Ler da memória sempre terá mais desempenho do que ir para o disco, portanto, para todas as tecnologias de banco de dados, você deve usar o máximo de memória possível. Se você não tiver certeza sobre a configuração ou tiver um erro, isso pode gerar alta utilização de memória ou até mesmo um problema de falta de memória.
Neste blog, veremos como verificar a utilização de memória do PostgreSQL e qual parâmetro você deve levar em consideração para ajustá-lo. Para isso, vamos começar vendo uma visão geral da arquitetura do PostgreSQL.
Arquitetura PostgreSQL
A arquitetura do PostgreSQL é baseada em três partes fundamentais:Processos, Memória e Disco.
A memória pode ser classificada em duas categorias:
- Memória local :Ele é carregado por cada processo de back-end para seu próprio uso no processamento de consultas. Está dividido em subáreas:
- Work mem:O work mem é usado para classificar tuplas por operações ORDER BY e DISTINCT e para unir tabelas.
- Trabalho de manutenção mem:Alguns tipos de operações de manutenção utilizam esta área. Por exemplo, VACUUM, se você não estiver especificando autovacuum_work_mem.
- Buffers temporários:são usados para armazenar tabelas temporárias.
- Memória Compartilhada :É alocado pelo servidor PostgreSQL quando é iniciado e é utilizado por todos os processos. Está dividido em subáreas:
- pool de buffer compartilhado:onde o PostgreSQL carrega páginas com tabelas e índices do disco, para trabalhar diretamente da memória, reduzindo o acesso ao disco.
- buffer WAL:Os dados WAL são o log de transações no PostgreSQL e contém as alterações no banco de dados. O buffer WAL é a área onde os dados WAL são armazenados temporariamente antes de gravá-los em disco nos arquivos WAL. Isso é feito a cada tempo pré-definido chamado checkpoint. Isso é muito importante para evitar a perda de informações em caso de falha do servidor.
- Registro de confirmação:salva o status de todas as transações para controle de simultaneidade.
Como saber o que está acontecendo
Se você estiver com alta utilização de memória, primeiro você deve confirmar qual processo está gerando o consumo.
Usando o comando Linux “Top”
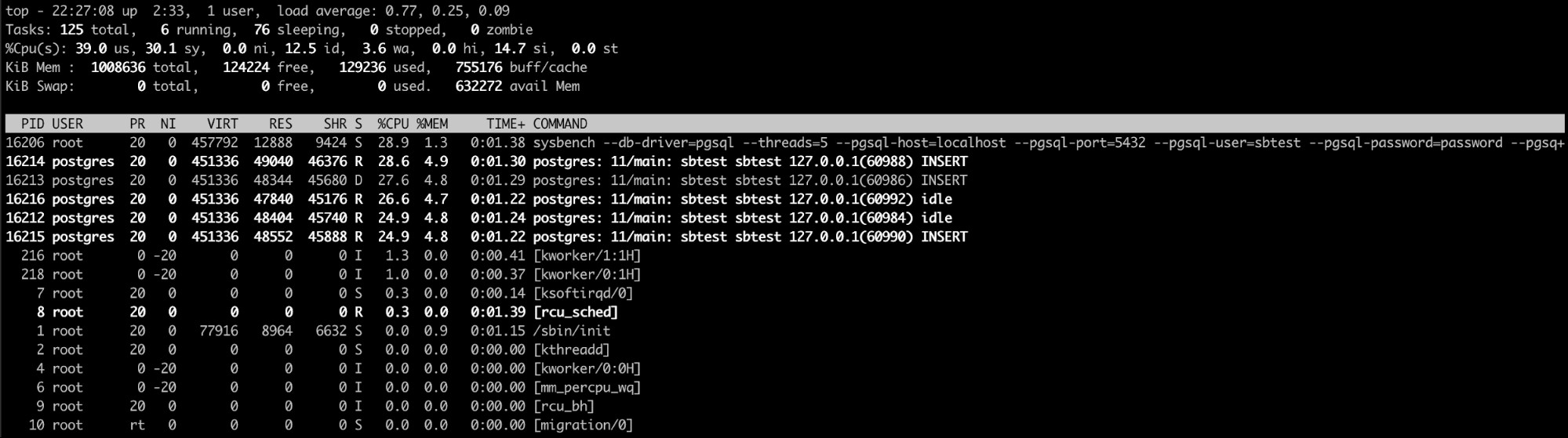
O comando top linux é provavelmente a melhor opção aqui (ou mesmo um um como htop). Com este comando, você pode ver os processos/processos que estão consumindo muita memória.
Ao confirmar que o PostgreSQL é responsável por esse problema, o próximo passo é verificar o motivo.
Usando o log do PostgreSQL
Verificar os logs do PostgreSQL e do sistema é definitivamente uma boa maneira de obter mais informações sobre o que está acontecendo em seu banco de dados/sistema. Você pode ver mensagens como:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childSe você não tiver memória livre suficiente.
Ou mesmo vários erros de mensagem do banco de dados como:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedQuando você está tendo algum comportamento inesperado no banco de dados. Portanto, os logs são úteis para detectar esses tipos de problemas e ainda mais. Você pode automatizar esse monitoramento analisando os arquivos de log procurando por obras como “FATAL”, “ERROR” ou “Kill”, para receber um alerta quando isso acontecer.
Usando Pg_top
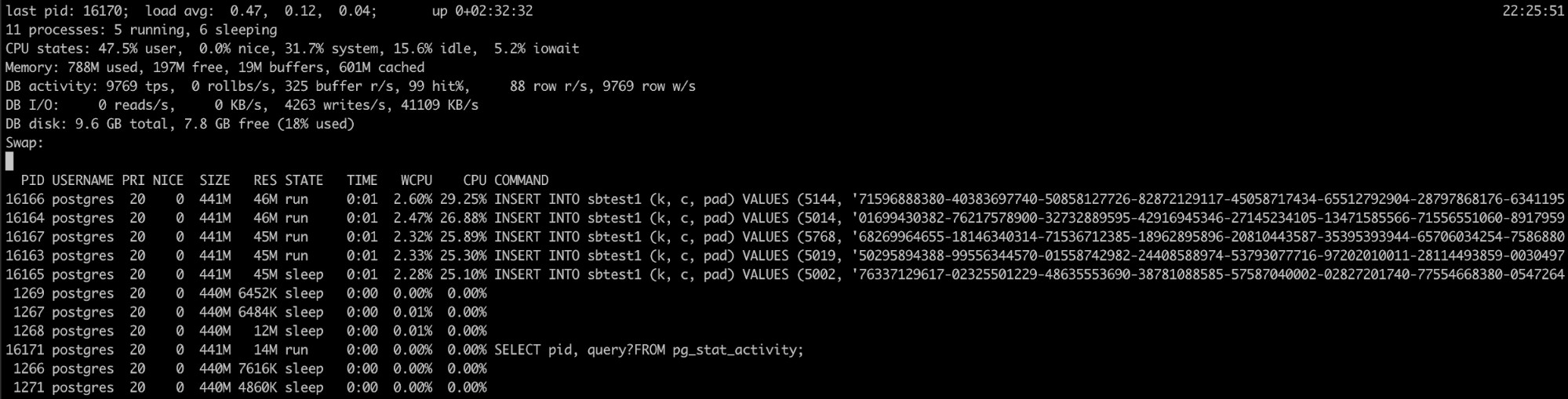
Se você sabe que o processo PostgreSQL está tendo uma alta utilização de memória, mas os logs não ajudaram, você tem outra ferramenta que pode ser útil aqui, pg_top.
Esta ferramenta é semelhante à principal ferramenta linux, mas é especificamente para PostgreSQL. Assim, ao usá-lo, você terá informações mais detalhadas sobre o que está executando seu banco de dados e poderá até matar consultas ou executar um trabalho de explicação se detectar algo errado. Você pode encontrar mais informações sobre esta ferramenta aqui.
Mas o que acontece se você não conseguir detectar nenhum erro e o banco de dados ainda estiver usando muita memória RAM. Portanto, você provavelmente precisará verificar a configuração do banco de dados.
Quais parâmetros de configuração levar em consideração
Se tudo parecer bem, mas você ainda tiver o problema de alta utilização, verifique a configuração para confirmar se está correta. Portanto, a seguir, são parâmetros que você deve levar em consideração neste caso.
buffers_compartilhados
Esta é a quantidade de memória que o servidor de banco de dados usa para buffers de memória compartilhada. Se esse valor for muito baixo, o banco de dados usará mais disco, o que causaria mais lentidão, mas se for muito alto, poderá gerar alta utilização de memória. De acordo com a documentação, se você tiver um servidor de banco de dados dedicado com 1 GB ou mais de RAM, um valor inicial razoável para shared_buffers é 25% da memória do seu sistema.
trabalho_mem
Especifica a quantidade de memória que será usada pelo ORDER BY, DISTINCT e JOIN antes de gravar nos arquivos temporários no disco. Assim como os shared_buffers, se configurarmos este parâmetro muito baixo, podemos ter mais operações indo para o disco, mas muito alto é perigoso para o uso de memória. O valor padrão é 4 MB.
max_connections
Work_mem também anda de mãos dadas com o valor max_connections, pois cada conexão executará essas operações ao mesmo tempo, e cada operação poderá usar a quantidade de memória especificada por esse valor antes dela começa a gravar dados em arquivos temporários. Este parâmetro determina o número máximo de conexões simultâneas ao nosso banco de dados, se configurarmos um número alto de conexões e não levarmos isso em consideração, você pode começar a ter problemas de recursos. O valor padrão é 100.
temp_buffers
Os buffers temporários são usados para armazenar as tabelas temporárias usadas em cada sessão. Este parâmetro define a quantidade máxima de memória para esta tarefa. O valor padrão é 8 MB.
maintenance_work_mem
Esta é a memória máxima que uma operação como Aspirar, adicionar índices ou chaves estrangeiras pode consumir. O bom é que apenas uma operação desse tipo pode ser executada em uma sessão, e não é o mais comum estar executando várias delas ao mesmo tempo no sistema. O valor padrão é 64 MB.
autovacuum_work_mem
O vácuo usa o Maintenance_work_mem por padrão, mas podemos separá-lo usando este parâmetro. Podemos especificar a quantidade máxima de memória a ser usada por cada trabalhador de autovacuum aqui.
wal_buffers
A quantidade de memória compartilhada usada para dados WAL que ainda não foram gravados em disco. A configuração padrão é 3% de shared_buffers, mas não menos que 64kB nem mais que o tamanho de um segmento WAL, normalmente 16MB.
Conclusão
Existem diferentes razões para ter uma alta utilização de memória e detectar o problema raiz pode ser uma tarefa demorada. Neste blog, mencionamos diferentes maneiras de verificar a utilização de memória do PostgreSQL e qual parâmetro você deve levar em consideração para ajustá-lo, para evitar o uso excessivo de memória.