Anteriormente, postamos um blog discutindo Achieving MySQL Failover &Failback on Google Cloud Platform (GCP) e neste blog veremos como seu rival, Amazon Relational Database Service (RDS), lida com o failover. Também veremos como você pode executar um failback de seu antigo nó mestre, trazendo-o de volta à sua ordem original como mestre.
Ao comparar as nuvens públicas gigantes da tecnologia que suportam serviços de banco de dados relacional gerenciado, a Amazon é a única que oferece uma opção alternativa (junto com MySQL/MariaDB, PostgreSQL, Oracle e SQL Server) para entregar seu próprio tipo de gerenciamento de banco de dados chamado Amazon Aurora. Para aqueles que não estão familiarizados com o Aurora, é um mecanismo de banco de dados relacional totalmente gerenciado compatível com MySQL e PostgreSQL. O Aurora faz parte do serviço de banco de dados gerenciado Amazon RDS, um serviço da web que facilita a configuração, a operação e o dimensionamento de um banco de dados relacional na nuvem.
Por que você precisaria fazer failover ou failback?
Projetar um sistema grande que seja tolerante a falhas, altamente disponível, sem ponto único de falha (SPOF) requer testes adequados para determinar como ele reagiria quando as coisas derem errado.
Se você estiver preocupado com o desempenho do seu sistema ao responder à detecção, isolamento e recuperação de falhas (FDIR) do sistema, o failover e o failback devem ser de grande importância.
Failover de banco de dados no Amazon RDS
O failover ocorre automaticamente (já que o failover manual é chamado de switchover). Conforme discutido em um blog anterior, a necessidade de failover ocorre quando o mestre de banco de dados atual sofre uma falha de rede ou encerramento anormal do sistema host. O failover o alterna para um estado estável de redundância ou para um servidor de computador em espera, sistema, componente de hardware ou rede.
No Amazon RDS, você não precisa fazer isso, nem é obrigado a monitorá-lo por conta própria, pois o RDS é um serviço de banco de dados gerenciado (o que significa que a Amazon cuida do trabalho para você). Esse serviço gerencia coisas como problemas de hardware, backup e recuperação, atualizações de software, atualizações de armazenamento e até mesmo patches de software. Falaremos sobre isso mais adiante neste blog.
Failback de banco de dados no Amazon RDS
No blog anterior, também abordamos por que você precisaria fazer o failback. Em um ambiente replicado típico, o mestre deve ser poderoso o suficiente para carregar uma carga enorme, especialmente quando o requisito de carga de trabalho é alto. Sua configuração mestre requer especificações de hardware adequadas para garantir que possa processar gravações, gerar eventos de replicação, processar leituras críticas etc. de maneira estável. Quando o failover é necessário durante a recuperação de desastres (ou para manutenção), não é incomum que, ao promover um novo mestre, você use hardware inferior. Essa situação pode ficar bem temporariamente, mas a longo prazo, o mestre designado deve ser trazido de volta para liderar a replicação depois que ela for considerada íntegra (ou a manutenção for concluída).
Ao contrário do failover, as operações de failback geralmente acontecem em um ambiente controlado usando a alternância. Raramente é feito quando em modo de pânico. Essa abordagem fornece aos engenheiros tempo suficiente para planejar cuidadosamente e ensaiar o exercício para garantir uma transição suave. Seu principal objetivo é simplesmente trazer de volta o bom e antigo mestre para o estado mais recente e restaurar a configuração de replicação para sua topologia original. Como estamos lidando com o Amazon RDS, não há necessidade de você se preocupar excessivamente com esse tipo de problema, pois é um serviço gerenciado com a maioria dos trabalhos sendo tratados pela Amazon.
Como o Amazon RDS trata o failover de banco de dados?
Ao implantar os nós do Amazon RDS, você pode configurar o cluster de banco de dados com a zona de multidisponibilidade (AZ) ou para uma zona de disponibilidade única. Vamos verificar cada um deles sobre como o failover está sendo processado.
O que é uma configuração Multi-AZ?
Quando ocorre uma catástrofe ou desastre, como interrupções não planejadas ou desastres naturais em que suas instâncias de banco de dados são afetadas, o Amazon RDS alterna automaticamente para uma réplica em espera em outra zona de disponibilidade. Essa AZ geralmente está em outra ramificação do data center, geralmente longe da zona de disponibilidade atual onde as instâncias estão localizadas. Essas AZs são instalações de última geração e altamente disponíveis que protegem suas instâncias de banco de dados. Os tempos de failover dependem da conclusão da configuração, que geralmente se baseia no tamanho e na atividade do banco de dados, bem como em outras condições presentes no momento em que a instância de banco de dados primária ficou indisponível.
Os tempos de failover geralmente são de 60 a 120 segundos. No entanto, eles podem ser mais longos, pois transações grandes ou um processo de recuperação demorado podem aumentar o tempo de failover. Quando o failover for concluído, também poderá levar mais tempo para que o RDS Console (UI) reflita a nova zona de disponibilidade.
O que é uma configuração Single-AZ?
As configurações Single-AZ só devem ser usadas para suas instâncias de banco de dados se seu RTO (objetivo de tempo de recuperação) e RPO (objetivo de ponto de recuperação) forem altos o suficiente para permitir isso. Existem riscos envolvidos com o uso de um Single-AZ, como grandes tempos de inatividade que podem interromper as operações de negócios.
Cenários comuns de falha do RDS
A quantidade de tempo de inatividade depende do tipo de falha. Vamos ver o que são e como a recuperação da instância é tratada.
Falha de instância recuperável
Uma falha de instância do Amazon RDS ocorre quando a instância do EC2 subjacente sofre uma falha. Após a ocorrência, a AWS acionará uma notificação de evento e enviará um alerta para você usando o Amazon RDS Event Notifications. Esse sistema usa o AWS Simple Notification Service (SNS) como processador de alertas.
O RDS tentará automaticamente iniciar uma nova instância na mesma zona de disponibilidade, anexar o volume do EBS e tentar a recuperação. Nesse cenário, o RTO geralmente é inferior a 30 minutos. O RPO é zero porque o volume do EBS pôde ser recuperado. O volume do EBS está em uma única zona de disponibilidade e esse tipo de recuperação ocorre na mesma zona de disponibilidade da instância original.
Falhas de instância não recuperáveis ou falhas de volume do EBS
Para recuperação de instância RDS com falha (ou se o volume EBS subjacente sofrer uma falha de perda de dados), a recuperação pontual (PITR) é necessária. O PITR não é tratado automaticamente pela Amazon, portanto, você precisa criar um script para automatizá-lo (usando o AWS Lambda) ou fazê-lo manualmente.
O tempo do RTO requer a inicialização de uma nova instância do Amazon RDS, que terá um novo nome DNS após a criação, e a aplicação de todas as alterações desde o último backup.
O RPO é normalmente de 5 minutos, mas você pode encontrá-lo chamando RDS:describe-db-instances:LatestRestorableTime. O tempo pode variar de 10 minutos a horas, dependendo do número de logs que precisam ser aplicados. Ele só pode ser determinado por testes, pois depende do tamanho do banco de dados, do número de alterações feitas desde o último backup e dos níveis de carga de trabalho no banco de dados. Como os backups e os logs de transações são armazenados no Amazon S3, essa recuperação pode ocorrer em qualquer zona de disponibilidade compatível na região.
Depois que a nova instância for criada, você precisará atualizar o nome do endpoint do seu cliente. Você também tem a opção de renomeá-lo para o nome do endpoint da instância de banco de dados antiga (mas isso exige que você exclua a instância com falha antiga), mas isso impossibilita a determinação da causa raiz do problema.
Interrupções na zona de disponibilidade
As interrupções da zona de disponibilidade podem ser temporárias e raras, no entanto, se a falha de AZ for mais permanente, a instância será configurada para um estado de falha. A recuperação funcionaria conforme descrito anteriormente e uma nova instância poderia ser criada em uma AZ diferente, usando a recuperação pontual. Esta etapa deve ser feita manualmente ou por script. A estratégia para esse tipo de cenário de recuperação deve fazer parte de seus planos maiores de recuperação de desastres (DR).
Se a falha da zona de disponibilidade for temporária, o banco de dados ficará inativo, mas permanecerá no estado disponível. Você é responsável pelo monitoramento em nível de aplicativo (usando ferramentas da Amazon ou de terceiros) para detectar esse tipo de cenário. Se isso ocorrer, você poderá aguardar a recuperação da zona de disponibilidade ou optar por recuperar a instância para outra zona de disponibilidade com uma recuperação pontual.
O RTO seria o tempo necessário para iniciar uma nova instância do RDS e, em seguida, aplicar todas as alterações desde o último backup. O RPO pode ser mais longo, até o momento em que ocorreu a falha da zona de disponibilidade.
Teste de failover e failback no Amazon RDS
Criamos e configuramos um Amazon RDS Aurora usando db.r4.large com uma implantação Multi-AZ (que criará uma réplica/leitor do Aurora em uma AZ diferente), acessível apenas via EC2. Você precisará escolher essa opção na criação se pretender ter o Amazon RDS como mecanismo de failover.
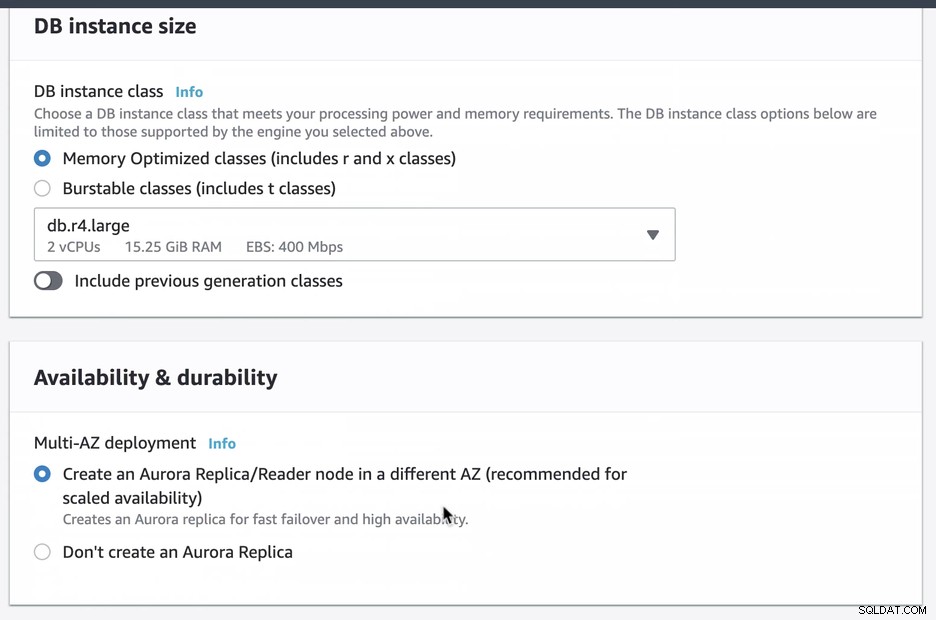
Durante o provisionamento de nossa instância RDS, levou cerca de 11 minutos antes as instâncias tornaram-se disponíveis e acessíveis. Abaixo está uma captura de tela dos nós disponíveis no RDS após a criação:
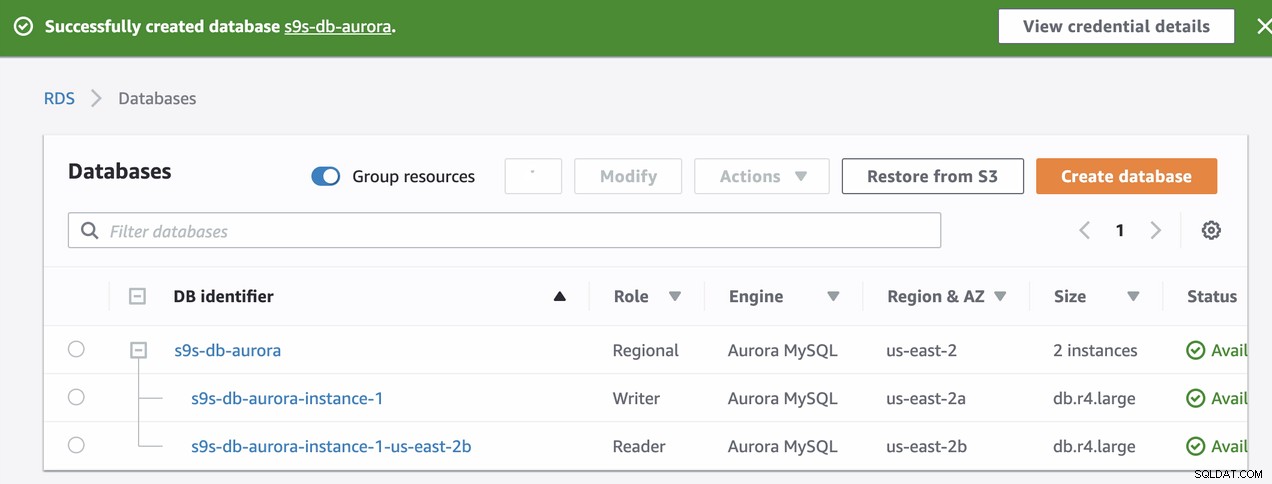
Esses dois nós terão seus próprios nomes de endpoints designados, que serão use para se conectar da perspectiva do cliente. Verifique primeiro e verifique o nome do host subjacente para cada um desses nós. Para verificar, você pode executar este comando bash abaixo e apenas substituir os nomes de host/endpoints de acordo:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+O resultado esclarece da seguinte forma,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Simulando o failover do Amazon RDS
Agora, vamos simular uma falha para simular um failover para a instância do gravador Amazon RDS Aurora, que é s9s-db-aurora-instance-1 com endpoint s9s-db-aurora.cluster-cmu8qdlvkepg.us -east-2.rds.amazonaws.com.
Para fazer isso, conecte-se à sua instância do gravador usando o prompt de comando do cliente mysql e emita a sintaxe abaixo:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];A emissão deste comando tem sua detecção de recuperação do Amazon RDS e atua muito rapidamente. Embora a consulta seja para fins de teste, ela pode ser diferente quando essa ocorrência ocorre em um evento factual. Você pode estar interessado em saber mais sobre como testar uma falha de instância em sua documentação. Veja como terminamos abaixo:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Executar o comando SQL acima significa que ele precisa simular uma falha de disco por pelo menos 3 minutos. Monitorei o ponto no tempo para iniciar a simulação e levou cerca de 18 segundos antes do início do failover.
Veja abaixo como o RDS lida com a falha da simulação e o failover,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Os resultados desta simulação são bastante interessantes. Vamos pegar este de cada vez.
- Por volta das 10:06:29, comecei a executar a consulta de simulação conforme indicado acima.
- Por volta das 10:06:44, mostra o endpoint s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com com o nome de host atribuído ip-10-20-1- 139 onde, na verdade, é a instância somente leitura, ficou inacessível, mas o comando de simulação foi executado na instância de leitura e gravação.
- Por volta das 10:06:51, ele mostra o endpoint s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com com o nome de host atribuído ip-10-20-1- 139 está ativo, mas tem marca como estado de leitura e gravação. Observe que a variável innodb_read_only, para instâncias gerenciadas do Aurora MySQL, é seu identificador para determinar se o host é um nó de leitura/gravação ou somente leitura, e o Aurora também é executado apenas no mecanismo de armazenamento InnoDB para instâncias compatíveis com MySQL.
- Por volta das 10:07:13, a ordem mudou. Isso significa que o failover foi feito e as instâncias foram atribuídas aos endpoints designados.
Confira o resultado abaixo que é mostrado no console do RDS:
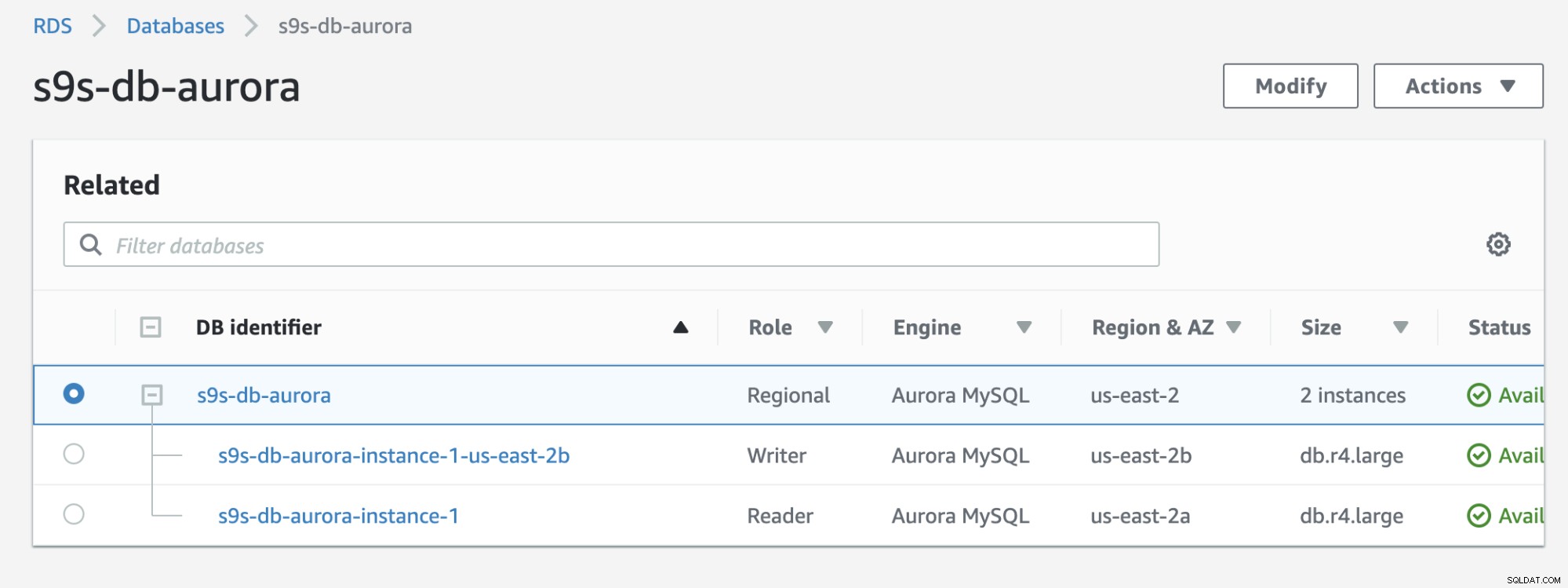
Se você comparar com o anterior, o s9s-db-aurora- instance-1 era um leitor, mas foi promovido como escritor após o failover. O processo, incluindo o teste, levou cerca de 44 segundos para concluir a tarefa, mas o failover foi concluído em quase 30 segundos. Isso é impressionante e rápido para um failover, especialmente considerando que se trata de um banco de dados de serviço gerenciado; o que significa que você não precisa se preocupar com nenhum problema de hardware ou manutenção.
Executando um failback no Amazon RDS
Failback no Amazon RDS é bem simples. Antes de passar por isso, vamos adicionar uma nova réplica de leitor. Precisamos de uma opção para testar e identificar qual nó o AWS RDS escolheria quando tenta fazer failback para o mestre desejado (ou failback para o mestre anterior) e para ver se seleciona o nó certo com base na prioridade. A lista atual de instâncias a partir de agora e seus endpoints são mostrados abaixo.
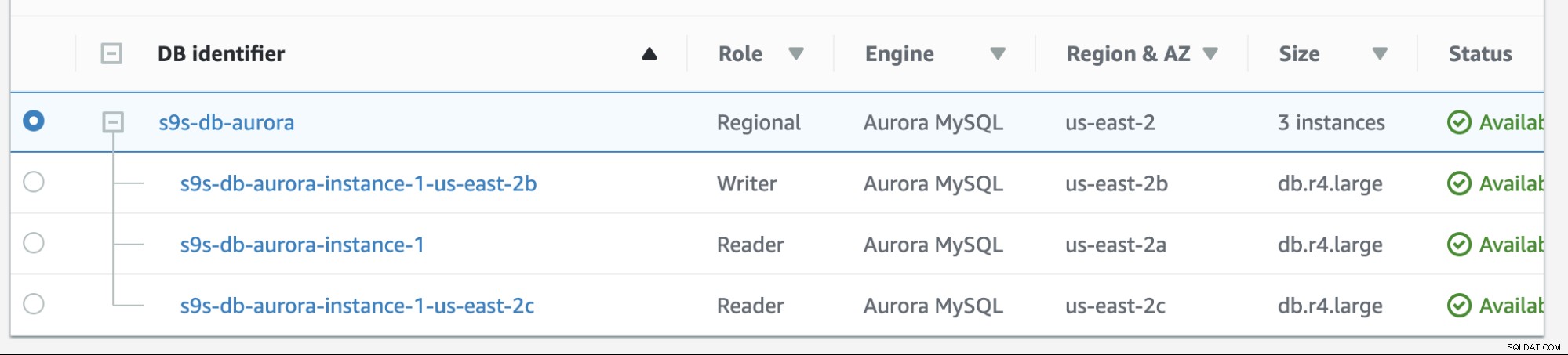

A nova réplica está localizada em us-east-2c AZ com db hostname de ip-10-20-2-239.
Vamos tentar fazer um failback usando a instância s9s-db-aurora-instance-1 como o destino de failback desejado. Nesta configuração, temos duas instâncias de leitor. Para garantir que o nó correto seja selecionado durante o failover, você precisará estabelecer se a prioridade ou a disponibilidade está no topo (camada-0> camada-1> camada-2 e assim por diante até a camada 15). Isso pode ser feito modificando a instância ou durante a criação da réplica.
Você pode verificar isso em seu console RDS.
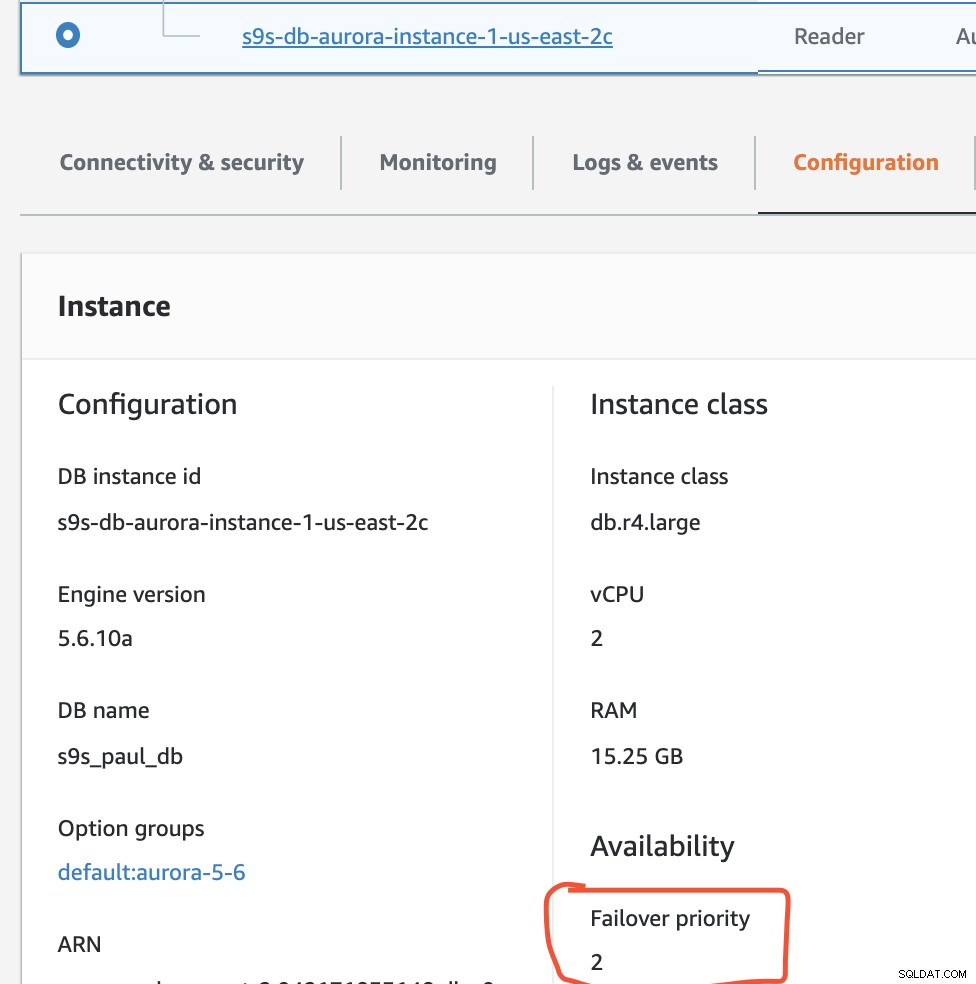
Nesta configuração s9s-db-aurora-instance-1 tem prioridade =0 (e é uma réplica de leitura), s9s-db-aurora-instance-1-us-east-2b tem prioridade =1 (e é o gravador atual) e s9s-db-aurora-instance-1-us- east-2c tem prioridade =2 (e também é uma réplica de leitura). Vamos ver o que acontece quando tentamos fazer o failback.
Você pode monitorar o estado usando este comando.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Após o failover ser acionado, ele retornará ao nosso destino desejado, que é o nó s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+A tentativa de failback começou às 13:30:59 e foi concluída por volta das 13:31:38 (a marca de 30 segundos mais próxima). Acaba com ~32 segundos neste teste, que ainda é rápido.
Verifiquei o failover/failback várias vezes e ele tem trocado consistentemente seu estado de leitura/gravação entre as instâncias s9s-db-aurora-instance-1 e s9s-db-aurora-instance-1- us-leste-2b. Isso deixa s9s-db-aurora-instance-1-us-east-2c sem escolha, a menos que ambos os nós estejam com problemas (o que é muito raro, pois todos estão situados em diferentes AZs).
Durante as tentativas de failover/failback, o RDS vai em um ritmo de transição rápido durante o failover em torno de 15 a 25 segundos (o que é muito rápido). Lembre-se de que não temos grandes arquivos de dados armazenados nesta instância, mas ainda é bastante impressionante, considerando que não há mais nada para gerenciar.
Conclusão
Executar um Single-AZ apresenta perigo ao realizar um failover. O Amazon RDS permite que você modifique e converta sua configuração Single-AZ para Multi-AZ, embora isso acrescente alguns custos para você. Single-AZ pode ser bom se você estiver bem com um tempo de RTO e RPO mais alto, mas definitivamente não é recomendado para aplicativos de negócios de alto tráfego e missão crítica.
Com o Multi-AZ, você pode automatizar failover e failback no Amazon RDS, dedicando seu tempo ao ajuste ou otimização de consultas. Isso facilita muitos problemas enfrentados por DevOps ou DBAs.
Embora o Amazon RDS possa causar um dilema em algumas organizações (já que não é independente de plataforma), ainda é digno de consideração; especialmente se seu aplicativo exigir um plano de DR de longo prazo e você não quiser perder tempo se preocupando com hardware e planejamento de capacidade.