De tempos em tempos, você pode notar que uma ou mais junções em um plano de execução são anotadas com um
StarJoinInfo estrutura. O esquema oficial do showplan tem o seguinte a dizer sobre este elemento do plano (clique para ampliar):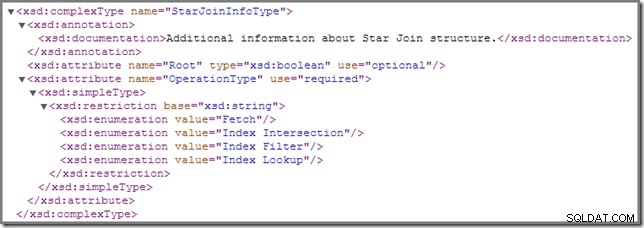
A documentação em linha mostrada lá ("informações adicionais sobre a estrutura Star Join ") não é tão esclarecedor, embora os outros detalhes sejam bastante intrigantes - vamos analisá-los em detalhes.
Se você consultar seu mecanismo de pesquisa favorito para obter mais informações usando termos como “otimização de junção em estrela do SQL Server”, provavelmente verá resultados descrevendo filtros de bitmap otimizados. Este é um recurso separado somente para empresas introduzido no SQL Server 2008 e não relacionado ao
StarJoinInfo estrutura em tudo. Otimizações para consultas seletivas de estrelas
A presença de
StarJoinInfo indica que o SQL Server aplicou uma de um conjunto de otimizações direcionadas a consultas seletivas de esquema em estrela. Essas otimizações estão disponíveis no SQL Server 2005, em todas as edições (não apenas Enterprise). Observe que seletivo aqui se refere ao número de linhas buscadas na tabela de fatos. A combinação de predicados dimensionais em uma consulta ainda pode ser seletiva mesmo quando seus predicados individuais qualificam um grande número de linhas. Interseção de índice comum
O otimizador de consulta pode considerar a combinação de vários índices não clusterizados onde não existe um único índice adequado, como demonstra a seguinte consulta do AdventureWorks:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
O otimizador determina que a combinação de dois índices não clusterizados (um em
SalesPersonID e o outro em CustomerID ) é a maneira mais barata de satisfazer essa consulta (não há índice em ambas as colunas):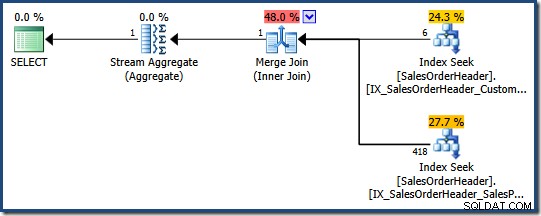
Cada busca de índice retorna a chave de índice clusterizado para linhas que passam o predicado. A junção corresponde às chaves retornadas para garantir que apenas as linhas que correspondam a ambos predicados são transmitidos.
Se a tabela fosse um heap, cada busca retornaria identificadores de linha de heap (RIDs) em vez de chaves de índice clusterizado, mas a estratégia geral é a mesma:encontre identificadores de linha para cada predicado e, em seguida, corresponda-os.
Interseção manual do índice de junção em estrela
A mesma ideia pode ser estendida para consultas que selecionam linhas de uma tabela de fatos usando predicados aplicados a tabelas de dimensão. Para ver como isso funciona, considere a seguinte consulta (usando o banco de dados de amostra Contoso BI) para encontrar o valor total de vendas de MP3 players vendidos em lojas da Contoso com exatamente 50 funcionários:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Para comparação com esforços posteriores, esta consulta (muito seletiva) produz um plano de consulta como o seguinte (clique para expandir):
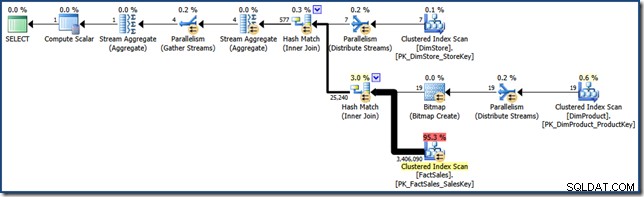
Esse plano de execução tem um custo estimado de pouco mais de 15,6 unidades . Ele apresenta execução paralela com uma varredura completa da tabela de fatos (embora com um filtro de bitmap aplicado).
As tabelas de fatos neste banco de dados de exemplo não incluem índices não clusterizados nas chaves estrangeiras da tabela de fatos por padrão, portanto, precisamos adicionar alguns:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Com esses índices em vigor, podemos começar a ver como a interseção de índices pode ser usada para melhorar a eficiência. A primeira etapa é encontrar identificadores de linha da tabela de fatos para cada predicado separado. As consultas a seguir aplicam um predicado de dimensão única e, em seguida, unem-se novamente à tabela de fatos para localizar identificadores de linha (chaves de índice clusterizado da tabela de fatos):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Os planos de consulta mostram uma varredura da tabela de dimensão pequena, seguida de pesquisas usando o índice não clusterizado da tabela de fatos para localizar identificadores de linha (lembre-se de que os índices não clusterizados sempre incluem a chave de clustering da tabela base ou o RID de heap):
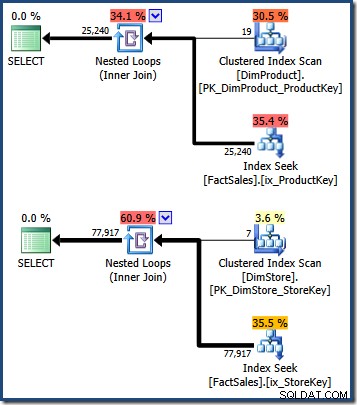
A interseção desses dois conjuntos de chaves de índice clusterizado da tabela de fatos identifica as linhas que devem ser retornadas pela consulta original. Assim que tivermos esses identificadores de linha, precisamos apenas procurar o Valor de vendas em cada linha da tabela de fatos e calcular a soma.
Consulta de interseção de índice manual
Juntar tudo isso em uma consulta fornece o seguinte:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1); O
FORCESEEK A dica está lá para garantir que obtenhamos pesquisas de pontos para a tabela de fatos. Sem isso, o otimizador opta por varrer a tabela de fatos, que é exatamente o que queremos evitar. O MAXDOP 1 dica apenas ajuda a manter o plano final em um tamanho bastante razoável para fins de exibição (clique para vê-lo em tamanho real):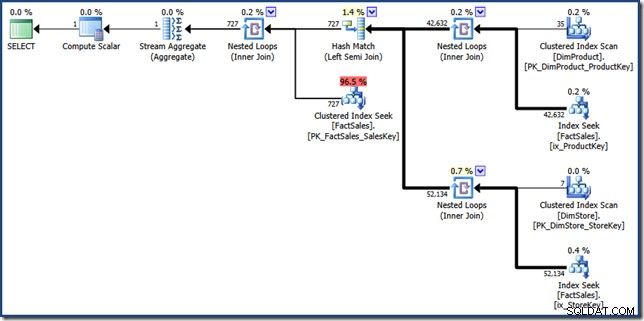
As partes componentes do plano de interseção de índice manual são bastante fáceis de identificar. As duas pesquisas de índice não clusterizado da tabela de fatos no lado direito produzem os dois conjuntos de identificadores de linha da tabela de fatos. A junção de hash encontra a interseção desses dois conjuntos. A busca de índice clusterizado na tabela de fatos localiza os Valores de Vendas para esses identificadores de linha. Por fim, o Stream Aggregate calcula o valor total.
Esse plano de consulta executa relativamente poucas pesquisas nos índices não clusterizados e clusterizados da tabela de fatos. Se a consulta for seletiva o suficiente, essa pode ser uma estratégia de execução mais barata do que a varredura completa da tabela de fatos. O banco de dados de amostra do Contoso BI é relativamente pequeno, com apenas 3,4 milhões de linhas na tabela de fatos de vendas. Para tabelas de fatos maiores, a diferença entre uma varredura completa e algumas centenas de pesquisas pode ser muito significativa. Infelizmente, a reescrita manual apresenta alguns erros graves de cardinalidade, resultando em um plano com custo estimado de 46,5 unidades .
Interseção automática do índice de junção de estrelas com pesquisas
Felizmente, não precisamos decidir se a consulta que estamos escrevendo é seletiva o suficiente para justificar essa reescrita manual. As otimizações de junção em estrela para consultas seletivas significam que o otimizador de consultas pode explorar essa opção para nós, usando a sintaxe de consulta original mais amigável:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; O otimizador produz o seguinte plano de execução com um custo estimado de 1,64 unidades (clique para ampliar):
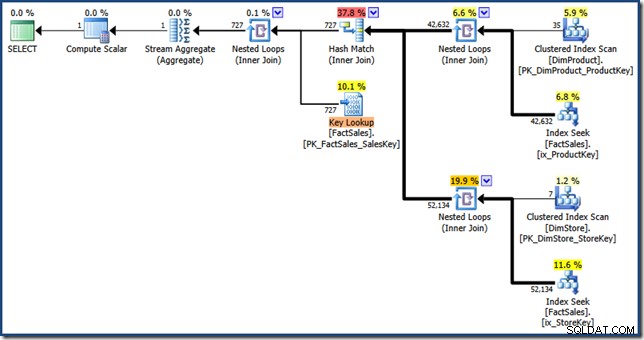
As diferenças entre este plano e a versão manual são:a interseção do índice é uma junção interna em vez de uma semijunção; e a pesquisa de índice clusterizado é mostrada como uma pesquisa de chave em vez de uma busca de índice clusterizado. Correndo o risco de trabalhar o ponto, se a tabela de fatos fosse um heap, o Key Lookup seria um RID Lookup.
As propriedades StarJoinInfo
Todas as associações neste plano têm um
StarJoinInfo estrutura. Para vê-lo, clique em um iterador de junção e procure na janela Propriedades do SSMS. Clique na seta à esquerda do StarJoinInfo elemento para expandir o nó. As junções da tabela de fatos não clusterizada à direita do plano são Pesquisas de Índice criadas pelo otimizador:
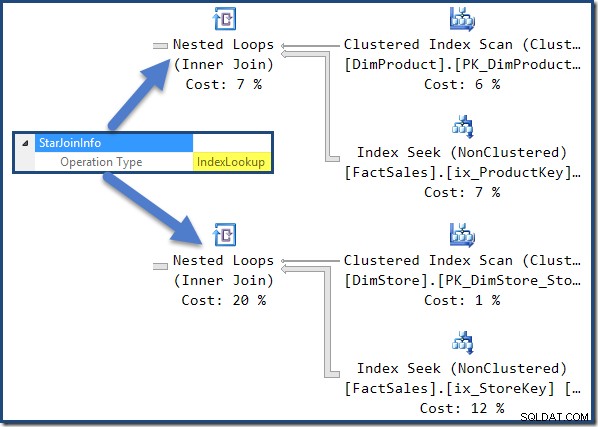
A junção de hash tem um
StarJoinInfo estrutura mostrando que está realizando um Index Intersection (novamente, fabricado pelo otimizador):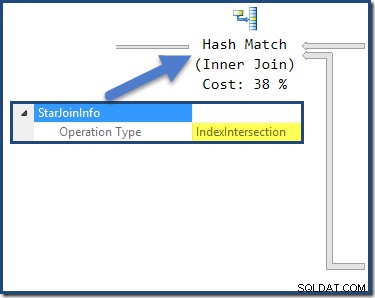
O
StarJoinInfo para a junção de loops aninhados mais à esquerda mostra que ela foi gerada para buscar linhas da tabela de fatos por identificador de linha. Está na raiz da subárvore star join gerada pelo otimizador: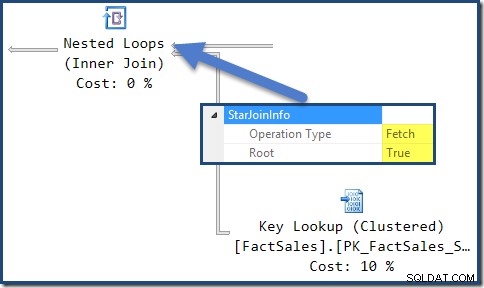
Produtos cartesianos e pesquisa de índice de várias colunas
Os planos de interseção de índice considerados como parte das otimizações de junção em estrela são úteis para consultas seletivas de tabela de fatos onde existem índices não clusterizados de coluna única em chaves estrangeiras de tabela de fatos (uma prática de projeto comum).
Às vezes, também faz sentido criar índices de várias colunas em chaves estrangeiras da tabela de fatos, para combinações consultadas com frequência. As otimizações de consulta em estrela seletivas internas também contêm uma reescrita para esse cenário. Para ver como isso funciona, adicione o seguinte índice de várias colunas à tabela de fatos:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Compile a consulta de teste novamente:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; O plano de consulta não apresenta mais interseção de índice (clique para ampliar):
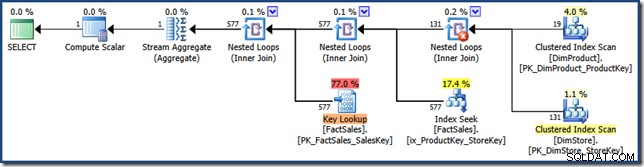
A estratégia escolhida aqui é aplicar cada predicado às tabelas de dimensão, pegar o produto cartesiano dos resultados e usá-lo para buscar as duas chaves do índice multicoluna. O plano de consulta então executa uma pesquisa de chave na tabela de fatos usando identificadores de linha exatamente como visto anteriormente.
O plano de consulta é particularmente interessante porque combina três recursos que são frequentemente considerados como Bad Things (varreduras completas, produtos cartesianos e pesquisas de chave) em uma otimização de desempenho . Esta é uma estratégia válida quando se espera que o produto das duas dimensões seja muito pequeno.
Não há
StarJoinInfo para o produto cartesiano, mas as outras junções possuem informações (clique para ampliar):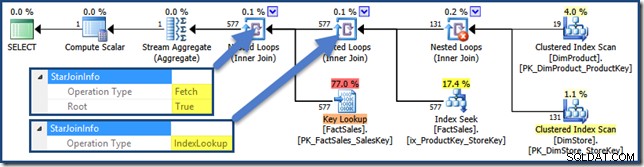
Filtro de índice
Voltando ao esquema showplan, há um outro
StarJoinInfo operação que precisamos cobrir: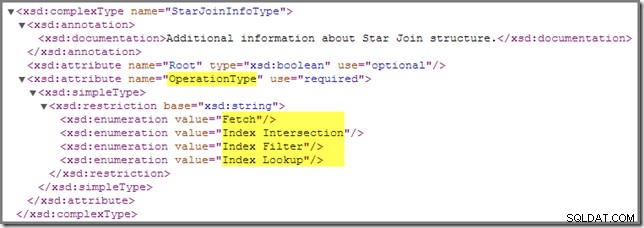
O
Index Filter value é visto com junções consideradas seletivas o suficiente para valer a pena executar antes da busca da tabela de fatos. Junções que não são seletivas o suficiente serão executadas após a busca e não terão um StarJoinInfo estrutura. Para ver um filtro de índice usando nossa consulta de teste, precisamos adicionar uma terceira tabela de junção à mistura, remover os índices da tabela de fatos não clusterizados criados até agora e adicionar uma nova:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; O plano de consulta agora é (clique para ampliar):
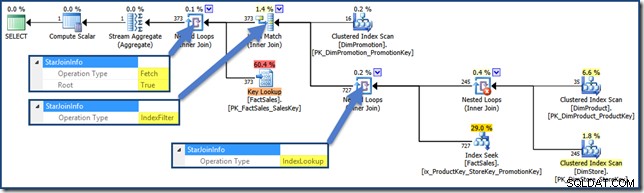
Um plano de consulta de interseção de índice de pilha
Para completar, aqui está um script para criar uma cópia heap da tabela de fatos com os dois índices não clusterizados necessários para habilitar a reescrita do otimizador de interseção de índice:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; O plano de execução para esta consulta tem os mesmos recursos de antes, mas a interseção de índice é realizada usando RIDs em vez de chaves de índice clusterizado de tabela de fatos, e a busca final é uma Pesquisa RID (clique para expandir):
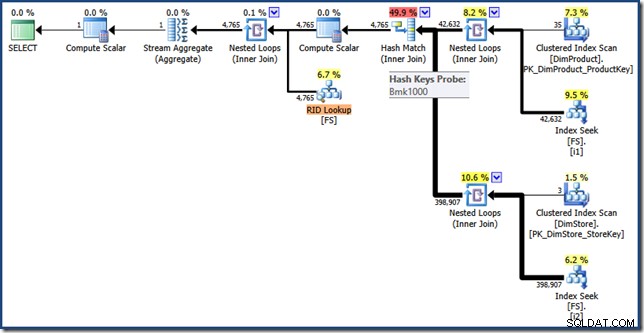
Considerações finais
As reescritas do otimizador mostradas aqui são direcionadas a consultas que retornam um número relativamente pequeno de linhas de um grande tabela de fatos. Essas reescritas estão disponíveis em todas as edições do SQL Server desde 2005.
Embora destinado a acelerar consultas seletivas de esquema em estrela (e floco de neve) em data warehousing, o otimizador pode aplicar essas técnicas sempre que detectar um conjunto adequado de tabelas e junções. A heurística usada para detectar consultas em estrela é bastante ampla, então você pode encontrar formas de plano com
StarJoinInfo estruturas em praticamente qualquer tipo de banco de dados. Qualquer tabela de tamanho razoável (digamos 100 páginas ou mais) com referências a tabelas menores (semelhantes a dimensões) é um candidato potencial para essas otimizações (observe que chaves estrangeiras explícitas não requerido). Para aqueles que gostam dessas coisas, a regra do otimizador responsável por gerar padrões seletivos de junção em estrela a partir de uma junção lógica de n-table é chamada StarJoinToIdxStrategy (star join à estratégia de índice).