Este artigo fornece um guia passo a passo para utilizar os recursos de Machine Learning com 2UDA. No artigo, usaremos um exemplo de Animais para prever se são mamíferos, aves, peixes ou insetos.
Versões de software
Vamos usar o 2UDA versão 11.6-1 para implementar o modelo de Machine Learning. 2UDA versão 11.6-1 combina:
- PostgreSQL 11.6
- Laranja 3.23.0
Você pode encontrar a versão mais recente do 2UDA aqui.
Etapa 1:carregar o conjunto de dados de treinamento no PostgreSQL
O conjunto de dados de amostra usado para treinar nosso modelo está disponível no repositório oficial do Orange GitHub aqui.
Siga estas etapas para carregar os dados de treinamento nas tabelas do PostgreSQL:
- Conecte-se ao PostgreSQL via psql, OmniDB ou qualquer outra ferramenta com a qual você esteja familiarizado.
- Crie uma tabela para armazenar nossos dados de treinamento . Aqui ele é nomeado como training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Insira dados de treinamento na tabela por meio da consulta COPY. Antes de executar a consulta COPY, verifique se o PostgreSQL exigiu permissões de leitura no arquivo de dados, caso contrário, a operação COPY falhará.
NOTA: Certifique-se de digitar uma guia espaço entre aspas simples após o delimitador palavra-chave.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Encontre a captura de tela do conjunto de dados de treinamento abaixo
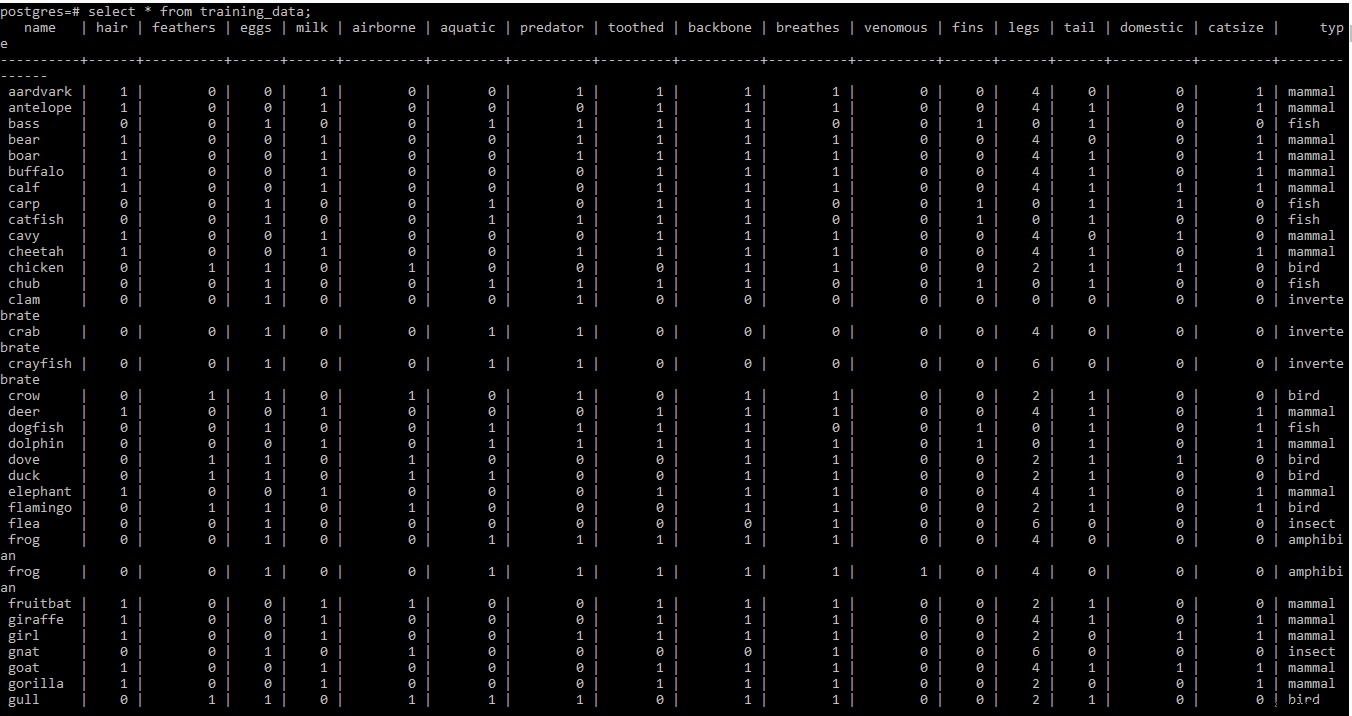
OBSERVAÇÃO: Linhas dois e três do conjunto de dados de treinamento no .tab arquivo contém algumas informações meta. Como não é necessário neste momento, ele foi removido do arquivo.
Etapa 2:crie um fluxo de trabalho com o Orange
- Vá para a área de trabalho e clique duas vezes no ícone laranja.
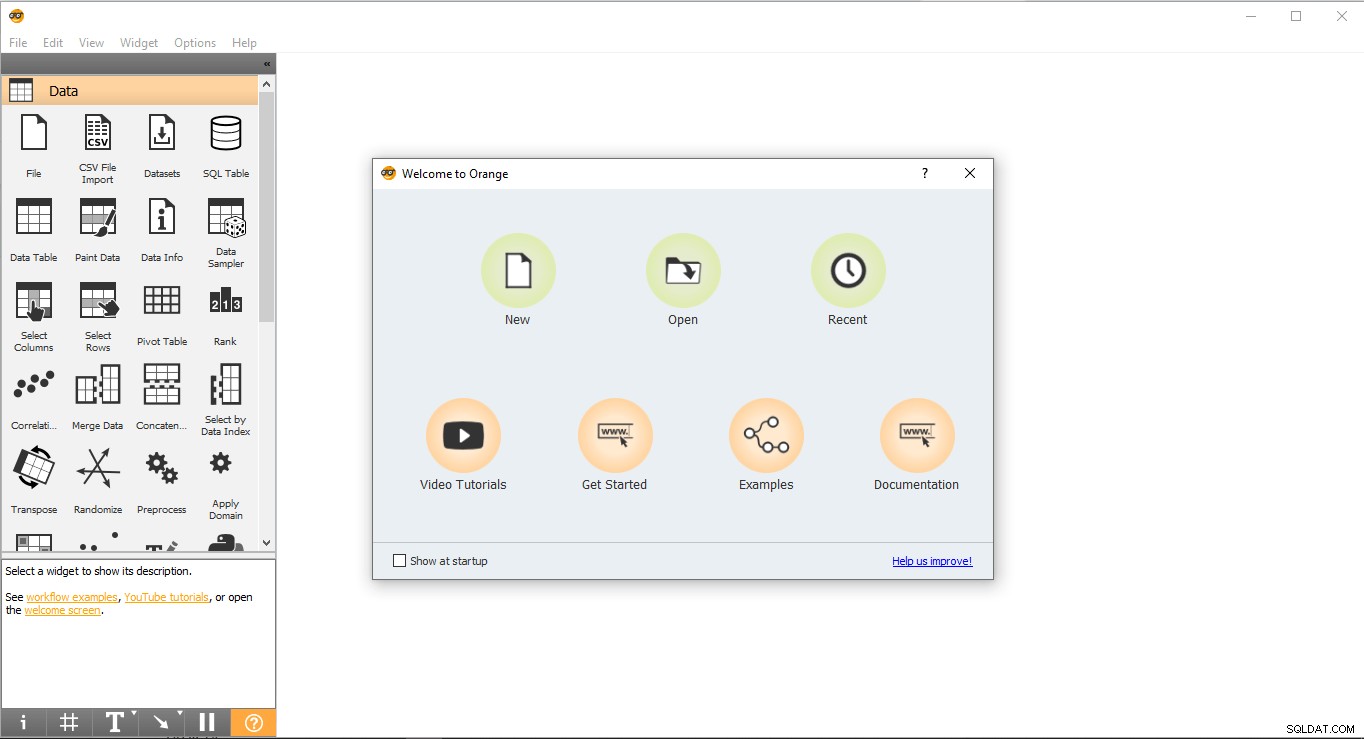
- Esta é a aparência da página inicial. Selecione Novo opção e criará um projeto em branco.

Agora você está pronto para aplicar o modelo de Machine Learning no conjunto de dados.
Etapa 3:selecione o modelo de aprendizado de máquina para treinar os dados
Para este artigo, k-mais próximo vizinhos (KNN) O modelo de aprendizado de máquina é usado para treinar os dados. Quando o processo de treinamento de dados estiver concluído, na próxima etapa, os dados de teste serão passados para a Previsão widget para verificar a precisão das previsões.
Etapa 4:importar dados de treinamento do PostgreSQL para o Orange
Esse conjunto de dados de treinamento será usado para treinar o modelo de Machine Learning.
- Arraste e solte Tabela SQL widget dos Dados cardápio.
- Renomear widget (opcional)
- Clique com o botão direito do mouse na Tabela SQL widget.
- Selecione Renomear .
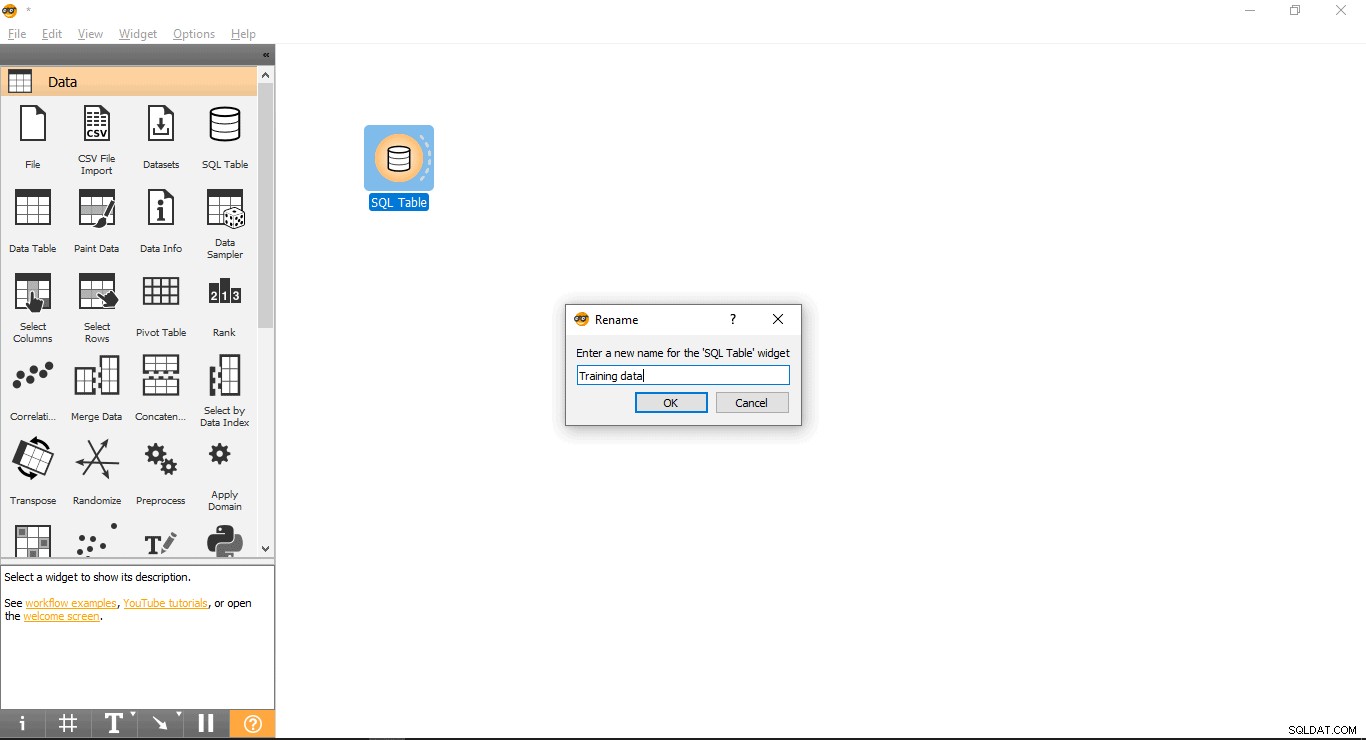
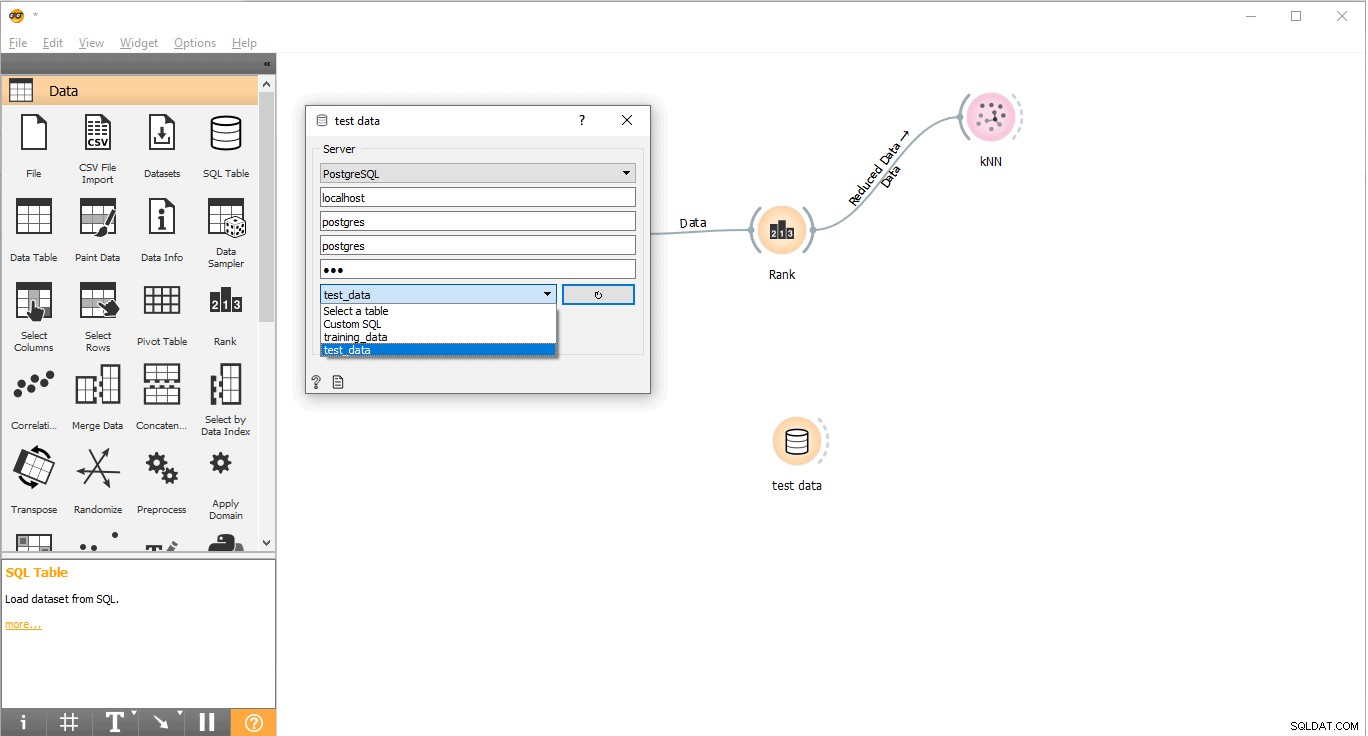
- Conecte-se ao PostgreSQL para carregar o conjunto de dados de treinamento:
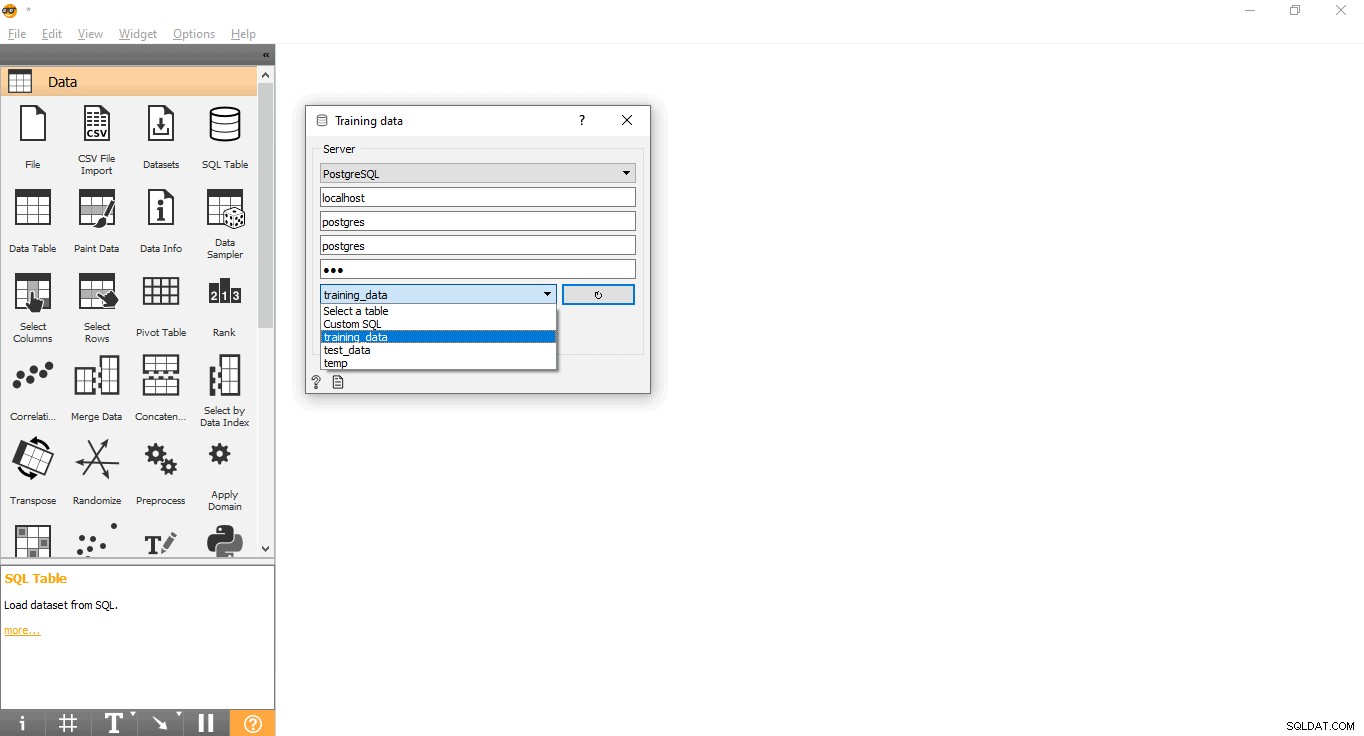
- Clique duas vezes em Dados de treinamento widget.
- Digite as credenciais para se conectar ao banco de dados PostgreSQL.
- Pressione o botão recarregar para carregar todas as tabelas disponíveis do banco de dados fornecido.
- Selecione a tabela training_data no menu suspenso e feche o pop-up.
Etapa 5:adicionar coluna de destino
Esta etapa é importante porque o modelo de Machine Learning tentará prever os dados para essa variável/coluna de destino:
- Arraste e solte Selecionar colunas widget dos dados cardápio.
- Clique duas vezes em Selecionar colunas widget.
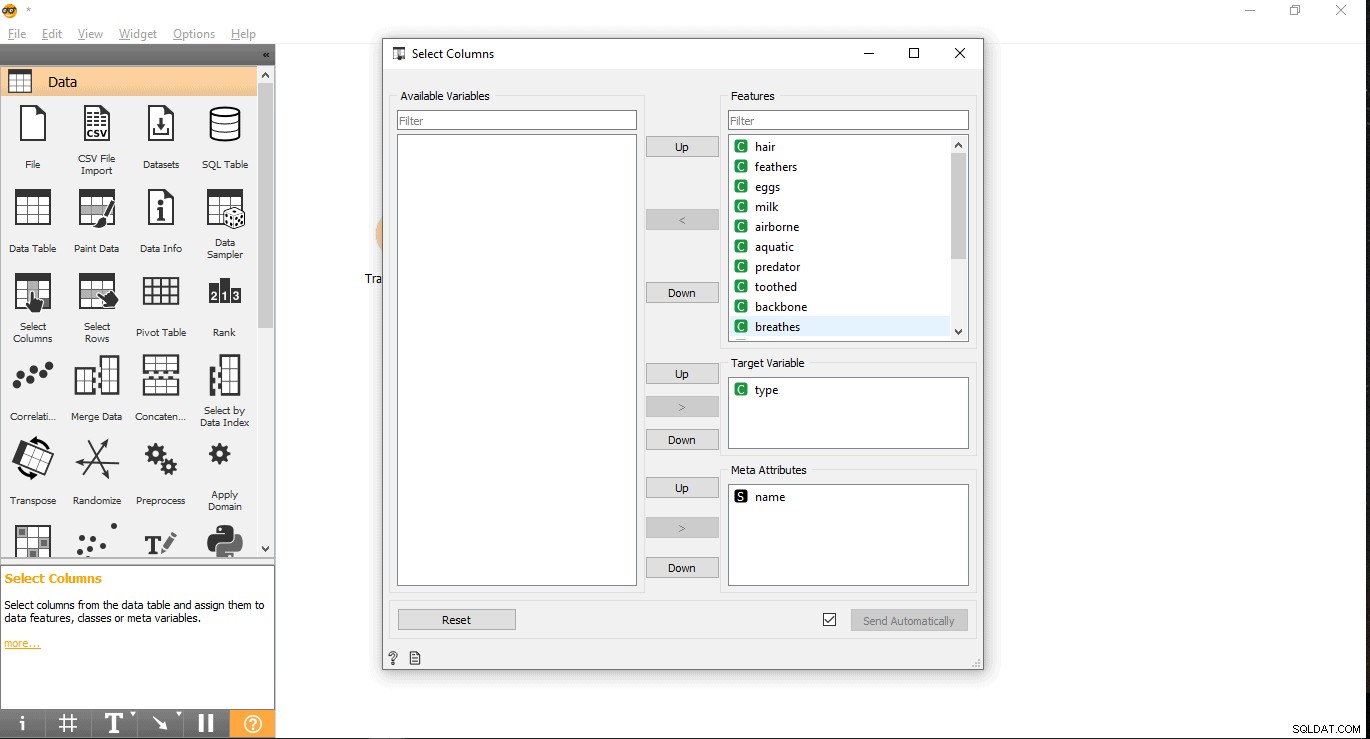
- Pesquise sua coluna de destino no rótulo Recursos. Aqui, tipo é usado como uma variável de destino porque precisamos ver de que tipo é um determinado animal.
- Arraste e solte em Variável de destino caixa e feche o pop-up.
Etapa 6:classificação das colunas
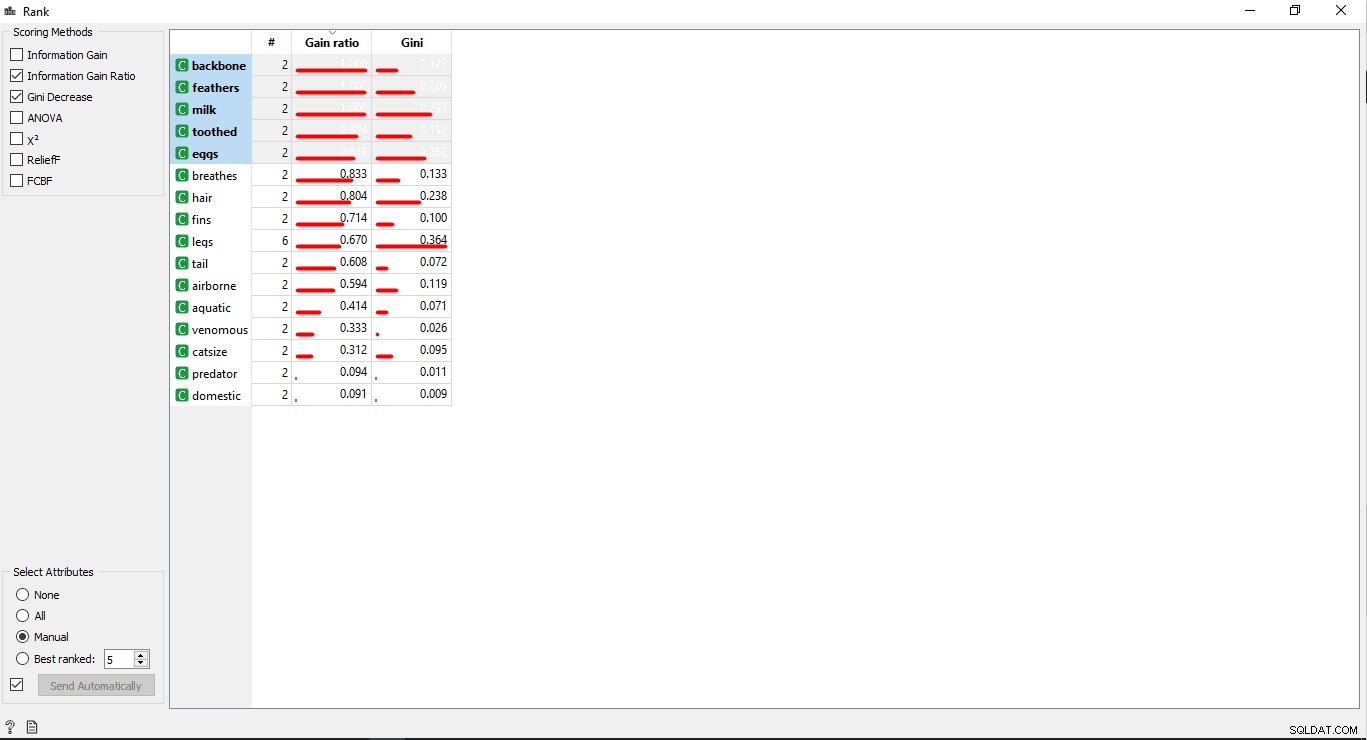
Você pode classificar ou pontuar a variável/colunas de treinamento de acordo com sua correlação com a coluna de destino.
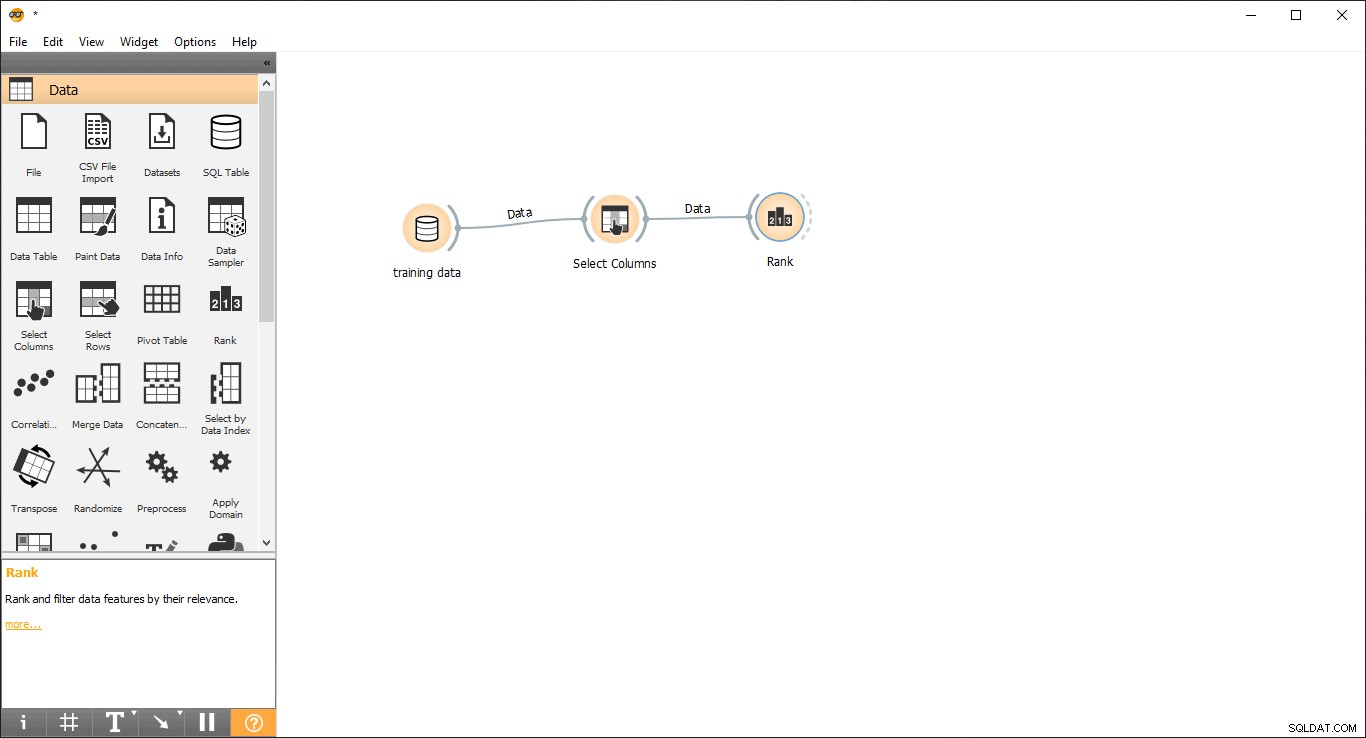
- Arraste e solte Classificação widget dos dados cardápio.
- Desenhe uma linha de link de Selecionar colunas widget para Classificar widget.
- Clique duas vezes na Classificação widget para ver as colunas mais relacionadas na tabela de dados de treinamento. Ele selecionará as 5 principais colunas por padrão.
Etapa 7:treinamento de dados
Nesta etapa, o Modelo de Aprendizado de Máquina (KNN) será treinado com o conjunto de dados de treinamento. Por favor, siga os seguintes passos:
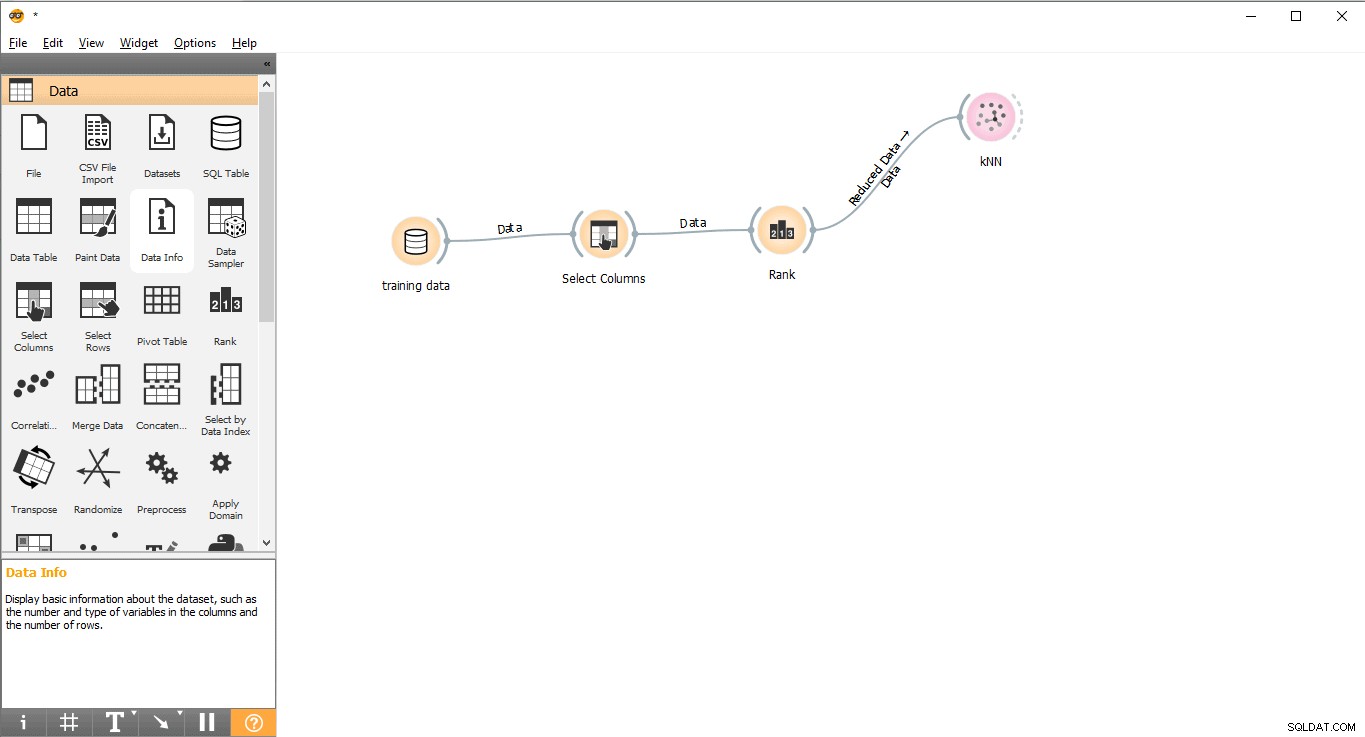
- Arraste e solte KNN widget do Modelo cardápio.
- Desenhe uma linha de link de Classificação widget para KNN widget.
Etapa 8:carregar o conjunto de dados de teste no PostgreSQL
Um conjunto de dados de teste separado é criado para realizar previsões. Siga as etapas para carregar o conjunto de dados de teste na tabela do PostgreSQL.
- Crie uma tabela para armazenar nossos dados de teste . Aqui é nomeado como test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Insira dados de teste na tabela de teste por meio de COPIAR inquerir. Antes de executar COPIAR verifique se o PostgreSQL exigiu permissões de leitura no arquivo de dados, caso contrário a operação COPY falhará.
OBSERVAÇÃO: Certifique-se de digitar uma guia espaço entre aspas simples após o delimitador palavra-chave. Um ponto de interrogação é colocado intencionalmente no tipo coluna do conjunto de dados de teste porque precisamos descobrir o tipo de um determinado animal com nosso modelo de Machine Learning.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Encontre a captura de tela do conjunto de dados de teste abaixo

Etapa 9:Importe os dados de teste do PostgreSQL para o Orange
Siga as etapas a seguir para aplicar as previsões.
- Arraste e solte Tabela SQL widget dos dados cardápio.
- Renomear widget (opcional)
- Clique com o botão direito do mouse na Tabela SQL widget.
- Selecione Renomear .
- Conecte-se ao PostgreSQL para carregar dados de teste.
- Clique duas vezes em Dados de teste widget.
- Conecte-o com Dados de teste tabela do PostgreSQL.
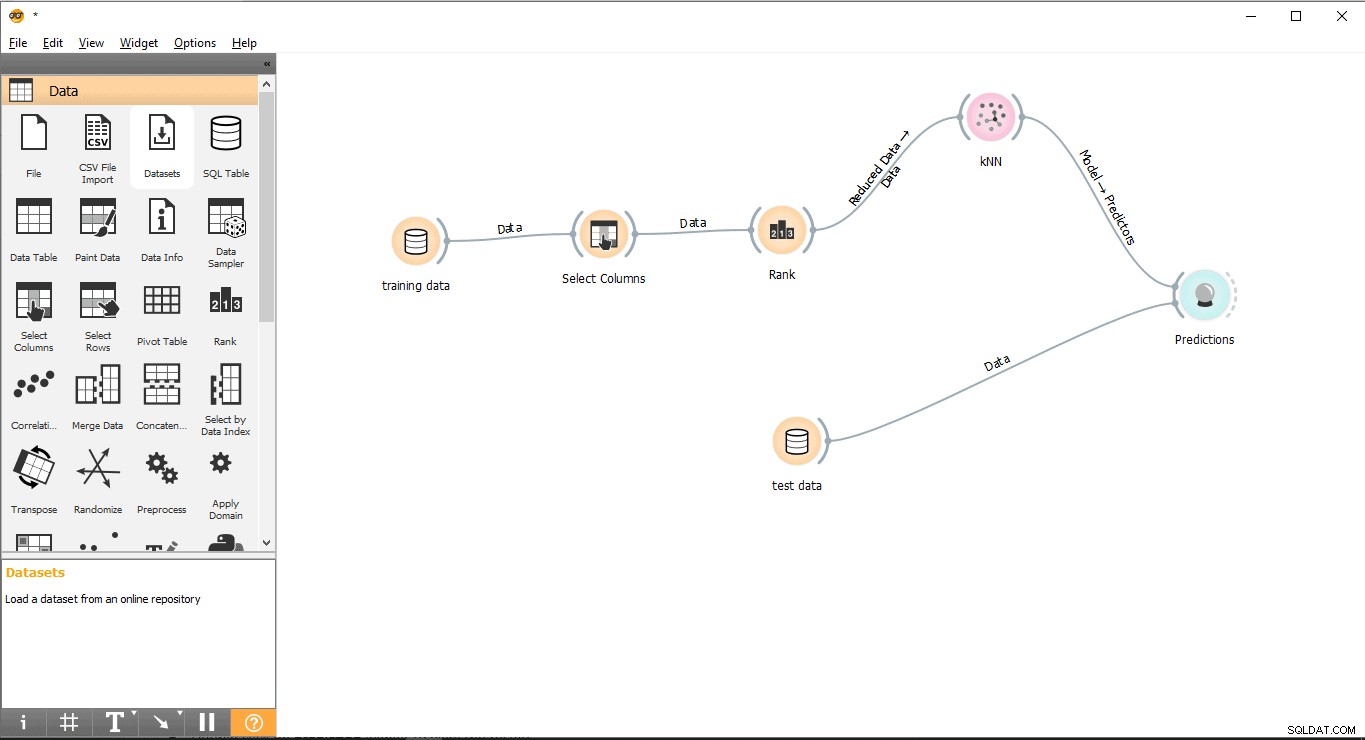
Agora estamos prontos para realizar previsões.
Etapa 10:previsões
Previsão widget tentará prever os dados de teste com base nos dados de treinamento de KNN .
- Arraste e solte Previsão widget do Avaliar cardápio.
- Desenhe um formulário de linha de link Dados de teste widget para Previsão widget.
- Desenhe uma linha de link de KNN widget para Previsão widget.
Etapa 11:Resultados
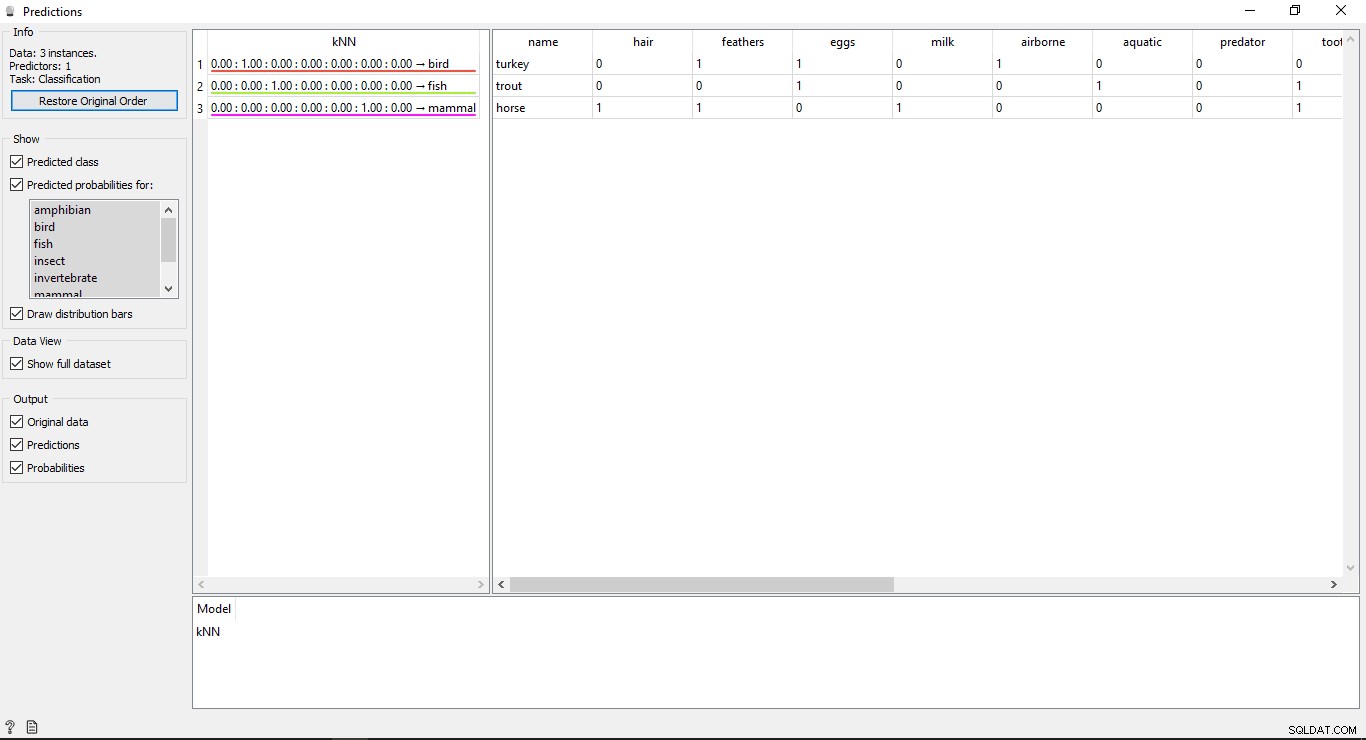
Clique duas vezes em Previsão widget para visualizar os resultados.
Compreendendo os resultados
Você verá 2 tabelas principais na janela de previsão. A tabela à esquerda mostra os resultados previstos, enquanto a tabela à direita mostra os dados originais do teste, que foram fornecidos para previsões.
Desde a KNN model foi usado para treinar dados, então você verá uma coluna chamada KNN que lista os resultados.
Como sabemos:
- Cavalo é um mamífero
- Truta é um peixe
- Turquia é um pássaro
Portanto, o KNN é capaz de determinar todos os tipos corretamente.
Precisão das previsões
Se você vir a tabela do lado esquerdo na saída do widget de previsão, ela tem alguns números antes do tipo previsto, ou seja, 1,00. 0,00 Esses números mostram a precisão do tipo previsto.
Usamos 7 tipos de animais no conjunto de dados de treinamento, portanto, mostra um número total de 7 colunas com valores de precisão, cada coluna representará 1 tipo de animal. Você pode verificar qual coluna está representando que tipo de animal, observando a lista disponível no lado esquerdo da tela em Probabilidades previstas para rótulo. Se você olhar para a primeira linha que diz Turquia é um pássaro . Podemos ver que sua precisão é 1,00 (100% da 2ª coluna). O mesmo vale para outros exemplos Truta é um peixe e sua precisão é 1,00 (100% da 3ª coluna).
Neste artigo, usamos o algoritmo dos k-vizinhos mais próximos (KNN) para implementar o modelo de Machine Learning. No próximo blog, usaremos o Support Vector Machine (SVM).
Para qualquer dúvida ou comentário, entre em contato usando o formulário de contato aqui.



