Você provavelmente cometeu alguns desses erros quando estava iniciando sua carreira de designer de banco de dados. Talvez você ainda os esteja fazendo, ou fará alguns no futuro. Não podemos voltar no tempo e ajudá-lo a desfazer seus erros, mas podemos evitar algumas dores de cabeça futuras (ou presentes).
A leitura deste artigo pode economizar muitas horas gastas corrigindo problemas de design e código, então vamos mergulhar. Dividi a lista de erros em dois grupos principais:aqueles que são não técnicos na natureza e aqueles que são estritamente técnicos . Ambos os grupos são uma parte importante do design do banco de dados.
Obviamente, se você não tiver habilidades técnicas, não saberá como fazer algo. Não é surpreendente ver esses erros na lista. Mas habilidades não técnicas? As pessoas podem esquecê-los, mas essas habilidades também são uma parte muito importante do processo de design. Eles agregam valor ao seu código e relacionam a tecnologia ao problema do mundo real que você precisa resolver.
Então, vamos começar com as questões não técnicas primeiro, depois passar para as técnicas.
Erros não técnicos de design de banco de dados
Nº 1 Planejamento ruim
Este é definitivamente um problema não técnico, mas é um problema importante e comum. Todos nós ficamos empolgados quando um novo projeto começa e, entrando nele, tudo parece ótimo. No início, o projeto ainda é uma página em branco e você e seu cliente estão felizes em começar a trabalhar em algo que criará um futuro melhor para ambos. Tudo isso é ótimo, e um grande futuro provavelmente será o resultado final. Mas ainda assim, precisamos manter o foco. Esta é a parte do projeto onde podemos cometer erros cruciais.
Antes de se sentar para desenhar um modelo de dados, você precisa ter certeza de que:
- Você está completamente ciente do que seu cliente faz (ou seja, seus planos de negócios relacionados a este projeto e também sua visão geral) e o que ele deseja que este projeto alcance agora e no futuro.
- Você entende o processo de negócios e, se ou quando necessário, está pronto para fazer sugestões para simplificá-lo e melhorá-lo (por exemplo, para aumentar a eficiência e a receita, reduzir custos e horas de trabalho etc.).
- Você entende o fluxo de dados na empresa do cliente. O ideal é que você conheça todos os detalhes:quem trabalha com os dados, quem faz alterações, quais relatórios são necessários, quando e por que tudo isso acontece.
- Você pode usar o idioma/terminologia que seu cliente usa. Embora você possa ou não ser um especialista em sua área, seu cliente definitivamente é. Peça que expliquem o que você não entendeu. E ao explicar detalhes técnicos ao cliente, use linguagem e terminologia que ele entenda.
- Você sabe quais tecnologias usará, desde o mecanismo de banco de dados e linguagens de programação até outras ferramentas. O que você decidir usar está intimamente relacionado ao problema que você resolverá, mas é importante incluir as preferências do cliente e sua infraestrutura de TI atual.
Durante a fase de planejamento, você deve obter respostas para estas perguntas:
- Quais serão as tabelas centrais do seu modelo? Você provavelmente terá alguns deles, enquanto as outras tabelas serão algumas das usuais (por exemplo, user_account, role). Não se esqueça dos dicionários e das relações entre tabelas.
- Quais nomes serão usados para tabelas no modelo? Lembre-se de manter a terminologia semelhante à que o cliente usa atualmente.
- Quais regras serão aplicadas ao nomear tabelas e outros objetos? (Consulte o Ponto 4 sobre convenções de nomenclatura.)
- Quanto tempo levará todo o projeto? Isso é importante, tanto para sua agenda quanto para o cronograma do cliente.
Somente quando você tiver todas essas respostas você estará pronto para compartilhar uma solução inicial para o problema. Essa solução não precisa ser um aplicativo completo – talvez um pequeno documento ou mesmo algumas frases no idioma do negócio do cliente.
Um bom planejamento não é específico para modelagem de dados; é aplicável a quase qualquer projeto de TI (e não TI). Pular é apenas uma opção se 1) você tiver um projeto muito pequeno; 2) as tarefas e objetivos são claros e 3) você está com muita pressa. Um exemplo histórico são os engenheiros de lançamento do Sputnik 1 dando instruções verbais aos técnicos que o montavam. O projeto estava com pressa por causa das notícias de que os EUA planejavam lançar seu próprio satélite em breve – mas acho que você não terá tanta pressa.
#2 Comunicação insuficiente com clientes e desenvolvedores
Ao iniciar o processo de design do banco de dados, você provavelmente entenderá a maioria dos principais requisitos. Alguns são muito comuns, independentemente do negócio, por exemplo. funções e status do usuário. Por outro lado, algumas tabelas em seu modelo serão bastante específicas. Por exemplo, se você estiver construindo uma maquete para uma empresa de táxi, terá tabelas para veículos, motoristas, clientes etc.
Ainda assim, nem tudo será óbvio no início de um projeto. Você pode entender mal alguns requisitos, o cliente pode adicionar algumas novas funcionalidades, você verá algo que poderia ser feito de forma diferente, o processo pode mudar, etc. Tudo isso causa mudanças no modelo. A maioria das alterações exige a adição de novas tabelas, mas às vezes você removerá ou modificará tabelas. Se você já começou a escrever código que usa essas tabelas, precisará reescrever esse código também.
Para reduzir o tempo gasto em alterações inesperadas, você deve:
- Fale com desenvolvedores e clientes e não tenha medo de fazer perguntas vitais para os negócios. Quando você achar que está pronto para começar, pergunte a si mesmo A situação X está coberta em nosso banco de dados? O cliente está fazendo Y dessa maneira; esperamos uma mudança no futuro próximo? Quando tivermos certeza de que nosso modelo tem a capacidade de armazenar tudo o que precisamos da maneira certa, podemos começar a codificar.
- Se você enfrentar uma grande mudança em seu design e já tiver muito código escrito, não tente uma solução rápida. Faça como deveria ter sido feito, não importa qual seja a situação atual. Uma solução rápida pode economizar algum tempo agora e provavelmente funcionaria bem por um tempo, mas pode se transformar em um verdadeiro pesadelo mais tarde.
- Se você acha que algo está bem agora, mas pode se tornar um problema mais tarde, não ignore. Analise essa área e implemente mudanças se elas melhorarem a qualidade e o desempenho do sistema. Vai custar algum tempo, mas você entregará um produto melhor e dormirá muito melhor.
Se você tentar evitar fazer alterações em seu modelo de dados quando vir um problema em potencial – ou se optar por uma solução rápida em vez de fazê-lo corretamente – você pagará por isso mais cedo ou mais tarde.
Além disso, mantenha contato com seu cliente e os desenvolvedores durante todo o projeto. Sempre verifique e veja se alguma mudança foi feita desde sua última discussão.
#3 Documentação deficiente ou ausente
Para a maioria de nós, a documentação vem no final do projeto. Se estivermos bem organizados, provavelmente documentamos as coisas ao longo do caminho e só precisaremos encerrar tudo. Mas honestamente, isso geralmente não é o caso. A documentação de escrita acontece pouco antes de o projeto ser fechado – e logo após terminarmos mentalmente com esse modelo de dados!
O preço pago por um projeto mal documentado pode ser bem alto, algumas vezes maior do que o preço que pagamos para documentar tudo adequadamente. Imagine encontrar um bug alguns meses depois de fechar o projeto. Porque você não documentou corretamente, você não sabe por onde começar.
Enquanto estiver trabalhando, não se esqueça de escrever comentários. Explique tudo o que precisa de explicações adicionais e, basicamente, anote tudo o que você acha que será útil um dia. Você nunca sabe se ou quando precisará dessa informação extra.
Erros técnicos no projeto do banco de dados
#4 Não usar uma convenção de nomenclatura
Você nunca sabe ao certo quanto tempo um projeto durará e se terá mais de uma pessoa trabalhando no modelo de dados. Há um ponto em que você está realmente perto do modelo de dados, mas ainda não começou a desenhá-lo. É quando é aconselhável decidir como você nomeará os objetos em seu modelo, no banco de dados e no aplicativo geral. Antes de modelar, você deve saber:
- Os nomes das tabelas são singulares ou plurais?
- Agruparemos as tabelas usando nomes? (Por exemplo, todas as tabelas relacionadas ao cliente contêm “client_”, todas as tabelas relacionadas a tarefas contêm “task_”, etc.)
- Vamos usar letras maiúsculas e minúsculas ou apenas minúsculas?
- Que nome usaremos para as colunas de ID? (Provavelmente, será "id".)
- Como nomearemos as chaves estrangeiras? (Provavelmente “id_” e o nome da tabela referenciada.)
Compare parte de um modelo que não usa convenções de nomenclatura com a mesma parte que usa convenções de nomenclatura, conforme mostrado abaixo:
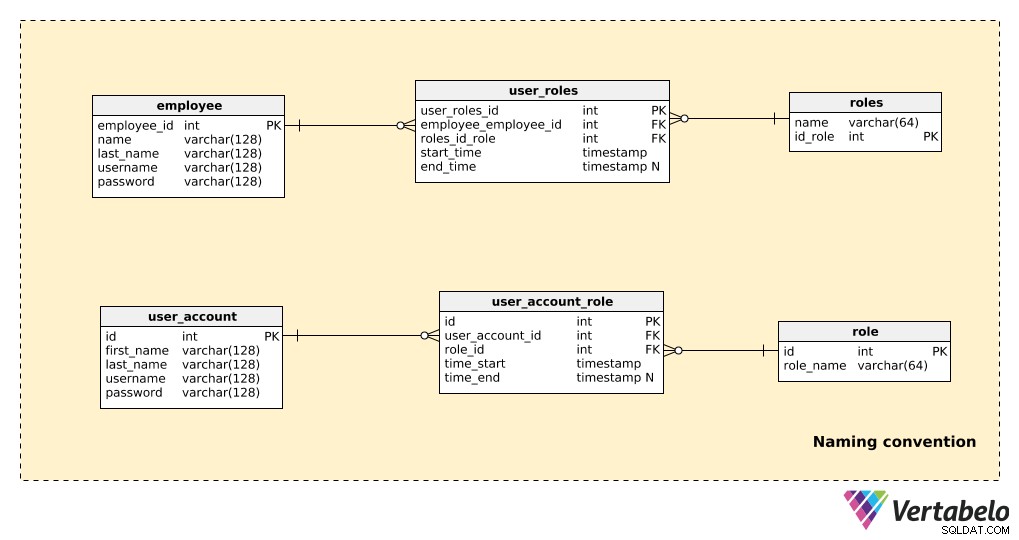
Existem apenas algumas tabelas aqui, mas ainda é bastante óbvio qual modelo é mais fácil de ler. Notar que:
- Ambos os modelos “funcionam”, então não há problemas no lado técnico.
- No exemplo de não-convenção de nomenclatura (as três tabelas superiores), há algumas coisas que afetam significativamente a legibilidade:usar as formas singular e plural nos nomes das tabelas; nomes de chave primária não padronizados (
employees_id,id_role); e os atributos em tabelas diferentes compartilham o mesmo nome (por exemplo, o nome aparece em ambos os campos “employee” e os “roles” tabelas).
Agora imagine a bagunça que criaríamos se nosso modelo contivesse centenas de tabelas. Talvez pudéssemos trabalhar com esse modelo (se o tivéssemos criado nós mesmos), mas daríamos muito azar a alguém se tivesse que trabalhar nele depois de nós.
Para evitar problemas futuros com nomes, não use palavras reservadas SQL, caracteres especiais ou espaços neles.
Portanto, antes de começar a criar qualquer nome, faça um documento simples (talvez com apenas algumas páginas) que descreva a convenção de nomenclatura que você usou. Isso aumentará a legibilidade de todo o modelo e simplificará o trabalho futuro.
Você pode ler mais sobre convenções de nomenclatura nestes dois artigos:
- Convenções de nomenclatura na modelagem de banco de dados
- Uma visão lógica sem emoção das convenções de nomenclatura do SQL Server
#5 Problemas de normalização
A normalização é uma parte essencial do design de banco de dados. Todo banco de dados deve ser normalizado para pelo menos 3NF (as chaves primárias são definidas, as colunas são atômicas e não há grupos repetidos, dependências parciais ou dependências transitivas). Isso reduz a duplicação de dados e garante a integridade referencial.
Você pode ler mais sobre normalização neste artigo. Em suma, sempre que falamos sobre o modelo de banco de dados relacional, estamos falando sobre o banco de dados normalizado. Se um banco de dados não for normalizado, encontraremos vários problemas relacionados à integridade dos dados.
Em alguns casos, podemos querer desnormalizar nosso banco de dados. Se você fizer isso, tenha um bom motivo. Você pode ler mais sobre a desnormalização de banco de dados aqui.
#6 Usando o modelo Entity-Attribute-Value (EAV)
EAV significa entidade-atributo-valor. Essa estrutura pode ser usada para armazenar dados adicionais sobre qualquer coisa em nosso modelo. Vejamos um exemplo.
Suponha que queremos armazenar alguns atributos adicionais do cliente. O “
customer ” é nossa entidade, o “attribute ” é obviamente nosso atributo, e o “attribute_value ” contém o valor desse atributo para esse cliente. 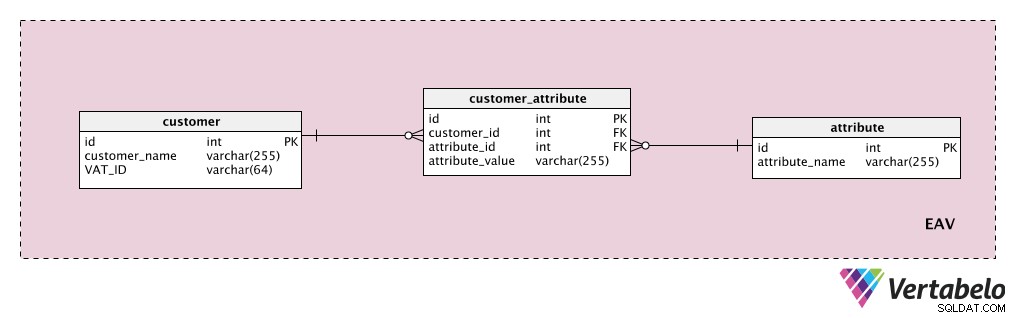
Primeiro, adicionaremos um dicionário com uma lista de todas as propriedades possíveis que poderíamos atribuir a um cliente. Este é o “attribute " tabela. Ele pode conter propriedades como "valor do cliente", "detalhes de contato", "informações adicionais" etc. O "customer_attribute ” contém uma lista de todos os atributos, com valores, para cada cliente. Para cada cliente, teremos apenas registros para os atributos que eles possuem e armazenaremos o "attribute_value ” para esse atributo.
Isso pode parecer ótimo. Isso nos permitiria adicionar novas propriedades facilmente (porque as adicionamos como valores no arquivo “customer_attribute " tabela). Assim, evitaríamos fazer alterações no banco de dados. Quase bom demais para ser verdade.
E é bom demais. Embora o modelo armazene os dados de que precisamos, trabalhar com esses dados é muito mais complicado. E isso inclui quase tudo, desde escrever consultas SELECT simples até obter todos os valores relacionados ao cliente, inserir, atualizar ou excluir valores.
Em suma, devemos evitar a estrutura EAV. Se você precisar usá-lo, use-o apenas quando tiver 100% de certeza de que é realmente necessário.
#7 Usando um GUID/UUID como chave primária
Um GUID (Globally Unique Identifier) é um número de 128 bits gerado de acordo com as regras definidas no RFC 4122. Às vezes, eles também são conhecidos como UUIDs (Universal Unique Identifiers). A principal vantagem de um GUID é que ele é único; a chance de você acertar o mesmo GUID duas vezes é realmente improvável. Portanto, os GUIDs parecem um ótimo candidato para a coluna de chave primária. Mas esse não é o caso.
Uma regra geral para chaves primárias é que usamos uma coluna inteira com a propriedade autoincrement definida como “yes”. Isso adicionará dados em ordem sequencial à chave primária e fornecerá desempenho ideal. Sem uma chave sequencial ou um carimbo de data/hora, não há como saber quais dados foram inseridos primeiro. Esse problema também surge quando usamos valores ÚNICOS do mundo real (por exemplo, um ID de IVA). Embora mantenham valores UNIQUE, não são boas chaves primárias. Use-os como chaves alternativas.
Uma observação adicional: Prefiro usar atributos inteiros gerados automaticamente de coluna única como chave primária. É definitivamente a melhor prática. Eu recomendo que você evite usar chaves primárias compostas.
#8 Indexação insuficiente
Os índices são uma parte muito importante do trabalho com bancos de dados, mas uma discussão completa deles está fora do escopo deste artigo. Felizmente, já temos alguns artigos relacionados a índices que você pode conferir para saber mais:- O que é um índice de banco de dados?
- Tudo sobre índices:o básico
- Tudo sobre índices, parte 2:estrutura e desempenho do índice MySQL
A versão curta é que eu recomendo que você adicione um índice onde você espera que seja necessário. Você também pode adicioná-los depois que o banco de dados estiver em produção, se perceber que a adição de índice em um determinado local melhorará o desempenho.
Dados redundantes nº 9
Dados redundantes geralmente devem ser evitados em qualquer modelo. Ele não apenas ocupa espaço em disco adicional, mas também aumenta muito as chances de problemas de integridade de dados. Se algo tiver que ser redundante, devemos cuidar para que os dados originais e a “cópia” estejam sempre em estados consistentes. Na verdade, existem algumas situações em que dados redundantes são desejáveis:
- Em alguns casos, temos que atribuir prioridade a uma determinada ação — e para que isso aconteça, temos que realizar cálculos complexos. Esses cálculos podem usar muitas tabelas e consumir muitos recursos. Nesses casos, seria sensato realizar esses cálculos fora do horário comercial (evitando assim problemas de desempenho durante o horário de trabalho). Se fizermos desta forma, poderíamos armazenar esse valor calculado e usá-lo mais tarde sem ter que recalcular. Claro, o valor é redundante; no entanto, o que ganhamos em desempenho é significativamente maior do que perdemos (algum espaço no disco rígido).
- Também podemos armazenar um pequeno conjunto de dados de relatórios dentro do banco de dados. Por exemplo, no final do dia, armazenaremos o número de chamadas que fizemos naquele dia, o número de vendas bem-sucedidas etc. Os dados de relatórios só devem ser armazenados dessa maneira se precisarmos usá-los com frequência. Mais uma vez, perderemos um pouco de espaço no disco rígido, mas evitaremos recalcular dados ou conectar-se ao banco de dados de relatórios (se houver).
Na maioria dos casos, não devemos usar dados redundantes porque:
- Armazenar os mesmos dados mais de uma vez no banco de dados pode afetar a integridade dos dados. Se você armazenar o nome de um cliente em dois locais diferentes, deverá fazer as alterações (inserir/atualizar/excluir) nos dois locais ao mesmo tempo. Isso também complica o código necessário, mesmo para as operações mais simples.
- Embora possamos armazenar alguns números agregados em nosso banco de dados operacional, devemos fazer isso somente quando realmente for necessário. Um banco de dados operacional não se destina a armazenar dados de relatórios e misturar esses dois geralmente é uma prática ruim. Qualquer pessoa que produza relatórios terá que usar os mesmos recursos que os usuários que trabalham em tarefas operacionais; consultas de relatórios são geralmente mais complexas e podem afetar o desempenho. Portanto, você deve separar seu banco de dados operacional e seu banco de dados de relatórios.
Agora é sua vez de pesar
Espero que a leitura deste artigo tenha lhe dado alguns novos insights e o encoraje a seguir as melhores práticas de modelagem de dados. Eles vão lhe poupar algum tempo!
Você já passou por algum dos problemas mencionados neste artigo? Você acha que perdemos algo importante? Ou você acha que devemos remover algo da nossa lista? Por favor, conte-nos nos comentários abaixo.



