Introdução aos índices do SQL Server
O Microsoft SQL Server é considerado um dos sistemas de gerenciamento de banco de dados relacional (RDBMS ), em que os dados são organizados logicamente em linhas e colunas que são armazenadas em contêineres de dados chamados tabelas. Fisicamente, as tabelas são armazenadas como páginas de 8 KB que podem ser organizados em tabelas Heap ou B-Tree Clustered. Na Pilha tabela, não há ordem de classificação que controle a ordem dos dados dentro das páginas de dados e a sequência de páginas dentro dessa tabela, pois não há índice clusterizado definido nessa tabela para impor o mecanismo de classificação. Se um índice clusterizado for definido em uma coluna do grupo de colunas da tabela, os dados serão classificados dentro das páginas de dados com base nos valores das colunas de chave de índice clusterizado e as páginas serão vinculadas com base nesses valores de chave de índice. Essa tabela classificada é chamada de Tabela em cluster .
No SQL Server, o índice é considerado uma chave importante e eficaz no processo de ajuste de desempenho. O objetivo de criar um índice é acelerar o acesso à tabela base e recuperar os dados solicitados sem precisar varrer todas as linhas da tabela para retornar os dados solicitados. Você pode pensar no índice do banco de dados como um índice de livro que o ajuda a encontrar rapidamente as palavras no livro, sem precisar ler o livro inteiro para encontrar essa palavra. Por exemplo, suponha que você precise recuperar informações sobre um cliente específico usando um ID de cliente. Se não houver nenhum índice definido para a coluna Customer ID nesta tabela, o SQL Server Engine verificará todas as linhas da tabela, uma a uma, para recuperar o cliente com a ID fornecida. Se um índice for definido para a coluna ID do cliente nesta tabela, o SQL Server Engine procurará os valores solicitados de ID do cliente no índice classificado, em vez da tabela base, para recuperar informações sobre o cliente, reduzindo o número de verificações linhas para recuperar os dados.
No SQL Server, o índice é estruturado logicamente como páginas de 8 K, ou nós de índice, na forma de uma árvore B. A estrutura B-Tree contém três níveis:um Nível raiz que inclui uma página de índice no topo da árvore B, um Nível de Folha que está localizado na parte inferior da árvore B e contém páginas de dados e um Nível intermediário que inclui todos os nós localizados entre os níveis raiz e folha, com valores de chave de índice e ponteiros para as páginas seguintes. Essa forma de árvore B fornece uma maneira rápida de navegar pelas páginas de dados da esquerda para a direita e de cima para baixo, com base na chave de índice.
No SQL Server, existem dois tipos principais de índices, um índice em cluster em que os dados reais são armazenados nas páginas de nível folha do índice, com a capacidade de criar apenas um índice clusterizado para cada tabela, pois os dados dentro das páginas de dados e a ordem das páginas serão classificados com base no índice clusterizado chave. Se você definir uma restrição de chave primária em sua tabela, um índice clusterizado será criado automaticamente se nenhum índice clusterizado tiver sido definido anteriormente para essa tabela. O segundo tipo de índices é um índice não clusterizado que inclui uma cópia classificada das colunas de chave de índice e um ponteiro para o restante das colunas na tabela base ou no índice clusterizado, com a capacidade de criar até 999 índices não clusterizados para cada tabela.
O SQL Server nos fornece outros tipos especiais de índices, como um índice único que é criado automaticamente quando uma restrição exclusiva é definida para impor a exclusividade de valores de coluna específicos, um índice composto em que mais de uma coluna de chave participará da chave de índice, um Índice de cobertura em que todas as colunas solicitadas por uma consulta específica participarão da chave de índice, um índice filtrado que é um índice não clusterizado otimizado com um predicado de filtro para indexar apenas uma pequena parte das linhas da tabela, um índice espacial que é criado nas colunas que armazenam dados espaciais, um índice XML que é criado em objetos binários grandes (BLOBs) XML em colunas de tipo de dados XML, um índice Columnstore em que os dados são organizados em formato de dados colunar, um índice de texto completo que é criado pelo mecanismo de texto completo do SQL Server e um índice de hash que é usado em tabelas com otimização de memória.
Como eu costumava chamar o índice do SQL Server, isso é uma faca de dois gumes , onde o SQL Server Query Optimizer pode se beneficiar do índice bem projetado para melhorar o desempenho de seus aplicativos, acelerando o processo de recuperação de dados. Por outro lado, um índice mal projetado não será escolhido pelo SQL Server Query Optimizer e degradará o desempenho de seus aplicativos, diminuindo a velocidade das operações de modificação de dados e consumindo seu armazenamento sem aproveitá-lo nos dados. processos de recuperação. Portanto, é melhor seguir primeiro as práticas recomendadas e diretrizes de criação de índice, verificar o efeito da criação de um no ambiente de desenvolvimento e encontrar um compromisso entre a velocidade das operações de recuperação de dados e a sobrecarga de adicionar esse índice nas operações de modificação de dados e os requisitos de espaço desse índice, antes de aplicá-lo ao ambiente de produção.
Antes de criar um índice, você precisa estudar os diferentes aspectos que afetam a criação e o uso do índice. Isso inclui o tipo da carga de trabalho do banco de dados, processamento de transações online (OLTP) ou processamento analítico online (OLAP), o tamanho da tabela , as características das colunas da tabela , a ordem de classificação das colunas na consulta, o tipo de índice que corresponde à consulta e às propriedades de armazenamento, como FILLFACTOR e PAD_INDEX opções que controlam a porcentagem de espaço em cada folha e as páginas de nível intermediário a serem preenchidas com dados.
Fragmentação de índice do SQL Server
Seu trabalho como DBA não se limita a criar o índice certo. Depois que o índice for criado, você deve monitorar o uso e as estatísticas do índice, por exemplo, você precisa saber se esse índice é usado mal ou não é usado. Assim, você pode fornecer a solução correta para manter esses índices ou substituí-los por outros mais eficientes. Desta forma, você manterá o mais alto desempenho aplicável ao seu sistema. Você pode se perguntar:por que o SQL Server Query Optimizer não usa mais meu índice, embora já o fizesse antes?
A resposta está relacionada principalmente aos dados contínuos e alterações de esquema que são executadas na tabela base que devem ser refletidas nos índices. Com o tempo, e com todas essas mudanças, as páginas de índice ficam desordenadas, fazendo com que o índice fique fragmentado. Outro motivo para a fragmentação é uma tentativa de inserir um novo valor ou atualizar o valor atual, e o novo valor não cabe no espaço livre disponível no momento. Neste caso, a página será dividida em duas páginas, onde a nova página será criada fisicamente após a última página. E você pode imaginar a leitura de um índice fragmentado e o número de páginas que devem ser digitalizadas e, claro, o número de operações de E/S realizadas para recuperar vários registros devido à distância entre essas páginas. E devido a esse custo extra de usar esse índice fragmentado, o SQL Server Query Optimizer ignorará esse índice.
Diferentes maneiras de obter fragmentação de índice
O SQL Server nos fornece diferentes maneiras de obter a porcentagem de fragmentação do índice. A primeira maneira é verificar a porcentagem de fragmentação do índice no Índice Propriedades janela, em Fragmentação guia, como mostrado abaixo:
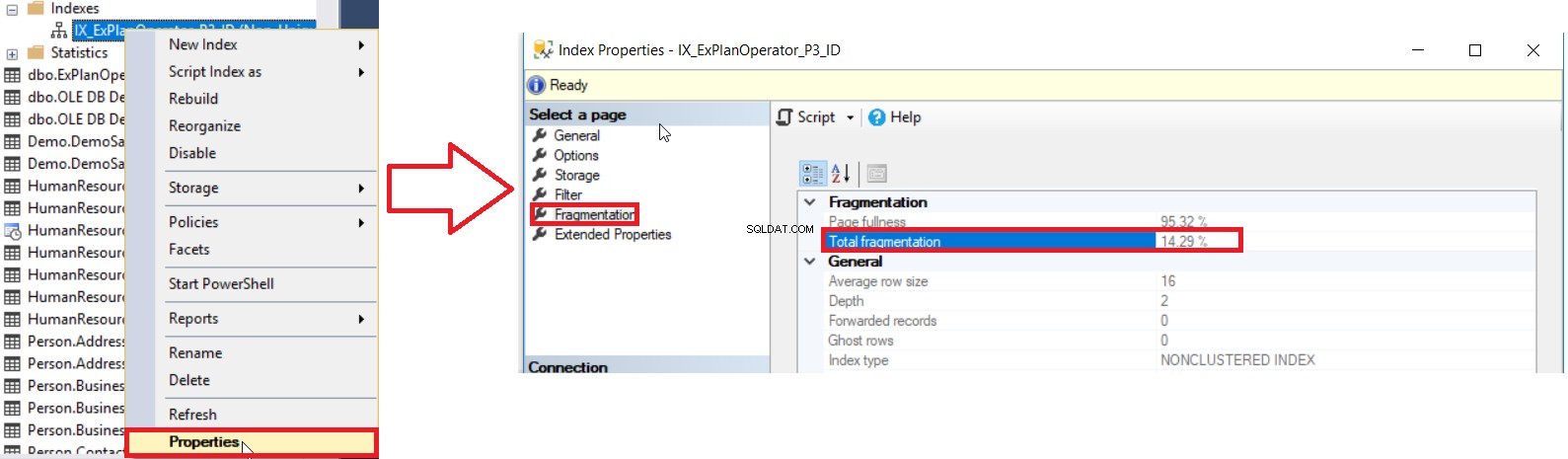
Mas para verificar o nível de fragmentação de vários índices, você precisa primeiro executar a verificação do método de interface do usuário para todos os índices, um por um, o que é uma operação que desperdiça tempo. O segundo método disponível para verificar o nível de fragmentação de todos os índices do banco de dados é consultar o DMF sys.dm_db_index_physical_stats e juntá-lo ao DMV sys.indexes para recuperar todas as informações sobre esses índices, levando em consideração que essas estatísticas serão atualizadas quando o O serviço SQL Server é reiniciado, usando uma consulta semelhante à seguinte:
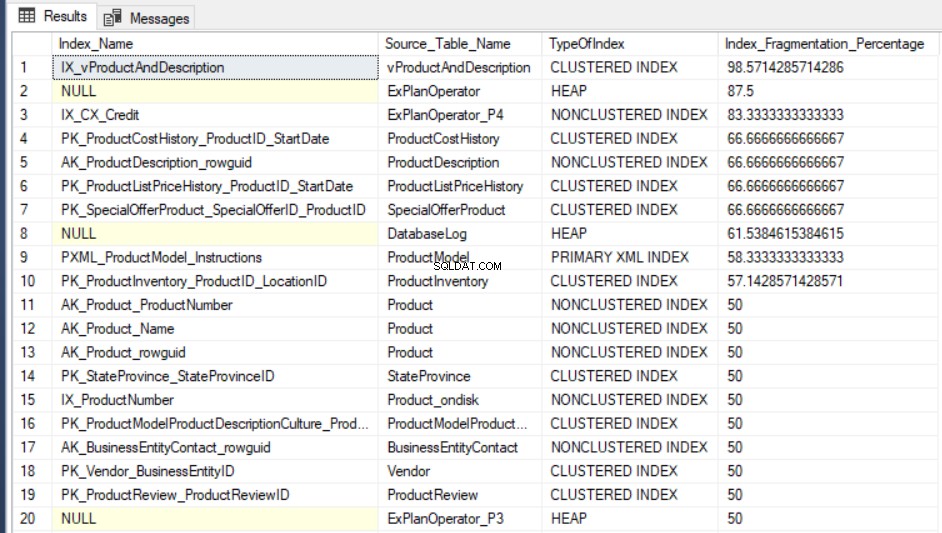
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
O resultado de saída da consulta do AdventureWorks2016CTP3 banco de dados de teste será semelhante ao seguinte:
O terceiro método de obter a porcentagem de fragmentação é usar o relatório padrão interno do SQL Server chamado Index Physical Statistics. Este relatório retorna informações úteis sobre as partições de índice, porcentagem de fragmentação, número de páginas em cada partição de índice e recomendações sobre como corrigir o problema de fragmentação de índice recriando ou reorganizando o índice. Para visualizar o relatório, clique com o botão direito do mouse em seu banco de dados, selecione a opção Reports, Standard Reports e selecione Index Physical Statistics conforme abaixo:
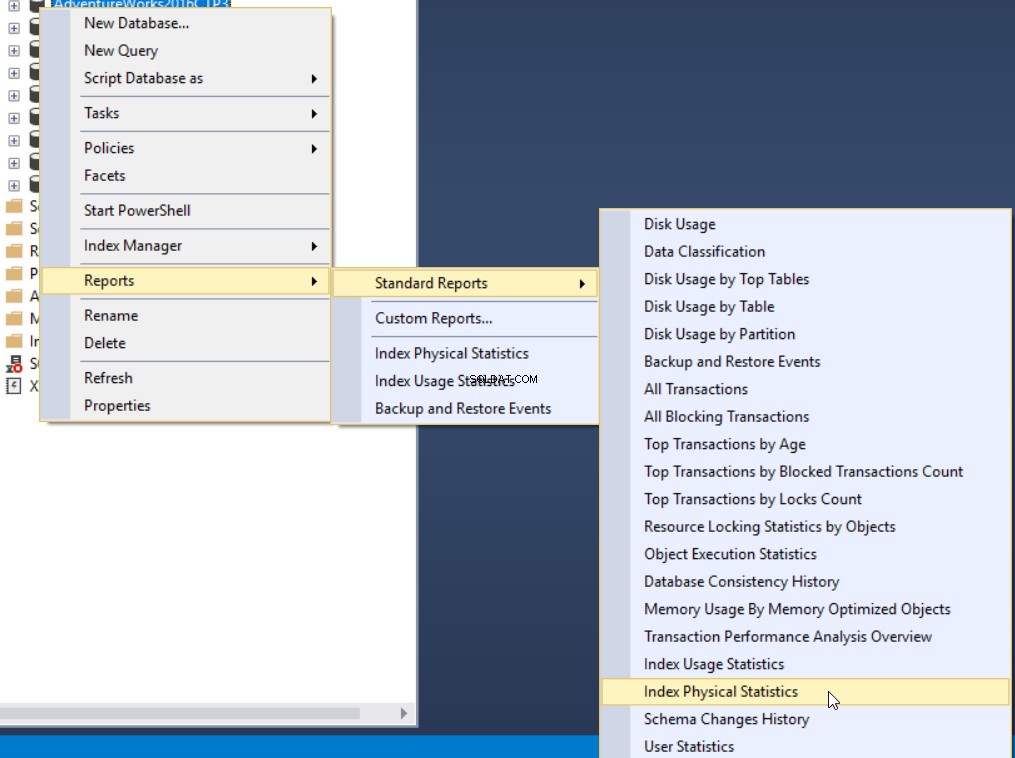
No nosso caso, o relatório gerado ficará assim:
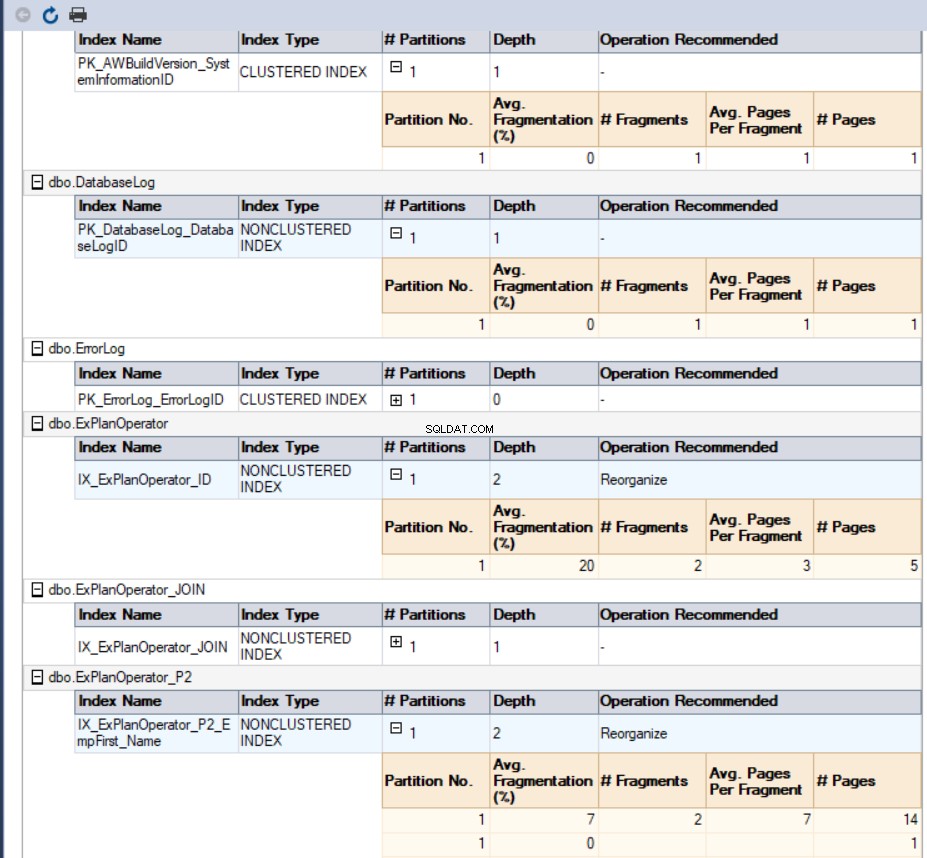
A última e mais fácil maneira de recuperar a porcentagem de fragmentação de todos os índices do banco de dados é a ferramenta dbForge Index Manager. O Gerenciador de Índice dbForge tool é um add-in que pode ser adicionado ao seu SQL Server Management Studio para analisar os índices de bancos de dados SQL Server, fornecendo um relatório muito útil com o status dos índices de banco de dados selecionados e sugestões de manutenção para corrigir esses problemas de fragmentação de índice.
Após instalar o add-in dbForge Index Manager em seu SSMS, você pode executá-lo clicando com o botão direito do mouse no banco de dados a ser verificado, selecione Index Manager , em seguida, Gerenciar a fragmentação do índice como mostrado abaixo:
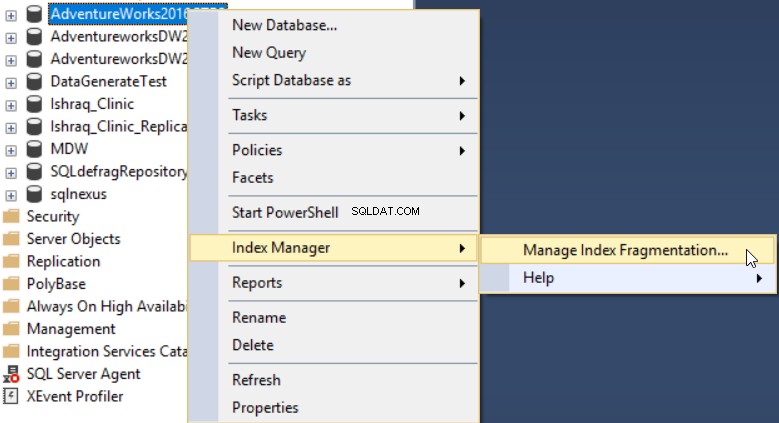
A ferramenta dbForge Index Manager permite obter uma visão geral da fragmentação dos índices de banco de dados selecionados, com recomendações para as ações adequadas para corrigir esse problema, conforme mostrado abaixo:

A ferramenta dbForge Index Manager também permite alternar entre bancos de dados, fornecendo um novo relatório após a varredura desse banco de dados, conforme mostrado abaixo:
O relatório de fragmentação do índice gerado pela ferramenta dbForge Index Manager pode ser exportado para um arquivo CSV para analisar o status da fragmentação dos índices, conforme mostrado abaixo:
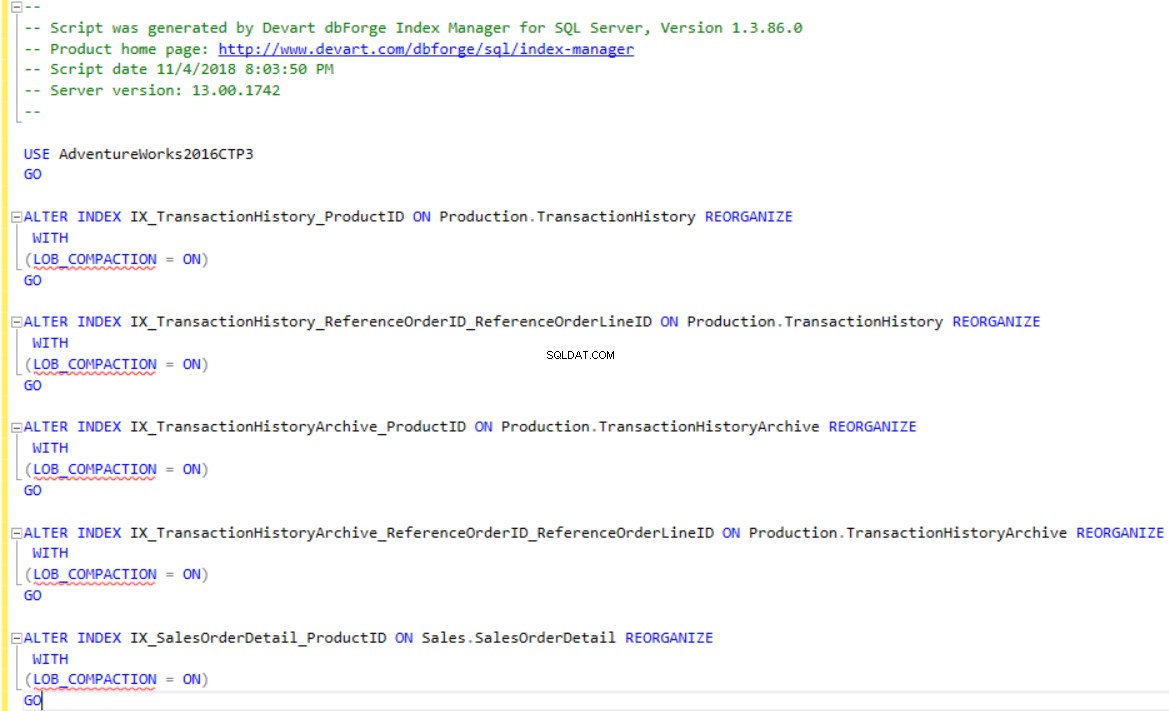
O dbForge Index Manager permite gerar scripts T-SQL para reconstruir ou reorganizar os índices conforme a recomendação da ferramenta. Use as Alterações de script opção para mostrar ou salvar o script para os índices que estão fragmentados, conforme mostrado abaixo:
A ferramenta dbForge Index Manager oferece a capacidade de corrigir o problema de fragmentação do índice diretamente clicando no botão Corrigir botão que executará a ação recomendada diretamente nos índices selecionados, mostrando o status da correção no Resultado coluna como mostrado abaixo:

Se você clicar no botão Reanalisar botão, ele verificará a fragmentação do índice no banco de dados novamente após executar a operação de correção com sucesso. O que está listado aqui neste artigo é apenas uma introdução de como a ferramenta dbForge Index Manager nos ajudará a identificar e corrigir problemas de fragmentação de índice. Minha recomendação para você é baixá-lo e verificar o que esta ferramenta pode lhe oferecer.
Links Úteis:
- Princípios básicos do índice
- Tipos de índices
- Índices clusterizados e não clusterizados descritos
- Estruturas de índice em cluster
Ferramenta útil:
dbForge Index Manager – suplemento SSMS útil para analisar o status de índices SQL e corrigir problemas com fragmentação de índice.