Na semana passada publiquei um post chamado #BackToBasics :
DATEFROMPARTS() , onde mostrei como usar essa função 2012+ para consultas de intervalo de datas mais limpas e sargáveis. Usei-o para demonstrar que, se você usar um predicado de data aberto e tiver um índice na coluna de data/hora relevante, poderá obter um uso de índice muito melhor e E/S menor (ou, no pior caso, , o mesmo, se uma busca não puder ser usada por algum motivo ou se não existir um índice adequado):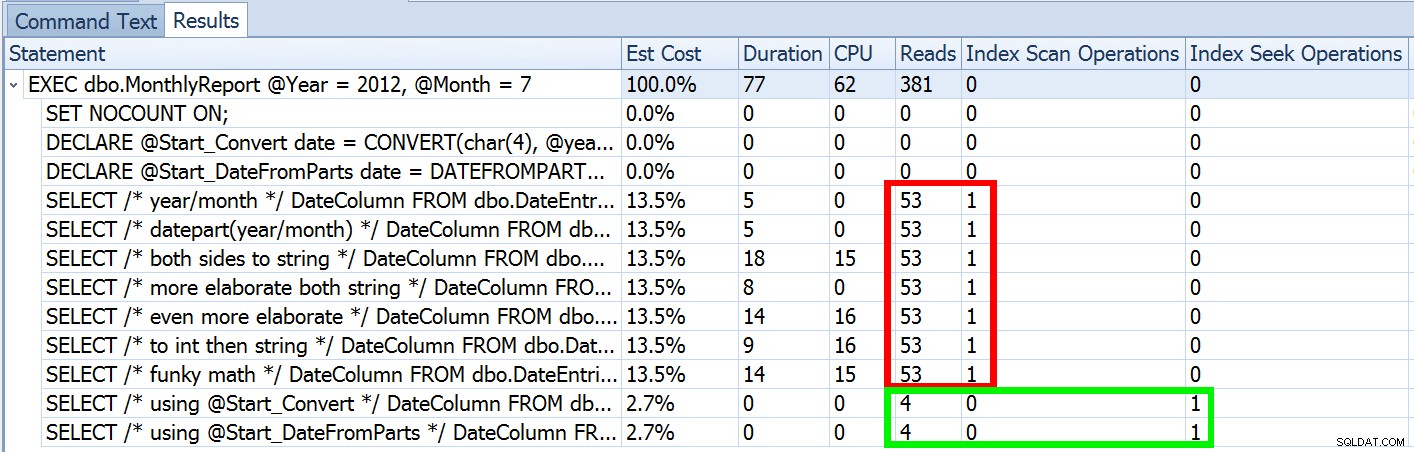
Mas isso é apenas parte da história (e para ser claro,
DATEFROMPARTS() não é tecnicamente necessário para obter uma busca, é apenas mais limpo nesse caso). Se diminuirmos um pouco o zoom, notamos que nossas estimativas estão longe de ser precisas, uma complexidade que eu não queria apresentar no post anterior: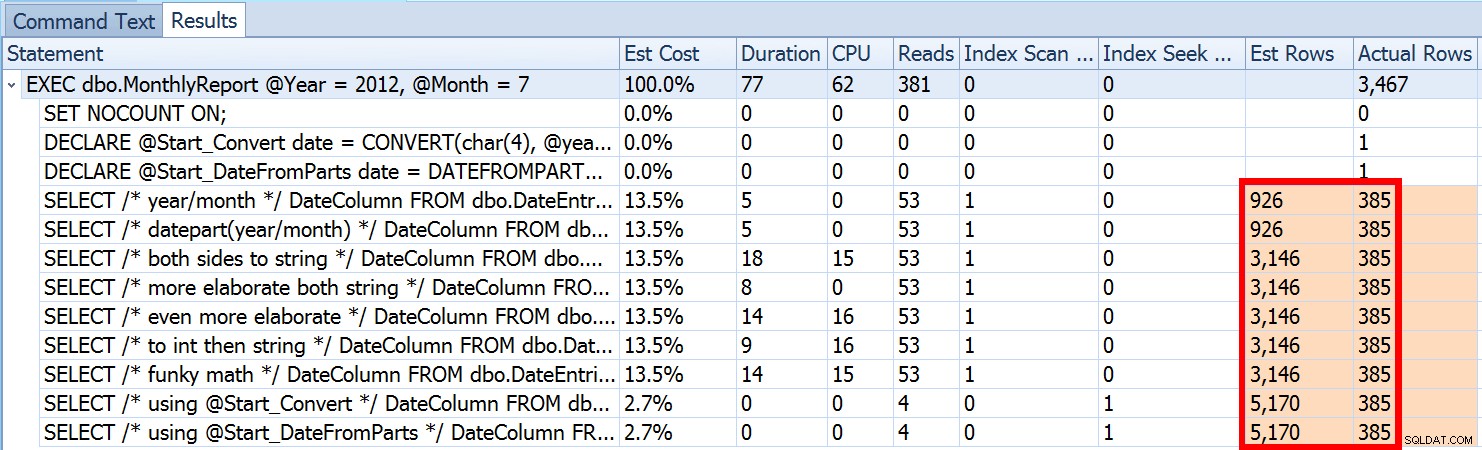
Isso não é incomum para predicados de desigualdade e com varreduras forçadas. E, claro, o método que sugeri não produziria as estatísticas mais imprecisas? Aqui está a abordagem básica (você pode obter o esquema da tabela, índices e dados de exemplo do meu post anterior):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Agora, estimativas imprecisas nem sempre serão um problema, mas podem causar problemas com escolhas de planos ineficientes nos dois extremos. Um único plano pode não ser ideal quando o intervalo escolhido gerar uma porcentagem muito pequena ou muito grande da tabela ou índice, e isso pode ser muito difícil para o SQL Server prever quando a distribuição de dados é desigual. Joseph Sack descreveu as coisas mais típicas que estimativas ruins podem afetar em seu post, "Dez ameaças comuns à qualidade do plano de execução":
"[…] estimativas de linhas ruins podem afetar uma variedade de decisões, incluindo seleção de índice, operações de busca versus varredura, execução paralela versus serial, seleção de algoritmo de junção, seleção de junção física interna versus externa (por exemplo, compilação versus sonda), geração de spool, pesquisas de favoritos vs. acesso completo à tabela de cluster ou heap, seleção de agregação de fluxo ou hash e se uma modificação de dados usa ou não um plano amplo ou estreito."
Existem outros também, como concessões de memória que são muito grandes ou muito pequenas. Ele continua descrevendo algumas das causas mais comuns de estimativas ruins, mas a causa principal neste caso está faltando em sua lista:estimativas. Como estamos usando uma variável local para alterar o
int de entrada parâmetros para uma única date local variável, o SQL Server não sabe qual será o valor, então faz estimativas padronizadas de cardinalidade com base em toda a tabela. Vimos acima que a estimativa para minha abordagem sugerida era de 5.170 linhas. Agora, sabemos que com um predicado de desigualdade e com o SQL Server não sabendo os valores dos parâmetros, ele adivinhará 30% da tabela.
31,645 * 0.3 não é 5.170. Nem 31,465 * 0.3 * 0.3 , quando lembramos que na verdade existem dois predicados trabalhando na mesma coluna. Então, de onde vem esse valor de 5.170? Como Paul White descreve em seu post, "Estimativa de cardinalidade para vários predicados", o novo estimador de cardinalidade no SQL Server 2014 usa recuo exponencial, portanto, multiplica a contagem de linhas da tabela (31.465) pela seletividade do primeiro predicado (0,3) , e então multiplica isso pela raiz quadrada da seletividade do segundo predicado (~0,547723).
31.645 * (0,3) * SQRT(0,3) ~=5.170,227
Então, agora podemos ver onde o SQL Server chegou com sua estimativa; quais são alguns dos métodos que podemos usar para fazer algo a respeito?
- Passe os parâmetros de data. Quando possível, você pode alterar o aplicativo para que ele passe parâmetros de data apropriados em vez de parâmetros inteiros separados.
- Use um procedimento de wrapper. Uma variação do método nº 1 – por exemplo, se você não puder alterar o aplicativo – seria criar um segundo procedimento armazenado que aceitasse parâmetros de data construídos do primeiro.
- Usar
OPTION (RECOMPILE). Com o pequeno custo de compilação toda vez que a consulta é executada, isso força o SQL Server a otimizar com base nos valores apresentados a cada vez, em vez de otimizar um único plano para valores de parâmetro desconhecidos, primeiros ou médios. (Para um tratamento completo deste tópico, veja "Parameter Sniffing, Embedding, and the RECOMPILE Options" de Paul White.
- Use SQL dinâmico. Tendo o SQL dinâmico aceitando a
dateconstruída variável força a parametrização adequada (como se você tivesse chamado um procedimento armazenado com umadateparâmetro), mas é um pouco feio e mais difícil de manter.
- Mexa com dicas e sinalizadores de rastreamento. Paul White fala sobre alguns deles no post mencionado.
Não vou sugerir que esta é uma lista exaustiva e não vou reiterar o conselho de Paul sobre dicas ou sinalizadores de rastreamento, então vou me concentrar apenas em mostrar como as quatro primeiras abordagens podem mitigar o problema com estimativas ruins .
1. Parâmetros de data
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Procedimento do wrapper
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. OPÇÃO (RECOMPILAR)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. SQL dinâmico
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Os testes
Com os quatro conjuntos de procedimentos em vigor, foi fácil construir testes que me mostrariam os planos e as estimativas derivadas do SQL Server. Como alguns meses são mais ocupados que outros, escolhi três meses diferentes e os executei várias vezes.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
O resultado? Cada plano produz a mesma Busca de Índice, mas as estimativas estão corretas apenas em todos os três períodos na
OPTION (RECOMPILE) versão. O restante continua usando as estimativas derivadas do primeiro conjunto de parâmetros (julho de 2012) e, assim, obtém estimativas melhores para o primeiro execução, essa estimativa não será necessariamente melhor para subsequentes execuções usando parâmetros diferentes (um caso clássico de sniffing de parâmetros):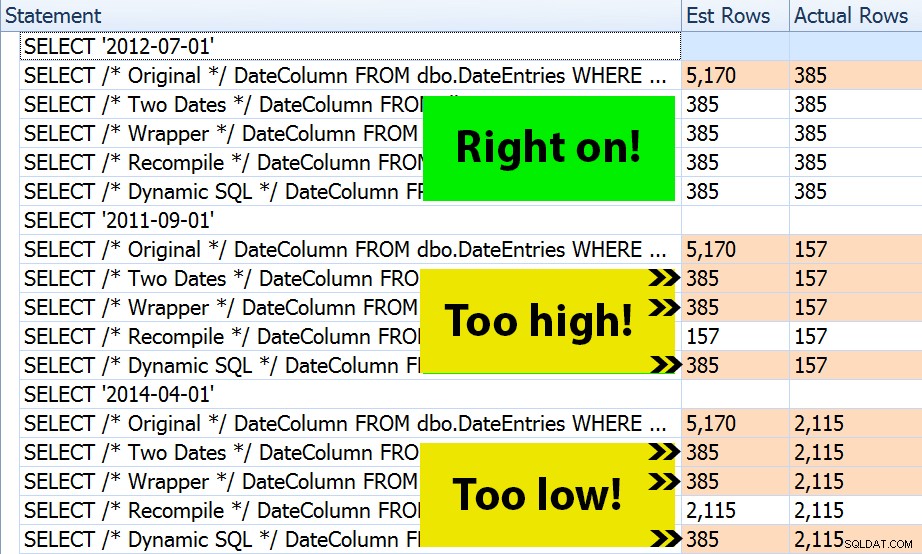
Observe que a saída acima não é *exata* do SQL Sentry Plan Explorer – por exemplo, eu removi as linhas da árvore de instrução que mostravam as chamadas externas de procedimento armazenado e declarações de parâmetro.
Caberá a você determinar se a tática de compilar sempre é a melhor para você, ou se você precisa "consertar" alguma coisa em primeiro lugar. Aqui, acabamos com os mesmos planos e sem diferenças perceptíveis nas métricas de desempenho do tempo de execução. Mas em tabelas maiores, com distribuição de dados mais distorcida e variações maiores nos valores de predicado (por exemplo, considere um relatório que pode cobrir uma semana, um ano e qualquer coisa entre eles), pode valer a pena alguma investigação. E observe que você pode combinar métodos aqui - por exemplo, você pode alternar para parâmetros de data apropriados *e* adicionar
OPTION (RECOMPILE) , Se você quisesse. Conclusão
Nesse caso específico, que é uma simplificação intencional, o esforço de obter as estimativas corretas realmente não valeu a pena – não obtivemos um plano diferente e o desempenho do tempo de execução foi equivalente. Há certamente outros casos, no entanto, em que isso fará a diferença, e é importante reconhecer a disparidade de estimativa e determinar se ela pode se tornar um problema à medida que seus dados crescem e/ou sua distribuição se distorce. Infelizmente, não há uma resposta em preto ou branco, pois muitas variáveis afetarão se a sobrecarga de compilação é justificada - como em muitos cenários, IT DEPENDS™ …