Em várias das minhas postagens no ano passado, usei o tema de pessoas vendo um tipo específico de espera e, em seguida, reagindo de maneira “instintiva” à espera. Normalmente, isso significa seguir alguns conselhos ruins da Internet e tomar uma ação drástica e inadequada ou chegar a uma conclusão sobre qual é a causa raiz do problema e, em seguida, perder tempo e esforço em uma busca inútil.
Um dos tipos de espera em que as reações instintivas são mais fortes e onde existem alguns dos conselhos mais fracos é a espera CXPACKET. É também o tipo de espera que é mais comumente a principal espera nos servidores das pessoas (de acordo com minhas duas grandes pesquisas de tipos de espera de 2010 e 2014 – veja aqui para detalhes), então vou cobri-lo neste post.
O que significa o tipo de espera CXPACKET?
A explicação mais simples é que CXPACKET significa que você tem consultas em paralelo e você *sempre* verá que CXPACKET espera por uma consulta paralela. As esperas do CXPACKET NÃO significam que você tem paralelismo problemático – você precisa ir mais fundo para determinar isso.
Como exemplo de operador paralelo, considere o operador Repartition Streams, que possui o seguinte ícone nos planos de consulta gráfica:

E aqui está uma imagem que mostra o que está acontecendo em termos de threads paralelos para este operador, com grau de paralelismo (DOP) igual a 4:
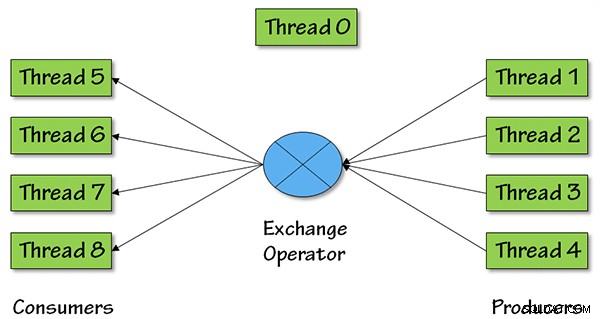
Para DOP =4, haverá quatro encadeamentos produtores, extraindo dados anteriores no plano de consulta, os dados retornam para o restante do plano de consulta por meio de quatro encadeamentos consumidores.
Você pode ver os vários encadeamentos em um operador paralelo que estão aguardando um recurso usando o sys.dm_os_waiting_tasks DMV, no exec_context_id coluna (este post tem meu script para fazer isso).
Há sempre uma thread de 'controle' para qualquer plano paralelo, que por acidente histórico é sempre a ID da thread 0. A thread de controle sempre registra uma espera CXPACKET, com duração igual ao tempo que o plano leva para ser executado. Paul White tem uma ótima explicação de threads em planos paralelos aqui.
A única vez que os threads sem controle registrarão as esperas do CXPACKET é se elas forem concluídas antes dos outros threads no operador. Isso pode acontecer se um dos encadeamentos ficar preso esperando por um recurso por um longo tempo, então veja qual é o tipo de espera do encadeamento que não mostra CXPACKET (usando meu script acima) e solucione o problema adequadamente. Isso também pode acontecer por causa de uma distribuição de trabalho distorcida entre os threads, e vou me aprofundar nesse caso no meu próximo post aqui (é causado por estatísticas desatualizadas e outros problemas de estimativa de cardinalidade).
Observe que no SQL Server 2016 SP2 e no SQL Server 2017 RTM CU3, os threads do consumidor não registram mais as esperas CXPACKET. Eles registram esperas CXCONSUMER, que são benignas e podem ser ignoradas. Isso é para reduzir o número de esperas de CXPACKET sendo geradas, e as restantes têm maior probabilidade de serem acionáveis.
Paralelismo inesperado?
Dado que CXPACKET simplesmente significa que você tem paralelismo acontecendo, a primeira coisa a se observar é se você espera paralelismo para a consulta que o está usando. Minha consulta fornecerá o ID do nó do plano de consulta onde o paralelismo está acontecendo (ele retira o ID do nó do plano de consulta XML se o tipo de espera do encadeamento for CXPACKET), então procure esse ID do nó e determine se o paralelismo faz sentido .
Um dos casos comuns de paralelismo inesperado é quando ocorre uma varredura de tabela onde você espera uma busca ou varredura de índice menor. Você verá isso no plano de consulta ou verá muitas esperas PAGEIOLATCH_SH (discutidas em detalhes aqui) junto com as esperas CXPACKET (um padrão clássico de estatísticas de espera a ser observado). Há uma variedade de causas de varreduras de tabela inesperadas, incluindo:
- Índice não clusterizado ausente, portanto, uma verificação de tabela é a única alternativa
- Estatísticas desatualizadas para que o Otimizador de consultas considere que uma verificação de tabela é o melhor método de acesso a dados a ser usado
- Uma conversão implícita, devido a uma incompatibilidade de tipo de dados entre uma coluna de tabela e uma variável ou parâmetro, o que significa que um índice não clusterizado não pode ser usado
- Aritmética sendo executada em uma coluna de tabela em vez de uma variável ou parâmetro, o que significa que um índice não clusterizado não pode ser usado
Em todos esses casos, a solução é ditada pelo que você acha que é a causa raiz.
Mas e se não houver um caso raiz óbvio e a consulta for considerada cara o suficiente para justificar um plano paralelo?
Evitando paralelismo
Entre outras coisas, o Query Optimizer decide produzir um plano de consulta paralela se o plano serial tiver um custo maior que o
cost threshold for parallelism , uma configuração sp_configure para a instância. O limite de custo para paralelismo (ou CTFP) é definido como cinco por padrão, o que significa que um plano não precisa ser muito caro para acionar a criação de um plano paralelo. Uma das maneiras mais fáceis de evitar paralelismo indesejado é aumentar o CTFP para um número muito maior, quanto mais alto você o definir, menos provável será a criação de planos paralelos. Algumas pessoas defendem a configuração de CTFP para algo entre 25 e 50, mas como em todas as configurações ajustáveis, é melhor testar vários valores e ver o que funciona melhor para o seu ambiente. Se você quiser um método um pouco mais programático para ajudar a escolher um bom valor CTFP, Jonathan escreveu uma postagem no blog mostrando uma consulta para analisar o cache do plano e produzir um valor sugerido para CTFP. Como exemplos, temos um cliente com CTFP definido para 200, e outro definido para o máximo – 32767 – como forma de impedir forçosamente qualquer paralelismo.
Você pode se perguntar por que o segundo cliente teve que usar o CTFP como um método de marreta para evitar o paralelismo quando você acha que eles poderiam simplesmente definir o 'grau máximo de paralelismo' do servidor (ou MAXDOP) para 1. Bem, qualquer pessoa com qualquer nível de permissão pode especifique uma dica MAXDOP de consulta e substitua a configuração MAXDOP do servidor, mas o CTFP não pode ser substituído.
E esse é outro método de limitar o paralelismo – definir uma dica MAXDOP na consulta que você não deseja que seja paralela.
Você também pode diminuir a configuração MAXDOP do servidor, mas essa é uma solução drástica, pois pode impedir que tudo use paralelismo. É comum hoje em dia que os servidores tenham cargas de trabalho mistas, por exemplo, com algumas consultas OLTP e algumas consultas de relatórios. Se você diminuir o MAXDOP do servidor, prejudicará o desempenho das consultas de relatórios.
Uma solução melhor quando há uma carga de trabalho mista seria usar o CTFP como descrevi acima ou utilizar o Resource Governor (que é apenas para empresas). Você pode usar o Resource Governor para separar as cargas de trabalho em grupos de carga de trabalho e, em seguida, definir um MAX_DOP (o sublinhado não é um erro de digitação) para cada grupo de carga de trabalho. E o bom de usar o Resource Governor é que o MAX_DOP não pode ser substituído por uma dica de consulta MAXDOP.
Resumo
Não caia na armadilha de pensar que CXPACKET espera automaticamente significa que você tem um paralelismo ruim acontecendo, e certamente não siga alguns dos conselhos da Internet que eu vi de fechar o servidor configurando MAXDOP para 1. Aproveite o tempo para investigar por que você está vendo esperas de CXPACKET e se é algo a ser tratado ou apenas um artefato de uma carga de trabalho que está sendo executada corretamente.
No que diz respeito às estatísticas gerais de espera, você pode encontrar mais informações sobre como usá-las para solucionar problemas de desempenho em:
- Minha série de postagens do blog SQLskills, começando com estatísticas de espera, ou por favor me diga onde dói
- Minha biblioteca de tipos de espera e classes de trava aqui
- Meu curso de treinamento online Pluralsight SQL Server:Solução de problemas de desempenho usando estatísticas de espera
- Consultor de desempenho do SQL Sentry
No próximo artigo da série, discutirei o paralelismo distorcido e apresentarei uma maneira simples de ver isso acontecendo. Até então, feliz solução de problemas!