Antes de analisar o problema de desempenho de registros encaminhados e resolvê-lo, precisamos revisar a estrutura das tabelas do SQL Server.
Visão geral da estrutura da tabela
No SQL Server, a unidade fundamental do armazenamento de dados são as páginas de 8 KB . Cada página começa com um cabeçalho de 96 bytes que armazena as informações do sistema sobre essa página. Em seguida, as linhas da tabela serão armazenadas nas páginas de dados em série após o cabeçalho. No final da página, a tabela de deslocamento de linha, que contém uma entrada para cada linha, será armazenada oposta à sequência das linhas na página. Esta entrada de deslocamento de linha mostra a que distância o primeiro byte dessa linha está localizado desde o início da página.
O SQL Server nos fornece dois tipos de tabelas, com base na estrutura dessa tabela. O Agrupado A tabela armazena e classifica os dados nas páginas de dados com base nos valores predefinidos de coluna ou colunas de chave de índice clusterizado. Além disso, as páginas de dados na tabela Clusterizada são classificadas e vinculadas em uma lista vinculada com base nos valores de chave de índice clusterizado. A árvore B A estrutura do índice clusterizado fornece um método de acesso rápido a dados com base nos valores de chave do índice clusterizado. Se uma nova linha for inserida ou um valor de chave existente for atualizado na tabela Clusterizada, o SQL Server armazenará o novo valor na posição lógica correta que se ajuste ao tamanho da linha inserida sem quebrar os critérios de ordenação. Se o valor inserido ou atualizado for maior que o espaço disponível na página de dados, a página será dividida em duas páginas para ajustar o novo valor.
O segundo tipo de tabelas é o Heap tabela, na qual os dados não são classificados nas páginas de dados em nenhuma ordem e as páginas não estão vinculadas, pois não há índice clusterizado definido nessa tabela, para impor qualquer critério de classificação. Rastrear as páginas que não são classificadas em nenhum critério de ordenação ou vinculadas na tabela de heap não é uma missão fácil. Para simplificar o processo de rastreamento da alocação de página na tabela de heap, o SQL Server usa o Mapa de alocação de índice (IAM), a única conexão lógica entre as páginas de dados na tabela de heap, mantendo uma entrada para cada página de dados na tabela ou o índice na tabela do IAM. Para recuperar quaisquer dados da tabela de heap, o SQL Server Engine verifica o IAM para localizar a extensão, que forma 8 páginas que armazenam os dados solicitados.
Emissão de registros encaminhados
Se uma nova linha for inserida na tabela de heap, o SQL Server Engine verificará o Espaço Livre da Página (PFS) para rastrear o status de alocação e o uso de espaço em cada página de dados para encontrar o primeiro local disponível nas páginas de dados que se ajusta ao tamanho da linha inserida. Em seguida, a linha será adicionada à página selecionada. Se o valor inserido for maior que o espaço disponível nas páginas de dados, uma nova página será adicionada a essa tabela para poder inserir o novo valor.
Por outro lado, se os dados existentes na tabela de heap forem modificados, por exemplo, atualizamos uma string de comprimento variável com tamanho de dados maior, e o espaço atual não couber nos novos dados, os dados serão movidos para um formato físico diferente. local e o Registro encaminhado será inserido na tabela de heap na localização original dos dados, para apontar para a nova localização desses dados e simplificar a localização dos dados de rastreamento. O novo local de dados contém também um ponteiro que aponta para o ponteiro de encaminhamento para mantê-lo atualizado no caso de mover os dados do novo local e evitar a longa cadeia de ponteiros de encaminhamento ou excluí-lo. Isso pode levar à remoção do registro de encaminhamento também.
Embora o método de redirecionamento de registros encaminhados reduza a necessidade de operações de reconstrução de tabelas com uso intensivo de recursos e índices não clusterizados para atualizar os endereços de dados sempre que o local dos dados for alterado, ele também dobra o número de leituras necessárias para recuperar os dados. O SQL Server visitará primeiro o local antigo, onde encontrará o registro encaminhado que o redireciona para o novo local de dados. Em seguida, ele lerá os dados solicitados, realizando a operação de leitura duas vezes. Além disso, o problema de registros encaminhados leva à alteração dos dados sequenciais lidos em leitura de dados aleatórios, afetando negativamente o desempenho da operação de recuperação de dados ao longo do tempo.
Vamos criar o seguinte heap ForwardRecordDemo tabela usando a instrução CREATE TABLE T-SQL abaixo:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Em seguida, preencha essa tabela com 3K registros para fins de teste, usando a instrução INSERT INTO T-SQL abaixo:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Identificando o problema de registros encaminhados
As informações sobre o tipo de tabela e o número de páginas consumidas durante o armazenamento dos dados da tabela, bem como a porcentagem de fragmentação do índice e o número de registros encaminhados para uma tabela específica, podem ser visualizados consultando o sys.dm_db_index_physical_stats função de gerenciamento dinâmico do sistema e passando para o DETALHE modo para retornar o número de registros de encaminhamento. Para fazer isso, use o script T-SQL abaixo:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Como você pode ver no resultado da consulta, a tabela anterior é a tabela de heap que não possui índice clusterizado criado nela para classificar os dados nas páginas e vincular as páginas entre si. As 3 mil linhas inseridas na tabela são atribuídas a 15 páginas de dados, sem registros encaminhados e percentual de fragmentação zero, conforme resultado abaixo:

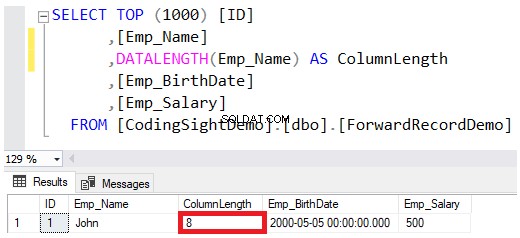
Quando você define o tipo de dados de uma coluna como VARCHAR ou NVARCHAR, o valor especificado na definição do tipo de dados é o tamanho máximo permitido para essa string, sem reservar totalmente esse valor enquanto salva os valores nas páginas de dados. Por exemplo, o João O nome do funcionário inserido nessa tabela reservará apenas 8 bytes dos 100 bytes máximos para essa coluna, levando em consideração que salvar a string NVARCHAR dobrará os bytes necessários para a coluna VARCHAR, conforme mostrado no DATALENGTH resultado da função abaixo:
Se você deseja atualizar o valor da coluna Emp_Name para incluir o nome completo do funcionário John, use a instrução UPDATE abaixo:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
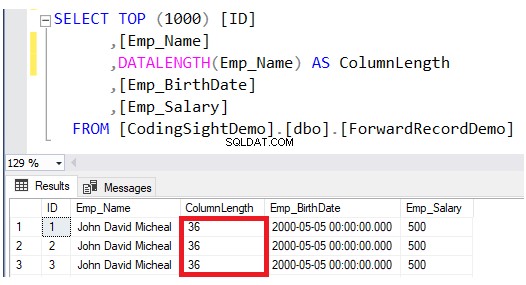
Verifique o comprimento da coluna atualizada usando o DATALENGTH função. Você verá que o comprimento da coluna Emp_Name nas linhas atualizadas foi expandido em 28 bytes por cada coluna, que é cerca de 3,5 páginas de dados adicionais a essa tabela, conforme mostrado no resultado abaixo:
Em seguida, verifique o número de registros encaminhados após a operação de atualização consultando a função de gerenciamento dinâmico do sistema sys.dm_db_index_physical_stats. Para fazer isso, use o script T-SQL abaixo:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Como você pode ver, atualizar a coluna Emp_Name em registros de 1K com valores de string maiores, sem adicionar nenhum novo registro, atribuirá o 5 extra páginas para essa tabela, em vez de 3,5 páginas como esperado anteriormente. Isso acontecerá devido à geração de 484 registros encaminhados para apontar para os novos locais dos dados movidos. Isso pode fazer com que a tabela seja 33% fragmentado, como mostrado claramente abaixo:

Novamente, se você conseguir atualizar o valor da coluna Emp_Name para incluir o nome completo do funcionário da Zaid, use a instrução UPDATE abaixo:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
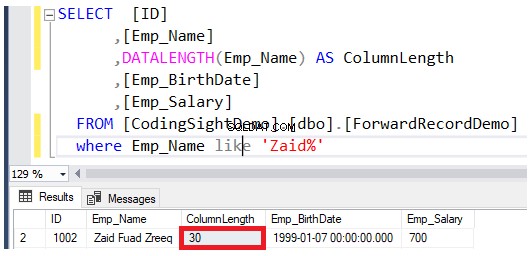
Verifique o comprimento da coluna atualizada usando o DATALENGTH função. Você verá que o comprimento da coluna Emp_Name nas linhas atualizadas foi expandido em 22 bytes por cada coluna, que é cerca de 2,7 páginas de dados adicionais adicionadas a essa tabela, conforme mostrado no resultado abaixo:
Verifique o número de registros encaminhados após realizar a operação de atualização. Você pode fazer isso consultando a função de gerenciamento dinâmico do sistema sys.dm_db_index_physical_stats usando o mesmo script T-SQL abaixo:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
O resultado mostrará que atualizar a coluna Emp_Name nos outros 1K registros com valores de string maiores sem inserir nenhuma nova linha atribuirá outro 4 páginas para essa tabela, em vez de 2,7 páginas como esperado. Isso acontecerá devido à geração de 417 adicionais registros encaminhados para apontar para os novos locais dos dados movidos e mantendo os mesmos 33% porcentagem de fragmentação, conforme mostrado abaixo:

Corrigindo o problema de registros encaminhados
A maneira mais simples de corrigir o problema de registros encaminhados é estimar o comprimento máximo da string que será armazenada na coluna e atribuí-la usando o tamanho fixo tipo de dados para essa coluna em vez de usar o tipo de dados de comprimento variável. A maneira permanente ideal de corrigir o problema de registros encaminhados é adicionar o índice clusterizado para aquela mesa. Dessa forma, a tabela será completamente convertida em uma tabela Clusterizada, que é classificada com base nos valores da chave do índice Clusterizado. Ele controlará a ordem dos dados existentes, os dados recém-inseridos e atualizados que não cabem no espaço disponível atual na página de dados, conforme descrito anteriormente na introdução deste artigo.
Se adicionar o índice clusterizado a essa tabela não for uma opção para requisitos específicos, como as tabelas de preparo ou as tabelas ETL, você poderá superar o problema de registros encaminhados temporariamente monitorando os registros encaminhados e reconstruindo a tabela de heap para removê-la, o que também atualizar todos os índices não clusterizados nessa tabela de heap. A funcionalidade de reconstruir a tabela de heap é introduzida no SQL Server 2008, usando o ALTER TABLE…REBUILD Comando T-SQL.
Para ver o impacto no desempenho dos Registros Encaminhados nas consultas de recuperação de dados, vamos executar a consulta SELECT que realiza a pesquisa com base nos valores da coluna Nome_Emp. No entanto, antes de executar a consulta, habilite as estatísticas TIME e IO:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Como resultado, você verá que 925 as operações lógicas de leitura são executadas para recuperar os dados solicitados em 84ms como mostrado abaixo:

Para reconstruir a tabela de heap para remover todos os registros encaminhados, use o comando ALTER TABLE…REBUILD:
ALTER TABLE ForwardRecordDemo REBUILD;
Execute a mesma instrução SELECT novamente:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
As estatísticas TIME e IO mostrarão que apenas 21 operações de leitura lógica em comparação com os 925 as operações de leitura lógica com os registros encaminhados incluídos são executadas para recuperar os dados solicitados em 79ms :

Para verificar o número de registros encaminhados após reconstruir a tabela de heap, execute a função de gerenciamento dinâmico do sistema sys.dm_db_index_physical_stats, use o mesmo script T-SQL abaixo:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Você verá que apenas 21 páginas, com os 3 anteriores páginas consumidas para os registros encaminhados, são atribuídas a essa tabela para armazenar os dados, que é semelhante ao resultado estimado que obtivemos durante as operações de inserção e atualização de dados (15+3,5+2,7). Depois de reconstruir a tabela de heap, todos os registros encaminhados são removidos agora. Como resultado, temos uma tabela sem fragmentação:

A questão dos registros encaminhados é uma questão importante de desempenho que os administradores de banco de dados devem considerar ao planejar o manutenção da mesa heap. Os resultados anteriores são recuperados de nossa tabela de testes que contém apenas 3 mil registros. Você pode imaginar o número de páginas que serão desperdiçadas pelos registros encaminhados e a degradação do desempenho de E/S, devido à leitura de um grande número de registros encaminhados ao ler tabelas enormes!
Referências:
- Guia de arquitetura de páginas e extensões
- dm_db_index_physical_stats (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- Saber sobre "Registros encaminhados" pode ajudar a diagnosticar problemas de desempenho difíceis de encontrar