Há muito foi estabelecido que variáveis de tabela com um grande número de linhas podem ser problemáticas, pois o otimizador sempre as vê como tendo uma linha. Sem uma recompilação após a variável de tabela ter sido preenchida (já que antes disso ela está vazia), não há cardinalidade para a tabela e as recompilações automáticas não acontecem porque as variáveis de tabela nem estão sujeitas a um limite de recompilação. Os planos, portanto, são baseados em uma cardinalidade de tabela de zero, não um, mas o mínimo é aumentado para um, como Paul White (@SQL_Kiwi) descreve nesta resposta dba.stackexchange.
A maneira como normalmente contornamos esse problema é adicionar
OPTION (RECOMPILE) para a consulta que faz referência à variável de tabela, forçando o otimizador a inspecionar a cardinalidade da variável de tabela depois que ela for preenchida. Para evitar a necessidade de alterar manualmente cada consulta para adicionar uma dica de recompilação explícita, um novo sinalizador de rastreamento (2453) foi introduzido no SQL Server 2012 Service Pack 2 e na atualização cumulativa nº 3 do SQL Server 2014:- KB #2952444:CORREÇÃO:desempenho ruim ao usar variáveis de tabela no SQL Server 2012 ou SQL Server 2014
Quando o sinalizador de rastreamento 2453 está ativo, o otimizador pode obter uma imagem precisa da cardinalidade da tabela após a criação da variável da tabela. Isso pode ser A Good Thing™ para muitas consultas, mas provavelmente não para todas, e você deve estar ciente de como funciona de maneira diferente de
OPTION (RECOMPILE) . Mais notavelmente, a otimização de incorporação de parâmetros que Paul White fala neste post ocorre em OPTION (RECOMPILE) , mas não sob esse novo sinalizador de rastreamento. Um teste simples
Meu teste inicial consistiu em apenas preencher uma variável de tabela e selecionar a partir dela; isso gerou a contagem de linhas estimada muito familiar de 1. Aqui está o teste que executei (e adicionei a dica de recompilação para comparar):
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, t.name FROM @t AS t; SELECT t.id, t.name FROM @t AS t OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Usando o SQL Sentry Plan Explorer, podemos ver que o plano gráfico para ambas as consultas neste caso é idêntico, provavelmente pelo menos em parte porque este é literalmente um plano trivial:

Plano gráfico para uma verificação de índice trivial em @t
No entanto, as estimativas não são as mesmas. Mesmo que o sinalizador de rastreamento esteja habilitado, ainda obteremos uma estimativa de 1 saindo da verificação de índice se não usarmos a dica de recompilação:
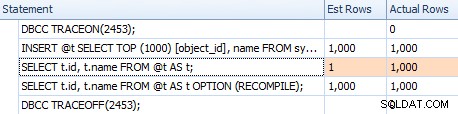
Comparação de estimativas para um plano trivial na grade de declarações
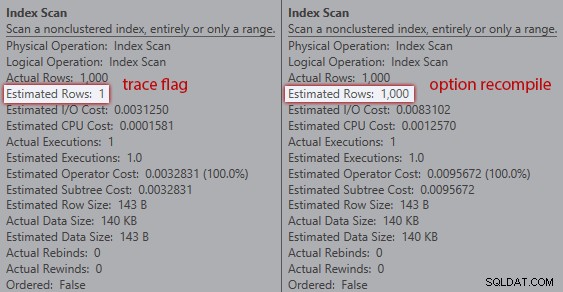
Comparação de estimativas entre sinalizador de rastreamento (esquerda) e recompilar (direita)
Se você já esteve perto de mim pessoalmente, provavelmente pode imaginar a cara que eu fiz neste momento. Eu tinha certeza de que o artigo da KB listava o número errado do sinalizador de rastreamento ou que eu precisava de alguma outra configuração habilitada para que ele realmente estivesse ativo.
Benjamin Nevarez (@BenjaminNevarez) rapidamente apontou para mim que eu precisava examinar mais de perto o artigo KB "Bugs corrigidos no SQL Server 2012 Service Pack 2". Embora eles tenham obscurecido o texto por trás de um marcador oculto em Highlights> Relational Engine, o artigo da lista de correções faz um trabalho um pouco melhor ao descrever o comportamento do sinalizador de rastreamento do que o artigo original (ênfase minha):
Se uma variável de tabela é unida a outras tabelas no SQL Server, isso pode resultar em desempenho lento devido à seleção ineficiente do plano de consulta porque o SQL Server não oferece suporte a estatísticas nem acompanha o número de linhas em uma variável de tabela ao compilar um plano de consulta.
Portanto, pareceria a partir dessa descrição que o sinalizador de rastreamento destina-se apenas a resolver o problema quando a variável de tabela participa de uma junção. (Por que essa distinção não é feita no artigo original, não faço ideia.) Mas também funciona se fizermos as consultas trabalharem um pouco mais – a consulta acima é considerada trivial pelo otimizador e o sinalizador de rastreamento não t mesmo tentar fazer qualquer coisa nesse caso. Mas ele entrará em ação se a otimização baseada em custo for realizada, mesmo sem uma junção; o sinalizador de rastreamento simplesmente não tem efeito em planos triviais. Aqui está um exemplo de um plano não trivial que não envolve uma associação:
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID(); SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID() OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Este plano não é mais trivial; otimização é marcada como completa. A maior parte do custo é movida para um operador de classificação:
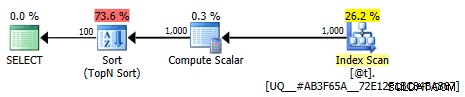
Plano gráfico menos trivial
E as estimativas se alinham para ambas as consultas (vou poupar as dicas de ferramentas desta vez, mas posso garantir que são as mesmas):

Grade de instruções para planos menos triviais com e sem a dica de recompilação
Portanto, parece que o artigo da KB não é exatamente preciso – consegui forçar o comportamento esperado do sinalizador de rastreamento sem introduzir uma junção. Mas eu quero testá-lo com uma junção também.
Um teste melhor
Vamos pegar este exemplo simples, com e sem o sinalizador de rastreamento:
--DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; --DBCC TRACEOFF(2453);
Sem o sinalizador de rastreamento, o otimizador estima que uma linha virá da varredura de índice em relação à variável da tabela. No entanto, com o sinalizador de rastreamento ativado, ele obtém as 1.000 linhas:
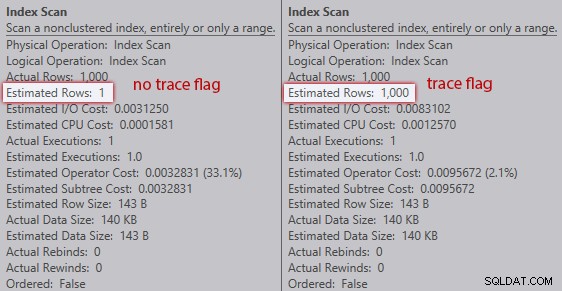
Comparação de estimativas de varredura de índice (sem sinalizador de rastreamento à esquerda, sinalizador de rastreamento à direita)
As diferenças não param por aí. Se olharmos mais de perto, podemos ver uma variedade de decisões diferentes que o otimizador tomou, todas decorrentes dessas melhores estimativas:
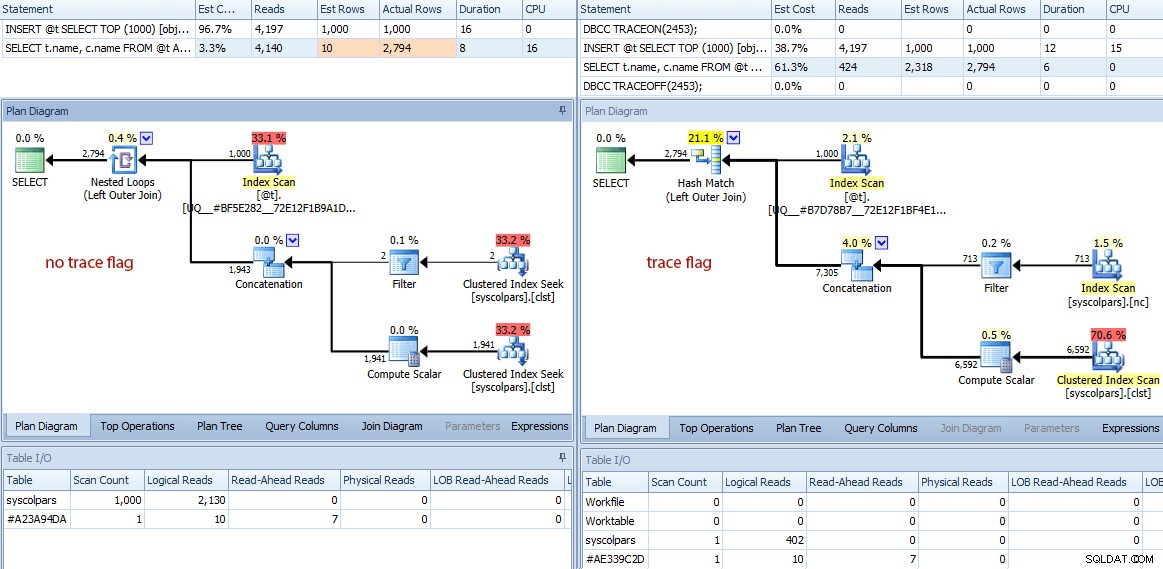
Comparação de planos (sem sinalizador de rastreamento à esquerda, sinalizador de rastreamento à direita)
Um rápido resumo das diferenças:
- A consulta sem o sinalizador de rastreamento executou 4.140 operações de leitura, enquanto a consulta com a estimativa aprimorada realizou apenas 424 (uma redução de aproximadamente 90%).
- O otimizador estimou que a consulta inteira retornaria 10 linhas sem o sinalizador de rastreamento e 2.318 linhas muito mais precisas ao usar o sinalizador de rastreamento.
- Sem o sinalizador de rastreamento, o otimizador optou por realizar uma junção de loops aninhados (o que faz sentido quando uma das entradas é estimada como muito pequena). Isso levou ao operador de concatenação e ambos os índices procuram ser executados 1.000 vezes, em contraste com a correspondência de hash escolhida no sinalizador de rastreamento, onde o operador de concatenação e as duas varreduras são executadas apenas uma vez.
- A guia Table I/O também mostra 1.000 varreduras (varreduras de intervalo disfarçadas como buscas de índice) e uma contagem de leitura lógica muito maior em relação a
syscolpars(a tabela do sistema por trás desys.all_columns). - Embora a duração não tenha sido significativamente afetada (24 milissegundos x 18 milissegundos), você provavelmente pode imaginar o tipo de impacto que essas outras diferenças podem ter em uma consulta mais séria.
- Se mudarmos o diagrama para custos estimados, podemos ver como a variável da tabela pode enganar o otimizador sem o sinalizador de rastreamento:
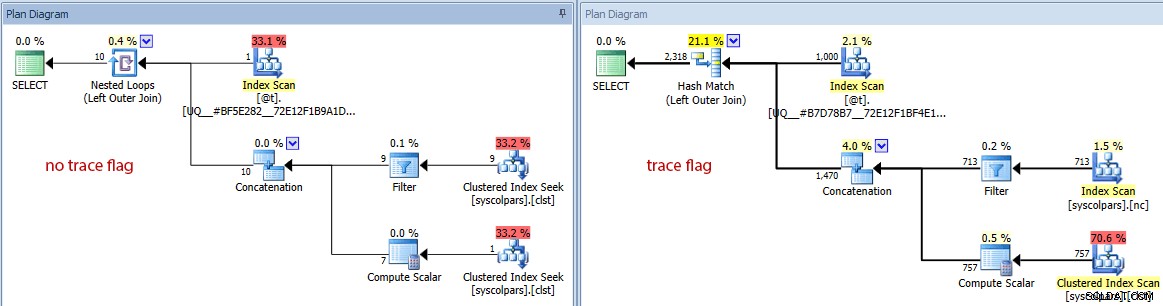
Comparando contagens de linhas estimadas (sem sinalizador de rastreamento à esquerda, rastreamento bandeira à direita)
É claro e não chocante que o otimizador faz um trabalho melhor na seleção do plano certo quando tem uma visão precisa da cardinalidade envolvida. Mas a que custo?
Recompilação e sobrecarga
Quando usamos
OPTION (RECOMPILE) com o lote acima, sem o sinalizador de rastreamento ativado, obtemos o seguinte plano - que é praticamente idêntico ao plano com o sinalizador de rastreamento (a única diferença perceptível é que as linhas estimadas são 2.316 em vez de 2.318):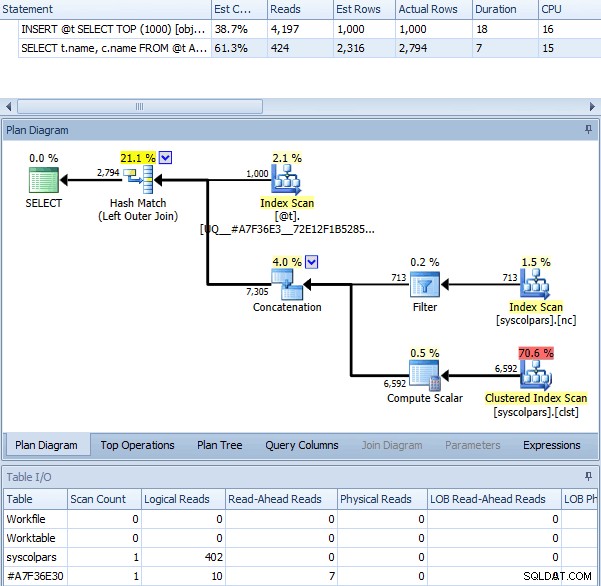
Mesma consulta com OPTION (RECOMPILE)
Portanto, isso pode levar você a acreditar que o sinalizador de rastreamento obtém resultados semelhantes acionando uma recompilação todas as vezes. Podemos investigar isso usando uma sessão de eventos estendidos muito simples:
CREATE EVENT SESSION [CaptureRecompiles] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles] ON SERVER STATE = START; Executei o seguinte conjunto de lotes, que executou 20 consultas com (a) nenhuma opção de recompilação ou sinalizador de rastreamento, (b) a opção de recompilação e (c) um sinalizador de rastreamento em nível de sessão.
/* default - no trace flag, no recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; GO 20 /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); GO 20 /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DBCC TRACEOFF(2453); GO 20
Então eu olhei para os dados do evento:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Os resultados mostram que nenhuma recompilação aconteceu na consulta padrão, a instrução que faz referência à variável da tabela foi recompilada uma vez sob o sinalizador de rastreamento e, como você pode esperar, todas as vezes com o
RECOMPILE opção:| sql_text | recompile_count |
|---|---|
| /* recompilar */ DECLARE @t TABLE (i INT … | 20 |
| /* sinalizador de rastreamento */ DBCC TRACEON(2453); DECLARE @t … | 1 |
Resultados da consulta em relação aos dados XEvents
Em seguida, desliguei a sessão Extended Events e alterei o lote para medir em escala. Essencialmente, o código mede 1.000 iterações de criação e preenchimento de uma variável de tabela e, em seguida, seleciona seus resultados em uma tabela #temp (uma maneira de suprimir a saída de tantos conjuntos de resultados descartáveis), usando cada um dos três métodos.
SET NOCOUNT ON; /* default - no trace flag, no recompile */ SELECT SYSDATETIME(); GO DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; DBCC TRACEOFF(2453); GO 1000 SELECT SYSDATETIME(); GO
Executei este lote 10 vezes e tirei as médias; eles eram:
| Método | Duração média (milissegundos) |
|---|---|
| Padrão | 23.148,4 |
| Recompilar | 29.959,3 |
| Sinalizador de rastreamento | 22.100,7 |
Duração média para 1.000 iterações
Nesse caso, obter as estimativas corretas sempre que usar a dica de recompilação foi muito mais lento do que o comportamento padrão, mas usar o sinalizador de rastreamento foi um pouco mais rápido. Isso faz sentido porque – enquanto ambos os métodos corrigem o comportamento padrão de usar uma estimativa falsa (e obter um plano ruim como resultado), as recompilações consomem recursos e, quando não produzem ou não podem produzir um plano mais eficiente, tendem a contribuem para a duração geral do lote.
Parece simples, mas espere…
O teste acima é um pouco – e intencionalmente – falho. Estamos inserindo o mesmo número de linhas (1.000) na variável de tabela todas as vezes . O que acontece se a população inicial da variável da tabela varia para diferentes lotes? Certamente veremos recompilações então, mesmo sob o sinalizador de rastreamento, certo? Hora de outro teste. Vamos configurar uma sessão de Extended Events um pouco diferente, apenas com um nome de arquivo de destino diferente (para não misturar nenhum dado da outra sessão):
CREATE EVENT SESSION [CaptureRecompiles_v2] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles_v2.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles_v2] ON SERVER STATE = START; Agora, vamos inspecionar este lote, configurando contagens de linhas para cada iteração que são significativamente diferentes. Executaremos isso três vezes, removendo os comentários apropriados para que tenhamos um lote sem um sinalizador de rastreamento ou recompilação explícita, um lote com o sinalizador de rastreamento e um lote com
OPTION (RECOMPILE) (ter um comentário preciso no início torna esses lotes mais fáceis de identificar em locais como saída de eventos estendidos):/* default, no trace flag or recompile */
/* recompile */
/* trace flag */
DECLARE @i INT = 1;
WHILE @i <= 6
BEGIN
--DBCC TRACEON(2453); -- uncomment this for trace flag
DECLARE @t TABLE(id INT PRIMARY KEY);
INSERT @t SELECT TOP (CASE @i
WHEN 1 THEN 24
WHEN 2 THEN 1782
WHEN 3 THEN 1701
WHEN 4 THEN 12
WHEN 5 THEN 15
WHEN 6 THEN 1560
END) [object_id]
FROM sys.all_objects;
SELECT t.id, c.name
FROM @t AS t
INNER JOIN sys.all_objects AS c
ON t.id = c.[object_id]
--OPTION (RECOMPILE); -- uncomment this for recompile
--DBCC TRACEOFF(2453); -- uncomment this for trace flag
DELETE @t;
SET @i += 1;
END Executei esses lotes no Management Studio, abri-os individualmente no Plan Explorer e filtrei a árvore de instruções apenas no
SELECT inquerir. Podemos ver o comportamento diferente nos três lotes observando as linhas estimadas e reais:
Comparação de três lotes, olhando linhas estimadas versus reais
Na grade mais à direita, você pode ver claramente onde as recompilações não ocorreram sob o sinalizador de rastreamento
Podemos verificar os dados do XEvents para ver o que realmente aconteceu com as recompilações:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles_v2*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Resultados:
| sql_text | recompile_count |
|---|---|
| /* recompilar */ DECLARE @i INT =1; ENQUANTO… | 6 |
| /* sinalizador de rastreamento */ DECLARE @i INT =1; ENQUANTO… | 4 |
Resultados da consulta em relação aos dados XEvents
Muito interessante! Sob o sinalizador de rastreamento, *vemos* recompilações, mas somente quando o valor do parâmetro de tempo de execução variou significativamente do valor armazenado em cache. Quando o valor do tempo de execução é diferente, mas não muito, não obtemos uma recompilação e as mesmas estimativas são usadas. Portanto, está claro que o sinalizador de rastreamento introduz um limite de recompilação para variáveis de tabela, e confirmei (através de um teste separado) que isso usa o mesmo algoritmo descrito para tabelas #temp neste artigo "antigo", mas ainda relevante. Vou provar isso em um post de acompanhamento.
Novamente, testaremos o desempenho, executando o lote 1.000 vezes (com a sessão de eventos estendidos desativada) e medindo a duração:
| Método | Duração média (milissegundos) |
|---|---|
| Padrão | 101.285,4 |
| Recompilar | 111.423,3 |
| Sinalizador de rastreamento | 110.318,2 |
Duração média para 1.000 iterações
Nesse cenário específico, perdemos cerca de 10% do desempenho forçando uma recompilação toda vez ou usando um sinalizador de rastreamento. Não tenho certeza de como o delta foi distribuído:os planos baseados em estimativas melhores não significativamente melhorar? As recompilações compensaram os ganhos de desempenho tanto ? Não quero gastar muito tempo com isso, e foi um exemplo trivial, mas serve para mostrar que brincar com a maneira como o otimizador funciona pode ser algo imprevisível. Às vezes, você pode ficar melhor com o comportamento padrão de cardinalidade =1, sabendo que nunca causará recompilações indevidas. Onde o sinalizador de rastreamento pode fazer muito sentido é se você tiver consultas em que está preenchendo repetidamente variáveis de tabela com o mesmo conjunto de dados (digamos, uma tabela de pesquisa de código postal) ou sempre usando 50 ou 1.000 linhas (digamos, preenchendo uma variável de tabela para uso em paginação). De qualquer forma, você certamente deve testar o impacto que isso tem em qualquer carga de trabalho em que planeja introduzir o sinalizador de rastreamento ou recompilações explícitas.
TVPs e tipos de mesa
Eu também estava curioso para saber como isso afetaria os tipos de tabela e se veríamos melhorias na cardinalidade para TVPs, onde esse mesmo sintoma existe. Então eu criei um tipo de tabela simples que imita a variável de tabela em uso até agora:
USE MyTestDB; GO CREATE TYPE dbo.t AS TABLE ( id INT PRIMARY KEY );
Então eu peguei o lote acima e simplesmente substituí
DECLARE @t TABLE(id INT PRIMARY KEY); com DECLARE @t dbo.t; – todo o resto ficou exatamente igual. Executei os mesmos três lotes e aqui está o que vi:
Comparação de estimativas e dados reais entre comportamento padrão, recompilação de opções e sinalizador de rastreamento 2453
Então, sim, parece que o sinalizador de rastreamento funciona exatamente da mesma maneira com TVPs - as recompilações geram novas estimativas para o otimizador quando as contagens de linhas ultrapassam o limite de recompilação e são ignoradas quando as contagens de linhas estão "próximas o suficiente".
Prós, contras e advertências
Uma vantagem do sinalizador de rastreamento é que você pode evitar algumas recompila e ainda vê a cardinalidade da tabela – contanto que você espere que o número de linhas na variável da tabela seja estável ou não observe desvios de plano significativos devido à variação da cardinalidade. Outra é que você pode habilitá-lo globalmente ou no nível da sessão e não precisar introduzir dicas de recompilação para todas as suas consultas. E, finalmente, pelo menos no caso em que a cardinalidade da variável da tabela era estável, as estimativas adequadas levaram a um desempenho melhor do que o padrão e também a um desempenho melhor do que usar a opção de recompilação – todas essas compilações certamente podem somar.
Há algumas desvantagens, também, é claro. Um que eu mencionei acima é que comparado com
OPTION (RECOMPILE) você perde certas otimizações, como a incorporação de parâmetros. Outra é que o sinalizador de rastreamento não terá o impacto esperado em planos triviais. E uma que descobri ao longo do caminho é que usando o QUERYTRACEON dica para impor o sinalizador de rastreamento no nível da consulta não funciona - até onde eu sei, o sinalizador de rastreamento deve estar no lugar quando a variável de tabela ou TVP é criada e/ou preenchida para que o otimizador veja a cardinalidade acima 1. Tenha em mente que executar o sinalizador de rastreamento globalmente introduz a possibilidade de regressões do plano de consulta para qualquer consulta envolvendo uma variável de tabela (é por isso que esse recurso foi introduzido em um sinalizador de rastreamento em primeiro lugar), portanto, certifique-se de testar toda a sua carga de trabalho não importa como você usa o sinalizador de rastreamento. Além disso, quando estiver testando esse comportamento, faça-o em um banco de dados de usuário; algumas das otimizações e simplificações que você normalmente espera que ocorram simplesmente não acontecem quando o contexto é definido como tempdb, portanto, qualquer comportamento observado pode não permanecer consistente quando você move o código e as configurações para um banco de dados de usuário.
Conclusão
Se você usar variáveis de tabela ou TVPs com um número grande, mas relativamente consistente de linhas, pode ser benéfico habilitar esse sinalizador de rastreamento para determinados lotes ou procedimentos para obter cardinalidade de tabela precisa sem forçar manualmente uma recompilação em consultas individuais. Você também pode usar o sinalizador de rastreamento no nível da instância, o que afetará todas as consultas. Mas, como qualquer mudança, em ambos os casos, você precisará ser diligente em testar o desempenho de toda a sua carga de trabalho, observando explicitamente quaisquer regressões e garantindo que deseja o comportamento do sinalizador de rastreamento porque pode confiar na estabilidade de sua variável de tabela contagem de linhas.
Fico feliz em ver o sinalizador de rastreamento adicionado ao SQL Server 2014, mas seria melhor se isso se tornasse o comportamento padrão. Não que haja alguma vantagem significativa em usar variáveis de tabela grandes sobre tabelas #temp grandes, mas seria bom ver mais paridade entre esses dois tipos de estrutura temporária que poderiam ser ditadas em um nível mais alto. Quanto mais paridade tivermos, menos as pessoas terão que deliberar sobre qual usar (ou pelo menos terão menos critérios a serem considerados na escolha). Martin Smith tem uma ótima sessão de perguntas e respostas no dba.stackexchange, que provavelmente agora deve ser atualizada:Qual é a diferença entre uma tabela temporária e uma variável de tabela no SQL Server?
Observação importante
Se você for instalar o SQL Server 2012 Service Pack 2 (seja ou não para usar esse sinalizador de rastreamento), consulte também meu post sobre uma regressão no SQL Server 2012 e 2014 que pode - em cenários raros - introduzir perda ou corrupção de dados em potencial durante as recriações de índice online. Há atualizações cumulativas disponíveis para SQL Server 2012 SP1 e SP2 e também para SQL Server 2014. Não haverá correção para a ramificação RTM 2012.
Testes adicionais
Eu tenho outras coisas na minha lista para testar. Por um lado, gostaria de ver se esse sinalizador de rastreamento tem algum efeito sobre os tipos de tabela In-Memory no SQL Server 2014. Também vou provar sem sombra de dúvida que o sinalizador de rastreamento 2453 usa o mesmo limite de recompilação para tabela variáveis e TVPs como faz para tabelas #temp.