Você provavelmente sabe como inserir registros em uma tabela usando uma ou várias cláusulas VALUES. Você também sabe como fazer inserções em massa usando SQL INSERT INTO SELECT. Mas você ainda clicou no artigo. Trata-se de lidar com duplicatas?
Muitos artigos cobrem SQL INSERT INTO SELECT. Google ou Bing e escolha o título que você mais gosta – ele vai fazer. Também não vou cobrir exemplos básicos de como isso é feito. Em vez disso, você verá exemplos de como usá-lo E lidar com duplicatas ao mesmo tempo . Então, você pode fazer esta mensagem familiar de seus esforços de INSERT:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Mas as primeiras coisas primeiro.

[id do formulário de envio=”12989″]
Preparar dados de teste para SQL INSERT INTO SELECT Amostras de código
Eu meio que pensando em macarrão desta vez. Então, vou usar dados sobre pratos de massa. Encontrei uma boa lista de pratos de massa na Wikipedia que podemos usar e extrair no Power BI usando uma fonte de dados da web. Eu digitei o URL da Wikipédia. Então eu especifiquei os dados de 2 tabelas da página. Limpei um pouco e copiei os dados para o Excel.
Agora temos os dados – você pode baixá-los aqui. É bruto porque vamos fazer 2 tabelas relacionais com isso. Usar INSERT INTO SELECT nos ajudará nessa tarefa,
Importar os dados no SQL Server
Você pode usar o SQL Server Management Studio ou o dbForge Studio for SQL Server para importar 2 planilhas para o arquivo Excel.
Crie um banco de dados em branco antes de importar os dados. Eu nomeei as tabelas dbo.ItalianPastaDishes e dbo.NonItalianPastaDishes .
Crie mais 2 tabelas
Vamos definir as duas tabelas de saída com o comando SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Nota:Existem índices exclusivos criados em duas tabelas. Isso nos impedirá de inserir registros duplicados posteriormente. As restrições tornarão essa jornada um pouco mais difícil, mas emocionante.
Agora que estamos prontos, vamos mergulhar.
5 maneiras fáceis de lidar com duplicatas usando SQL INSERT INTO SELECT
A maneira mais fácil de lidar com duplicatas é remover restrições exclusivas, certo?
Errado!
Sem restrições exclusivas, é fácil cometer um erro e inserir os dados duas vezes ou mais. Nós não queremos isso. E se tivermos uma interface de usuário com uma lista suspensa para escolher a origem do prato de massa? As duplicatas deixarão seus usuários felizes?
Portanto, remover as restrições exclusivas não é uma das cinco maneiras de manipular ou excluir registros duplicados no SQL. Temos melhores opções.
1. Usando INSERT INTO SELECT DISTINCT
A primeira opção de como identificar registros SQL em SQL é usar DISTINCT em seu SELECT. Para explorar o caso, preencheremos a Origem tabela. Mas primeiro, vamos usar o método errado:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Isso acionará os seguintes erros duplicados:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Há um problema ao tentar selecionar linhas duplicadas no SQL. Para iniciar a verificação SQL para duplicatas que existiam antes, executei a parte SELECT da instrução INSERT INTO SELECT:
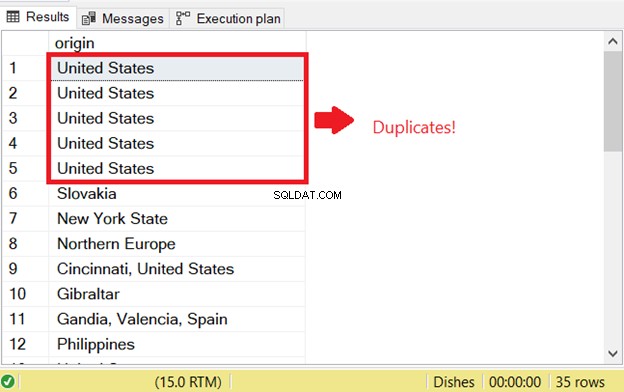
Esse é o motivo do primeiro erro de duplicação do SQL. Para evitar isso, adicione a palavra-chave DISTINCT para tornar o conjunto de resultados exclusivo. Segue o código correto:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Ele insere os registros com sucesso. E terminamos com a Origem tabela.
O uso de DISTINCT fará registros exclusivos da instrução SELECT. No entanto, isso não garante que não existam duplicatas na tabela de destino. É bom quando você tem certeza de que a tabela de destino não possui os valores que deseja inserir.
Portanto, não execute essas instruções mais de uma vez.
2. Usando WHERE NOT IN
Em seguida, preenchemos os PastaDishes tabela. Para isso, precisamos primeiro inserir registros do ItalianPastaDishes tabela. Aqui está o código:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Desde ItalianPastaDishes contém dados brutos, precisamos juntar a Origem texto em vez do OriginID . Agora, tente executar o mesmo código duas vezes. A segunda vez que ele for executado não terá registros inseridos. Isso acontece por causa da cláusula WHERE com o operador NOT IN. Ele filtra os registros que já existem na tabela de destino.
Em seguida, precisamos preencher os PastaDishes tabela dos NonItalianPastaDishes tabela. Como estamos apenas no segundo ponto deste post, não vamos inserir tudo.
Escolhemos pratos de massa dos Estados Unidos e das Filipinas. Aqui vai:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
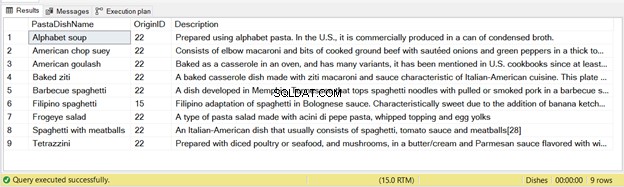
Há 9 registros inseridos a partir desta declaração – veja a Figura 2 abaixo:
Novamente, se você executar o código acima duas vezes, a segunda execução não terá registros inseridos.
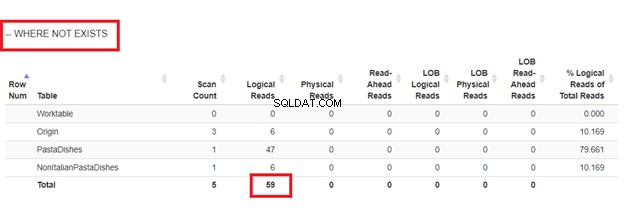
3. Usando WHERE NOT EXISTS
Outra maneira de encontrar duplicatas no SQL é usar NOT EXISTS na cláusula WHERE. Vamos tentar com as mesmas condições da seção anterior:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
O código acima irá inserir os mesmos 9 registros que você viu na Figura 2. Isso evitará inserir os mesmos registros mais de uma vez.
4. Usando SE NÃO EXISTE
Às vezes você pode precisar implantar uma tabela no banco de dados e é necessário verificar se já existe uma tabela com o mesmo nome para evitar duplicatas. Neste caso, o comando SQL DROP TABLE IF EXISTS pode ser de grande ajuda. Outra maneira de garantir que você não inserirá duplicatas é usar IF NOT EXISTS. Novamente, usaremos as mesmas condições da seção anterior:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
O código acima verificará primeiro a existência de 9 registros. Se retornar verdadeiro, INSERT prosseguirá.
5. Usando COUNT(*) =0
Por fim, o uso de COUNT(*) na cláusula WHERE também pode garantir que você não insira duplicatas. Aqui está um exemplo:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Para evitar duplicatas, COUNT ou registros retornados pela subconsulta acima devem ser zero.
Observação :Você pode projetar qualquer consulta visualmente em um diagrama usando o recurso Construtor de Consultas do dbForge Studio para SQL Server.
Comparando maneiras diferentes de lidar com duplicatas com SQL INSERT INTO SELECT
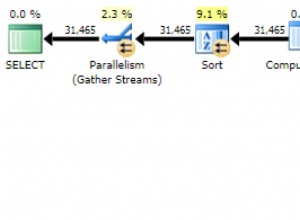
4 seções usaram a mesma saída, mas abordagens diferentes para inserir registros em massa com uma instrução SELECT. Você pode se perguntar se a diferença está apenas na superfície. Podemos verificar suas leituras lógicas de STATISTICS IO para ver como elas são diferentes.
Usando WHERE NOT IN:
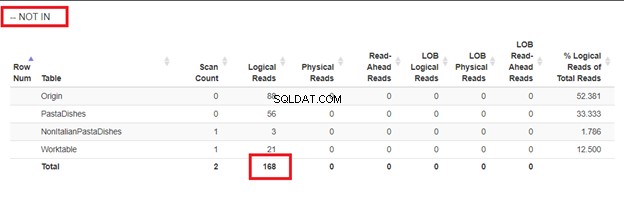
Usando NOT EXISTS:
Usando SE NÃO EXISTE:
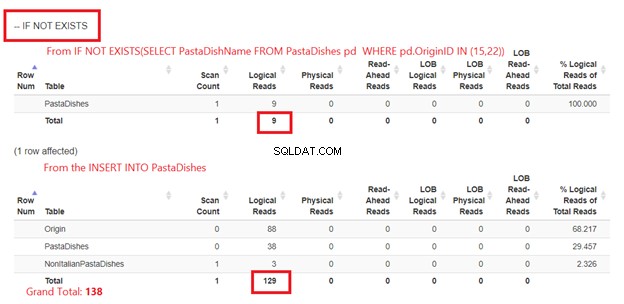
A Figura 5 é um pouco diferente. 2 leituras lógicas aparecem para os PastaDishes tabela. A primeira é de IF NOT EXISTS(SELECT PastaDishName de Pratos de Massa ONDE OriginID IN (15,22)). O segundo é da instrução INSERT.
Finalmente, usando COUNT(*) =0
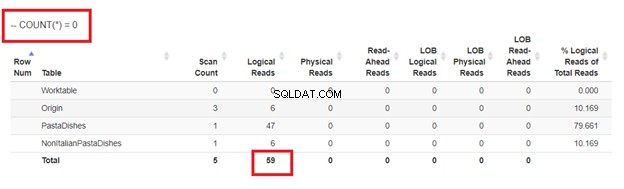
Das leituras lógicas de 4 abordagens que tivemos, a melhor escolha é WHERE NOT EXISTS ou COUNT(*) =0. Quando inspecionamos seus planos de execução, vemos que eles têm o mesmo QueryHashPlan . Assim, eles têm planos semelhantes. Enquanto isso, o menos eficiente está usando NOT IN.
Isso significa que WHERE NOT EXISTS é sempre melhor do que NOT IN? De jeito nenhum.
Sempre inspecione as leituras lógicas e o Plano de Execução de suas consultas!
Mas antes de concluir, precisamos terminar a tarefa em mãos. Em seguida, inseriremos o restante dos registros e inspecionaremos os resultados.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Navegar na lista de 179 pratos de massa da Ásia à Europa me deixa com fome. Confira uma parte da lista da Itália, Rússia e mais abaixo:

Conclusão
Evitar duplicatas no SQL INSERT INTO SELECT não é tão difícil assim. Você tem operadores e funções à mão para levá-lo a esse nível. Também é um bom hábito verificar o Plano de Execução e leituras lógicas para comparar qual é melhor.
Se você acha que outra pessoa se beneficiará deste post, compartilhe-o em suas plataformas de mídia social favoritas. E se você tiver algo a acrescentar que esquecemos, informe-nos na seção de comentários abaixo.