Se o seu sistema depende do PostgreSQL e você está procurando soluções de cluster para alta disponibilidade, queremos que você saiba com antecedência que é uma tarefa complexa, mas não impossível de realizar.
Considerando seus requisitos de tolerância a falhas, aqui estão algumas soluções de cluster de alta disponibilidade que podem ajudar.
O PostgreSQL não oferece suporte nativo a nenhuma solução de cluster multimestre como MySQL ou Oracle. No entanto, muitos produtos comerciais e comunitários oferecem essa implementação, incluindo replicação e balanceamento de carga para PostgreSQL.
Para começar, vamos rever alguns conceitos básicos:
O que é alta disponibilidade?
Alta disponibilidade refere-se à quantidade de tempo que um serviço está disponível e geralmente é definido pelo nível de desempenho acordado de uma empresa.
A redundância é a base da alta disponibilidade; no caso de um incidente, você pode continuar a operar e acessar os sistemas sem problemas.
Recuperação Contínua
Quando ocorrer um incidente, se você precisar restaurar um backup e aplicar os logs WAL (Write-Ahead Logging), o tempo de recuperação será muito alto e não estará altamente disponível.
No entanto, se você tiver os backups e logs arquivados em um servidor de contingência, poderá aplicar os logs à medida que eles chegam. Se os logs fossem enviados e aplicados a cada minuto, a base de contingência estaria em recuperação contínua e teria um estado desatualizado para a produção de no máximo um minuto.
Bancos de dados em espera
A ideia de um banco de dados standby é manter uma cópia de um banco de dados de produção que sempre tenha os mesmos dados e esteja pronto para ser usado em caso de incidente.
Existem várias maneiras de classificar um banco de dados standby.
Pela natureza da replicação:
-
Esperas físicas:Os blocos de disco são copiados.
-
Esperas lógicas:Transmissão das alterações de dados.
Pela sincronicidade das transações:
-
Assíncrono:Existe a possibilidade de perda de dados.
-
Síncrono:Não há possibilidade de perda de dados; Os commits no master aguardam a resposta do standby.
Pelo uso:
-
Warm standbys:Eles não suportam conexões.
-
Hot standbys:Suporta conexões somente leitura.
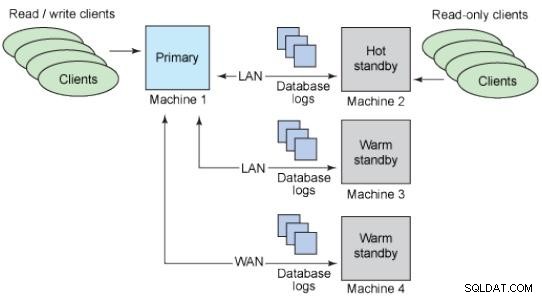
Agrupamentos
Um cluster é um grupo de hosts trabalhando juntos e vistos como um só. Isso fornece uma maneira de obter escalabilidade horizontal e a capacidade de processar mais trabalho adicionando servidores.
Ele pode resistir à falha de um nó e continuar a funcionar de forma transparente. Dependendo do que é compartilhado, existem dois modelos de cluster:
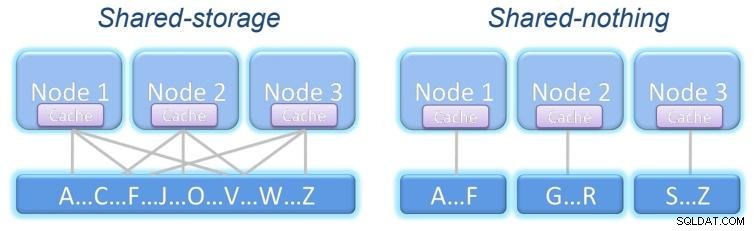
-
Armazenamento compartilhado:Todos os nós acessam o mesmo armazenamento com as mesmas informações.
-
Nada compartilhado:cada nó tem seu próprio armazenamento, que pode ou não ter as mesmas informações que o outro nós, dependendo da estrutura do nosso sistema.
Vamos agora rever algumas das opções de clustering que temos no PostgreSQL.
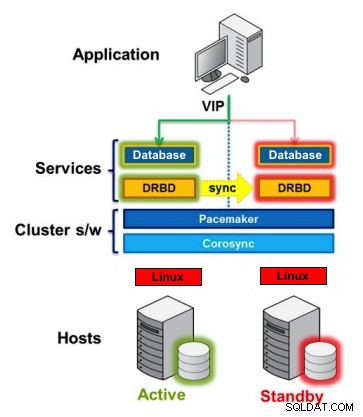
Dispositivo de bloco replicado distribuído
DRBD é um módulo do kernel Linux que implementa a replicação de bloco síncrona usando a rede. Na verdade, ele não implementa um cluster e não lida com failover ou monitoramento. Você precisa de um software complementar para isso, por exemplo, Corosync + Pacemaker + DRBD.
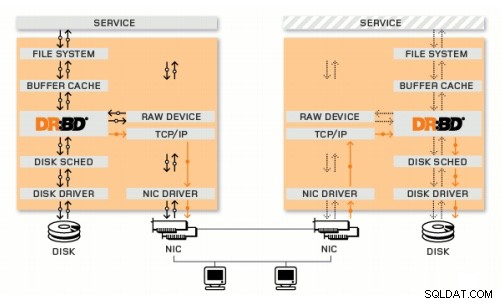
Exemplo:
-
Corosync:Manipula mensagens entre hosts.
-
Pacemaker:Inicia e interrompe serviços, certificando-se de que eles sejam executados apenas em um host.
-
DRBD:Sincroniza os dados no nível dos dispositivos de bloco.
Controle de Cluster
ClusterControl é um software de gerenciamento e automação sem agente para clusters de banco de dados. Ele ajuda a implantar, monitorar, gerenciar e dimensionar seu servidor/cluster de banco de dados diretamente de sua interface de usuário. Ele pode lidar com a maioria das tarefas de administração necessárias para manter servidores de banco de dados ou clusters.
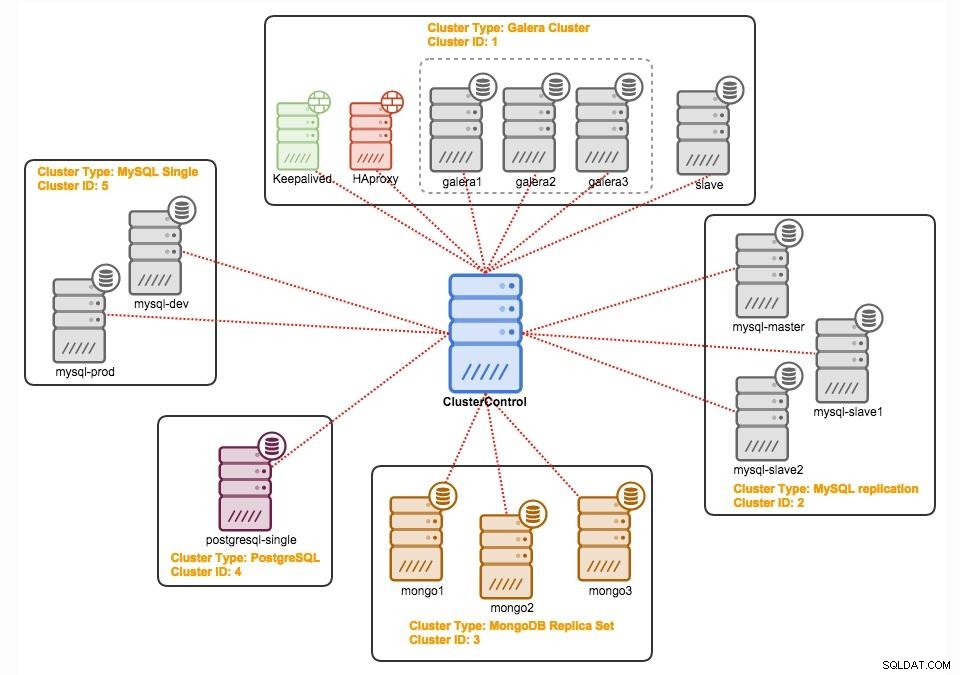
Com ClusterControl, você pode:
-
Implante bancos de dados autônomos, replicados ou em cluster na pilha de tecnologia de sua escolha.
-
Automatize failovers, recuperação e tarefas diárias de maneira uniforme em bancos de dados poliglotas e infraestruturas dinâmicas.
-
Crie backups completos ou incrementais manualmente ou agende-os.
-
Faça um monitoramento unificado e abrangente em tempo real de todo o seu banco de dados e infraestrutura de servidor.
-
Adicione ou remova facilmente um nó com uma única ação.
-
Clone seu cluster para outro data center/provedor de nuvem
Se você tiver um incidente no PostgreSQL, seu nó Standby pode ser promovido a Primário automaticamente.
É uma ferramenta completa que oferece gerenciamento e automação completos do ciclo de vida de operações por meio de um único painel. O ClusterControl também oferece uma avaliação gratuita de 30 dias para que você possa avaliá-lo, sem compromisso.
Rubirep
Rubyrep é uma solução que fornece replicação assíncrona, multi-mestre, multiplataforma (implementada em Ruby ou JRuby) e multi-DBMS (MySQL ou PostgreSQL).
Ele é baseado em gatilhos e não suporta DDL, usuários ou concessões. A simplicidade de uso e administração é seu objetivo primordial.
Alguns recursos incluem:
-
Configuração simples
-
Instalação simples
-
Independente de plataforma, independente de design de tabela.
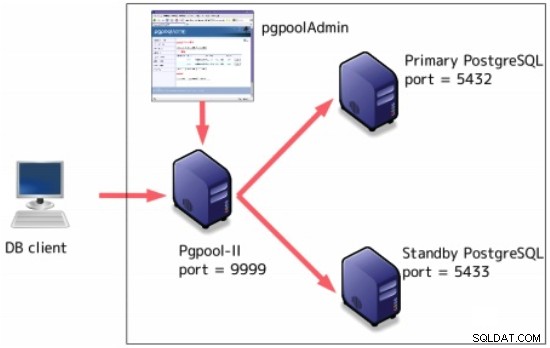
Pgpool-II
Pgpool-II é um middleware que funciona entre servidores PostgreSQL e um cliente de banco de dados PostgreSQL.
Alguns recursos incluem:
-
Pool de conexões
-
Replicação
-
Balanceamento de carga
-
Failover automático
-
Consultas paralelas
Pode ser configurado em cima da replicação de streaming:
Bucardo
Bucardo oferece replicação mestre-escravo em cascata assíncrona, baseada em linha, usando gatilhos e enfileiramento no banco de dados, e replicação mestre-mestre assíncrona, baseada em linha, usando gatilhos e resolução de conflitos personalizada.
Bucardo requer um banco de dados dedicado e funciona como um daemon Perl que se comunica com este banco de dados e todos os outros bancos de dados envolvidos na replicação. Pode ser executado como multi-master ou multi-slave.
A replicação mestre-escravo envolve uma ou mais fontes indo para um ou mais destinos. A origem deve ser PostgreSQL, mas os destinos podem ser PostgreSQL, MySQL, Redis, Oracle, MariaDB, SQLite ou MongoDB.
Alguns recursos incluem:
-
Balanceamento de carga
-
Escravos não são restritos e podem ser escritos
-
Replicação parcial
-
Replicação sob demanda (as alterações podem ser enviadas automaticamente ou quando desejado)
-
Os escravos podem ser "pré-aquecidos" para configuração rápida
Desvantagens:
-
Não é possível lidar com DDL
-
Não é possível lidar com objetos grandes
-
Não é possível replicar tabelas incrementalmente sem uma chave exclusiva
-
Não funcionará em versões anteriores ao Postgres 8
Postgres-XC
Postgres-XC é um projeto de código aberto para fornecer uma solução de cluster PostgreSQL escalável, síncrona, simétrica e transparente. É uma coleção de componentes de banco de dados fortemente acoplados que podem ser instalados em mais de um hardware ou máquina virtual.
Escalável por gravação significa que o Postgres-XC pode ser configurado com quantos servidores de banco de dados você quiser e lidar com muito mais gravações (atualizando instruções SQL) em comparação com o que um único servidor de banco de dados pode fazer.
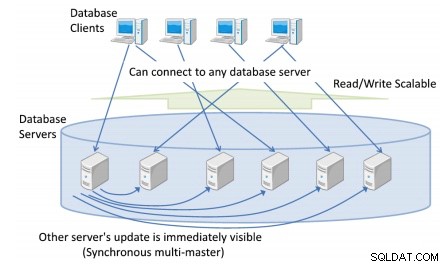
Você pode ter mais de um servidor de banco de dados ao qual os clientes se conectam, fornecendo uma visão única e consistente de todo o cluster do banco de dados.
Qualquer atualização de banco de dados de qualquer servidor de banco de dados fica imediatamente visível para quaisquer outras transações executadas em diferentes mestres.
Transparente significa que você não precisa se preocupar com como seus dados são armazenados em mais de um servidor de banco de dados internamente.
Você pode configurar o Postgres-XC para rodar em vários servidores. Seus dados são armazenados de forma distribuída, particionada ou replicada, conforme sua escolha para cada tabela. Quando você emite consultas, o Postgres-XC determina onde os dados de destino são armazenados e emite consultas correspondentes aos servidores que contêm os dados de destino.
Cidade
Citus é um substituto imediato para o PostgreSQL com recursos integrados de alta disponibilidade, como auto-sharding e replicação. O Citus fragmenta seu banco de dados e replica várias cópias de cada fragmento no cluster de nós de commodities. Se um nó no cluster ficar indisponível, o Citus redireciona de forma transparente quaisquer gravações ou consultas para um dos outros nós que hospedam uma cópia do estilhaço afetado.
Alguns recursos incluem:
-
Fragmentação lógica automática
-
Replicação integrada
-
Replicação com reconhecimento de data center para recuperação de desastres
-
Tolerância a falhas de consulta intermediária com balanceamento de carga avançado
Você pode aumentar o tempo de atividade de seus aplicativos em tempo real com tecnologia PostgreSQL e minimizar o impacto de falhas de hardware no desempenho. Você pode conseguir isso com ferramentas de alta disponibilidade integradas, minimizando a intervenção manual cara e propensa a erros.
PostgresXL
PostgresXL é uma solução de cluster multimestre sem compartilhamento que pode distribuir de forma transparente uma tabela em um conjunto de nós e executar consultas em paralelo com esses nós. Ele tem um componente adicional chamado Global Transaction Manager (GTM) para fornecer uma visão globalmente consistente do cluster.
PostgresXL é um cluster de banco de dados SQL de código aberto horizontalmente escalável, flexível o suficiente para lidar com diversas cargas de trabalho de banco de dados:
-
cargas de trabalho com uso intenso de gravação OLTP
-
Business Intelligence que requer paralelismo MPP
-
Armazenamento de dados operacional
-
Armazenamento de valores-chave
-
GIS Geoespacial
-
Ambientes de carga de trabalho mista
-
Ambientes hospedados por provedores multilocatários

Componentes:
-
Global Transaction Monitor (GTM):O Global Transaction Monitor garante a consistência das transações em todo o cluster.
-
Coordenador:O Coordenador gerencia as sessões do usuário e interage com o GTM e os nós de dados.
-
Nó de Dados:O Nó de Dados é onde os dados reais são armazenados.
Encerrando
Existem muitos outros produtos disponíveis para implementar seu ambiente de alta disponibilidade para PostgreSQL, mas você deve ter cuidado com:
-
Novos produtos, não testados o suficiente
-
Projetos descontinuados
-
Limitações
-
Custos de licenciamento
-
Implementações muito complexas
-
Soluções inseguras
Ao selecionar qual solução você usará, leve também em consideração sua infraestrutura. Se você tiver apenas um servidor de aplicativos, por mais que tenha configurado a alta disponibilidade dos bancos de dados, se o servidor de aplicativos falhar, você ficará inacessível. Você deve analisar bem os pontos únicos de falha na infraestrutura e tentar resolvê-los.
Tendo em conta estes pontos, pode encontrar uma solução de cluster de alta disponibilidade que se adapta às suas necessidades e requisitos, sem dores de cabeça. Se você estiver procurando por recursos de HA adicionais para seu banco de dados PG, confira esta postagem sobre a implantação do PostgreSQL para alta disponibilidade.
Para se manter atualizado sobre as soluções de gerenciamento de banco de dados e as melhores práticas, siga-nos no Twitter e LinkedIn e assine nossa newsletter.