Introdução
É de conhecimento comum nos círculos de banco de dados que os índices melhoram o desempenho da consulta satisfazendo inteiramente o conjunto de resultados necessário (Cobrindo índices) ou agindo como pesquisas que direcionam facilmente o mecanismo de consulta para a localização exata do conjunto de dados necessário. No entanto, como DBAs experientes sabem, não se deve ficar muito entusiasmado com a criação de índices em ambientes OLTP sem entender a natureza da carga de trabalho. Usando o Query Store na instância do SQL Server 2019 (o Query Store foi introduzido no SQL Server 2016), é muito fácil mostrar o efeito de um índice nas inserções.
Inserir sem índice
Começamos restaurando o banco de dados WideWorldImporters Sample e, em seguida, criando uma cópia do arquivo Sales. Tabela de faturas usando o script da Listagem 1. Observe que o banco de dados de exemplo já tem o Repositório de Consultas habilitado no modo de leitura/gravação.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Observe que não há índices na tabela que acabamos de criar. Tudo o que temos é a estrutura da tabela. Uma vez feito, realizamos inserções na nova tabela usando os dados de seu pai, conforme mostrado na Listagem 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
Durante esta operação, o Repositório de Consultas captura o plano de execução da consulta. A Figura 1 mostra brevemente o que está acontecendo sob o capô. Lendo da esquerda para a direita, vemos que o SQL Server executa as inserções usando Plan ID 563 – uma Varredura de Índice na Chave Primária da tabela de origem para buscar os dados e, em seguida, uma Inserção de Tabela na tabela de destino. (Leitura da esquerda para a direita). Observe que, neste caso, a maior parte do custo está na Inserção da Tabela – 99% do custo da consulta.
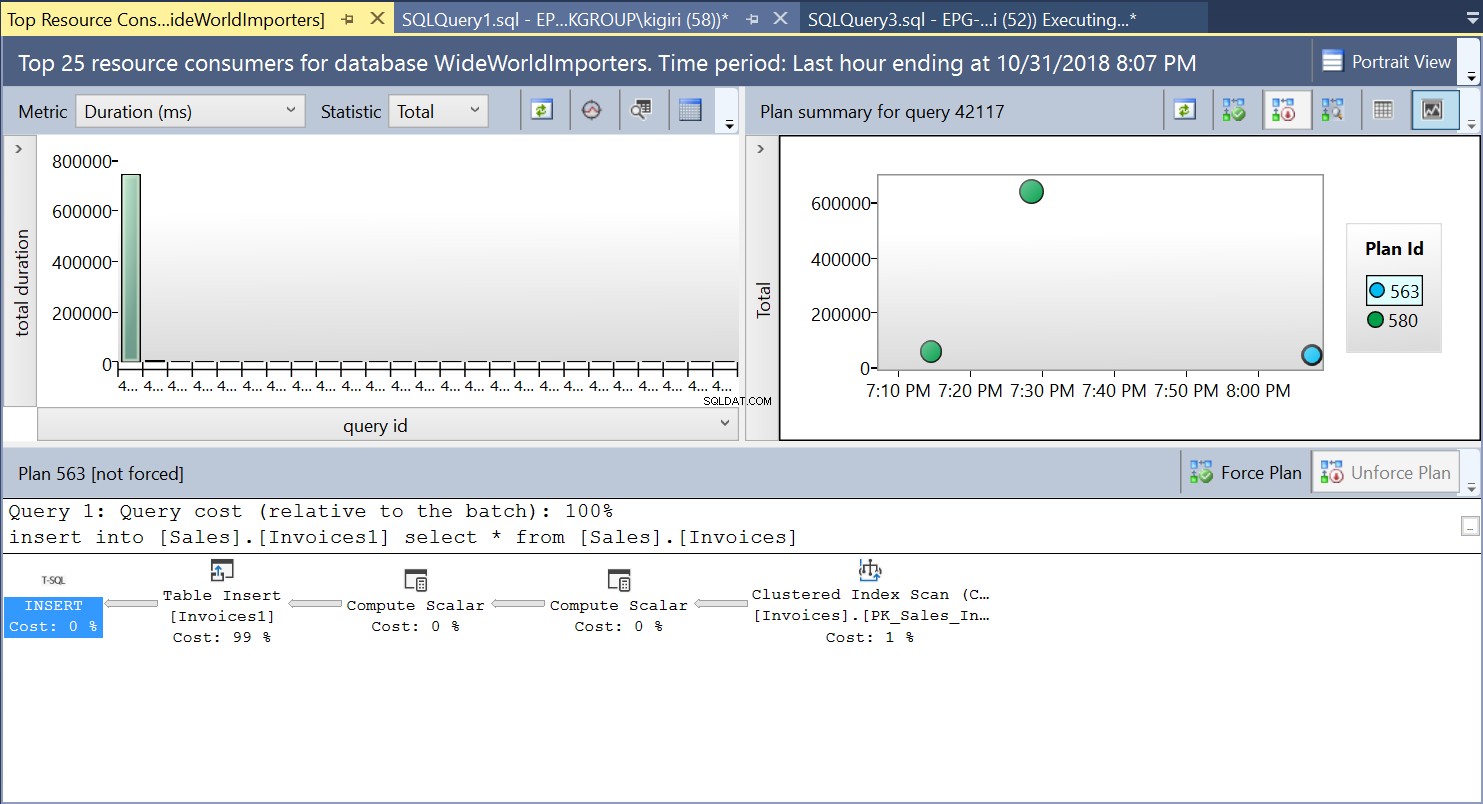
Fig. 1 Plano de Execução 563
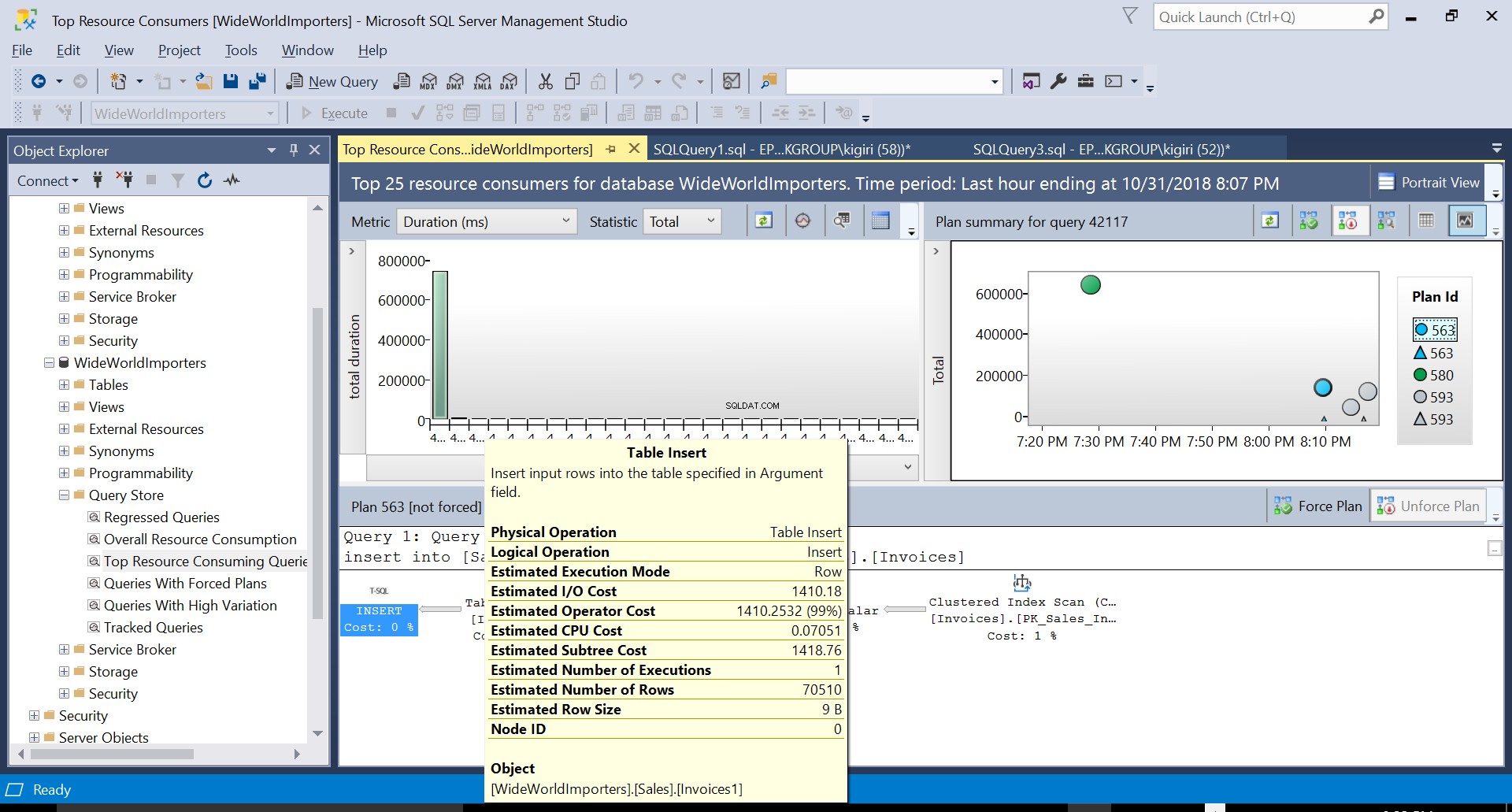
Fig. 2 Inserção de Tabela no Destino
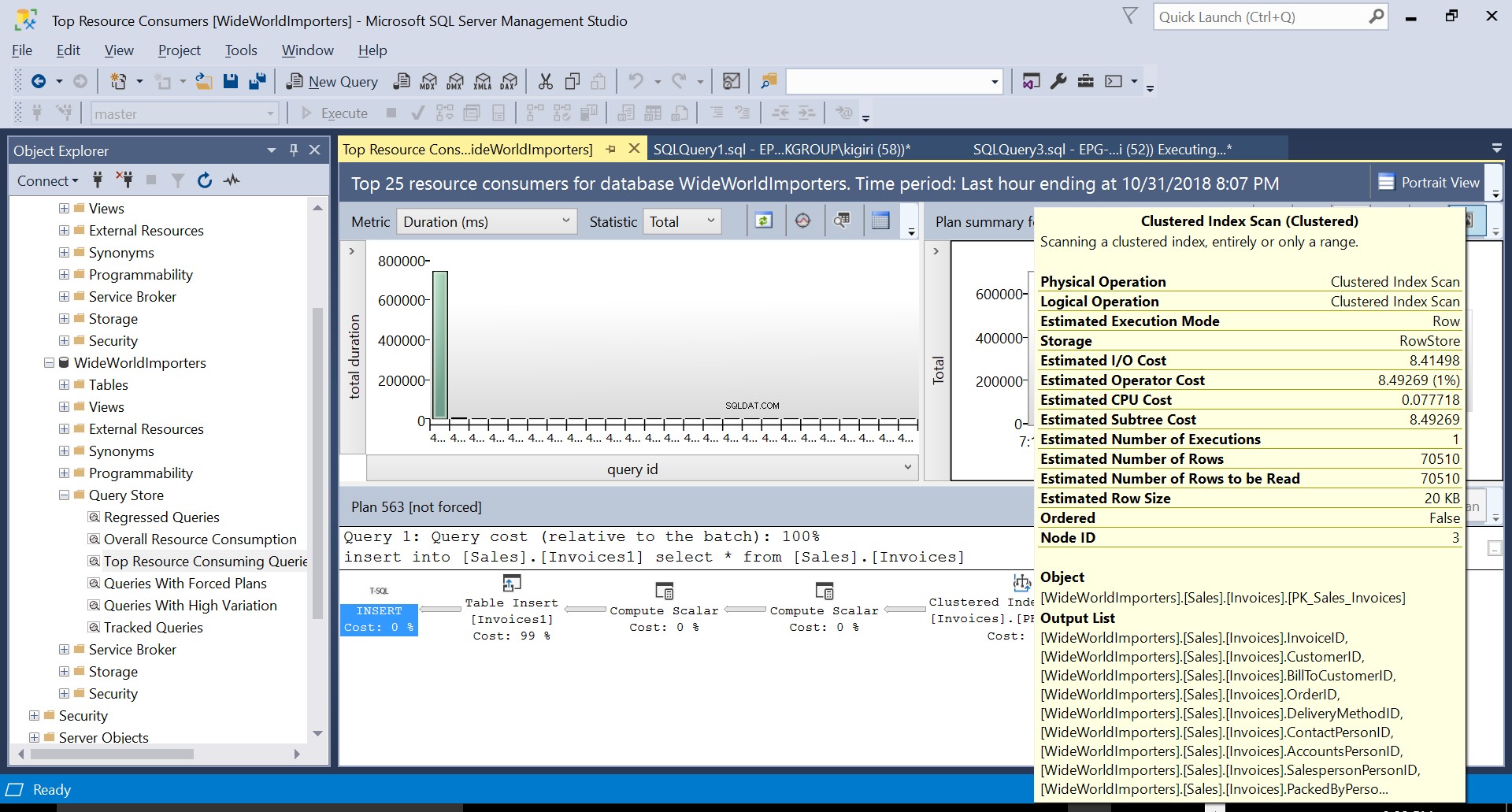
Fig. 3 Varredura de Índice Agrupado na Tabela de Origem
Inserir com índice
Em seguida, criamos um índice na tabela de destino usando o DDL na Listagem 3. Quando repetimos a instrução na Listagem 2 depois de truncar a tabela de destino, vemos um plano de execução ligeiramente diferente (ID do plano 593 mostrado na Fig 4). Ainda vemos a inserção de tabela, mas ela contribui apenas com 58% ao custo da consulta. A dinâmica de execução é um pouco distorcida com a introdução de uma classificação e uma inserção de índice. Essencialmente, o que está acontecendo é que o SQL Server deve introduzir linhas correspondentes no índice à medida que novos registros são introduzidos na tabela.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
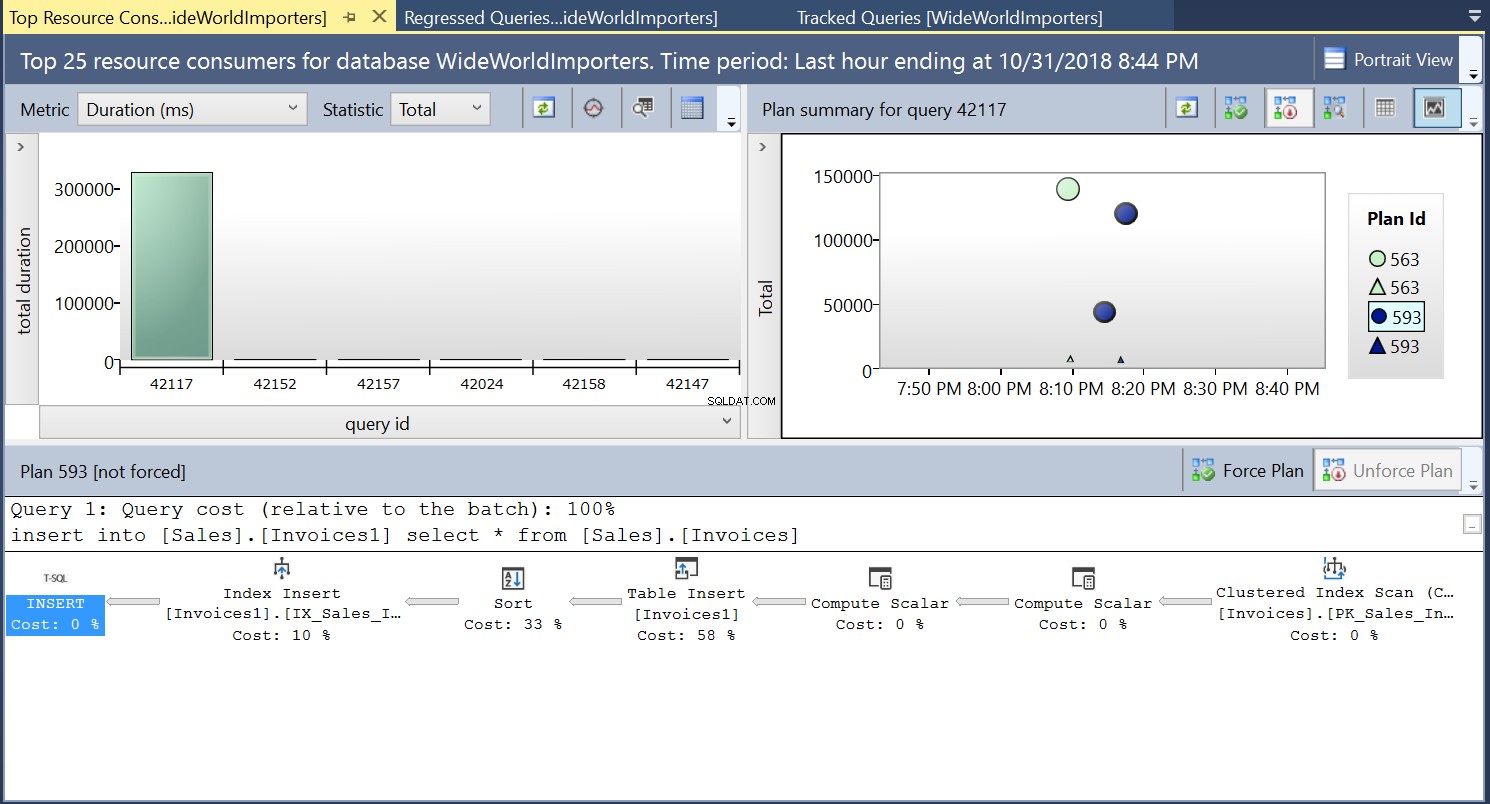
Fig. 4 Plano de Execução 593
Aprofundando
Podemos examinar os detalhes de ambos os planos e ver como esses novos fatores aumentam o tempo de execução da instrução. O plano 593 adiciona cerca de 300 ms adicionais à duração média da instrução. Sob carga de trabalho pesada em um ambiente de produção, essa diferença pode ser significativa.
Ativar STATISTICS IO ao executar a instrução insert apenas uma vez em ambos os casos – com Index na tabela de destino e sem um índice na tabela Destination – também mostra que mais trabalho é feito em termos de IO lógico ao inserir linhas em uma tabela com índices.
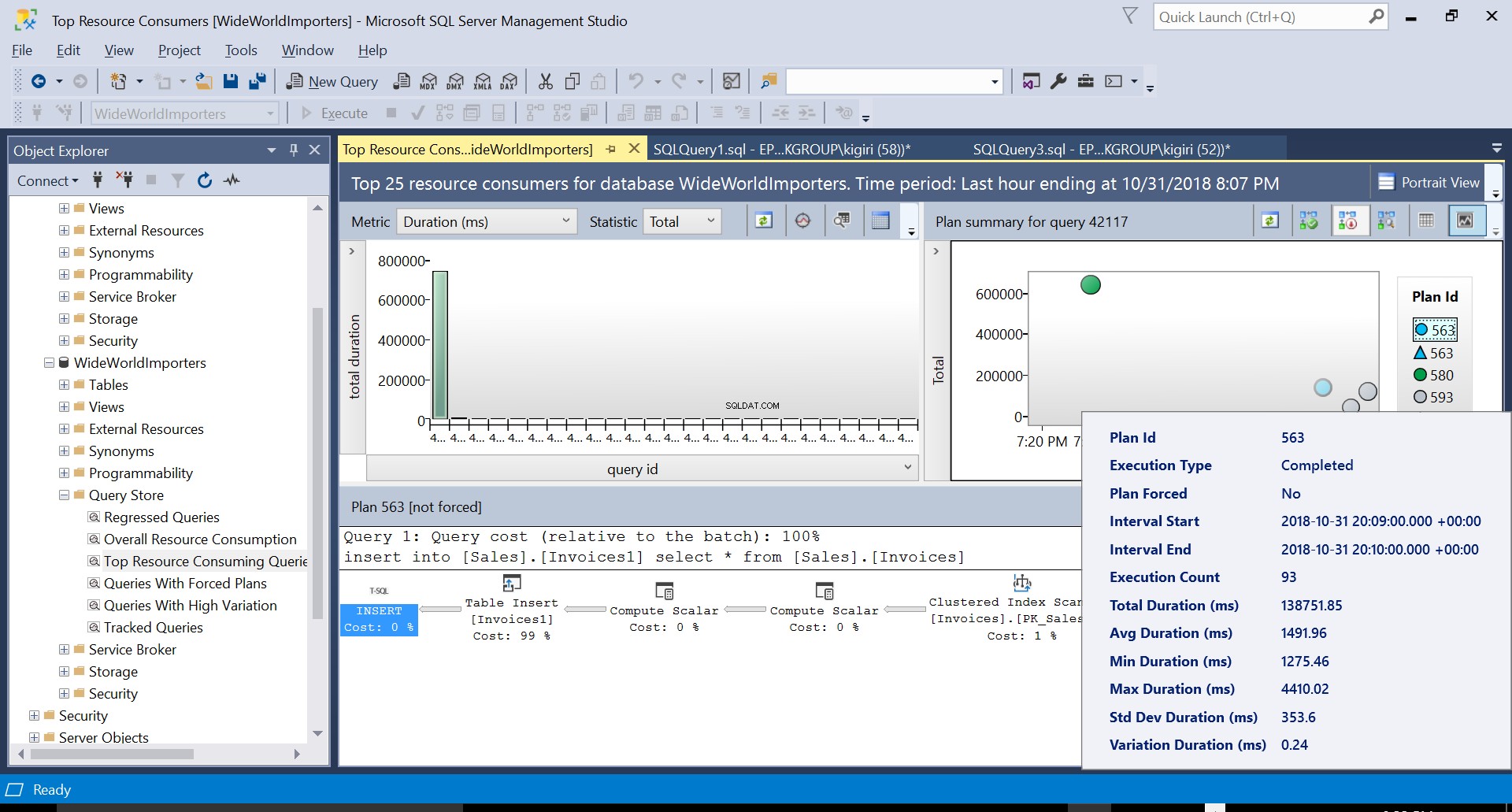
Fig. 5 Detalhes do Plano de Execução 563
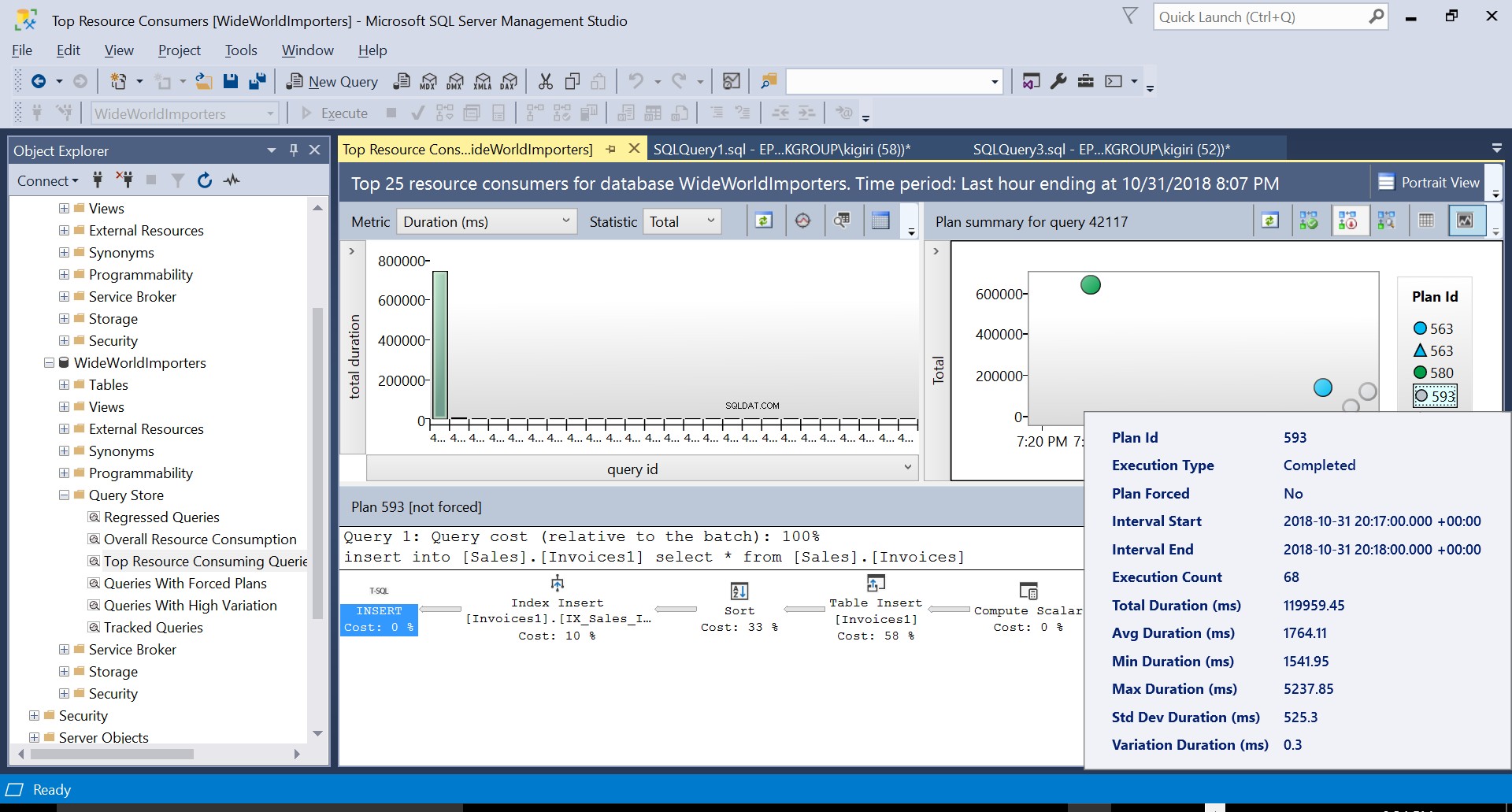
Fig. 4 Detalhes do Plano de Execução 593
Sem índice:saída com STATISTICS IO ativado:
Tabela 'Faturas1'. Contagem de varredura 0, leituras lógicas 78372 , leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Faturas'. Contagem de varredura 1, leituras lógicas 11400, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
(70510 linhas afetadas)
Índice:saída com STATISTICS IO ativado:
Tabela 'Faturas1'. Contagem de varredura 0, leituras lógicas 81119 , leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Tabela de trabalho'. Contagem de varredura 0, leituras lógicas 0, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Faturas'. Contagem de varredura 1, leituras lógicas 11400 , leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
(70510 linhas afetadas)
Informações Adicionais
A Microsoft e outras fontes fornecem scripts para examinar o ambiente de produção de índices e identificar situações como:
- Índices redundantes – Índices duplicados
- Índices ausentes – Índices que podem melhorar o desempenho com base na carga de trabalho
- Montes – Tabelas sem índices agrupados
- Tabelas superindexadas – Tabelas com mais índices do que colunas
- Uso do índice – Contagem de buscas, varreduras e pesquisas em índices
Os itens 2, 3 e 5 estão mais relacionados ao impacto no desempenho em relação às leituras, enquanto os itens 1 e 4 estão relacionados ao impacto no desempenho em relação às gravações. As Listagens 4 e 5 são dois exemplos dessas consultas publicamente disponíveis.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Conclusão
Mostramos, usando o Query Store, que a carga de trabalho adicional com um índice pode ser introduzida no plano de execução de uma instrução de inserção de exemplo. Na produção, índices excessivos e redundantes podem ter um impacto negativo no desempenho, principalmente em bancos de dados destinados a cargas de trabalho OLTP. É importante usar scripts e ferramentas disponíveis para examinar os índices e determinar se eles estão realmente ajudando ou prejudicando o desempenho.
Ferramenta útil:
dbForge Index Manager – suplemento SSMS útil para analisar o status de índices SQL e corrigir problemas com fragmentação de índice.



