De um modo geral, o melhor tipo de classificação é aquele que é evitado completamente. Com indexação cuidadosa e, às vezes, alguma escrita de consulta criativa, muitas vezes podemos remover a necessidade de um operador Sort dos planos de execução. Onde os dados a serem classificados são grandes, evitar esse tipo de classificação pode produzir melhorias de desempenho muito significativas.
O segundo melhor tipo de classificação é aquele que não podemos evitar, mas que reserva uma quantidade apropriada de memória e usa toda ou a maior parte dela para fazer algo que valha a pena. Ser valioso pode assumir muitas formas. Às vezes, um Sort pode mais do que se pagar, permitindo uma operação posterior que funciona com muito mais eficiência na entrada classificada. Outras vezes, o Sort é simplesmente necessário, e só precisamos torná-lo o mais eficiente possível.
Depois vêm os Sorts que geralmente queremos evitar:aqueles que reservam muito mais memória do que precisam e aqueles que reservam muito pouco. O último caso é o que a maioria das pessoas se concentra. Com memória insuficiente reservada (ou disponível) para concluir a operação de classificação necessária na memória, um operador Sort irá, com poucas exceções, derramar linhas de dados para tempdb . Na realidade, isso quase sempre significa escrever páginas de classificação no armazenamento físico (e lê-las mais tarde, é claro).
Nas versões modernas do SQL Server, uma classificação derramada resulta em um ícone de aviso nos planos pós-execução, que pode incluir detalhes sobre quantos dados foram derramados, quantos threads estavam envolvidos e o nível de derramamento.
Antecedentes:Níveis de derramamento
Considere a tarefa de ordenar 4000 MB de dados, quando temos apenas 500 MB de memória disponível. Obviamente, não podemos ordenar todo o conjunto na memória de uma só vez, mas podemos dividir a tarefa:
Primeiro lemos 500 MB de dados, classificamos esse conjunto na memória e gravamos o resultado no disco. Fazer isso um total de 8 vezes consome toda a entrada de 4.000 MB, resultando em 8 conjuntos de dados classificados de 500 MB de tamanho. A segunda etapa é realizar uma mesclagem de 8 vias dos conjuntos de dados classificados. Observe que uma mesclagem é necessário, não uma simples concatenação dos conjuntos, uma vez que os dados só são garantidos para serem classificados conforme necessário dentro de um conjunto específico de 500 MB no estágio intermediário.
Em princípio, poderíamos ler e mesclar uma linha por vez de cada uma das oito execuções de classificação, mas isso não seria muito eficiente. Em vez disso, lemos a primeira parte de cada classificação de volta à memória, digamos 60 MB. Isso consome 8 x 60 MB =480 MB dos 500 MB que temos disponíveis. Podemos então executar com eficiência a mesclagem de 8 vias na memória por um tempo, armazenando em buffer a saída classificada final com os 20 MB de memória ainda disponíveis. À medida que cada um dos buffers de memória de execução de classificação se esvazia, lemos uma nova seção dessa execução de classificação na memória. Depois que todas as execuções de classificação forem consumidas, a classificação estará concluída.
Existem alguns detalhes e otimizações adicionais que podemos incluir, mas esse é o esboço básico de um derramamento de Nível 1, também conhecido como derramamento de passagem única. Uma única passagem extra sobre os dados é necessária para produzir a saída final classificada.
Agora, uma mesclagem de n vias poderia teoricamente acomodar um tipo de qualquer tamanho, em qualquer quantidade de memória, simplesmente aumentando o número de conjuntos intermediários classificados localmente. O problema é que, à medida que 'n' aumenta, acabamos lendo e gravando pedaços menores de dados. Por exemplo, classificar 400 GB de dados em 500 MB de memória significaria algo como uma mesclagem de 800 vias, com apenas cerca de 0,6 MB de cada conjunto classificado intermediário na memória a qualquer momento (800 x 0,6 MB =480 MB, deixando algum espaço para um buffer de saída).
Várias passagens de mesclagem podem ser usadas para contornar isso. A ideia geral é mesclar progressivamente pequenos pedaços em pedaços maiores, até que possamos produzir com eficiência o fluxo de saída classificado final. No exemplo, isso pode significar mesclar 40 dos 800 conjuntos classificados de primeira passagem por vez, resultando em 20 partes maiores, que podem ser mescladas novamente para formar a saída. Com um total de duas passagens extras sobre os dados, isso seria um vazamento de Nível 2 e assim por diante. Felizmente, um aumento linear no nível de derramamento permite um aumento exponencial no tamanho da classificação, portanto, os níveis de derramamento de classificação profunda raramente são necessários.
O derramamento de "Nível 15.000"
Neste ponto, você pode estar se perguntando que combinação de pequena concessão de memória e enorme tamanho de dados poderia resultar em um derramamento de classificação de nível 15.000. Tentando classificar toda a Internet em 1 MB de memória? Possivelmente, mas isso é muito difícil de demonstrar. Para ser honesto, não tenho ideia se um nível de derramamento tão genuinamente alto é possível no SQL Server. O objetivo aqui (uma trapaça, com certeza) é fazer o SQL Server reportar um derramamento de nível 15.000.
O ingrediente chave é o particionamento. Desde o SQL Server 2012, temos permitido um máximo (conveniente) de 15.000 partições por objeto (suporte para 15.000 partições também está disponível no 2008 SP2 e 2008 R2 SP1, mas você deve habilitá-lo manualmente por banco de dados e estar ciente de todas as as advertências).
A primeira coisa que precisamos é de uma função de partição de 15.000 elementos e um esquema de partição associado. Para evitar um bloco de código embutido realmente enorme, o script a seguir usa SQL dinâmico para gerar as instruções necessárias:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); O script é bastante fácil de modificar para um número menor caso sua configuração tenha dificuldades com 15.000 partições (particularmente do ponto de vista da memória, como veremos em breve). As próximas etapas são criar uma tabela de heap normal (não particionada) com uma única coluna de inteiros e, em seguida, preenchê-la com os inteiros de 1 a 15.000 inclusive:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Isso deve ser concluído em 100ms ou mais. Se você tiver uma tabela de números disponível, sinta-se à vontade para usá-la para uma experiência mais baseada em conjuntos. A forma como a tabela base é preenchida não é importante. Para obter nosso derramamento de 15.000 níveis, tudo o que precisamos fazer agora é criar um índice clusterizado particionado na tabela:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
O tempo de execução depende muito do sistema de armazenamento em uso. No meu laptop, usando um SSD de consumidor bastante típico de alguns anos atrás, leva cerca de 20 segundos, o que é bastante significativo, considerando que estamos lidando com apenas 15.000 linhas no total. Em uma VM do Azure de especificação bastante baixa com desempenho de E/S bastante terrível, o mesmo teste levou cerca de 20 minutos.
Análise
O plano de execução para a construção do índice é:
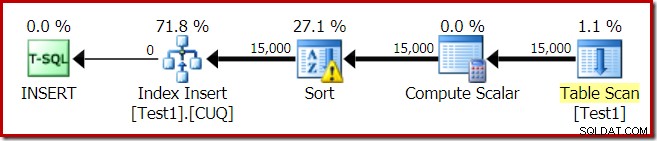
O Table Scan lê as 15.000 linhas de nossa tabela de heap. O Compute Scalar calcula o número da partição do índice de destino para cada linha usando a função interna
RangePartitionNew() . O Sort é a parte mais interessante do plano, então vamos analisá-lo com mais detalhes. Primeiro, o aviso de classificação, conforme exibido no Plan Explorer:

Um aviso semelhante do SSMS (retirado de uma execução diferente do script):
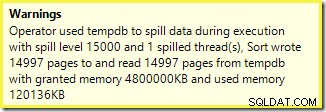
A primeira coisa a notar é o relatório de um nível de derramamento de 15.000 tipos, como prometido. Isso não é totalmente preciso, mas os detalhes são bastante interessantes. O Sort neste plano tem um
Partition ID propriedade, que normalmente não está presente: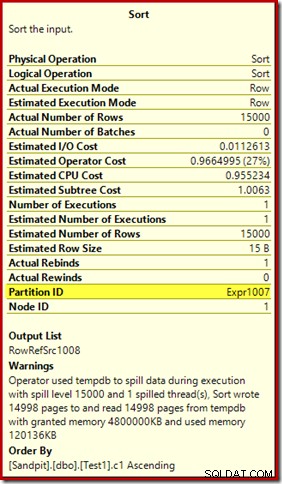
Esta propriedade é igual à definição da função de particionamento interno no Compute Scalar.
Esta é uma criação de índice não alinhado , porque a origem e o destino têm arranjos de particionamento diferentes. Nesse caso, essa diferença surge porque a tabela de heap de origem não é particionada, mas o índice de destino é. Como consequência, 15.000 classificações separadas são criadas em tempo de execução:uma por partição de destino não vazia. Cada uma dessas classificações atinge o nível 1, e o SQL Server soma todos esses vazamentos para fornecer o nível final de classificação de 15.000.
Os 15.000 tipos separados explicam a grande concessão de memória. Cada instância de classificação tem um tamanho mínimo de 40 páginas, que é 40 x 8 KB =320 KB. Portanto, as 15.000 classificações exigem 15.000 x 320 KB =4.800.000 KB de memória no mínimo. Isso é pouco menos de 4,6 GB de RAM reservados exclusivamente para uma consulta que classifica 15.000 linhas contendo uma única coluna inteira. E cada classificação se espalha para o disco, apesar de receber apenas uma linha! Se o paralelismo fosse usado para a construção do índice, a concessão de memória poderia ser inflada ainda mais pelo número de threads. Observe também que a única linha é gravada em uma página, o que explica o número de páginas gravadas e lidas de tempdb. Parece haver uma condição de corrida que significa que o número relatado de páginas geralmente é um pouco menor que 15.000.
Este exemplo reflete um caso extremo, é claro, mas ainda é difícil entender por que cada classificação derrama sua única linha em vez de classificar na memória que recebeu. Talvez isso seja por design por algum motivo, ou talvez seja simplesmente um bug. Seja qual for o caso, ainda é muito divertido ver algumas centenas de KB de dados demorando tanto com uma concessão de memória de 4,6 GB e um derramamento de 15.000 níveis. A menos que você o encontre em um ambiente de produção, talvez. De qualquer forma, é algo para se estar ciente.
O enganoso relatório de derramamento de 15.000 níveis se resume a limitações de representação na saída do plano de exibição. A questão fundamental é algo que surge em muitos lugares onde ocorrem ações repetidas, por exemplo, no lado interno da junção de loops aninhados. Certamente seria útil poder ver uma repartição mais precisa em vez de um total geral nesses casos. Com o tempo, essa área melhorou um pouco, então agora temos mais informações de plano por encadeamento ou por partição para algumas operações. Ainda há um longo caminho a percorrer.
Ainda é pouco útil que 15.000 derramamentos separados de nível 1 sejam relatados aqui como um único derramamento de 15.000 níveis.
Variações de teste
Este artigo é mais sobre como destacar as limitações das informações do plano e o potencial de baixo desempenho quando um número extremo de partições é usado, do que sobre como tornar a operação de exemplo específica mais eficiente, mas há algumas variações interessantes que eu quero ver também .
On-line, Classificar em tempdb
Executando a mesma operação de criação de índice particionado com
ONLINE = ON, SORT_IN_TEMPDB = ON não sofre da mesma enorme concessão de memória e derramamento:CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1); Observe que usar
ONLINE por si só não é suficiente. Na verdade, isso resulta no mesmo plano de antes com todos os mesmos problemas, mais uma sobrecarga adicional para construir cada partição de índice online. Para mim, isso resulta em tempo de execução de mais de um minuto. Deus sabe quanto tempo levaria em uma instância do Azure de baixa especificação com desempenho de E/S terrível. De qualquer forma, o plano de execução com
ONLINE = ON, SORT_IN_TEMPDB = ON é:
A classificação é executada antes que o número da partição de destino seja calculado. Ele não possui a propriedade Partition ID, portanto, é apenas uma classificação normal. Toda a operação é executada por cerca de dez segundos (ainda há muitas partições a serem criadas). Ele reserva menos de 3 MB de memória e usa no máximo 816 KB. Uma grande melhoria em relação a 4,6 GB e 15.000 vazamentos.
Primeiro índice, depois dados
Resultados semelhantes podem ser obtidos gravando os dados em uma tabela de heap primeiro:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Em seguida, crie uma tabela clusterizada particionada vazia e insira os dados do heap:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Isso leva cerca de dez segundos, com uma concessão de memória de 2 MB e sem derramamento:
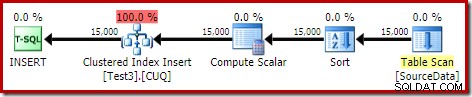
Obviamente, a classificação também pode ser evitada completamente indexando a tabela de origem (não particionada) e inserindo os dados em ordem de índice (a melhor classificação é nenhuma classificação, lembre-se).
Heap particionado, depois dados e índice
Para esta última variação, primeiro criamos um heap particionado e carregamos as 15.000 linhas de teste:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Esse script é executado por um segundo ou dois, o que é muito bom. A etapa final é criar o índice clusterizado particionado:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
Isso é um desastre completo, tanto do ponto de vista do desempenho quanto do ponto de vista das informações do plano de exibição. A operação em si é executada por pouco menos de um minuto, com o seguinte plano de execução:

Este é um plano de inserção colocado. O Constant Scan contém uma linha para cada id de partição. O lado interno do loop procura a partição atual do heap (sim, uma busca em um heap). A classificação tem uma propriedade de identificação de partição (apesar de ser constante por iteração de loop), portanto, há uma classificação por partição e o comportamento indesejável de derramamento. O aviso de estatísticas na tabela de heap é falso.
A raiz do plano de inserção indica que uma concessão de memória de 1 MB foi reservada, com um máximo de 144 KB usados:
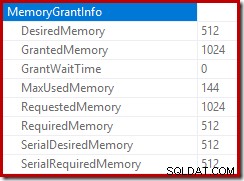
O operador de classificação não relata um derramamento de nível 15.000, mas de outra forma faz uma bagunça completa da matemática de iteração por loop envolvida:

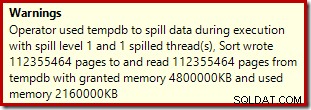
Monitorar a memória concede DMV durante a execução mostra que essa consulta realmente reserva apenas 1 MB, com um máximo de 144 KB usados em cada iteração do loop. (Por outro lado, a reserva de memória de 4,6 GB no primeiro teste é absolutamente genuína.) Isso é confuso, é claro.
O problema (como mencionado anteriormente) é que o SQL Server fica confuso sobre a melhor forma de relatar o que aconteceu em muitas iterações. Provavelmente não é prático incluir informações de desempenho do plano por partição por iteração, mas não há como fugir do fato de que o arranjo atual às vezes produz resultados confusos. Só podemos esperar que um dia seja encontrada uma maneira melhor de relatar esse tipo de informação, em um formato mais consistente.



