Introdução
Os desenvolvedores geralmente são instruídos a usar procedimentos armazenados para evitar as chamadas consultas ad hoc o que pode resultar em inchaço desnecessário do cache do plano. Veja, quando o código SQL recorrente é escrito de forma inconsistente ou quando há um código que gera SQL dinâmico em tempo real, o SQL Server tende a criar um plano de execução para cada execução individual. Isso pode diminuir o desempenho geral por:
Exigir uma fase de compilação para cada execução de código.
Inchar o cache do plano com muitos identificadores de plano que não podem ser reutilizados.
Otimizar para cargas de trabalho ad hoc
Uma maneira de lidar com esse problema no passado é otimizar a instância para cargas de trabalho ad hoc. Fazer isso só pode ser útil se a maioria dos bancos de dados ou os bancos de dados mais significativos na instância estiverem executando predominantemente SQL Ad Hoc.
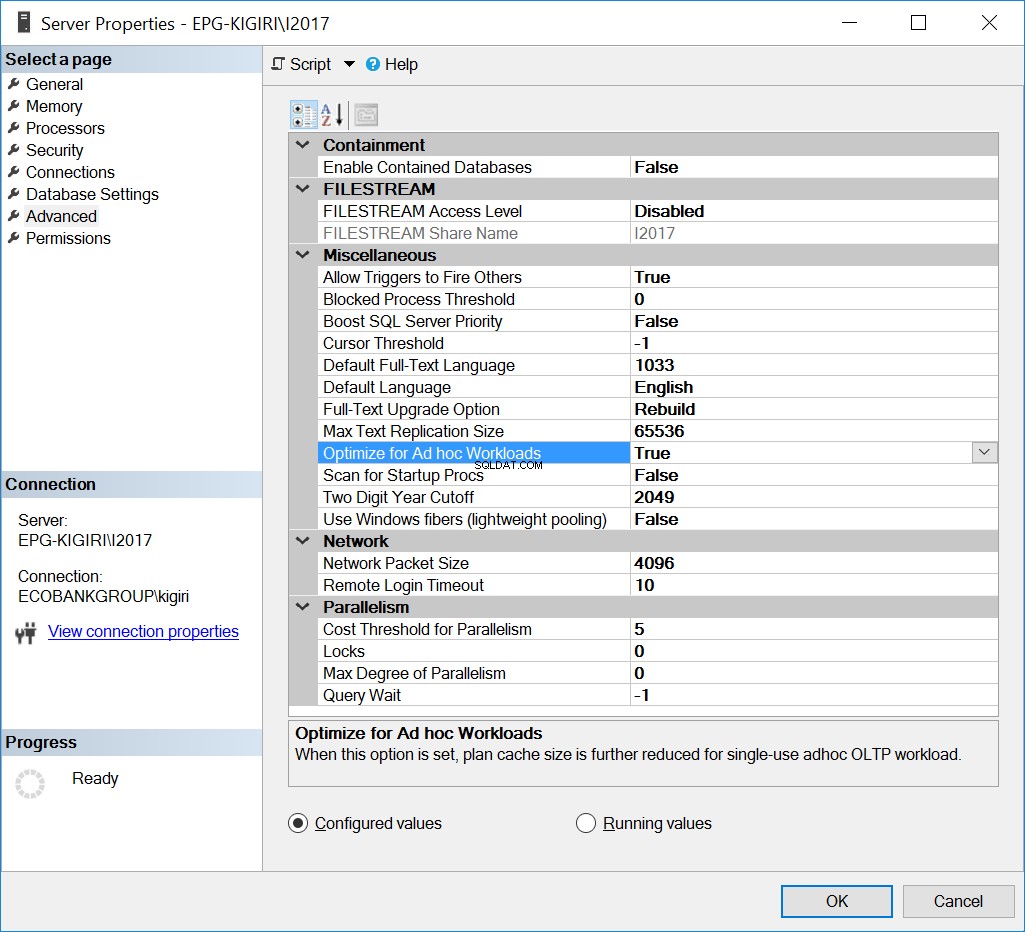
Fig. 1 Otimizar para cargas de trabalho ad hoc
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
Essencialmente, esta opção diz ao SQL Server para salvar uma versão parcial do plano conhecido como stub de plano compilado. O stub ocupa muito menos espaço do que todo o plano.
Como alternativa a esse método, algumas pessoas abordam o problema de forma bastante brutal e liberam o cache do plano de vez em quando. Ou, de forma mais cuidadosa, libere “planos de uso único” usando DBCC FREESYSTEMCACHE. Liberar todo o cache do plano tem suas desvantagens, como você já deve saber.
Usando procedimentos e parâmetros armazenados
Ao usar procedimentos armazenados, pode-se praticamente eliminar o problema causado pelo Ad Hoc SQL. Um procedimento armazenado é compilado apenas uma vez e o mesmo plano é reutilizado para execuções subsequentes das mesmas consultas SQL ou semelhantes. Quando os procedimentos armazenados são usados para implementar a lógica de negócios, a principal diferença nas consultas SQL que serão eventualmente executadas pelo SQL Server está nos parâmetros passados em tempo de execução. Como o plano já está em vigor e pronto para uso, o SQL Server usará o mesmo plano, independentemente do parâmetro passado.
Dados distorcidos
Em certos cenários, os dados com os quais estamos lidando não são distribuídos uniformemente. Podemos demonstrar isso – primeiro, precisaremos criar uma tabela:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Nossa tabela contém dados de sócios de clubes de diferentes países. Um grande número de membros do clube é de Gana, enquanto duas outras nações têm dez e dois membros, respectivamente. Para manter o foco na agenda e para simplificar, usei apenas três países e o mesmo nome para membros vindos do mesmo país. Além disso, adicionei um índice clusterizado na coluna ID e um índice não clusterizado na coluna CountryCode para demonstrar o efeito de diferentes planos de execução para diferentes valores.
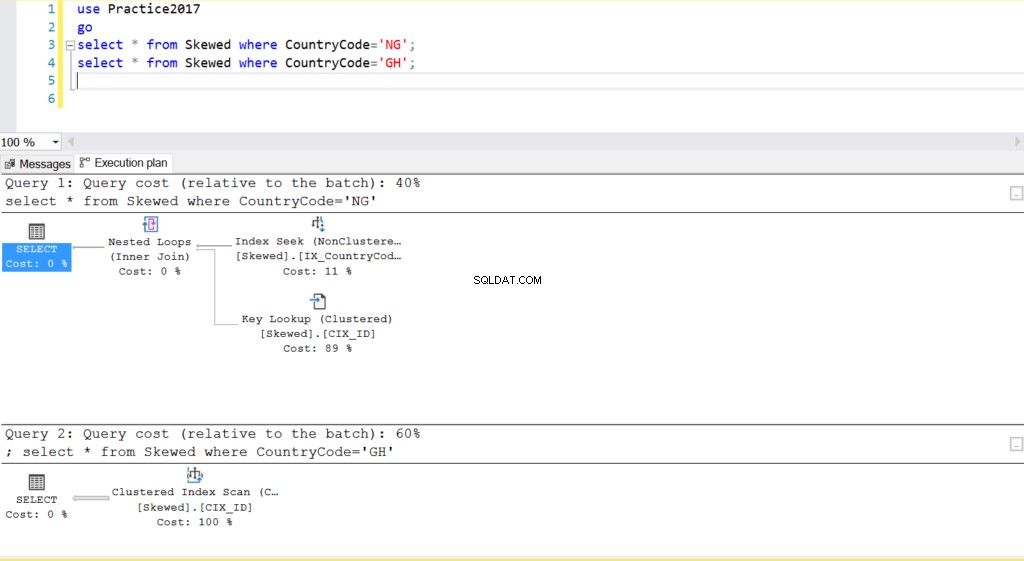
Fig. 2 Planos de execução para duas consultas
Quando consultamos a tabela para registros em que CountryCode é NG e GH, descobrimos que o SQL Server usa dois planos de execução diferentes nesses casos. Isso acontece porque o número esperado de linhas para CountryCode='NG' é 10, enquanto que para CountryCode='GH' é 10000. O SQL Server determina o plano de execução preferencial com base nas estatísticas da tabela. Se o número esperado de linhas for alto em comparação com o número total de linhas na tabela, o SQL Server decide que é melhor simplesmente fazer uma verificação completa da tabela em vez de fazer referência a um índice. Com um número estimado de linhas muito menor, o índice se torna útil.
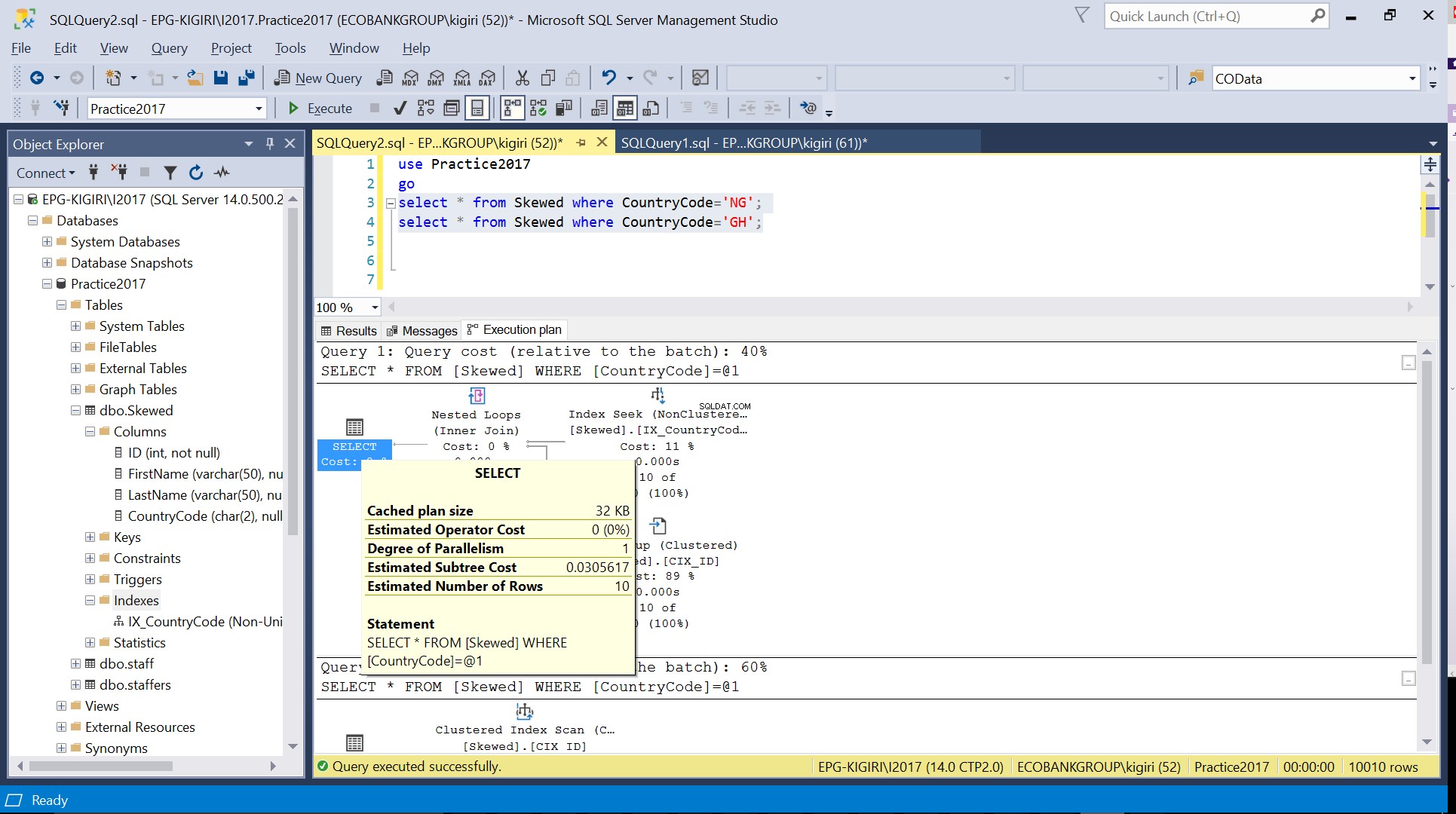
Fig. 3 Número estimado de linhas para CountryCode='NG'
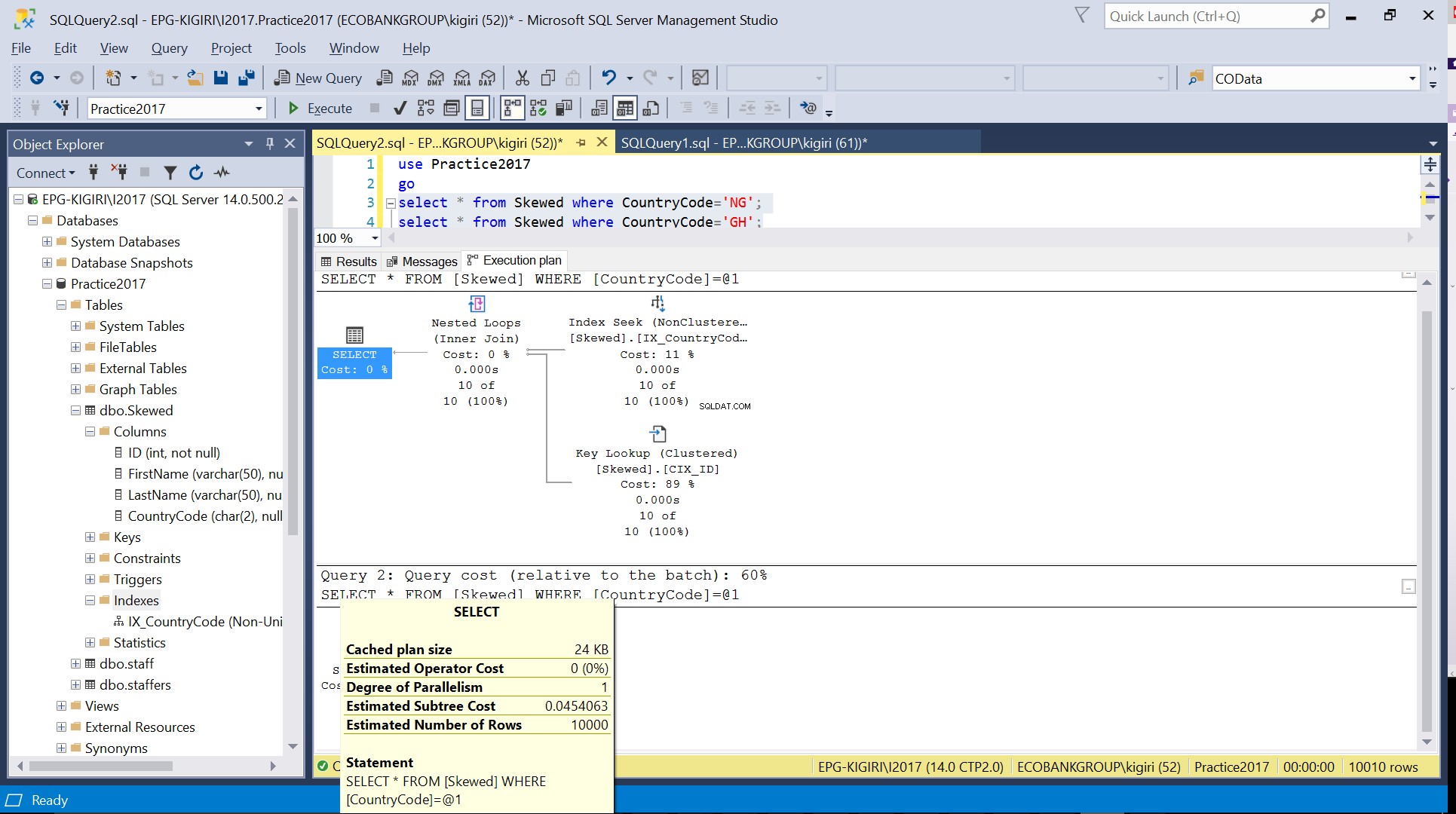
Fig. 4 Número estimado de linhas para CountryCode='GH'
Inserir procedimentos armazenados
Podemos criar um procedimento armazenado para buscar os registros que desejamos usando a mesma consulta. A única diferença desta vez é que passamos CountryCode como parâmetro (veja a Listagem 3). Ao fazer isso, descobrimos que o plano de execução é o mesmo, independentemente do parâmetro que passamos. O plano de execução que será usado é determinado pelo plano de execução retornado na primeira vez que o procedimento armazenado é invocado. Por exemplo, se executarmos o procedimento com CountryCode='GH' primeiro, ele usará uma varredura completa da tabela a partir desse ponto. Se limparmos o cache do procedimento e executarmos o procedimento com CountryCode='NG' primeiro, ele usará verificações baseadas em índice no futuro.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
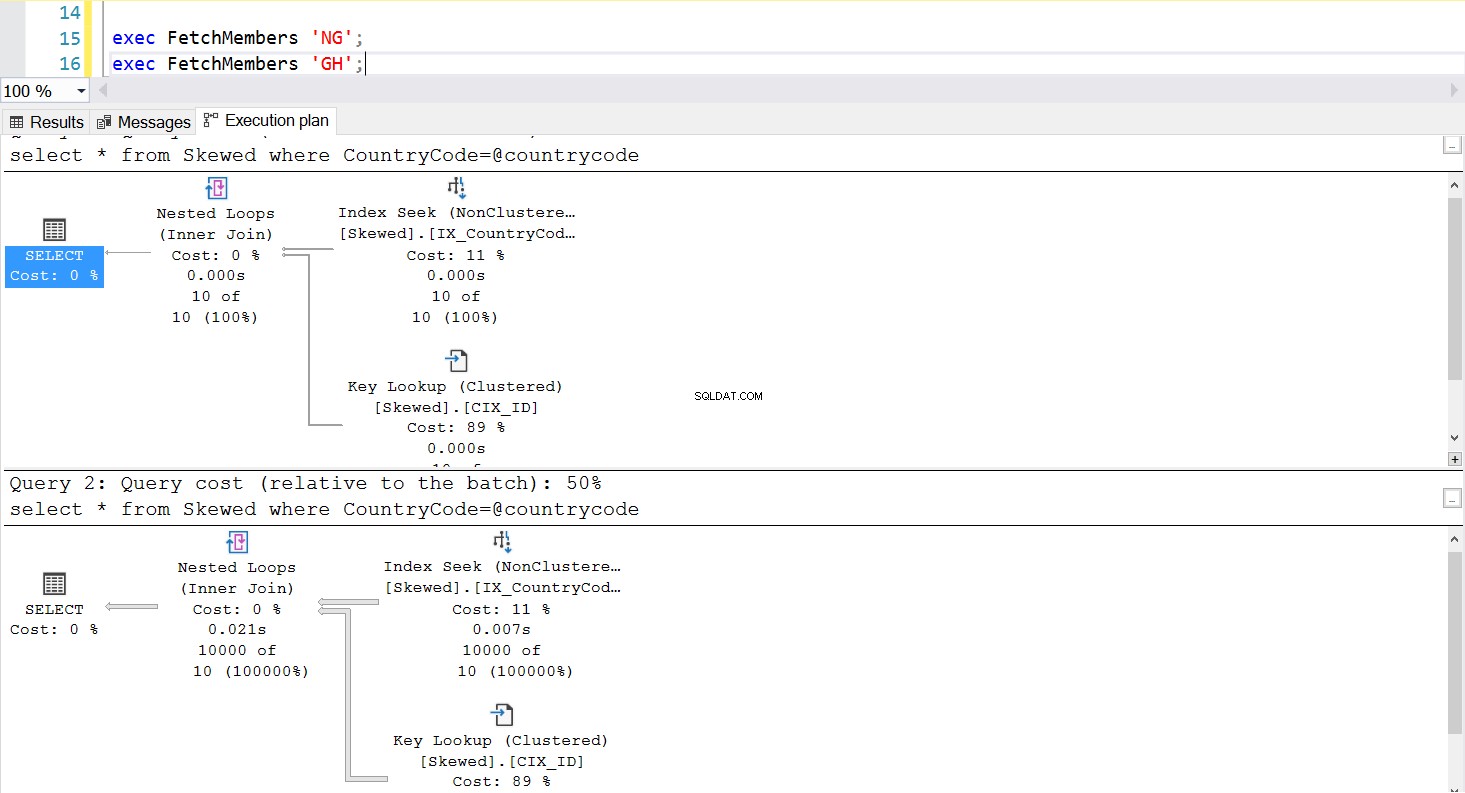
Fig. 5 Índice busca plano de execução quando 'NG' é usado primeiro
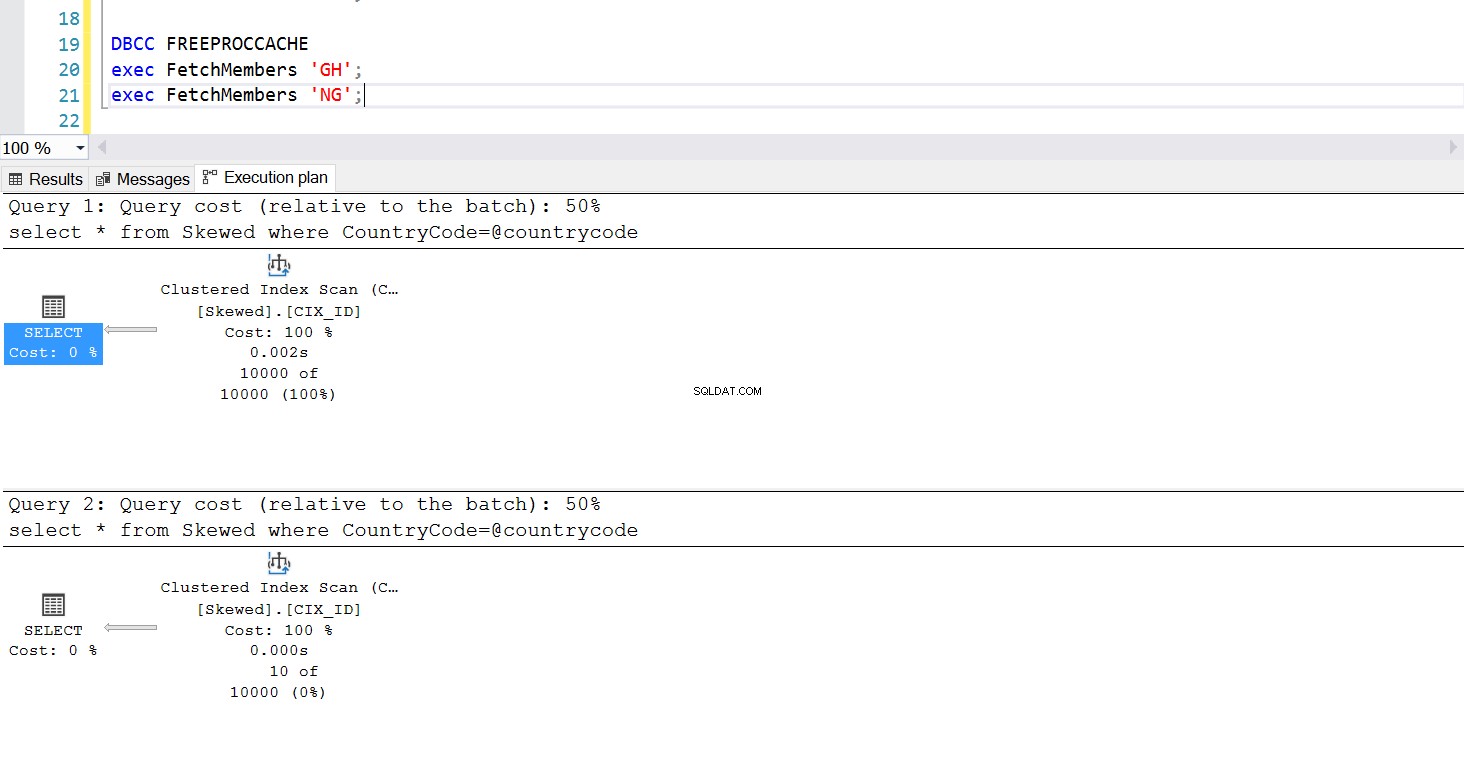
Fig. 6 Plano de execução de varredura de índice clusterizado quando 'GH' é usado primeiro
A execução do procedimento armazenado está se comportando conforme projetado – o plano de execução necessário é usado de forma consistente. No entanto, isso pode ser um problema porque um plano de execução não é adequado para todas as consultas se os dados estiverem distorcidos. Usar um índice para recuperar uma coleção de linhas quase tão grande quanto a tabela inteira não é eficiente – nem usar uma varredura completa para recuperar apenas um pequeno número de linhas. Este é o problema do Parameter Sniffing.
Soluções possíveis
Uma maneira comum de gerenciar o problema de Parameter Sniffing é invocar deliberadamente a recompilação sempre que o procedimento armazenado for executado. Isso é muito melhor do que liberar o cache do plano – exceto se você quiser liberar o cache dessa consulta SQL específica, o que é totalmente possível. Dê uma olhada em uma versão atualizada do procedimento armazenado. Desta vez, ele usa OPTION (RECOMPILE) para gerenciar o problema. A Fig.6 nos mostra que, sempre que o novo procedimento armazenado é executado, ele utiliza um plano adequado ao parâmetro que estamos passando.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
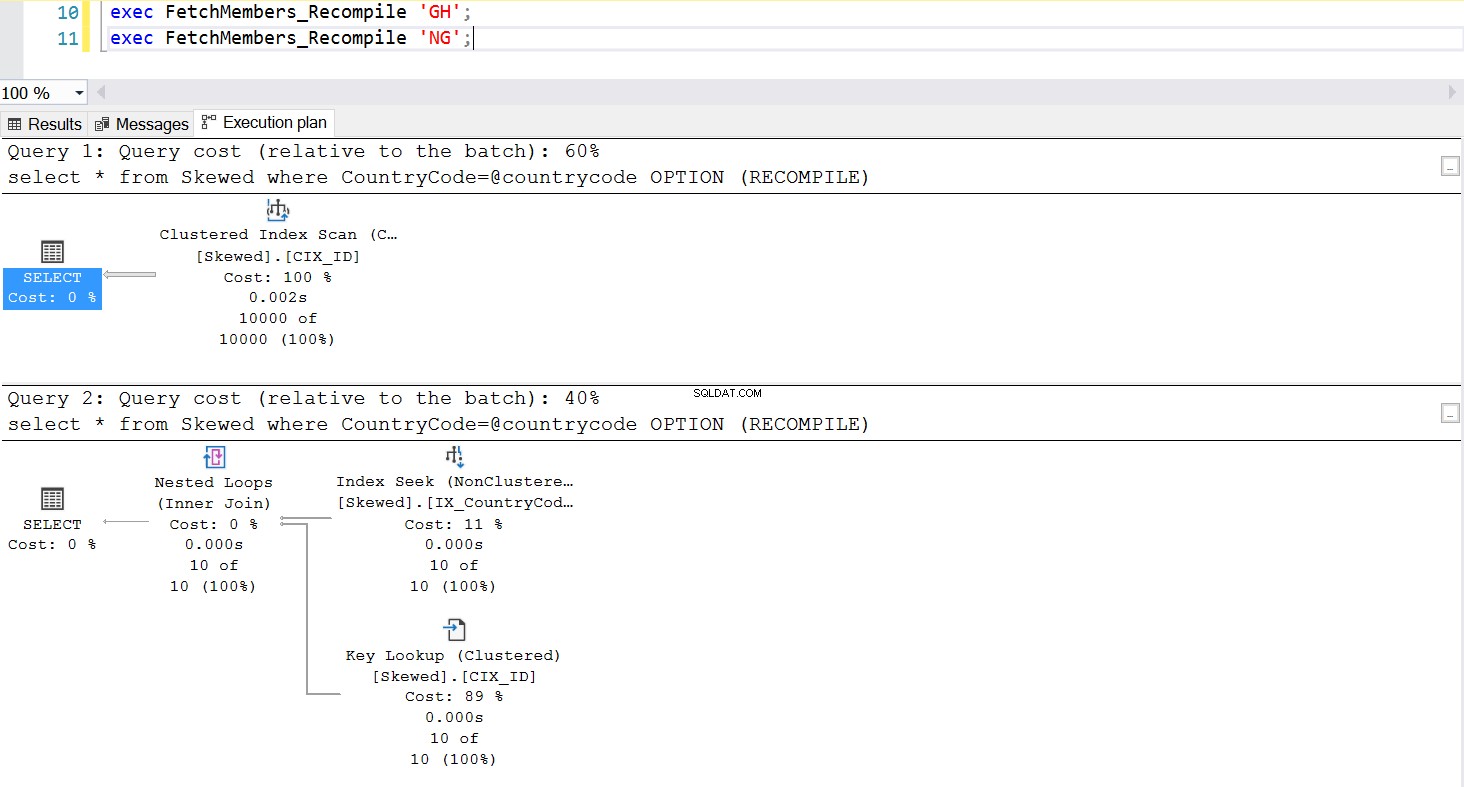
Fig. 7 Comportamento do procedimento armazenado com OPTION (RECOMPILE)
Conclusão
Neste artigo, vimos como planos de execução consistentes para procedimentos armazenados podem se tornar um problema quando os dados com os quais estamos lidando são distorcidos. Também demonstramos isso na prática e aprendemos sobre uma solução comum para o problema. Ouso dizer que esse conhecimento é inestimável para desenvolvedores que usam o SQL Server. Existem várias outras soluções para este problema – Brent Ozar se aprofundou no assunto e destacou alguns detalhes e soluções mais profundos no SQLDay Poland 2017. Eu listei o link correspondente na seção de referência.
Referências
Planejar o cache e otimizar para cargas de trabalho ad hoc
Identificando e corrigindo problemas de detecção de parâmetros



