table = """
CREATE TABLE IF NOT EXISTS comments (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT NOT NULL,
user_id INTEGER NOT NULL,
post_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
create_likes_table = """
CREATE TABLE IF NOT EXISTS likes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER NOT NULL,
post_id integer NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
execute_query(connection, create_comments_table)
execute_query(connection, create_likes_table)
Você pode ver que criando tabelas no SQLite é muito semelhante ao uso de SQL bruto. Tudo o que você precisa fazer é armazenar a consulta em uma variável de string e depois passar essa variável para
cursor.execute() . MySQL
Você usará o
mysql-connector-python Módulo Python SQL para criar tabelas no MySQL. Assim como no SQLite, você precisa passar sua consulta para cursor.execute() , que é retornado chamando .cursor() na connection objeto. Você pode criar outra função execute_query() que aceita a connection e query fragmento: 1def execute_query(connection, query):
2 cursor = connection.cursor()
3 try:
4 cursor.execute(query)
5 connection.commit()
6 print("Query executed successfully")
7 except Error as e:
8 print(f"The error '{e}' occurred")
Na linha 4, você passa a
query para cursor.execute() . Agora você pode criar seus
users tabela usando esta função:create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT,
name TEXT NOT NULL,
age INT,
gender TEXT,
nationality TEXT,
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_users_table)
A consulta para implementar a relação de chave estrangeira é ligeiramente diferente no MySQL em comparação com o SQLite. Além disso, o MySQL usa o
AUTO_INCREMENT palavra-chave (em comparação com o SQLite AUTOINCREMENT palavra-chave) para criar colunas onde os valores são incrementados automaticamente quando novos registros são inseridos. O script a seguir cria os
posts tabela, que contém uma chave estrangeira user_id que faz referência ao id coluna dos users tabela:create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id INT AUTO_INCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY fk_user_id (user_id) REFERENCES users(id),
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_posts_table)
Da mesma forma, para criar os
comments e likes tabelas, você pode passar o CREATE correspondente consultas para execute_query() . PostgreSQL
Assim como nos bancos de dados SQLite e MySQL, a
connection objeto que é retornado por psycopg2.connect() contém um cursor objeto. Você pode usar cursor.execute() para executar consultas Python SQL em seu banco de dados PostgreSQL. Defina uma função
execute_query() :def execute_query(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
Você pode usar esta função para criar tabelas, inserir registros, modificar registros e excluir registros em seu banco de dados PostgreSQL.
Agora crie os
users tabela dentro do sm_app base de dados:create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
)
"""
execute_query(connection, create_users_table)
Você pode ver que a consulta para criar os
users table no PostgreSQL é um pouco diferente do SQLite e do MySQL. Aqui, a palavra-chave SERIAL é usado para criar colunas que são incrementadas automaticamente. Lembre-se de que o MySQL usa a palavra-chave AUTO_INCREMENT . Além disso, a referência de chave estrangeira também é especificada de forma diferente, conforme mostrado no script a seguir que cria os
posts tabela:create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER REFERENCES users(id)
)
"""
execute_query(connection, create_posts_table)
Para criar os
comments tabela, você terá que escrever um CREATE consulta para os comments table e passe para execute_query() . O processo para criar os likes mesa é a mesma. Você só precisa modificar o CREATE consulta para criar os likes tabela em vez dos comments tabela. Inserindo registros
Na seção anterior, você viu como criar tabelas em seus bancos de dados SQLite, MySQL e PostgreSQL usando diferentes módulos SQL do Python. Nesta seção, você verá como inserir registros em suas mesas.
SQLite
Para inserir registros em seu banco de dados SQLite, você pode usar o mesmo
execute_query() função que você usou para criar tabelas. Primeiro, você deve armazenar seu INSERT INTO consulta em uma string. Então, você pode passar a connection objeto e query string para execute_query() . Vamos inserir cinco registros nos users tabela:create_users = """
INSERT INTO
users (name, age, gender, nationality)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
Como você definiu o
id coluna para incrementar automaticamente, você não precisa especificar o valor do id coluna para estes users . Os users tabela preencherá automaticamente esses cinco registros com id valores de 1 para 5 . Agora insira seis registros nas
posts tabela:create_posts = """
INSERT INTO
posts (title, description, user_id)
VALUES
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3);
"""
execute_query(connection, create_posts)
É importante mencionar que o
user_id coluna das posts table é uma chave estrangeira que faz referência ao id coluna dos users tabela. Isso significa que o user_id a coluna deve conter um valor que já existe no id coluna dos users tabela. Se não existir, você verá um erro. Da mesma forma, o script a seguir insere registros nos
comments e likes tabelas:create_comments = """
INSERT INTO
comments (text, user_id, post_id)
VALUES
('Count me in', 1, 6),
('What sort of help?', 5, 3),
('Congrats buddy', 2, 4),
('I was rooting for Nadal though', 4, 5),
('Help with your thesis?', 2, 3),
('Many congratulations', 5, 4);
"""
create_likes = """
INSERT INTO
likes (user_id, post_id)
VALUES
(1, 6),
(2, 3),
(1, 5),
(5, 4),
(2, 4),
(4, 2),
(3, 6);
"""
execute_query(connection, create_comments)
execute_query(connection, create_likes)
Em ambos os casos, você armazena seu
INSERT INTO query como uma string e execute-a com execute_query() . MySQL
Existem duas maneiras de inserir registros em bancos de dados MySQL a partir de um aplicativo Python. A primeira abordagem é semelhante ao SQLite. Você pode armazenar o
INSERT INTO query em uma string e então use cursor.execute() para inserir registros. Anteriormente, você definiu uma função wrapper
execute_query() que você usou para inserir registros. Você pode usar esta mesma função agora para inserir registros em sua tabela MySQL. O script a seguir insere registros em users tabela usando execute_query() :create_users = """
INSERT INTO
`users` (`name`, `age`, `gender`, `nationality`)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
A segunda abordagem usa
cursor.executemany() , que aceita dois parâmetros:- A consulta string contendo placeholders para os registros a serem inseridos
- A lista de registros que você deseja inserir
Veja o exemplo a seguir, que insere dois registros no
likes tabela:sql = "INSERT INTO likes ( user_id, post_id ) VALUES ( %s, %s )"
val = [(4, 5), (3, 4)]
cursor = connection.cursor()
cursor.executemany(sql, val)
connection.commit()
Cabe a você qual abordagem você escolhe para inserir registros em sua tabela MySQL. Se você é um especialista em SQL, então você pode usar
.execute() . Se você não estiver muito familiarizado com SQL, pode ser mais simples usar .executemany() . Com qualquer uma das duas abordagens, você pode inserir registros com sucesso nas posts , comments e likes mesas. PostgreSQL
Na seção anterior, você viu duas abordagens para inserir registros em tabelas de banco de dados SQLite. O primeiro usa uma consulta de string SQL e o segundo usa
.executemany() . psycopg2 segue esta segunda abordagem, embora .execute() é usado para executar uma consulta baseada em espaço reservado. Você passa a consulta SQL com os espaços reservados e a lista de registros para
.execute() . Cada registro na lista será uma tupla, onde os valores da tupla correspondem aos valores da coluna na tabela do banco de dados. Veja como você pode inserir registros de usuário em users tabela em um banco de dados PostgreSQL:users = [
("James", 25, "male", "USA"),
("Leila", 32, "female", "France"),
("Brigitte", 35, "female", "England"),
("Mike", 40, "male", "Denmark"),
("Elizabeth", 21, "female", "Canada"),
]
user_records = ", ".join(["%s"] * len(users))
insert_query = (
f"INSERT INTO users (name, age, gender, nationality) VALUES {user_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, users)
O script acima cria uma lista
users que contém cinco registros de usuário na forma de tuplas. Em seguida, você cria uma string de espaço reservado com cinco elementos de espaço reservado (%s ) que correspondem aos cinco registros do usuário. A string de espaço reservado é concatenada com a consulta que insere registros em users tabela. Finalmente, a string de consulta e os registros do usuário são passados para .execute() . O script acima insere com sucesso cinco registros em users tabela. Dê uma olhada em outro exemplo de inserção de registros em uma tabela do PostgreSQL. O script a seguir insere registros nas
posts tabela:posts = [
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3),
]
post_records = ", ".join(["%s"] * len(posts))
insert_query = (
f"INSERT INTO posts (title, description, user_id) VALUES {post_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, posts)
Você pode inserir registros nos
comments e likes tabelas com a mesma abordagem. Selecionando registros
Nesta seção, você verá como selecionar registros de tabelas de banco de dados usando os diferentes módulos SQL do Python. Em particular, você verá como executar
SELECT consultas em seus bancos de dados SQLite, MySQL e PostgreSQL. SQLite
Para selecionar registros usando SQLite, você pode usar novamente
cursor.execute() . No entanto, depois de fazer isso, você precisará chamar .fetchall() . Esse método retorna uma lista de tuplas em que cada tupla é mapeada para a linha correspondente nos registros recuperados. Para simplificar o processo, você pode criar uma função
execute_read_query() :def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
Esta função aceita a
connection objeto e o SELECT consulta e retorna o registro selecionado. SELECT
Vamos agora selecionar todos os registros dos
users tabela:select_users = "SELECT * from users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
No script acima, o
SELECT consulta seleciona todos os usuários de users tabela. Isso é passado para o execute_read_query() , que retorna todos os registros dos users tabela. Os registros são então percorridos e impressos no console. Observação: Não é recomendado usar
SELECT * em tabelas grandes, pois pode resultar em um grande número de operações de E/S que aumentam o tráfego da rede. A saída da consulta acima é assim:
(1, 'James', 25, 'male', 'USA')
(2, 'Leila', 32, 'female', 'France')
(3, 'Brigitte', 35, 'female', 'England')
(4, 'Mike', 40, 'male', 'Denmark')
(5, 'Elizabeth', 21, 'female', 'Canada')
Da mesma forma, você pode recuperar todos os registros dos
posts tabela com o script abaixo:select_posts = "SELECT * FROM posts"
posts = execute_read_query(connection, select_posts)
for post in posts:
print(post)
A saída fica assim:
(1, 'Happy', 'I am feeling very happy today', 1)
(2, 'Hot Weather', 'The weather is very hot today', 2)
(3, 'Help', 'I need some help with my work', 2)
(4, 'Great News', 'I am getting married', 1)
(5, 'Interesting Game', 'It was a fantastic game of tennis', 5)
(6, 'Party', 'Anyone up for a late-night party today?', 3)
O resultado mostra todos os registros nas
posts tabela. JOIN
Você também pode executar consultas complexas envolvendo
JOIN operações para recuperar dados de duas tabelas relacionadas. Por exemplo, o script a seguir retorna os IDs e nomes dos usuários, juntamente com a descrição das postagens que esses usuários postaram:select_users_posts = """
SELECT
users.id,
users.name,
posts.description
FROM
posts
INNER JOIN users ON users.id = posts.user_id
"""
users_posts = execute_read_query(connection, select_users_posts)
for users_post in users_posts:
print(users_post)
Here’s the output:
(1, 'James', 'I am feeling very happy today')
(2, 'Leila', 'The weather is very hot today')
(2, 'Leila', 'I need some help with my work')
(1, 'James', 'I am getting married')
(5, 'Elizabeth', 'It was a fantastic game of tennis')
(3, 'Brigitte', 'Anyone up for a late night party today?')
You can also select data from three related tables by implementing multiple
JOIN operators . The following script returns all posts, along with the comments on the posts and the names of the users who posted the comments:select_posts_comments_users = """
SELECT
posts.description as post,
text as comment,
name
FROM
posts
INNER JOIN comments ON posts.id = comments.post_id
INNER JOIN users ON users.id = comments.user_id
"""
posts_comments_users = execute_read_query(
connection, select_posts_comments_users
)
for posts_comments_user in posts_comments_users:
print(posts_comments_user)
The output looks like this:
('Anyone up for a late night party today?', 'Count me in', 'James')
('I need some help with my work', 'What sort of help?', 'Elizabeth')
('I am getting married', 'Congrats buddy', 'Leila')
('It was a fantastic game of tennis', 'I was rooting for Nadal though', 'Mike')
('I need some help with my work', 'Help with your thesis?', 'Leila')
('I am getting married', 'Many congratulations', 'Elizabeth')
You can see from the output that the column names are not being returned by
.fetchall() . To return column names, you can use the .description attribute of the cursor objeto. For instance, the following list returns all the column names for the above query:cursor = connection.cursor()
cursor.execute(select_posts_comments_users)
cursor.fetchall()
column_names = [description[0] for description in cursor.description]
print(column_names)
The output looks like this:
['post', 'comment', 'name']
You can see the names of the columns for the given query.
WHERE
Now you’ll execute a
SELECT query that returns the post, along with the total number of likes that the post received:select_post_likes = """
SELECT
description as Post,
COUNT(likes.id) as Likes
FROM
likes,
posts
WHERE
posts.id = likes.post_id
GROUP BY
likes.post_id
"""
post_likes = execute_read_query(connection, select_post_likes)
for post_like in post_likes:
print(post_like)
The output is as follows:
('The weather is very hot today', 1)
('I need some help with my work', 1)
('I am getting married', 2)
('It was a fantastic game of tennis', 1)
('Anyone up for a late night party today?', 2)
By using a
WHERE clause, you’re able to return more specific results. MySQL
The process of selecting records in MySQL is absolutely identical to selecting records in SQLite. You can use
cursor.execute() followed by .fetchall() . The following script creates a wrapper function execute_read_query() that you can use to select records:def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
Now select all the records from the
users tabela:select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
The output will be similar to what you saw with SQLite.
PostgreSQL
The process of selecting records from a PostgreSQL table with the
psycopg2 Python SQL module is similar to what you did with SQLite and MySQL. Again, you’ll use cursor.execute() followed by .fetchall() to select records from your PostgreSQL table. The following script selects all the records from the users table and prints them to the console:def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except OperationalError as e:
print(f"The error '{e}' occurred")
select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
Again, the output will be similar to what you’ve seen before.
Updating Table Records
In the last section, you saw how to select records from SQLite, MySQL, and PostgreSQL databases. In this section, you’ll cover the process for updating records using the Python SQL libraries for SQLite, PostgresSQL, and MySQL.
SQLite
Updating records in SQLite is pretty straightforward. You can again make use of
execute_query() . As an example, you can update the description of the post with an id of 2 . First, SELECT the description of this post:select_post_description = "SELECT description FROM posts WHERE id = 2"
post_description = execute_read_query(connection, select_post_description)
for description in post_description:
print(description)
You should see the following output:
('The weather is very hot today',)
The following script updates the description:
update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
Now, if you execute the
SELECT query again, you should see the following result:('The weather has become pleasant now',)
The output has been updated.
MySQL
The process of updating records in MySQL with
mysql-connector-python is also a carbon copy of the sqlite3 Python SQL module. You need to pass the string query to cursor.execute() . For example, the following script updates the description of the post with an id of 2 :update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
Again, you’ve used your wrapper function
execute_query() to update the post description. PostgreSQL
The update query for PostgreSQL is similar to what you’ve seen with SQLite and MySQL. You can use the above scripts to update records in your PostgreSQL table.
Deleting Table Records
In this section, you’ll see how to delete table records using the Python SQL modules for SQLite, MySQL, and PostgreSQL databases. The process of deleting records is uniform for all three databases since the
DELETE query for the three databases is the same. SQLite
You can again use
execute_query() to delete records from YOUR SQLite database. All you have to do is pass the connection object and the string query for the record you want to delete to execute_query() . Then, execute_query() will create a cursor object using the connection and pass the string query to cursor.execute() , which will delete the records. As an example, try to delete the comment with an
id of 5 :delete_comment = "DELETE FROM comments WHERE id = 5"
execute_query(connection, delete_comment)
Now, if you select all the records from the
comments table, you’ll see that the fifth comment has been deleted. MySQL
The process for deletion in MySQL is also similar to SQLite, as shown in the following example:
delete_comment = "DELETE FROM comments WHERE id = 2"
execute_query(connection, delete_comment)
Here, you delete the second comment from the
sm_app database’s comments table in your MySQL database server. PostgreSQL
The delete query for PostgreSQL is also similar to SQLite and MySQL. You can write a delete query string by using the
DELETE keyword and then passing the query and the connection object to execute_query() . This will delete the specified records from your PostgreSQL database. Conclusão
In this tutorial, you’ve learned how to use three common Python SQL libraries.
sqlite3 , mysql-connector-python , and psycopg2 allow you to connect a Python application to SQLite, MySQL, and PostgreSQL databases, respectively. Now you can:
- Interact with SQLite, MySQL, or PostgreSQL databases
- Use three different Python SQL modules
- Execute SQL queries on various databases from within a Python application
However, this is just the tip of the iceberg! There are also Python SQL libraries for object-relational mapping , such as SQLAlchemy and Django ORM, that automate the task of database interaction in Python. You’ll learn more about these libraries in other tutorials in our Python databases section.