Visão geral
Este artigo discute duas abordagens diferentes disponíveis para remover linhas duplicadas de tabelas SQL, o que geralmente se torna difícil com o tempo à medida que os dados aumentam se isso não for feito a tempo.
A presença de linhas duplicadas é um problema comum que os desenvolvedores e testadores de SQL enfrentam de tempos em tempos, no entanto, essas linhas duplicadas se enquadram em várias categorias diferentes que discutiremos neste artigo.
Este artigo se concentra em um cenário específico, quando os dados inseridos em uma tabela de banco de dados levam à introdução de registros duplicados e, em seguida, examinaremos mais detalhadamente os métodos para remover duplicatas e, finalmente, remover as duplicatas usando esses métodos.
Preparando dados de amostra
Antes de começarmos a explorar as diferentes opções disponíveis para remover duplicatas, vale a pena neste momento configurar um banco de dados de exemplo que nos ajudará a entender as situações em que dados duplicados chegam ao sistema e as abordagens a serem usadas para erradicá-los .
Configurar banco de dados de amostra (UniversityV2)
Comece criando um banco de dados muito simples que consiste apenas em um Aluno mesa no início.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Preencher a Tabela do Aluno
Vamos adicionar apenas dois registros à tabela Aluno:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Verificação de dados
Veja a tabela que contém dois registros distintos no momento:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
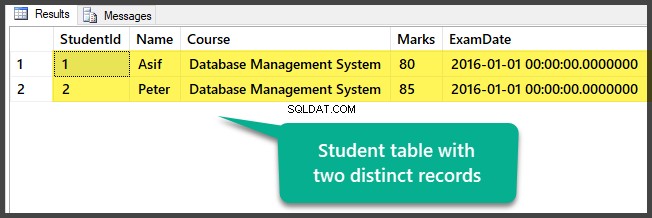
Você preparou com êxito os dados de amostra configurando um banco de dados com uma tabela e dois registros distintos (diferentes).
Vamos discutir agora alguns cenários potenciais em que duplicatas foram introduzidas e excluídas a partir de situações simples a ligeiramente complexas.
Caso 01:Adicionando e removendo duplicatas
Agora vamos introduzir linha(s) duplicada(s) na tabela Aluno.
Pré-condições
Nesse caso, diz-se que uma tabela tem registros duplicados se o Nome de um aluno , Curso , Marcas e Data do Exame coincidem em mais de um registro, mesmo que o ID do aluno é diferente.
Assim, assumimos que dois alunos não podem ter o mesmo nome, curso, notas e data de exame.
Adicionando dados duplicados para Aluno Asif
Vamos inserir deliberadamente um registro duplicado para Aluno:Asif para o Aluno tabela da seguinte forma:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Visualizar dados duplicados do aluno
Veja o Aluno tabela para ver registros duplicados:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
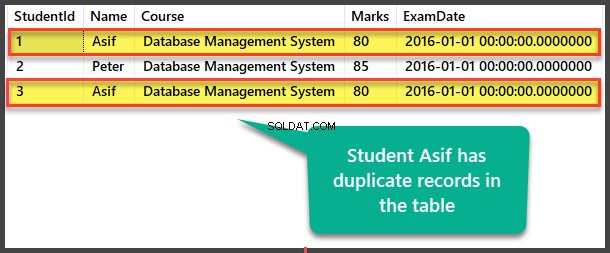
Encontrando duplicatas pelo método de auto-referência
E se houver milhares de registros nesta tabela, a visualização da tabela não ajudará muito.
No método de auto-referência, pegamos duas referências à mesma tabela e as juntamos usando o mapeamento coluna por coluna, com exceção do ID que é menor ou maior que o outro.
Vejamos o método de auto-referência para encontrar duplicatas que se parecem com isso:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
A saída do script acima nos mostra apenas os registros duplicados:

Encontrando duplicatas pelo método de auto-referência-2
Outra maneira de encontrar duplicatas usando auto-referência é usar INNER JOIN da seguinte forma:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Remoção de duplicatas pelo método de auto-referência
Podemos remover as duplicatas usando o mesmo método que usamos para encontrar duplicatas, com exceção de usar DELETE de acordo com sua sintaxe da seguinte maneira:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
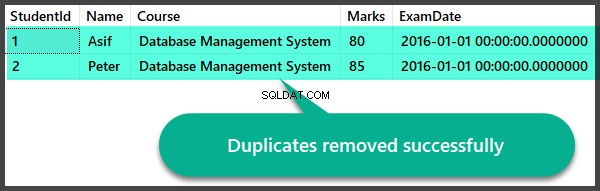
Verificação de dados após a remoção de duplicatas
Vamos verificar rapidamente os registros depois de removermos as duplicatas:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Criando a visualização de duplicatas e removendo o procedimento armazenado de duplicatas
Agora que sabemos que nossos scripts podem encontrar e excluir com sucesso linhas duplicadas no SQL, é melhor transformá-las em visualização e procedimento armazenado para facilitar o uso:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
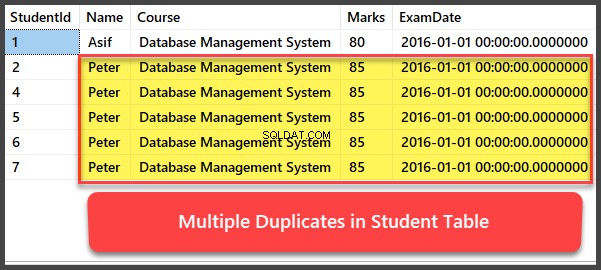
Adicionar e visualizar vários registros duplicados
Vamos agora adicionar mais quatro registros ao Aluno tabela e todos os registros são duplicados de forma que tenham o mesmo nome, curso, notas e data do exame:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Remoção de duplicatas usando o procedimento UspRemoveDuplicates
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
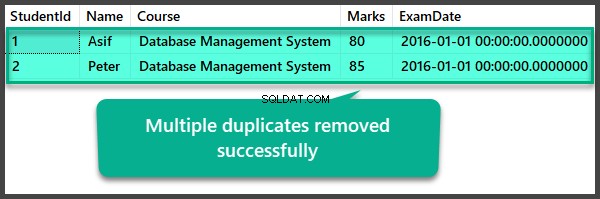
Verificação de dados após a remoção de várias duplicatas
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Caso 02:Adicionando e removendo duplicatas com os mesmos IDs
Até agora, identificamos registros duplicados com IDs distintos, mas e se os IDs forem os mesmos.
Por exemplo, pense no cenário em que uma tabela foi importada recentemente de um arquivo de texto ou Excel que não possui chave primária.
Pré-condições
Nesse caso, diz-se que uma tabela tem registros duplicados se todos os valores da coluna forem exatamente os mesmos, incluindo alguma coluna de ID e a chave primária estiver ausente, o que facilitou a inserção dos registros duplicados.
Criar Tabela de Curso sem Chave Primária
Para reproduzir o cenário em que registros duplicados na ausência de uma chave primária caem em uma tabela, vamos primeiro criar um novo Curso tabela sem nenhuma chave primária no banco de dados University2 da seguinte forma:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
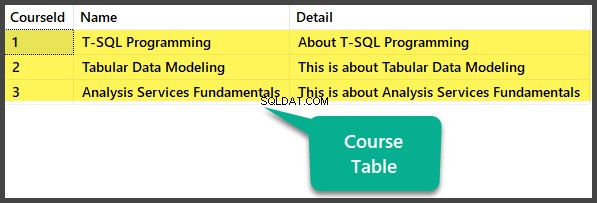
Preencher Tabela de Curso
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
Verificação de dados
Veja o Curso tabela:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
Adicionando dados duplicados na tabela do curso
Agora insira duplicatas no Curso tabela:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Visualizar dados duplicados do curso
Selecione todas as colunas para visualizar a tabela:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

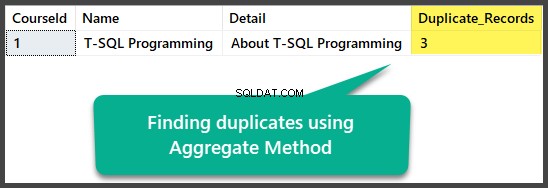
Encontrando duplicatas pelo método agregado
Podemos encontrar duplicatas exatas usando o método agregado agrupando todas as colunas com um total de mais de uma depois de selecionar todas as colunas junto com a contagem de todas as linhas usando a função de contagem agregada(*):
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Isso pode ser aplicado da seguinte forma:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
Remoção de duplicatas por método agregado
Vamos remover as duplicatas usando o Método Agregado da seguinte forma:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Verificação de dados
USE UniversityV2
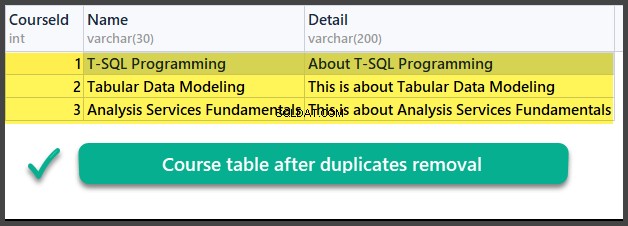
Assim, aprendemos com sucesso como remover duplicatas de uma tabela de banco de dados usando dois métodos diferentes com base em dois cenários diferentes.
Coisas para fazer
Agora você pode identificar e liberar facilmente uma tabela de banco de dados do valor duplicado.
1. Tente criar o UspRemoveDuplicatesByAggregate procedimento armazenado com base no método mencionado acima e remova duplicatas chamando o procedimento armazenado
2. Tente modificar o procedimento armazenado criado acima (UspRemoveDuplicatesByAggregates) e implemente as dicas de limpeza mencionadas neste artigo.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Você pode ter certeza de que o UspRemoveDuplicatesByAggregate procedimento armazenado pode ser executado tantas vezes quanto possível, mesmo após a remoção das duplicatas, para mostrar que o procedimento permanece consistente em primeiro lugar?
4. Consulte meu artigo anterior Jump to Start Test-Driven Database Development (TDDD) – Parte 1 e tente inserir duplicatas nas tabelas de banco de dados SQLDevBlog, depois tente remover as duplicatas usando os dois métodos mencionados nesta dica.
5. Tente criar outro banco de dados de amostra EmployeesSample referindo-se ao meu artigo anterior Art of Isolating Dependency and Data in Database Unit Testing e insira duplicatas nas tabelas e tente removê-las usando os dois métodos que você aprendeu com esta dica.
Ferramenta útil:
dbForge Data Compare for SQL Server – poderosa ferramenta de comparação SQL capaz de trabalhar com big data.