Existem vários provedores de nuvem atualmente. Eles podem ser pequenos ou grandes, locais ou com data centers espalhados por todo o mundo. Muitos desses provedores de nuvem oferecem algum tipo de solução de banco de dados relacional gerenciado. Os bancos de dados suportados tendem a ser MySQL ou PostgreSQL ou algum outro tipo de banco de dados relacional.
Ao projetar qualquer tipo de infraestrutura de banco de dados, é importante entender as necessidades do seu negócio e decidir que tipo de disponibilidade você precisa alcançar.
Nesta postagem do blog, analisaremos as opções de alta disponibilidade para soluções baseadas em MySQL de um dos maiores provedores de nuvem - Google Cloud Platform.
Como implantar um ambiente altamente disponível usando a instância SQL do GCP
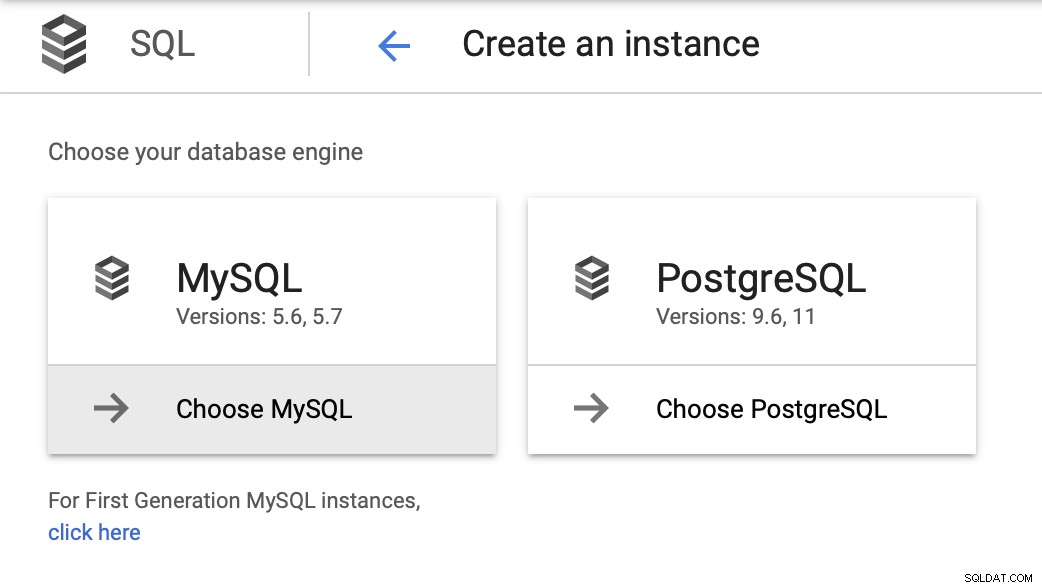
Para este blog queremos um ambiente muito simples - um banco de dados, com talvez uma ou duas réplicas. Queremos poder fazer failover facilmente e restaurar as operações o mais rápido possível se o mestre falhar. Usaremos o MySQL 5.7 como a versão de escolha e começaremos com o assistente de implantação da instância:
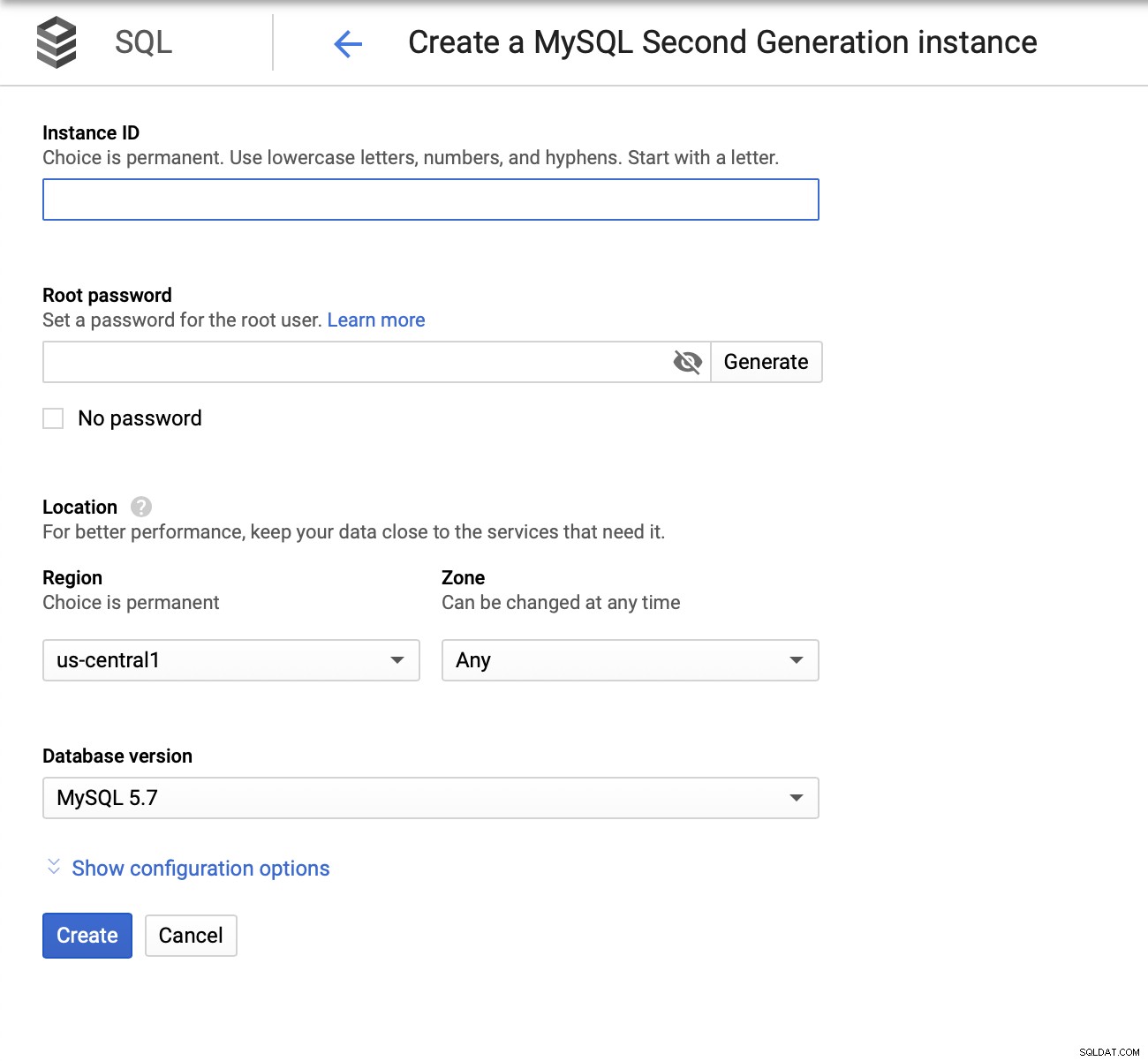
Depois temos que criar a senha root, definir o nome da instância e determinar onde deve ser localizado:
A seguir, examinaremos as opções de configuração:
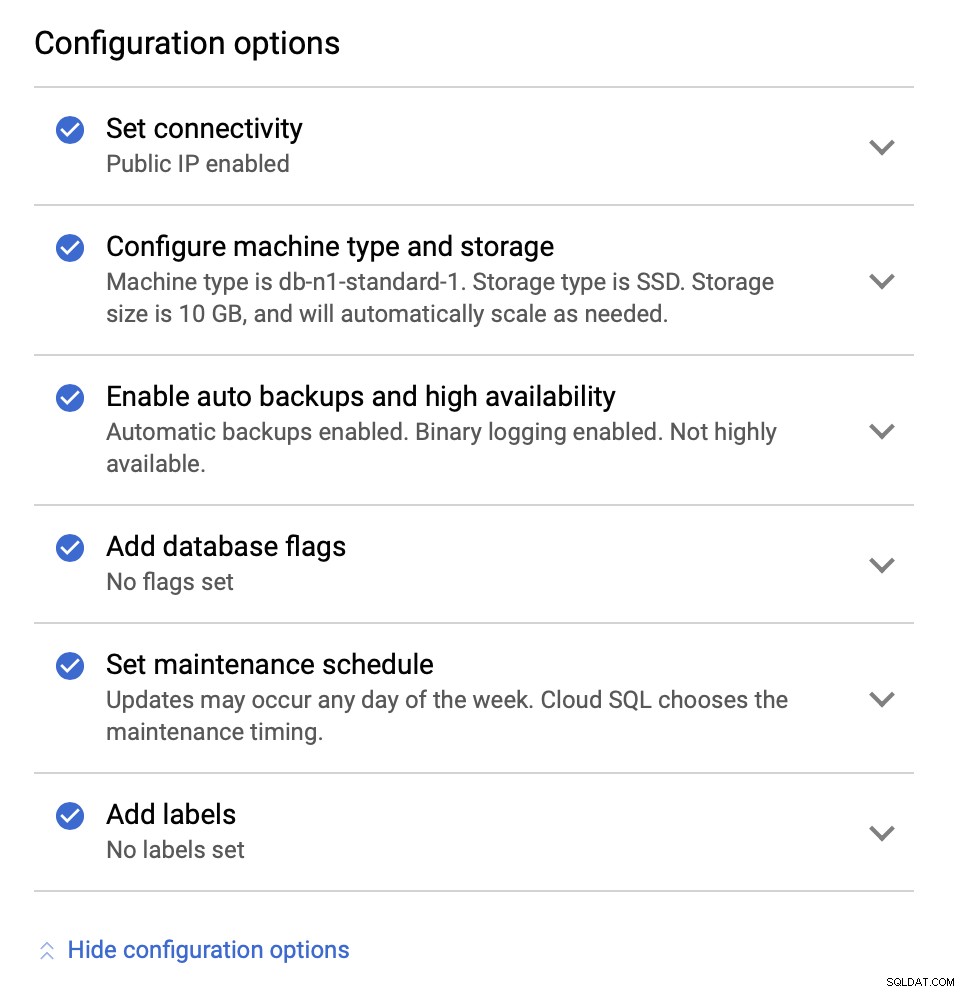
Podemos fazer alterações em termos de tamanho da instância (vamos usar db-n1-standard-4), armazenamento e programação de manutenção. O que é mais importante para nós nesta configuração são as opções de alta disponibilidade:
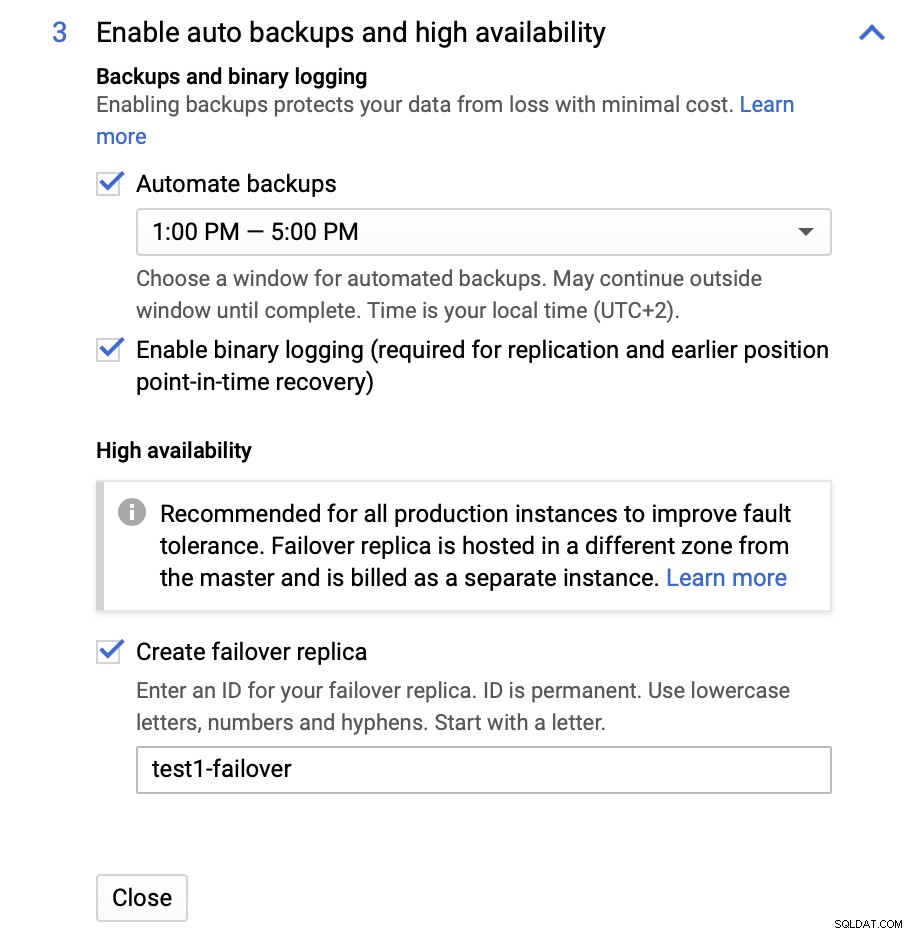
Aqui podemos optar por criar uma réplica de failover. Essa réplica será promovida a mestre caso o mestre original falhe.

Depois de implantarmos a configuração, vamos adicionar um escravo de replicação:
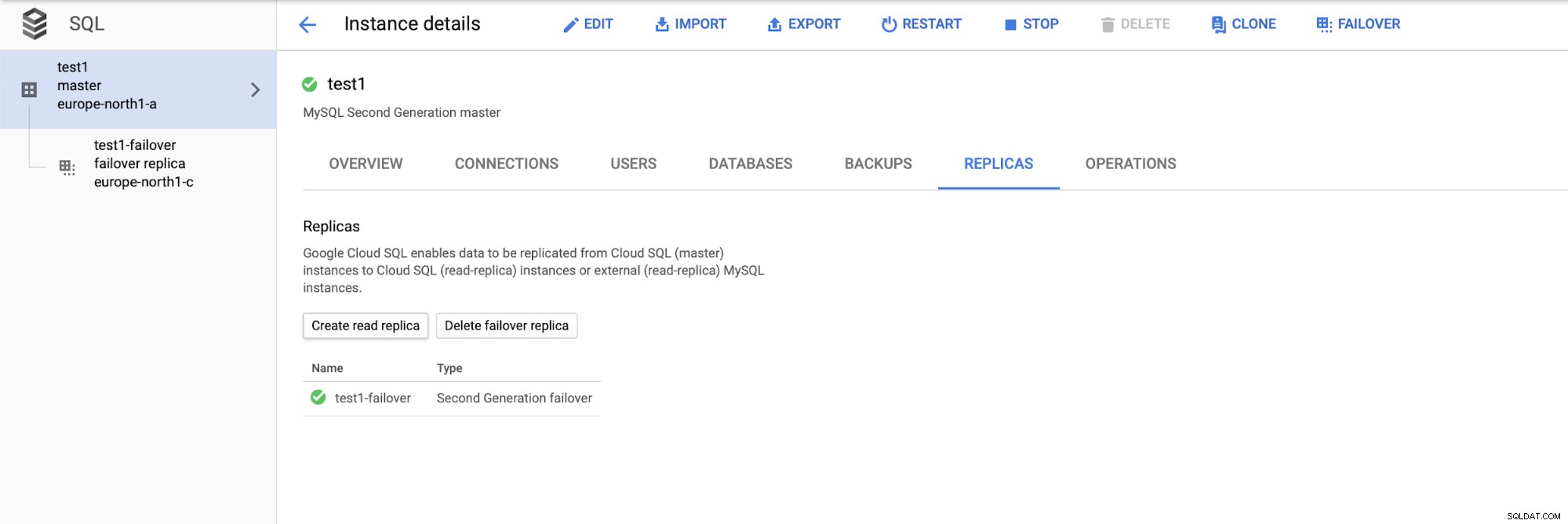
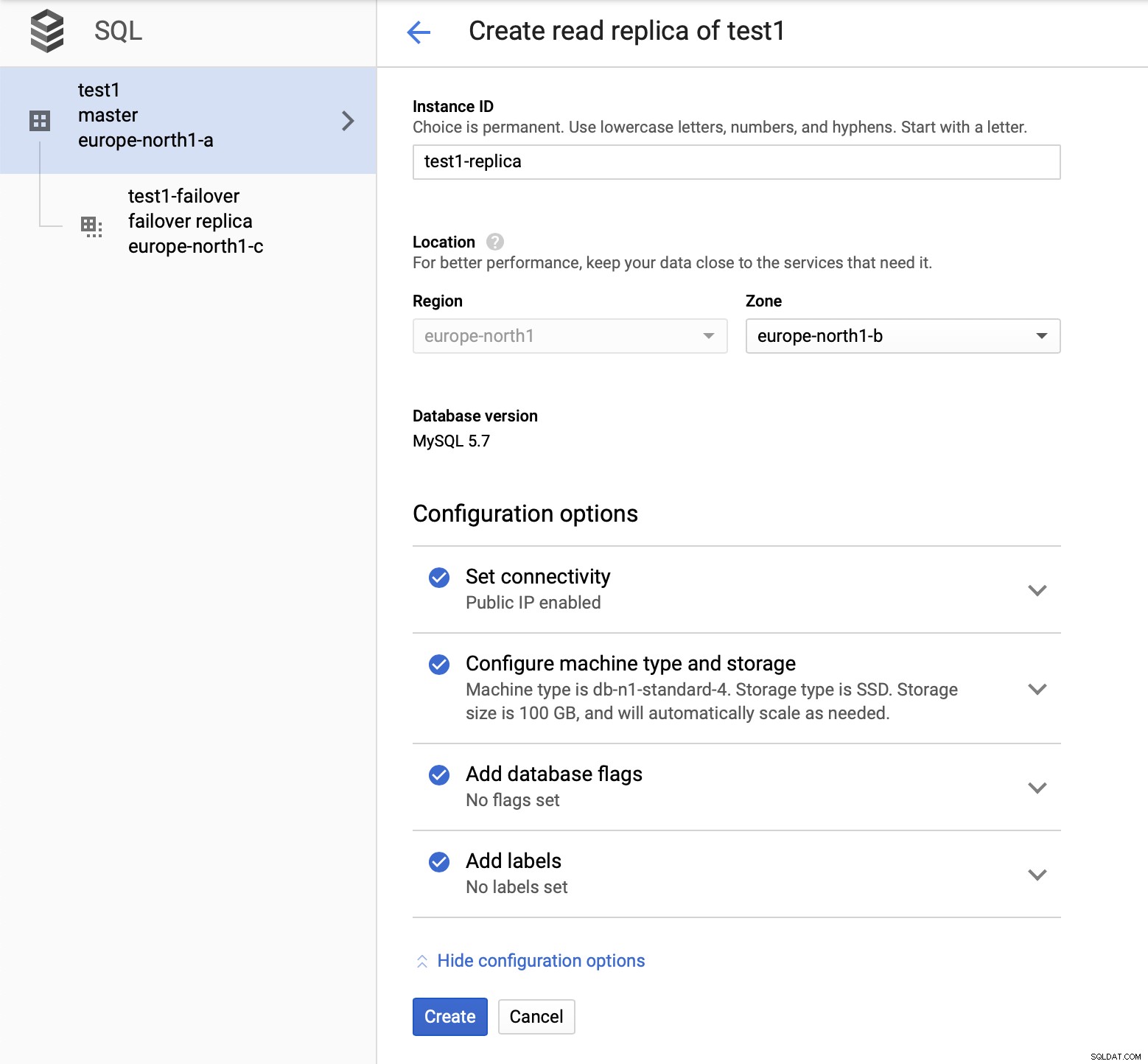
Depois que o processo de adição da réplica estiver concluído, estamos prontos para alguns testes. Vamos executar a carga de trabalho de teste usando o Sysbench em nosso mestre, réplica de failover e réplica de leitura para ver como isso funcionará. Executaremos três instâncias do Sysbench, usando os endpoints para todos os três tipos de nós.
Então, acionaremos o failover manual por meio da interface do usuário:
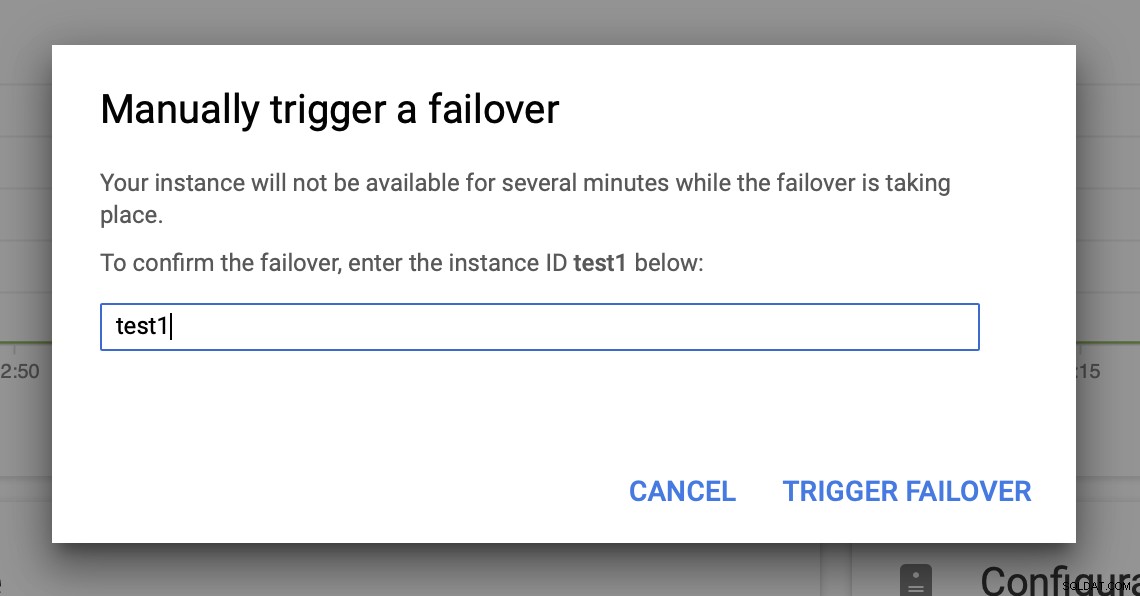
Testando o MySQL Failover no Google Cloud Platform?
Cheguei a este ponto sem nenhum conhecimento detalhado de como funcionam os nós SQL no GCP. Eu tinha algumas expectativas, no entanto, com base na experiência anterior do MySQL e no que vi nos outros provedores de nuvem. Para começar, o failover para o nó de failover deve ser muito rápido. O que gostaríamos é de manter os slaves de replicação disponíveis, sem a necessidade de reconstrução. Também gostaríamos de ver com que rapidez podemos executar o failover uma segunda vez (já que não é incomum que o problema se propague de um banco de dados para outro).
O que determinamos durante nossos testes...
- Durante o failover, o mestre ficou disponível novamente em 75 a 80 segundos.
- A réplica de failover ficou indisponível por 5 a 6 minutos.
- A réplica de leitura estava disponível durante o processo de failover, mas ficou indisponível por 55 a 60 segundos após a disponibilidade da réplica de failover
O que não temos certeza...
O que acontece quando a réplica de failover não está disponível? Com base no tempo, parece que a réplica de failover está sendo reconstruída. Isso faz sentido, mas o tempo de recuperação estaria fortemente relacionado ao tamanho da instância (especialmente ao desempenho de E/S) e ao tamanho do arquivo de dados.
O que está acontecendo com a réplica de leitura depois que a réplica de failover foi reconstruída? Originalmente, a réplica de leitura estava conectada ao mestre. Quando o mestre falhou, esperamos que a réplica de leitura forneça uma visão desatualizada do conjunto de dados. Depois que o novo mestre aparecer, ele deverá se reconectar por meio de replicação à instância (que costumava ser uma réplica de failover e que foi promovida a mestre). Não há necessidade de um minuto de inatividade quando CHANGE MASTER está sendo executado.
Mais importante, durante o processo de failover não há como executar outro failover (o que faz sentido):
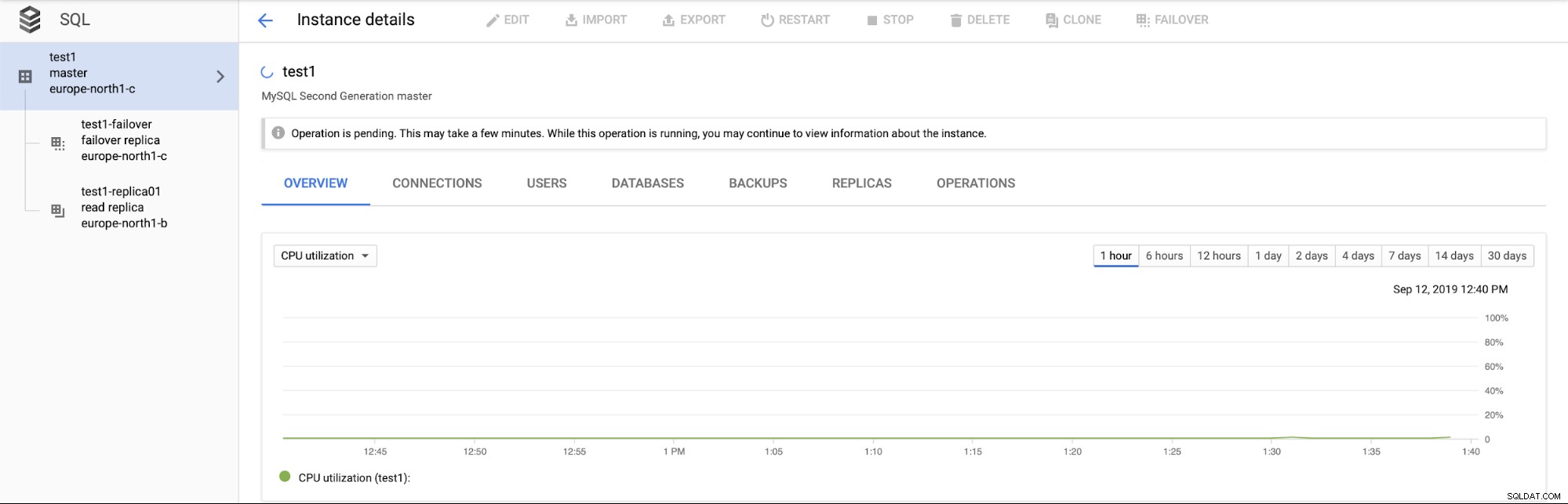
Também não é possível promover uma réplica de leitura (o que não necessariamente faz sentido - esperamos poder promover réplicas de leitura a qualquer momento).

É importante observar, contar com as réplicas de leitura para fornecer alta disponibilidade (sem criar uma réplica de failover) não é uma solução viável. Você pode promover uma réplica de leitura para se tornar mestre, mas um novo cluster seria criado; separado do resto dos nós.
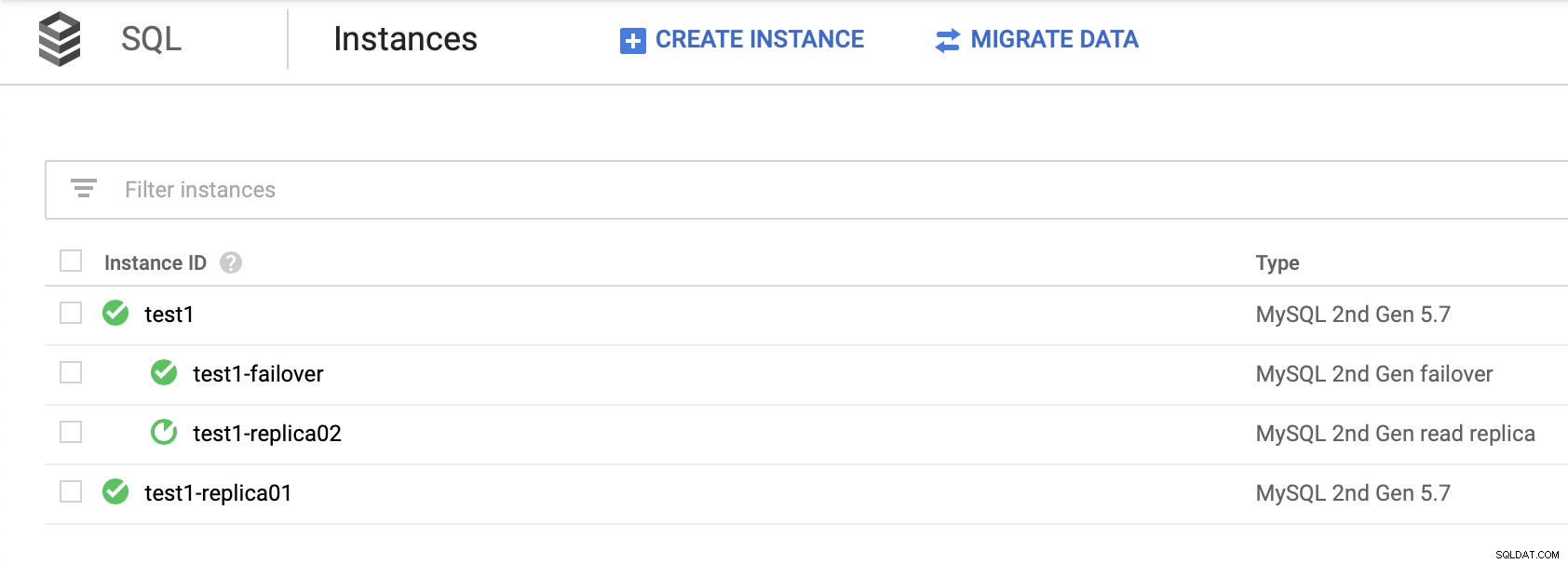
Não há como escravizar suas outras réplicas do novo cluster. A única maneira de fazer isso seria criar novas réplicas, mas esse é um processo demorado. Também é praticamente inutilizável, tornando a réplica de failover a única opção real de alta disponibilidade para nós SQL no Google Cloud Platform.
Conclusão
Embora seja possível criar um ambiente altamente disponível para nós SQL no GCP, o mestre não estará disponível por aproximadamente um minuto e meio. Todo o processo (incluindo a reconstrução da réplica de failover e algumas ações nas réplicas de leitura) levou vários minutos. Durante esse período, não conseguimos acionar um failover adicional nem promover uma réplica de leitura.
Temos usuários do GCP por aí? Como você está alcançando a alta disponibilidade?