[ Parte 1 | Parte 2 | Parte 3]
No espírito dos recentes discursos de Grant Fritchey e dos esforços de Erin Stellato desde antes de nos conhecermos, quero entrar na onda para trombetear e promover a ideia de abandonar o rastreamento em favor de Eventos Estendidos. Quando alguém diz rastrear , a maioria das pessoas pensa imediatamente em Profiler . Embora o Profiler seja seu próprio pesadelo especial, hoje eu queria falar sobre o rastreamento padrão do SQL Server.
Em nosso ambiente, ele está habilitado em todos os mais de 200 servidores de produção e coleta muito lixo que nunca iremos investigar. Tanto lixo, na verdade, que eventos importantes que podemos achar úteis para solucionar problemas são lançados dos arquivos de rastreamento antes que tenhamos a chance. Então comecei a considerar a perspectiva de desligá-lo, porque:
- não é gratuito (a sobrecarga do observador da própria atividade de rastreamento, a E/S envolvida na gravação nos arquivos de rastreamento e o espaço que eles consomem);
- na maioria dos servidores, nunca foi analisado; em outros, raramente; e,
- é fácil reativar para solução de problemas específica e isolada.
Algumas outras coisas afetam o valor do rastreamento padrão. Não é configurável de forma alguma - você não pode alterar quais eventos ele coleta, não pode adicionar filtros e não pode controlar quantos arquivos ele mantém (5), quão grande eles podem obter (20 MB cada) , ou onde eles estão armazenados (
SERVERPROPERTY('ErrorLogFileName') ). Portanto, estamos completamente à mercê da carga de trabalho — em qualquer servidor, não podemos prever até onde os dados podem ir (eventos com TextData maiores valores, por exemplo, podem ocupar muito mais espaço e enviar eventos mais antigos mais rapidamente). Às vezes pode voltar uma semana, outras vezes pode voltar apenas alguns minutos. Analisando o estado atual
Executei o código a seguir em 224 instâncias de produção, apenas para entender que tipo de ruído está preenchendo o rastreamento padrão em nosso ambiente. Isso provavelmente é mais complicado do que precisa ser e nem é tão complexo quanto a consulta final que usei, mas é um ponto de partida decente para analisar o detalhamento dos tipos de eventos de alto nível que estão sendo capturados no momento:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (O predicado EventSubClass existe para evitar a contagem dupla de eventos DDL.Para um mapa dos valores EventClass, listei-os nesta resposta no Stack Exchange.)
E os resultados não são bonitos (resultados típicos de um servidor aleatório). O seguinte não representa a saída exata dessa consulta, mas passei algum tempo agregando os resultados em um formato mais digerível, para ver quanto dos dados era útil e quanto era ruído (clique para ampliar):
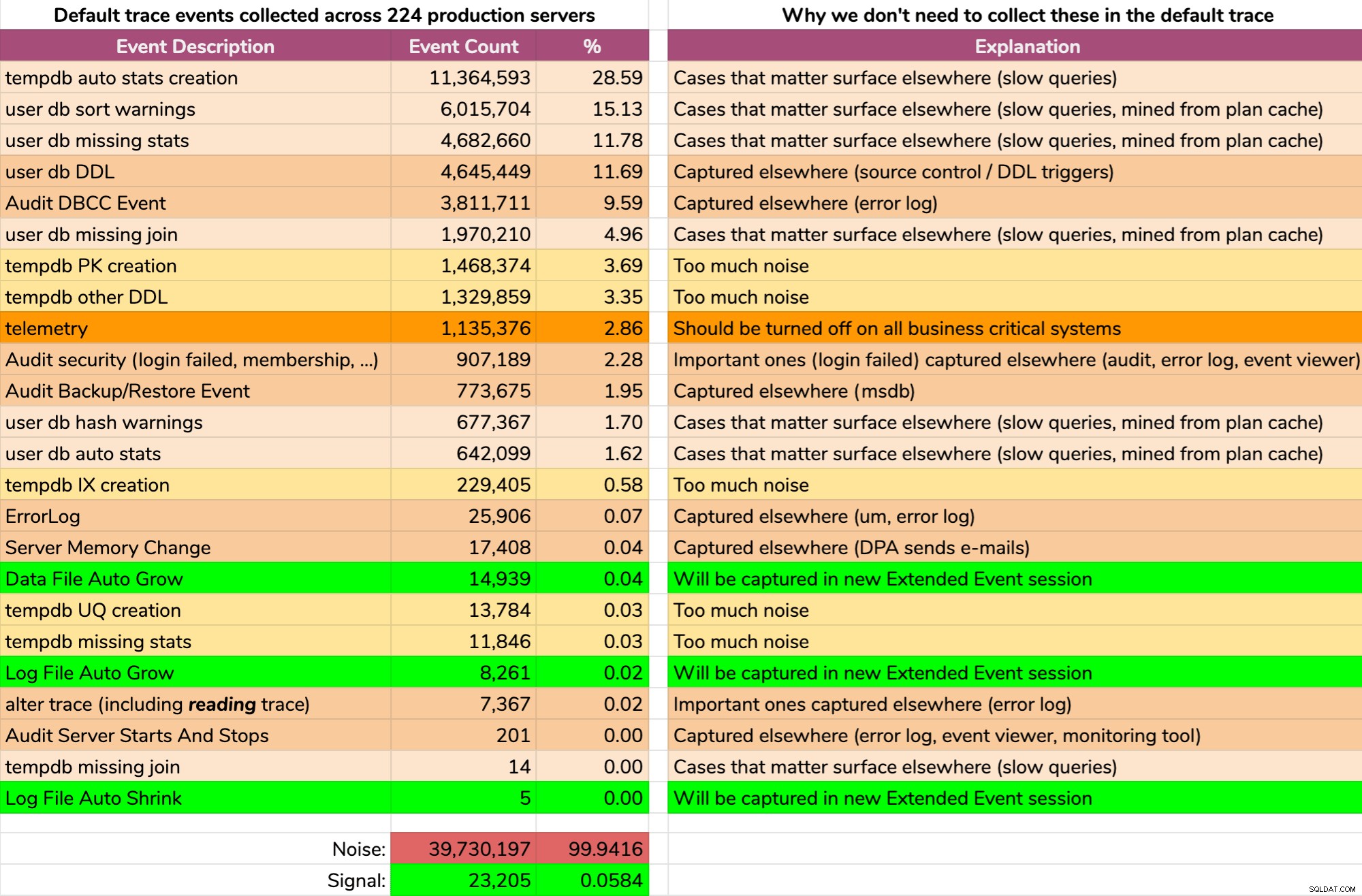
Quase todo o ruído (99,94%). A única coisa útil que precisávamos do rastreamento padrão eram eventos de crescimento de arquivo e redução, já que eram a única coisa que não estávamos capturando em outro lugar de uma forma ou de outra. Mas nem sempre podemos confiar nisso, porque os dados são removidos muito rapidamente.
Outra maneira de dividir os dados:evento mais antigo por instância. Algumas instâncias tinham tanto ruído que não conseguiam manter os dados de rastreamento padrão por mais de alguns minutos! Desfoquei os nomes dos servidores, mas são dados reais (estes são os 20 servidores com o menor histórico - clique para ampliar):
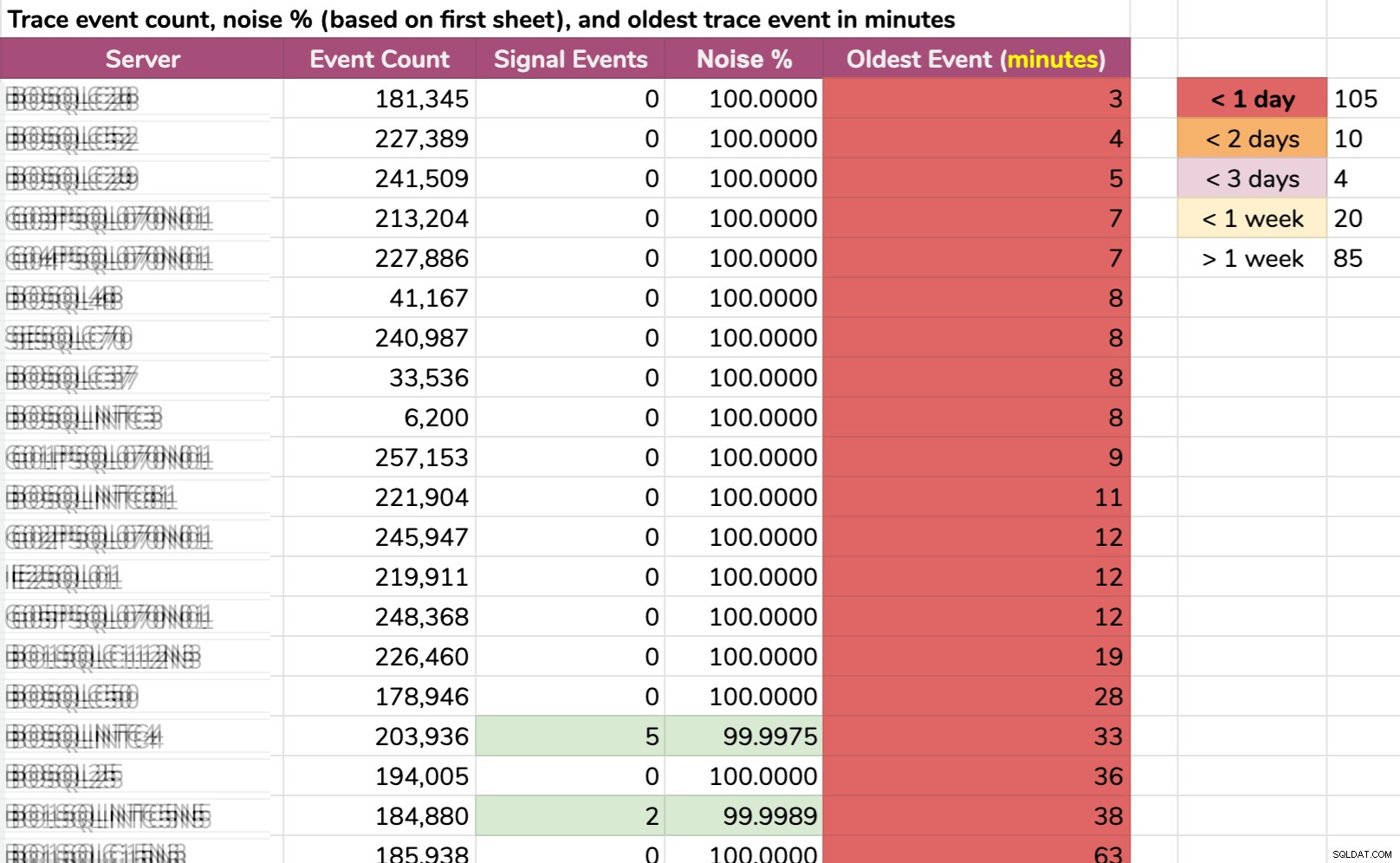
Mesmo que o rastreamento estivesse coletando somente informação relevante, e algo interessante acontecesse, teríamos que agir rapidamente para pegá-la, dependendo do servidor. Se aconteceu:
- há 20 minutos , ele já teria desaparecido em 15 instâncias .
- esta vez ontem , ele desapareceria em 105 instâncias .
- há dois dias , ele desapareceria em 115 instâncias .
- há mais de uma semana , ele desapareceria em 139 instâncias .
Tínhamos um punhado de servidores na outra extremidade também, mas eles não são interessantes nesse contexto; esses servidores são assim simplesmente porque nada de interessante acontece lá (por exemplo, eles não estão ocupados ou fazem parte de qualquer carga de trabalho crítica).
No lado positivo…
Investigar o rastreamento padrão revelou algumas configurações incorretas em alguns de nossos servidores:
- Vários servidores ainda tinham telemetria ativada . Sou totalmente a favor da Microsoft em determinados ambientes, mas sem custos indiretos em sistemas críticos de negócios.
- Algumas tarefas de sincronização em segundo plano estavam adicionando membros às funções às cegas , repetidamente, sem verificar se eles já estavam nessas funções. Isso não é prejudicial em si, especialmente porque esses eventos não preencherão mais o rastreamento padrão, mas provavelmente também estão preenchendo as auditorias com ruído, e provavelmente há outras operações de reaplicação cegas acontecendo no mesmo padrão.
- Alguém ativou a redução automática em algum lugar (bom luto!), então isso era algo que eu queria rastrear e evitar que acontecesse novamente (o novo XE também capturará esses eventos).
Isso levou a tarefas de acompanhamento para corrigir esses problemas e/ou adicionar condições à automação existente já em vigor. Assim, podemos evitar a recorrência sem depender apenas de ter a sorte de encontrá-los em alguma futura revisão de rastreamento padrão, antes de serem lançados.
…mas o problema continua
Caso contrário, tudo é informação sobre a qual não podemos agir ou, conforme descrito no gráfico acima, eventos que já capturamos em outro lugar. E, novamente, os únicos dados em que estou interessado do rastreamento padrão que ainda não capturamos por outros meios são eventos relacionados ao crescimento e redução do arquivo (mesmo que o rastreamento padrão apenas capture a variedade automática).
Mas o maior problema não é realmente o volume do ruído. Eu posso lidar com grandes arquivos de rastreamento massivos com muito lixo, já que as cláusulas WHERE foram inventadas exatamente para esse propósito. O verdadeiro problema é que eventos importantes estavam desaparecendo muito rapidamente.
A resposta
A resposta, pelo menos em nosso cenário, foi simples:desabilite o rastreamento padrão, já que não vale a pena executá-lo se não for confiável.
Mas dada a quantidade de ruído acima, o que deve substituí-lo? Nada?
Você pode querer uma sessão de eventos estendidos que capture tudo o rastreamento padrão capturado. Em caso afirmativo, Jonathan Kehayias o protege. Isso lhe daria as mesmas informações, mas com controle sobre coisas como retenção, onde os dados são armazenados e, à medida que você se sente mais confortável, a capacidade de remover alguns dos eventos mais barulhentos ou menos úteis, gradualmente, ao longo do tempo.
Meu plano era um pouco mais agressivo, e rapidamente se tornou um processo "simples" para realizar o seguinte em todos os servidores do ambiente (via CMS):
- desenvolva uma sessão de eventos estendidos que capture apenas eventos de alteração de arquivo (manuais e automáticos)
- desative o rastreamento padrão
- criar uma visualização para simplificar o consumo de dados de destino por nossas equipes
Observe que não estou sugerindo que você desative cegamente o rastreamento padrão , apenas explicando por que escolhi fazê-lo em nosso ambiente. Nas próximas postagens desta série, mostrarei a nova sessão de Eventos Estendidos, a exibição que expõe os dados subjacentes, o código que usei para implantar essas alterações em todos os servidores e os possíveis efeitos colaterais que você deve ter em mente.
[ Parte 1 | Parte 2 | Parte 3]