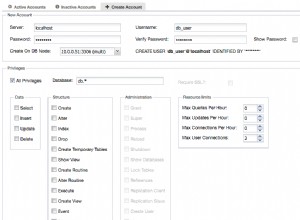
crosstab() função com dois parâmetros.
Deve funcionar assim, para obter valores para 2012:
SELECT * FROM crosstab(
$$SELECT testname, to_char(last_update, 'mon_YYYY'), count(*)::int AS ct
FROM tests
WHERE current_status = 'FAILED'
AND last_update >= '2012-01-01 0:0'
AND last_update < '2013-01-01 0:0' -- proper date range!
GROUP BY 1,2
ORDER BY 1,2$$
,$$VALUES
('jan_2012'::text), ('feb_2012'), ('mar_2012')
, ('apr_2012'), ('may_2012'), ('jun_2012')
, ('jul_2012'), ('aug_2012'), ('sep_2012')
, ('oct_2012'), ('nov_2012'), ('dec_2012')$$)
AS ct (testname text
, jan_2012 int, feb_2012 int, mar_2012 int
, apr_2012 int, may_2012 int, jun_2012 int
, jul_2012 int, aug_2012 int, sep_2012 int
, oct_2012 int, nov_2012 int, dec_2012 int);
Encontre uma explicação detalhada nesta pergunta relacionada.
Testado agora com meu próprio caso de teste.
Não exibir valores NULL
O principal problema (que meses sem linhas não apareceriam) é evitado pelo
crosstab() função com dois parâmetros. Você não pode usar
COALESCE na consulta interna, porque o NULL os valores são inseridos por crosstab() em si. Você poderia ... 1. Envolva tudo em uma subconsulta:
SELECT testname
,COALESCE(jan_2012, 0) AS jan_2012
,COALESCE(feb_2012, 0) AS feb_2012
,COALESCE(mar_2012, 0) AS mar_2012
, ...
FROM (
-- query from above)
) x;
2. LEFT JOIN a consulta principal para a lista completa de meses.
Nesse caso, você não precisa do segundo parâmetro por definição.
Para um intervalo maior, você pode usar
generate_series() para criar os valores. SELECT * FROM crosstab(
$$SELECT t.testname, m.mon, count(x.testname)::int AS ct
FROM (
VALUES
('jan_2012'::text), ('feb_2012'), ('mar_2012')
,('apr_2012'), ('may_2012'), ('jun_2012')
,('jul_2012'), ('aug_2012'), ('sep_2012')
,('oct_2012'), ('nov_2012'), ('dec_2012')
) m(mon)
CROSS JOIN (SELECT DISTINCT testname FROM tests) t
LEFT JOIN (
SELECT testname
,to_char(last_update, 'mon_YYYY') AS mon
FROM tests
WHERE current_status = 'FAILED'
AND last_update >= '2012-01-01 0:0'
AND last_update < '2013-01-01 0:0' -- proper date range!
) x USING (mon)
GROUP BY 1,2
ORDER BY 1,2$$
)
AS ct (testname text
, jan_2012 int, feb_2012 int, mar_2012 int
, apr_2012 int, may_2012 int, jun_2012 int
, jul_2012 int, aug_2012 int, sep_2012 int
, oct_2012 int, nov_2012 int, dec_2012 int);
Caso de teste com dados de amostra
Aqui está um caso de teste com alguns dados de amostra que o OP não forneceu. Eu usei isso para testá-lo e fazê-lo funcionar.
CREATE TEMP TABLE tests (
id bigserial PRIMARY KEY
,testname text NOT NULL
,last_update timestamp without time zone NOT NULL DEFAULT now()
,current_status text NOT NULL
);
INSERT INTO tests (testname, last_update, current_status)
VALUES
('foo', '2012-12-05 21:01', 'FAILED')
,('foo', '2012-12-05 21:01', 'FAILED')
,('foo', '2012-11-05 21:01', 'FAILED')
,('bar', '2012-02-05 21:01', 'FAILED')
,('bar', '2012-02-05 21:01', 'FAILED')
,('bar', '2012-03-05 21:01', 'FAILED')
,('bar', '2012-04-05 21:01', 'FAILED')
,('bar', '2012-05-05 21:01', 'FAILED');