Adição: O SQL Server 2012 mostra algum desempenho aprimorado nessa área, mas não parece resolver os problemas específicos indicados abaixo. Aparentemente, isso deve ser corrigido na próxima versão principal depois SQL Server 2012!
Seu plano mostra que as inserções únicas estão usando procedimentos parametrizados (possivelmente parametrizados automaticamente), portanto, o tempo de análise/compilação para eles deve ser mínimo.
Eu pensei em pesquisar um pouco mais sobre isso, então configure um loop (script) e tentei ajustar o número de
VALUES cláusulas e registrando o tempo de compilação. Em seguida, dividi o tempo de compilação pelo número de linhas para obter o tempo médio de compilação por cláusula. Os resultados estão abaixo
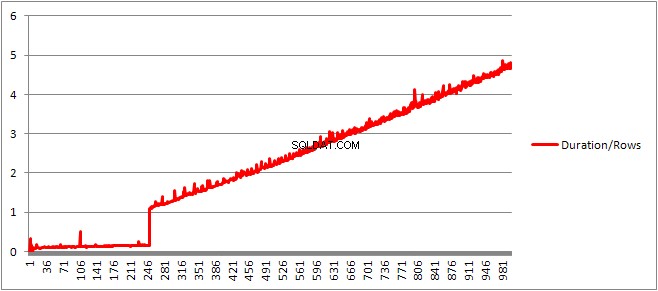
Até 250
VALUES cláusulas apresentam o tempo de compilação/número de cláusulas tem uma ligeira tendência de alta mas nada muito dramático. 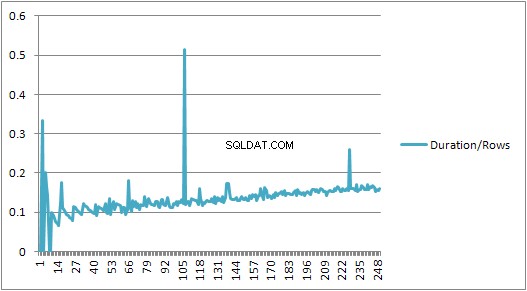
Mas então há uma mudança repentina.
Essa seção dos dados é mostrada abaixo.
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
O tamanho do plano em cache que estava crescendo linearmente cai repentinamente, mas o CompileTime aumenta 7 vezes e o CompileMemory dispara. Este é o ponto de corte entre o plano ser um auto parametrizado (com 1.000 parâmetros) e um não parametrizado. A partir daí, parece ficar linearmente menos eficiente (em termos de número de cláusulas de valor processadas em um determinado tempo).
Não tenho certeza por que isso deveria ser. Presumivelmente, ao compilar um plano para valores literais específicos, ele deve executar alguma atividade que não seja dimensionada linearmente (como classificação).
Não parece afetar o tamanho do plano de consulta em cache quando tentei uma consulta consistindo inteiramente de linhas duplicadas e também não afeta a ordem da saída da tabela das constantes (e como você está inserindo em um heap o tempo gasto na classificação seria inútil de qualquer maneira, mesmo que o fizesse).
Além disso, se um índice clusterizado for adicionado à tabela, o plano ainda mostrará uma etapa de classificação explícita para que não pareça estar classificando em tempo de compilação para evitar uma classificação em tempo de execução.

Eu tentei ver isso em um depurador, mas os símbolos públicos para minha versão do SQL Server 2008 não parecem estar disponíveis, então eu tive que olhar para o equivalente
UNION ALL construção no SQL Server 2005. Um rastreamento de pilha típico está abaixo
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
Então, tirando os nomes no rastreamento de pilha, parece gastar muito tempo comparando strings.
Este artigo da base de conhecimento indica que
DeriveNormalizedGroupProperties está associado ao que costumava ser chamado de estágio de normalização do processamento de consultas Este estágio agora é chamado de vinculação ou algebrização e leva a saída da árvore de análise da expressão do estágio de análise anterior e gera uma árvore de expressão algebrizada (árvore do processador de consultas) para avançar para a otimização (otimização de plano trivial neste caso) [ref].
Eu tentei mais um experimento (Script) que era re-executar o teste original, mas olhando para três casos diferentes.
- Nome e sobrenome Strings de 10 caracteres sem duplicatas.
- Nome e sobrenome Strings de 50 caracteres sem duplicatas.
- Nome e sobrenome Strings de 10 caracteres com todas as duplicatas.
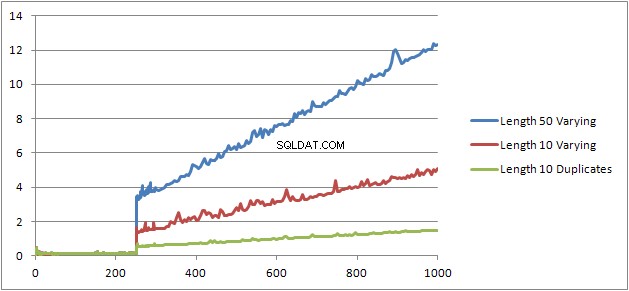
Pode-se ver claramente que quanto mais longas as cordas, piores as coisas ficam e que, inversamente, quanto mais duplicatas, melhores as coisas ficam. Como as duplicatas mencionadas anteriormente não afetam o tamanho do plano em cache, presumo que deve haver um processo de identificação de duplicatas ao construir a própria árvore de expressão algebrizada.
Editar
Um lugar onde essas informações são aproveitadas é mostrado por @Lieven aqui
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
Porque em tempo de compilação pode determinar que o
Name a coluna não tem duplicatas, ela ignora a ordenação pelo secundário 1/ (ID - ID) expressão em tempo de execução (a classificação no plano tem apenas um ORDER BY coluna) e nenhum erro de divisão por zero é gerado. Se duplicatas forem adicionadas à tabela, o operador de classificação mostrará duas colunas ordenadas e o erro esperado será gerado.