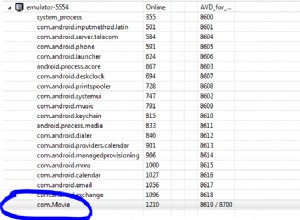
Essencialmente, o limite inferior e superior e o número de partições são usados para calcular o incremento ou divisão para cada tarefa paralela.
Digamos que a tabela tenha a coluna de partição "year" e tenha dados de 2006 a 2016.
Se você definir o número de partições como 10, com limite inferior 2006 e limite superior 2016, você terá cada tarefa buscando dados para seu próprio ano - o caso ideal.
Mesmo se você especificar incorretamente o limite inferior e/ou superior, por exemplo, defina inferior =0 e superior =2016, haverá um desvio na transferência de dados, mas você não "perderá" ou deixará de recuperar nenhum dado, porque:
A primeira tarefa buscará dados para o ano <0.
A segunda tarefa buscará dados para o ano entre 0 e 2016/10.
A terceira tarefa buscará dados para o ano entre 2016/10 e 2*2016/10.
...
E a última tarefa terá uma condição where com ano->2016.
T.