Publiquei vários benchmarks comparando diferentes versões do PostgreSQL, como por exemplo a palestra sobre arqueologia de desempenho (avaliando o PostgreSQL 7.4 até 9.4), e todos esses benchmarks assumidos em ambiente fixo (hardware, kernel, …). O que é bom em muitos casos (por exemplo, ao avaliar o impacto no desempenho de um patch), mas na produção essas coisas mudam com o tempo – você obtém atualizações de hardware e, de tempos em tempos, recebe uma atualização com uma nova versão do kernel.
Para atualizações de hardware (melhor armazenamento, mais RAM, CPUs mais rápidas, …), o impacto geralmente é bastante fácil de prever e, além disso, as pessoas geralmente percebem que precisam avaliar o impacto analisando os gargalos na produção e talvez até testando o novo hardware primeiro .
Mas e as atualizações do kernel? Infelizmente, geralmente não fazemos muito benchmarking nesta área. A suposição é principalmente que os novos kernels são melhores que os mais antigos (mais rápidos, mais eficientes, dimensionados para mais núcleos de CPU). Mas é mesmo verdade? E quão grande é a diferença? Por exemplo, e se você atualizar um kernel de 3.0 para 4.7 - isso afetará o desempenho e, se sim, o desempenho melhorará ou não?
De tempos em tempos, recebemos relatórios sobre regressões sérias com uma versão específica do kernel ou melhorias repentinas entre as versões do kernel. Então, claramente, as versões do kernel podem afetar o desempenho.
Estou ciente de um único benchmark PostgreSQL comparando diferentes versões do kernel, feito em 2014 por Sergey Konoplev em resposta às recomendações para evitar kernels 3.0 – 3.8. Mas esse benchmark é bastante antigo (a última versão do kernel disponível ~ 18 meses atrás era 3.13, enquanto hoje temos 3.19 e 4.6), então decidi executar alguns benchmarks com kernels atuais (e PostgreSQL 9.6beta1).
PostgreSQL vs. versões do kernel
Mas primeiro, deixe-me discutir algumas diferenças significativas entre as políticas que governam os commits nos dois projetos. No PostgreSQL, temos o conceito de versões principais e secundárias – versões principais (por exemplo, 9.5) são lançadas aproximadamente uma vez por ano e incluem vários novos recursos. Versões secundárias (por exemplo, 9.5.2) incluem apenas correções de bugs e são lançadas a cada três meses (ou com mais frequência, quando um bug grave é descoberto). Portanto, não deve haver grandes alterações de desempenho ou comportamento entre versões secundárias, o que torna bastante seguro implantar versões secundárias sem testes extensivos.
Com as versões do kernel, a situação é muito menos clara. O kernel Linux também possui ramificações (por exemplo, 2.6, 3.0 ou 4.7), que não são de forma alguma iguais às “versões principais” do PostgreSQL, pois continuam recebendo novos recursos e não apenas correções de bugs. Não estou afirmando que a política de versionamento do PostgreSQL seja de alguma forma automaticamente superior, mas a consequência é que a atualização entre versões secundárias do kernel pode facilmente afetar significativamente o desempenho ou até mesmo introduzir bugs (por exemplo, 3.18.37 sofre com problemas de OOM devido a uma não correção de bugs comprometer-se).
É claro que as distribuições percebem esses riscos e geralmente bloqueiam a versão do kernel e fazem mais testes para eliminar novos bugs. Esta postagem, no entanto, usa kernels de longo prazo vanilla, disponíveis em www.kernel.org.
Referência
Existem muitos benchmarks que podemos usar - este post apresenta um conjunto de testes pgbench, ou seja, um benchmark OLTP bastante simples (tipo TPC-B). Pretendo fazer testes adicionais com outros tipos de benchmark (principalmente orientados para DWH/DSS) e os apresentarei neste blog no futuro.
Agora, de volta ao pgbench – quando digo “coleção de testes” quero dizer combinações de
- somente leitura x leitura-gravação
- tamanho do conjunto de dados – o conjunto ativo (não) se encaixa em buffers / RAM compartilhados
- contagem de clientes – cliente único versus muitos clientes (bloqueio/agendamento)
Os valores obviamente dependem do hardware usado, então vamos ver em qual hardware esta rodada de benchmarks estava sendo executada:
- CPU:Intel i5-2500k @ 3,3 GHz (3,7 GHz turbo)
- RAM:8 GB (DDR3 @ 1333 MHz)
- armazenamento:6x Intel SSD DC S3700 em RAID-10 (invasão Linux sw)
- sistema de arquivos:ext4 com agendador de E/S padrão (cfq)
Portanto, é a mesma máquina que usei para vários benchmarks anteriores - uma máquina bastante pequena, não exatamente a CPU mais nova etc., mas acredito que ainda seja um sistema "pequeno" razoável.
Os parâmetros de referência são:
- escalas de conjunto de dados:30, 300 e 1500 (ou seja, aproximadamente 450 MB, 4,5 GB e 22,5 GB)
- contagens de clientes:1, 4, 16 (a máquina tem 4 núcleos)
Para cada combinação houve 3 execuções somente leitura (15 minutos cada) e 3 execuções leitura-gravação (30 minutos cada). O script real que conduz o benchmark está disponível aqui (junto com resultados e outros dados úteis).
Observação :Se você tiver hardware significativamente diferente (por exemplo, unidades rotacionais), poderá ver resultados muito diferentes. Se você tem um sistema que gostaria de testar, me avise e eu o ajudarei com isso (supondo que eu possa publicar os resultados).
Versões do kernel
Em relação às versões do kernel, testei as versões mais recentes em todas as ramificações de longo prazo desde 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 e 4.7). Ainda existem muitos sistemas rodando em kernels 2.6.x, então é útil saber quanto desempenho você pode ganhar (ou perder) atualizando para um kernel mais novo. Mas eu tenho compilado todos os kernels por conta própria (ou seja, usando kernels vanilla, sem patches específicos de distribuição), e os arquivos de configuração estão no repositório git.
Resultados
Como de costume, todos os dados estão disponíveis no bitbucket, incluindo
- arquivo .config do kernel
- script de referência (run-pgbench.sh)
- Configuração do PostgreSQL (com alguns ajustes básicos para o hardware)
- Registros do PostgreSQL
- vários logs do sistema (dmesg, sysctl, mount, …)
Os gráficos a seguir mostram os tps médios para cada caso comparado – os resultados para as três execuções são bastante consistentes, com ~2% de diferença entre o mínimo e o máximo na maioria dos casos.
somente leitura
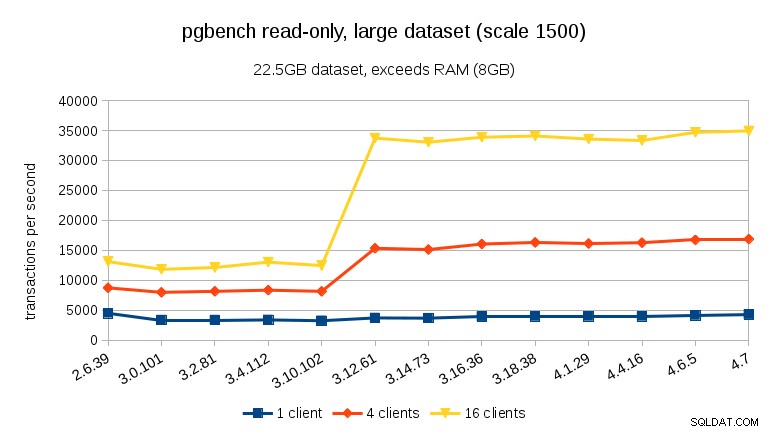
Para o menor conjunto de dados, há uma clara queda de desempenho entre 3,4 e 3,10 para todas as contagens de clientes. Os resultados para 16 clientes (4x o número de núcleos), porém mais do que se recupera em 3.12.
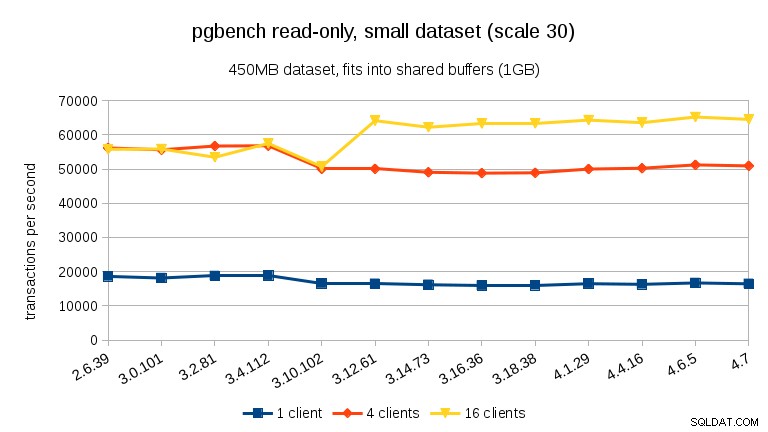
Para o conjunto de dados médio (se encaixa na RAM, mas não nos buffers compartilhados), podemos ver a mesma queda entre 3.4 e 3.10, mas não a recuperação em 3.12.
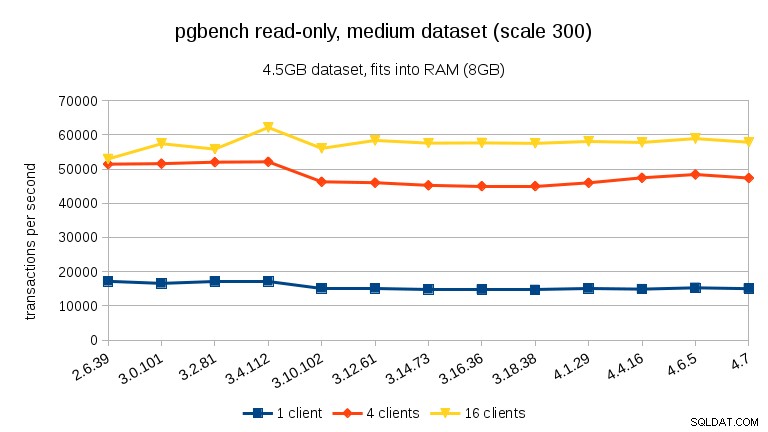
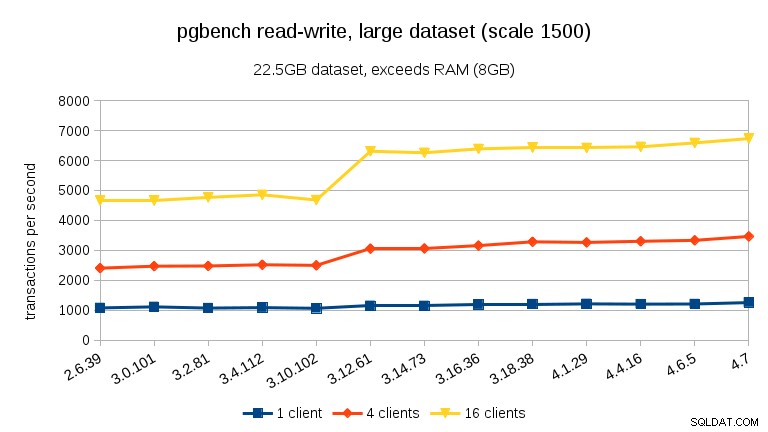
Para grandes conjuntos de dados (excedendo a RAM, tão fortemente limitado por E/S), os resultados são muito diferentes – não tenho certeza do que aconteceu entre 3.10 e 3.12, mas a melhoria de desempenho (particularmente para contagens de clientes mais altas) é bastante surpreendente.
ler-escrever
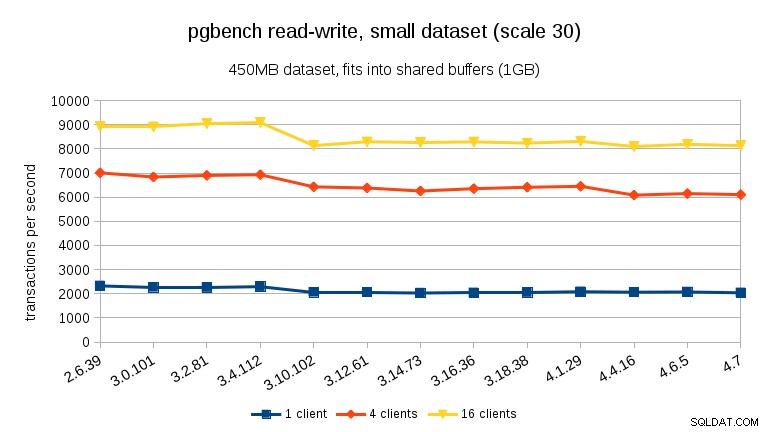
Para a carga de trabalho de leitura e gravação, os resultados são bastante semelhantes. Para os conjuntos de dados pequenos e médios, podemos observar a mesma queda de ~ 10% entre 3,4 e 3,10, mas infelizmente nenhuma recuperação em 3,12.
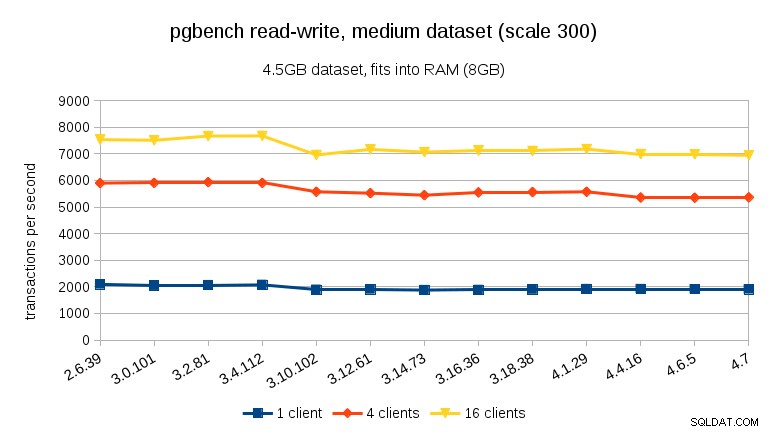
Para o grande conjunto de dados (novamente, significativamente limitado por E/S), podemos ver uma melhoria semelhante na versão 3.12 (não tão significativa quanto para a carga de trabalho somente leitura, mas ainda significativa):
Resumo
Não me atrevo a tirar conclusões de um único benchmark em uma única máquina, mas acho que é seguro dizer:
- O desempenho geral é bastante estável, mas podemos ver algumas mudanças significativas no desempenho (em ambas as direções).
- Com conjuntos de dados que cabem na memória (em shared_buffers ou pelo menos na RAM), vemos uma queda de desempenho mensurável entre 3,4 e 3,10. No teste somente leitura, isso se recupera parcialmente na versão 3.12 (mas apenas para muitos clientes).
- Com os conjuntos de dados excedendo a memória e, portanto, principalmente vinculados a E/S, não vemos nenhuma queda de desempenho, mas uma melhoria significativa na versão 3.12.
Quanto às razões pelas quais essas mudanças repentinas acontecem, não tenho certeza. Existem muitos commits possivelmente relevantes entre as versões, mas não tenho certeza de como identificar o correto sem testes extensivos (e demorados). Se você tiver outras ideias (por exemplo, está ciente de tais commits), me avise.



