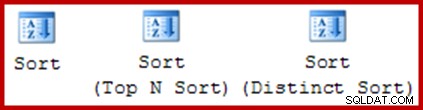
No que diz respeito aos planos de execução gráfica, há apenas um ícone para uma classificação física no SQL Server:

Este mesmo ícone é usado para os três operadores de classificação lógica:Classificação, Classificação N Top e Classificação Distinta:
Indo um nível mais profundo, existem quatro implementações diferentes de Sort no mecanismo de execução (sem contar a classificação em lote para junções de loop otimizadas, que não é uma classificação completa e, de qualquer maneira, não é visível nos planos). Se você estiver usando o SQL Server 2014, o número de implementações de classificação do mecanismo de execução aumentará para sete:
- CQScanSortNovo
- CQScanTopSortNovo
- CQScanIndexSortNovo
- CQScanPartitionSortNew (somente SQL Server 2014)
- CQScanInMemSortNovo
- Procedimento compilado nativamente de OLTP na memória (Hekaton) Top N Sort (somente SQL Server 2014)
- Procedimento compilado nativamente de OLTP na memória (Hekaton) Classificação geral (somente SQL Server 2014)
Este artigo analisa essas implementações de classificação e quando cada uma é usada no SQL Server. A primeira parte abrange os primeiros quatro itens da lista.
1. CQScanSortNovo
Esta é a classe de classificação mais geral, usada quando nenhuma das outras opções disponíveis é aplicável. A classificação geral usa uma concessão de memória do espaço de trabalho reservada logo antes do início da execução da consulta. Essa concessão é proporcional às estimativas de cardinalidade e às expectativas de tamanho médio da linha e não pode ser aumentada após o início da execução da consulta.
A implementação atual parece usar uma variedade de classificação de mesclagem interna (talvez classificação de mesclagem binária), fazendo a transição para classificação de mesclagem externa (com várias passagens, se necessário) se a memória reservada for insuficiente. A classificação de mesclagem externa usa tempdb físico espaço para execuções de classificação que não cabem na memória (comumente conhecido como derramamento de classificação). A classificação geral também pode ser configurada para aplicar distinção durante a operação de classificação.
O rastreamento de pilha parcial a seguir mostra um exemplo do CQScanSortNew class classificando strings usando uma classificação de mesclagem interna:
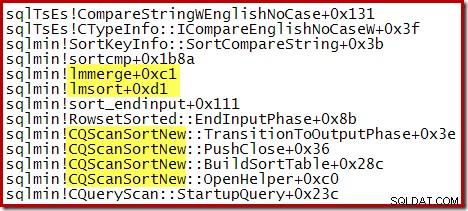
Nos planos de execução, Sort fornece informações sobre a fração da concessão de memória geral do espaço de trabalho de consulta que está disponível para Sort ao ler registros (a fase de entrada) e a fração disponível quando a saída classificada está sendo consumida pelos operadores do plano pai (a fase de saída ).
A fração de concessão de memória é um número entre 0 e 1 (onde 1 =100% da memória concedida) e é visível no SSMS destacando a classificação e procurando na janela Propriedades. O exemplo abaixo foi retirado de uma consulta com apenas um único operador Sort, portanto, ele tem a concessão de memória completa do espaço de trabalho de consulta disponível durante as fases de entrada e saída:
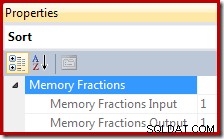
As frações de memória refletem o fato de que, durante sua fase de entrada, Sort precisa compartilhar a concessão de memória de consulta geral com operadores que consomem memória em execução concorrente abaixo dela no plano de execução. Da mesma forma, durante a fase de saída, Sort precisa compartilhar a memória concedida com operadores que consomem memória em execução simultânea acima dela no plano de execução.
O processador de consulta é inteligente o suficiente para saber que alguns operadores estão bloqueando (stop-and-go), marcando efetivamente os limites onde a concessão de memória pode ser reciclada e reutilizada. Em planos paralelos, a fração de concessão de memória disponível para uma classificação geral é dividida igualmente entre os encadeamentos e não pode ser reequilibrada em tempo de execução em caso de distorção (uma causa comum de derramamento em planos de classificação paralela).
O SQL Server 2012 e posterior inclui informações adicionais sobre a concessão mínima de memória do espaço de trabalho necessária para inicializar os operadores do plano que consomem memória e o desejado concessão de memória (a quantidade "ideal" de memória estimada necessária para concluir toda a operação na memória). Em um plano de execução pós-execução ("real"), também há novas informações sobre quaisquer atrasos na aquisição da concessão de memória, a quantidade máxima de memória realmente usada e como a reserva de memória foi distribuída entre os nós NUMA.
Todos os exemplos do AdventureWorks a seguir usam um CQScanSortNew classificação geral:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
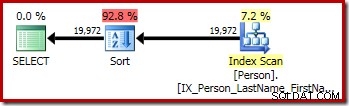
P.LastName; A primeira consulta (uma classificação não distinta) produz o seguinte plano de execução:
A segunda e terceira consultas (equivalentes) produzem este plano:
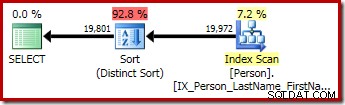
CQScanSortNovo pode ser usado tanto para classificação geral lógica quanto para classificação distinta lógica.
2. CQScanTopSortNovo
CQScanTopSortNovo é uma subclasse de CQScanSortNew usado para implementar um Top N Sort (como o nome sugere). CQScanTopSortNovo delega grande parte do trabalho principal para CQScanSortNew , mas modifica o comportamento detalhado de diferentes maneiras, dependendo do valor de N.
Para N> 100, CQScanTopSortNew é essencialmente apenas um CQScanSortNew normal sort que para automaticamente de produzir linhas classificadas após N linhas. Para N <=100, CQScanTopSortNew retém apenas os N principais resultados atuais durante a operação de classificação e acompanha o valor de chave mais baixo que se qualifica atualmente.
Por exemplo, durante uma classificação N Top otimizada (onde N <=100), a pilha de chamadas apresenta RowsetTopN enquanto que com a classificação geral na seção 1 vimos RowsetSorted :
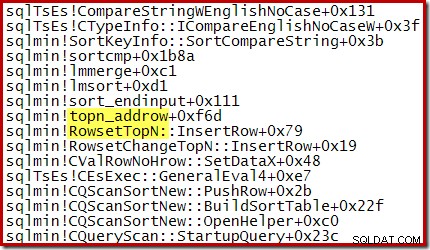
Para um Top N Sort onde N> 100, a pilha de chamadas no mesmo estágio de execução é a mesma que a classificação geral vista anteriormente:
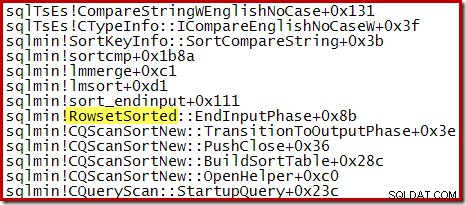
Observe que o CQScanTopSortNew nome de classe não aparece em nenhum desses rastreamentos de pilha. Isso se deve simplesmente ao modo como as subclasses funcionam. Em outros pontos durante a execução dessas consultas, CQScanTopSortNew métodos (por exemplo, Open, GetRow e CreateTopNTable) aparecem explicitamente na pilha de chamadas. Como exemplo, o seguinte foi obtido posteriormente na execução da consulta e mostra o CQScanTopSortNew nome da classe:
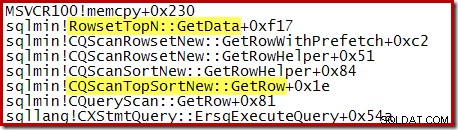
Classificação N principais e o Otimizador de consulta
O otimizador de consulta não sabe nada sobre Top N Sort, que é apenas um operador de mecanismo de execução. Quando o otimizador produz uma árvore de saída com um operador físico Top imediatamente acima de uma classificação física (não distinta), uma reescrita de pós-otimização pode reduzir as duas operações físicas em um único operador Top N Sort. Mesmo no caso N> 100, isso representa uma economia na passagem de linhas iterativamente entre uma saída Sort e uma entrada Top.
A consulta a seguir usa alguns sinalizadores de rastreamento não documentados para mostrar a saída do otimizador e a reescrita pós-otimização em ação:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352); A árvore de saída do otimizador mostra os operadores físicos Top e Sort separados:
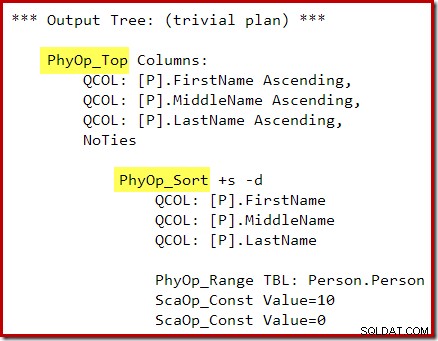
Após a reescrita da pós-otimização, o Top e o Sort foram recolhidos em um único Top N Sort:
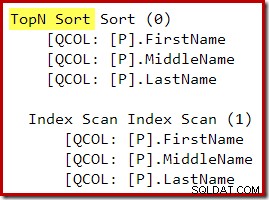
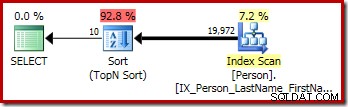
O plano de execução gráfica para a consulta T-SQL acima mostra o único operador Top N Sort:
Quebrando a regravação do Top N Sort
A reescrita de pós-otimização do Top N Sort só pode recolher um Top adjacente e um Sort não distinto em um Top N Sort. Adicionar DISTINCT (ou a cláusula GROUP BY equivalente) à consulta acima impedirá a regravação do Top N Sort:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; O plano de execução final para esta consulta apresenta os operadores Top e Sort (Distinct Sort) separados:
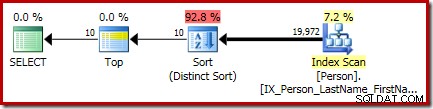
O Sort lá é o geral CQScanSortNew classe executando em modo distinto como visto na seção 1 anterior.
Uma segunda maneira de evitar a reescrita em um Top N Sort é introduzir um ou mais operadores adicionais entre o Top e o Sort. Por exemplo:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; A saída do otimizador de consulta agora tem uma operação entre o Top e o Sort, portanto, um Top N Sort não é gerado durante a fase de reescrita pós-otimização:
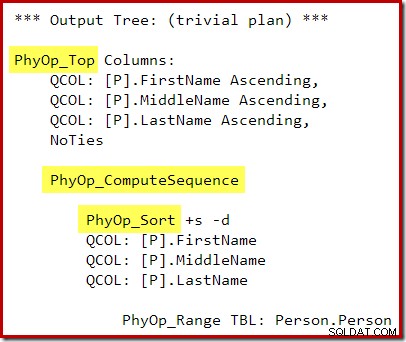
O plano de execução é:

A sequência de computação (implementada como dois segmentos e um projeto de sequência) entre Top e Sort evita o colapso de Top e Sort em um único operador Top N Sort. Os resultados corretos ainda serão obtidos com este plano, é claro, mas a execução pode ser um pouco menos eficiente do que poderia ter sido com o operador Top N Sort combinado.
3. CQScanIndexSortNovo
CQScanIndexSortNovo é usado apenas para classificação em planos de construção de índice DDL. Ele reutiliza alguns dos recursos gerais de classificação que já vimos, mas adiciona otimizações específicas para inserções de índice. É também a única classe de classificação que pode solicitar dinamicamente mais memória após o início da execução.
A estimativa de cardinalidade geralmente é precisa para um plano de construção de índice porque o número total de linhas na tabela geralmente é uma quantidade conhecida. Isso não quer dizer que as concessões de memória para classificações de plano de construção de índice sempre serão precisas; apenas torna um pouco menos fácil de demonstração. Portanto, o exemplo a seguir usa uma extensão não documentada, mas razoavelmente conhecida, para o comando UPDATE STATISTICS para enganar o otimizador fazendo-o pensar que a tabela na qual estamos construindo um índice tem apenas uma linha:
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; O plano de execução pós-execução ("real") para a compilação do índice não mostra um aviso para uma classificação derramada (quando executado no SQL Server 2012 ou posterior), apesar da estimativa de 1 linha e das 19.972 linhas realmente classificadas:
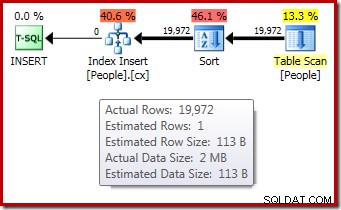
A confirmação de que a concessão de memória inicial foi expandida dinamicamente vem da observação das propriedades do iterador raiz. A consulta recebeu inicialmente 1.024 KB de memória, mas acabou consumindo 1.576 KB:
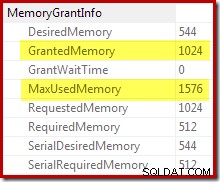
O aumento dinâmico na memória concedida também pode ser rastreado usando o evento estendido do canal de depuração sort_memory_grant_adjustment. Este evento é gerado cada vez que a alocação de memória é aumentada dinamicamente. Se este evento estiver sendo monitorado, podemos capturar um rastreamento de pilha quando ele for publicado, seja por meio de eventos estendidos (com alguma configuração estranha e um sinalizador de rastreamento) ou de um depurador anexado, conforme abaixo:
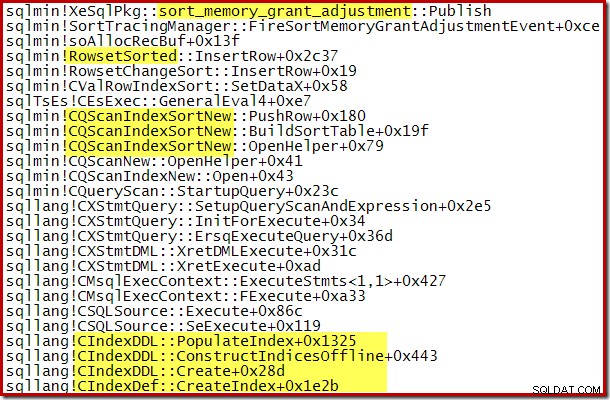
A expansão de concessão de memória dinâmica também pode ajudar com planos de criação de índice paralelos em que a distribuição de linhas entre os encadeamentos é desigual. A quantidade de memória que pode ser consumida dessa maneira não é ilimitada, no entanto. O SQL Server verifica cada vez que uma expansão é necessária para ver se a solicitação é razoável, considerando os recursos disponíveis naquele momento.
Algumas informações sobre esse processo podem ser obtidas habilitando o sinalizador de rastreamento não documentado 1504, junto com 3604 (para saída de mensagem para o console) ou 3605 (saída para o log de erros do SQL Server). Se o plano de compilação do índice for paralelo, somente 3605 será eficaz porque os trabalhadores paralelos não podem enviar mensagens de rastreamento entre threads para o console.
A seção a seguir da saída de rastreamento foi capturada durante a criação de um índice moderadamente grande em uma instância do SQL Server 2014 com memória limitada:
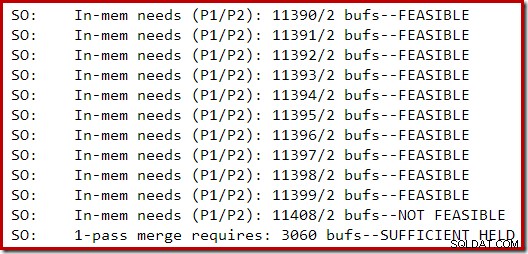
A expansão de memória para a classificação prosseguiu até que a solicitação fosse considerada inviável, momento em que foi determinado que já havia memória suficiente para que um derramamento de classificação de passagem única fosse concluído.
4. CQScanPartitionSortNovo
Esse nome de classe pode sugerir que esse tipo de classificação é usado para dados de tabela particionada ou ao criar índices em tabelas particionadas, mas nenhum desses é realmente o caso. A classificação de dados particionados usa CQScanSortNew ou CQScanTopSortNew como normal; classificar linhas para inserção em um índice particionado geralmente usa CQScanIndexSortNew como visto na seção 3.
O CQScanPartitionSortNew A classe de classificação está presente apenas no SQL Server 2014. Ela é usada apenas ao classificar linhas por id de partição, antes da inserção em um índice columnstore clusterizado particionado . Observe que ele é usado apenas para particionado armazenamento de colunas em cluster; planos de inserção columnstore clusterizados regulares (não particionados) não se beneficiam de uma classificação.
As inserções em um índice columnstore clusterizado particionado nem sempre apresentarão uma classificação. É uma decisão baseada em custo que depende do número estimado de linhas a serem inseridas. Se o otimizador estimar que vale a pena classificar as inserções por partição para otimizar a E/S, o operador de inserção columnstore terá o DMLRequestSort propriedade definida como true e um CQScanPartitionSortNew sort pode aparecer no plano de execução.
A demonstração nesta seção usa uma tabela permanente de números sequenciais. Se você não tiver um desses, o script a seguir pode ser usado para criar um:
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); A demonstração em si envolve a criação de uma tabela indexada columnstore clusterizada particionada e a inserção de linhas suficientes (da tabela Numbers acima) para convencer o otimizador a usar uma classificação de partição pré-inserção:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; O plano de execução para a inserção mostra a classificação usada para garantir que as linhas cheguem ao iterador de inserção de armazenamento de colunas clusterizado na ordem do ID da partição:

Uma pilha de chamadas capturada enquanto o CQScanPartitionSortNew ordenação estava em andamento é mostrado abaixo:
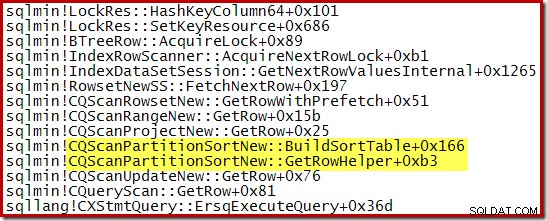
Há algo mais interessante sobre essa classe de classificação. As ordenações normalmente consomem toda a sua entrada em sua chamada de método Open. Após a classificação, eles retornam o controle ao operador pai. Mais tarde, a classificação começa a produzir linhas de saída classificadas uma de cada vez da maneira usual por meio de chamadas GetRow. CQScanPartitionSortNovo é diferente, como você pode ver na pilha de chamadas acima:Ele não consome sua entrada durante seu método Open – ele espera até que GetRow seja chamado por seu pai pela primeira vez.
Nem toda classificação no ID da partição que aparece em um plano de execução inserindo linhas em um índice columnstore clusterizado particionado será um CQScanPartitionSortNew ordenar. Se a classificação aparecer imediatamente à direita do operador de inserção de índice columnstore, as chances são muito boas de que seja um CQScanPartitionSortNew ordenar.
Por fim, CQScanPartitionSortNew é uma das duas únicas classes de classificação que define a propriedade Soft Sort exposta quando as propriedades do plano de execução do operador Sort são geradas com o sinalizador de rastreamento não documentado 8666 ativado:
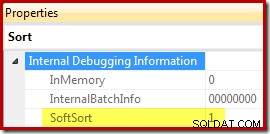
O significado de "soft sort" neste contexto não é claro. Ele é rastreado como uma propriedade na estrutura do otimizador de consulta e parece estar relacionado a inserções de dados particionadas otimizadas, mas determinar exatamente o que isso significa requer mais pesquisas. Enquanto isso, essa propriedade pode ser usada para inferir que um Sort foi implementado com CQScanPartitionSortNew sem anexar um depurador. O significado do sinalizador de propriedade InMemory mostrado acima será abordado na parte 2. Ele não indicar se uma classificação regular foi executada na memória ou não.
Resumo da Parte Um
- CQScanSortNovo é a classe de classificação geral usada quando nenhuma outra opção é aplicável. Parece que usa uma variedade de classificação de mesclagem interna na memória, fazendo a transição para classificação de mesclagem externa usando tempdb se o espaço de trabalho de memória concedido for insuficiente. Essa classe pode ser usada para classificação geral e classificação distinta.
- CQScanTopSortNovo implementa Top N Sort. Onde N <=100, uma classificação de mesclagem interna na memória é executada e nunca é derramada para tempdb . Apenas os n principais itens atuais são retidos na memória durante a classificação. Para N> 100 CQScanTopSortNovo é equivalente a um CQScanSortNew sort que para automaticamente após a saída de N linhas. Uma classificação N> 100 pode se espalhar para tempdb se necessário.
- O Top N Sort visto nos planos de execução é uma reescrita de otimização pós-consulta. Se o otimizador de consulta produzir uma árvore de saída com uma classificação superior adjacente e uma classificação não distinta, essa reescrita poderá recolher os dois operadores físicos em um único operador de classificação N superior.
- CQScanIndexSortNovo é usado apenas em planos DDL de construção de índice. É a única classe de classificação padrão que pode adquirir dinamicamente mais memória durante a execução. As classificações de construção de índice ainda podem se espalhar para o disco em algumas circunstâncias, inclusive quando o SQL Server decide que um aumento de memória solicitado não é compatível com a carga de trabalho atual.
- CQScanPartitionSortNovo está presente apenas no SQL Server 2014 e é usado apenas para otimizar inserções em um índice columnstore clusterizado particionado. Ele oferece uma "classificação suave".
A segunda parte deste artigo examinará CQScanInMemSortNew , e as duas classificações de procedimento armazenado compilado nativamente OLTP na memória.