Alguns anos atrás (no pgconf.eu 2014 em Madrid) eu apresentei uma palestra chamada “Performance Archaeology” que mostrou como o desempenho mudou nos últimos lançamentos do PostgreSQL. Fiz essa palestra porque acho que a visão de longo prazo é interessante e pode nos dar insights que podem ser muito valiosos. Para pessoas que realmente trabalham com código PostgreSQL como eu, é um guia útil para desenvolvimento futuro, e para usuários do PostgreSQL pode ajudar na avaliação de atualizações.
Então, decidi repetir este exercício e escrever algumas postagens no blog analisando o desempenho de várias versões do PostgreSQL. Na palestra de 2014, comecei com o PostgreSQL 7.4, que naquela época tinha cerca de 10 anos (lançado em 2003). Desta vez vou começar com o PostgreSQL 8.3, que tem cerca de 12 anos.
Por que não começar com o PostgreSQL 7.4 novamente? Existem cerca de três razões principais pelas quais decidi começar com o PostgreSQL 8.3. Em primeiro lugar, preguiça geral. Quanto mais antiga a versão, mais difícil pode ser construir usando as versões atuais do compilador etc. Em segundo lugar, leva tempo para executar benchmarks apropriados, especialmente com grandes quantidades de dados, então adicionar uma única versão principal pode adicionar facilmente alguns dias de tempo de máquina. Simplesmente não parecia valer a pena. E, finalmente, o 8.3 introduziu uma série de mudanças importantes – melhorias no autovacuum (ativado por padrão, processos de trabalho simultâneos, …), pesquisa de texto completo integrada ao núcleo, pontos de verificação espalhados e assim por diante. Então acho que faz todo o sentido começar com o PostgreSQL 8.3. Que foi lançado há cerca de 12 anos, então essa comparação realmente cobrirá um período de tempo mais longo.
Decidi comparar três tipos básicos de carga de trabalho – OLTP, análise e pesquisa de texto completo. Acho que o OLTP e a análise são escolhas bastante óbvias, pois a maioria dos aplicativos é uma mistura desses dois tipos básicos. A pesquisa de texto completo me permite demonstrar melhorias em tipos especiais de índices, que também são usados para indexar tipos de dados populares como JSONB, tipos usados pelo PostGIS etc.
Por que fazer isso?
Será que realmente vale o esforço? Afinal, fazemos benchmarks durante o desenvolvimento o tempo todo para mostrar que um patch ajuda e/ou que não causa regressões, certo? O problema é que geralmente são apenas benchmarks “parciais”, comparando dois commits específicos e geralmente com uma seleção bastante limitada de cargas de trabalho que achamos que podem ser relevantes. O que faz todo o sentido – você simplesmente não pode executar uma bateria completa de cargas de trabalho para cada confirmação.
De vez em quando (geralmente logo após o lançamento de uma nova versão principal do PostgreSQL) as pessoas executam testes comparando a nova versão com a anterior, o que é bom e eu encorajo você a executar esses benchmarks (seja algum tipo de benchmark padrão, ou algo específico para sua aplicação). Mas é difícil combinar esses resultados em uma visão de longo prazo, porque esses testes usam configurações e hardwares diferentes (geralmente um mais recente para a versão mais recente) e assim por diante. Portanto, é difícil fazer julgamentos claros sobre as mudanças em geral.
O mesmo se aplica ao desempenho do aplicativo, que é o “benchmark final”, é claro. Mas as pessoas podem não atualizar para todas as versões principais (às vezes podem pular algumas versões, por exemplo, de 9,5 a 12). E quando eles atualizam, geralmente é combinado com atualizações de hardware etc. Sem mencionar que os aplicativos evoluem com o tempo (novos recursos, complexidade adicional), a quantidade de dados e o número de usuários simultâneos crescem etc.
É isso que esta série de blogs tenta mostrar – tendências de longo prazo no desempenho do PostgreSQL para algumas cargas de trabalho básicas, para que nós – os desenvolvedores – tenhamos uma sensação calorosa e confusa sobre o bom trabalho ao longo dos anos. E para mostrar aos usuários que, embora o PostgreSQL seja um produto maduro neste momento, ainda há melhorias significativas em cada nova versão principal.
Não é meu objetivo usar esses benchmarks para comparação com outros produtos de banco de dados ou produzir resultados para atender a qualquer classificação oficial (como o TPC-H). Meu objetivo é simplesmente me educar como desenvolvedor PostgreSQL, talvez identificar e investigar alguns problemas e compartilhar as descobertas com outras pessoas.
Comparação justa?
Não acho que tais comparações de versões lançadas ao longo de 12 anos não possam ser totalmente justas, porque qualquer software é desenvolvido em um contexto específico – hardware é um bom exemplo, para um sistema de banco de dados. Se você olhar para as máquinas que você usou 12 anos atrás, quantos núcleos elas tinham, quanta memória RAM? Que tipo de armazenamento eles usaram?
Um servidor de médio porte típico em 2008 tinha talvez 8-12 núcleos, 16 GB de RAM e um RAID com algumas unidades SAS. Um servidor de médio porte típico hoje pode ter algumas dezenas de núcleos, centenas de GB de RAM e armazenamento SSD.
O desenvolvimento de software é organizado por prioridade – sempre há mais tarefas em potencial do que você tem tempo, então você precisa escolher tarefas com a melhor relação custo/benefício para seus usuários (especialmente aqueles que financiam o projeto, direta ou indiretamente). E em 2008 algumas otimizações provavelmente ainda não eram relevantes – a maioria das máquinas não tinha quantidades extremas de RAM, então otimizar para grandes buffers compartilhados ainda não valia a pena, por exemplo. E muitos dos gargalos da CPU foram ofuscados pela E/S, porque a maioria das máquinas tinha armazenamento de “ferrugem giratória”.
Nota:Claro, havia clientes usando máquinas muito grandes mesmo naquela época. Alguns usaram o Postgres da comunidade com vários ajustes, outros decidiram executar com um dos vários forks do Postgres com recursos adicionais (por exemplo, paralelismo massivo, consultas distribuídas, uso de FPGA etc.). E isso também influenciou o desenvolvimento da comunidade, é claro.
À medida que as máquinas maiores se tornaram mais comuns ao longo dos anos, mais pessoas podiam comprar máquinas com grandes quantidades de RAM e alta contagem de núcleos, alterando a relação custo/benefício. Os gargalos foram investigados e resolvidos, permitindo que as versões mais recentes tivessem um desempenho melhor.
Isso significa que um benchmark como esse é sempre um pouco injusto – ele favorecerá a versão mais antiga ou mais recente, dependendo da configuração (hardware, configuração). Eu tentei escolher parâmetros de hardware e configuração para que não seja tão ruim para versões mais antigas.
O ponto que estou tentando mostrar é que isso não significa que as versões mais antigas do PostgreSQL eram uma porcaria – é assim que o desenvolvimento de software funciona. Você aborda os gargalos que seus usuários provavelmente encontrarão, não os gargalos que eles podem encontrar em 10 anos.
Hardware
Prefiro fazer benchmarks em hardwares físicos aos quais tenho acesso direto, porque isso me permite controlar todos os detalhes, tenho acesso a todos os detalhes e assim por diante. Então, usei a máquina que tenho em nosso escritório – nada extravagante, mas espero que seja bom o suficiente para esse propósito.
- 2x E5-2620 v4 (16 núcleos, 32 threads)
- 64 GB de RAM
- Intel Optane 900P 280GB NVMe SSD (dados)
- 3 x 7,2k SATA RAID0 (espaço de tabela temporário)
- kernel 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
Também usei uma segunda máquina – bem menor –, com apenas 4 núcleos e 8 GB de RAM, que geralmente apresenta as mesmas melhorias/regressões, apenas menos pronunciadas.
pgbench
Como ferramenta de benchmarking utilizei o conhecido pgbench, utilizando a versão mais recente (do PostgreSQL 13) para testar todas as versões. Isso elimina possíveis vieses devido a otimizações feitas no pgbench ao longo do tempo, tornando os resultados mais comparáveis.
O benchmark testa vários casos diferentes, variando vários parâmetros, a saber:
escala
- pequeno – os dados cabem em buffers compartilhados, mostrando problemas de bloqueio etc.
- médio – dados maiores que os buffers compartilhados, mas cabem na RAM, geralmente limitados à CPU (ou possivelmente E/S para cargas de trabalho de leitura e gravação)
- grande – dados maiores que RAM, principalmente limitados por E/S
modos
- somente leitura – pgbench -S
- ler-escrever – pgbench -N
contagens de clientes
- 1, 4, 8, 16, 32, 64, 128, 256
- o número de threads do pgbench (-j) é ajustado de acordo
Resultados
Ok, vamos ver os resultados. Vou apresentar os resultados do armazenamento NVMe primeiro, depois mostrarei alguns resultados interessantes usando o armazenamento SATA RAID.
NVMe SSD/somente leitura
Para o pequeno conjunto de dados (que se encaixa totalmente em buffers compartilhados), os resultados somente leitura são assim:
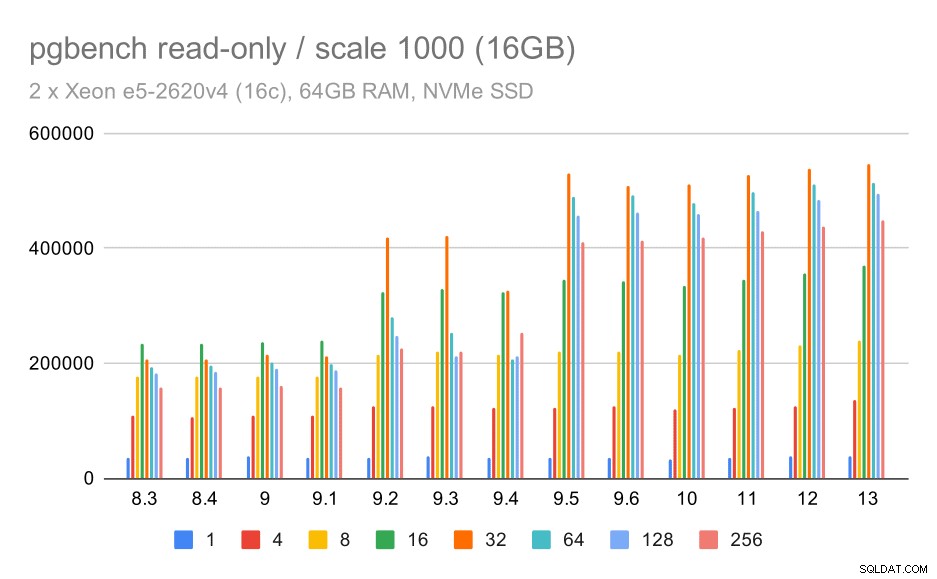
resultados do pgbench/somente leitura em conjunto de dados pequeno (escala 100, ou seja, 1,6 GB)
Claramente, houve um aumento significativo da taxa de transferência na versão 9.2, que continha várias melhorias de desempenho, por exemplo, atalho para bloqueio. A taxa de transferência para um único cliente realmente cai um pouco – de 47k tps para apenas cerca de 42k tps. Mas para contagens de clientes mais altas, a melhoria na versão 9.2 é bastante clara.
resultados do pgbench / somente leitura no conjunto de dados médio (escala 1000, ou seja, 16 GB)
Para o conjunto de dados médio (que é maior que os buffers compartilhados, mas ainda se encaixa na RAM), parece haver alguma melhoria no 9.2 também, embora não tão claro quanto acima, seguido por uma melhoria muito mais clara no 9.5 provavelmente graças a melhorias de escalabilidade de bloqueio .
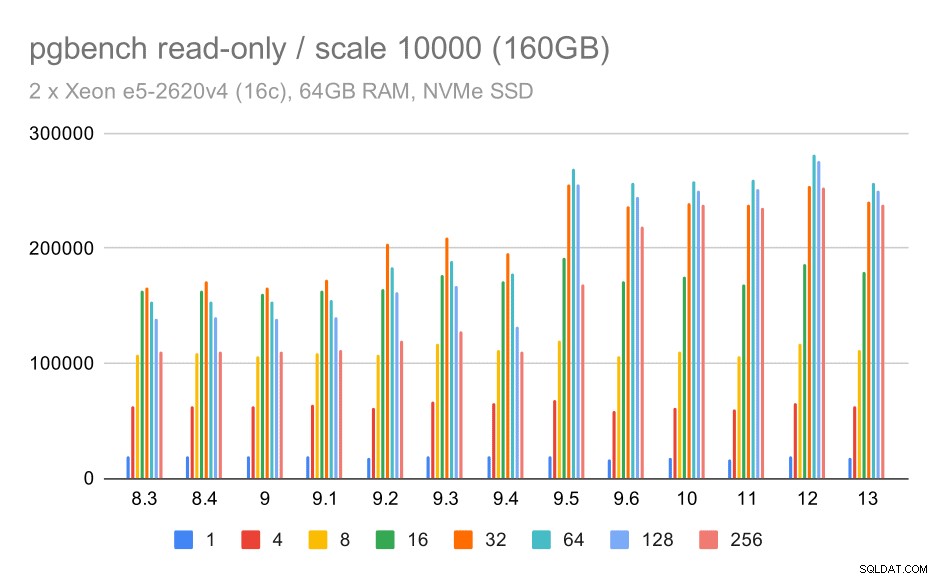
resultados do pgbench/somente leitura em grandes conjuntos de dados (escala 10000, ou seja, 160 GB)
No maior conjunto de dados, que é principalmente sobre a capacidade de utilizar o armazenamento com eficiência, também há alguma aceleração - provavelmente graças às melhorias do 9.5 também.
NVMe SSD/leitura-gravação
Os resultados de leitura e gravação também mostram algumas melhorias, embora não tão pronunciadas. No pequeno conjunto de dados, os resultados são assim:
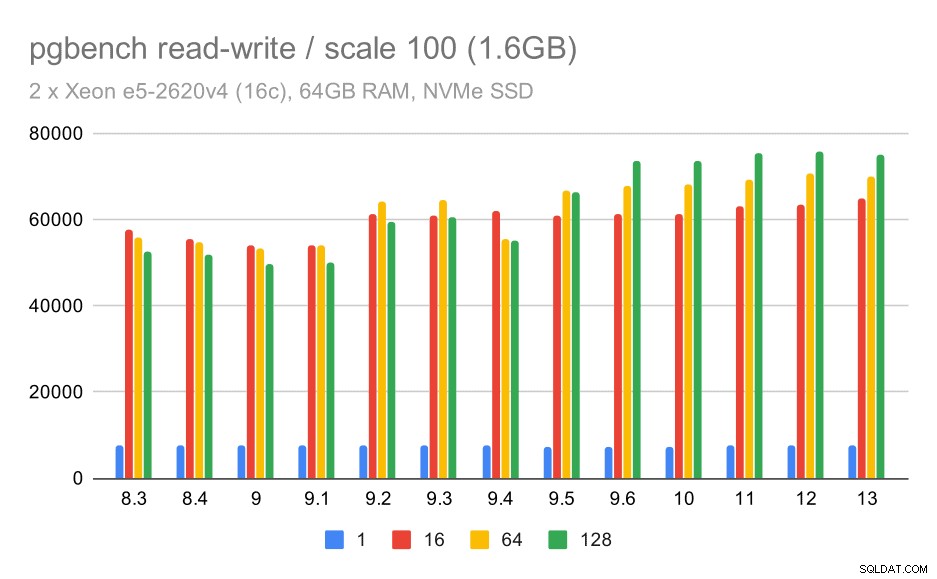
resultados do pgbench / leitura-gravação em conjunto de dados pequeno (escala 100, ou seja, 1,6 GB)
Portanto, uma melhoria modesta de cerca de 52k para 75k tps com número suficiente de clientes.
Para o conjunto de dados médio, a melhoria é muito mais clara – de cerca de 27k para 63k tps, ou seja, a taxa de transferência mais que dobra.
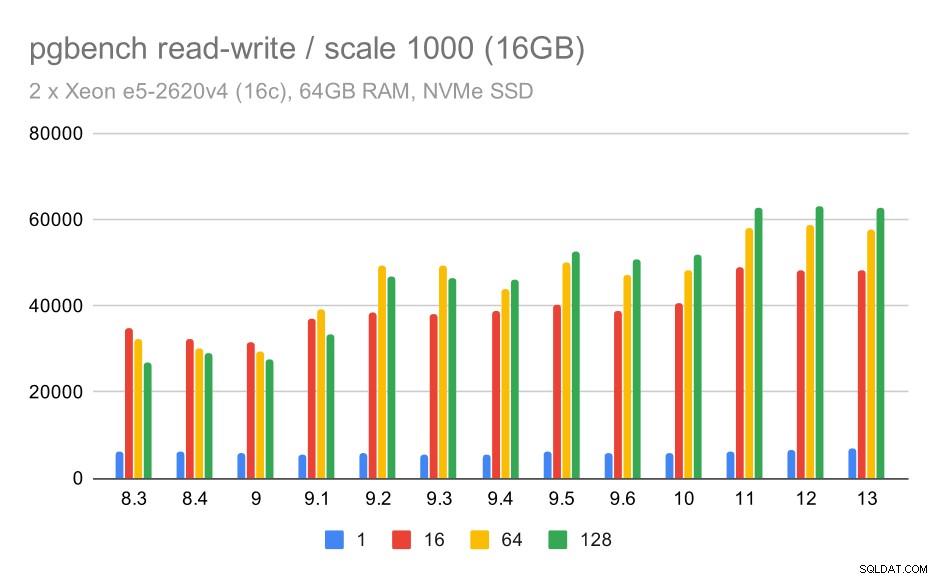
resultados do pgbench / leitura-gravação no conjunto de dados médio (escala 1000, ou seja, 16 GB)
Para o maior conjunto de dados, vemos uma melhoria geral semelhante, mas parece haver alguma regressão entre 9,5 e 11.
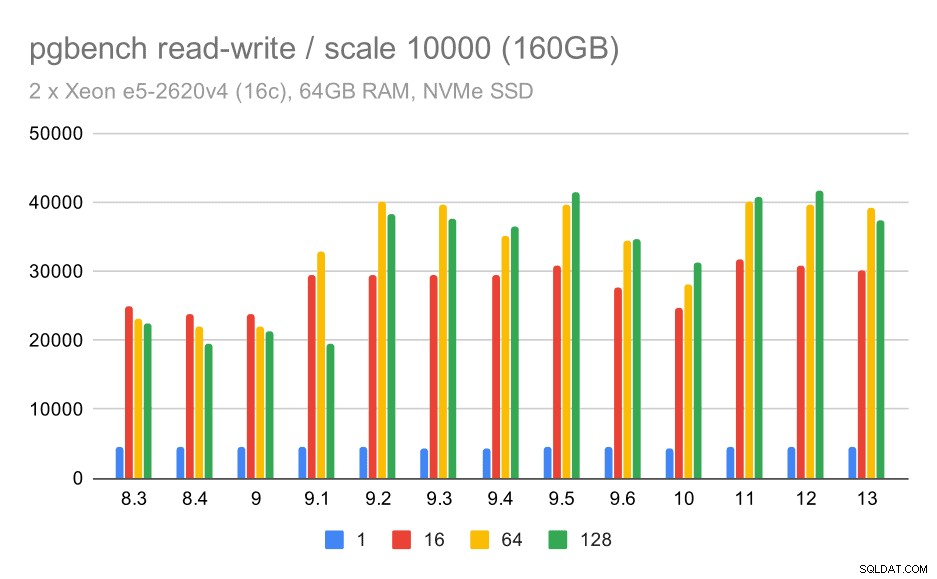
resultados do pgbench / leitura-gravação em grande conjunto de dados (escala 10000, ou seja, 160 GB)
SATA RAID/somente leitura
Para o armazenamento SATA RAID, os resultados somente leitura não são tão bons. Podemos ignorar os conjuntos de dados pequenos e médios, para os quais o sistema de armazenamento é irrelevante. Para o grande conjunto de dados, a taxa de transferência é um pouco barulhenta, mas parece realmente diminuir com o tempo – principalmente desde o PostgreSQL 9.6. Eu não sei qual é a razão para isso (nada nas notas de versão 9.6 se destaca como um candidato claro), mas parece algum tipo de regressão.
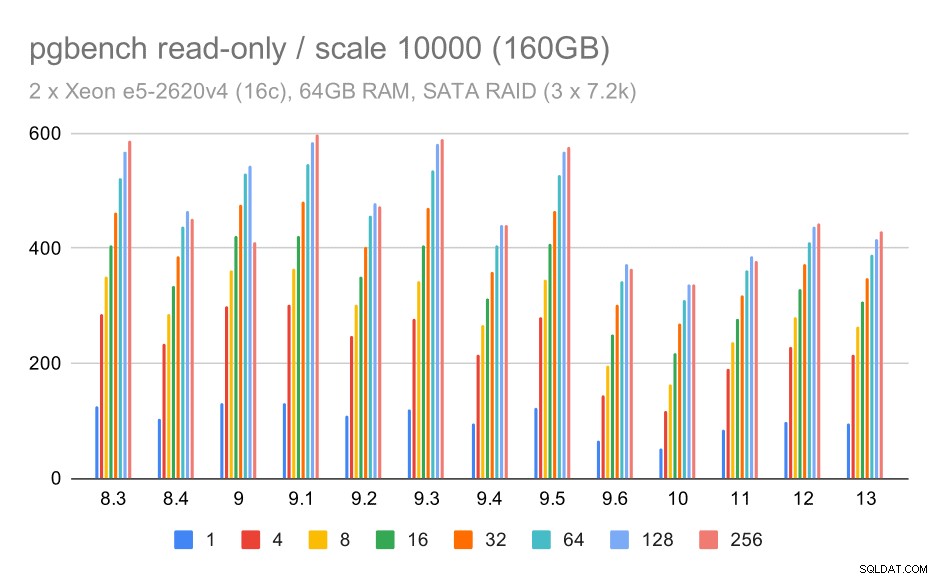
pgbench resulta em SATA RAID / somente leitura em grandes conjuntos de dados (escala 10000, ou seja, 160 GB)
SATA RAID/leitura-gravação
O comportamento de leitura e gravação parece muito melhor, no entanto. No conjunto de dados pequeno, a taxa de transferência aumenta de cerca de 600 tps para mais de 6.000 tps. Aposto que isso se deve a melhorias no commit de grupo em 9.1 e 9.2.
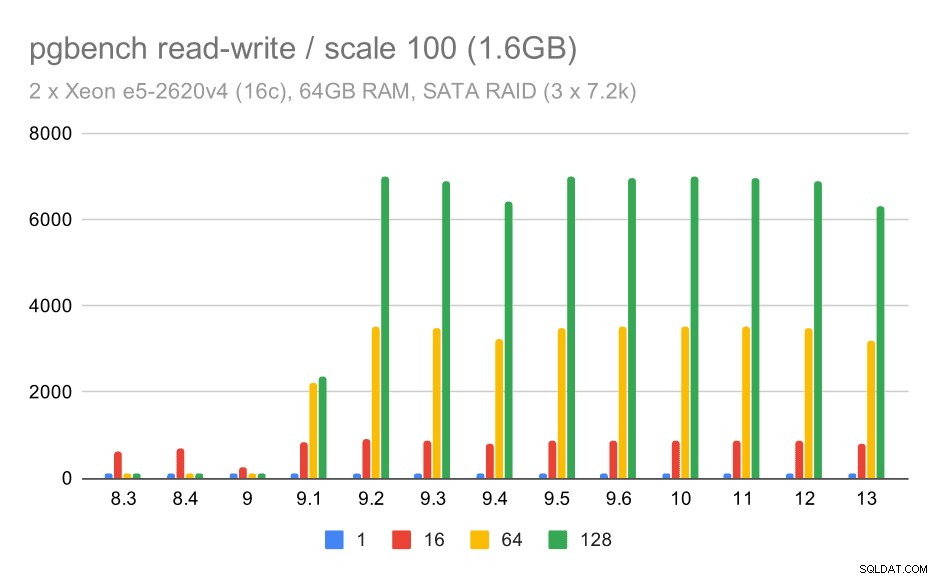
pgbench resulta em SATA RAID / read-write em um pequeno conjunto de dados (escala 100, ou seja, 1,6 GB)
Para as médias e grandes escalas podemos ver melhorias semelhantes – mas menores –, porque o armazenamento também precisa lidar com as solicitações de E/S para ler e gravar os blocos de dados. Para a escala média só precisamos fazer as gravações (como os dados cabem na RAM), para a grande escala também precisamos fazer as leituras – então o throughput máximo é ainda menor.
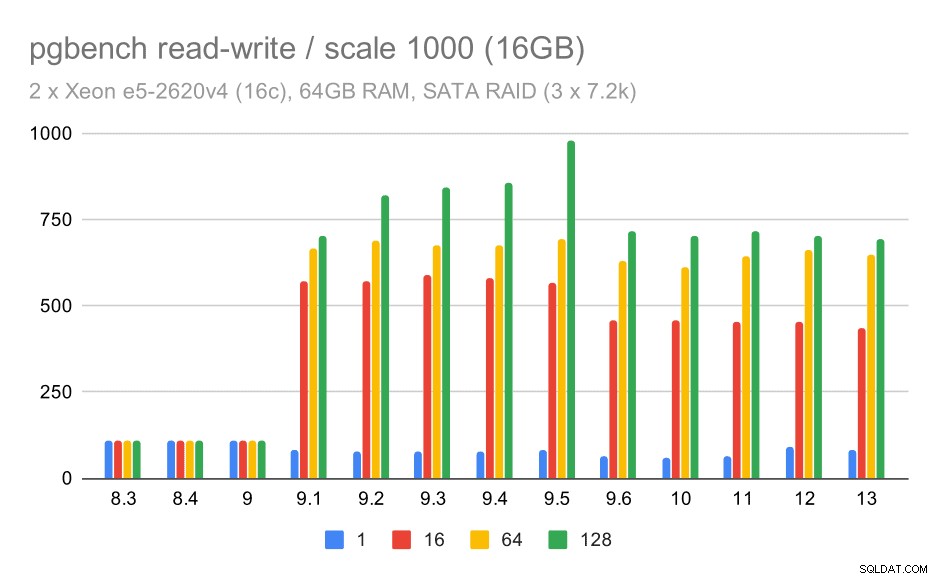
pgbench resulta em SATA RAID / leitura-gravação no conjunto de dados médio (escala 1000, ou seja, 16 GB)
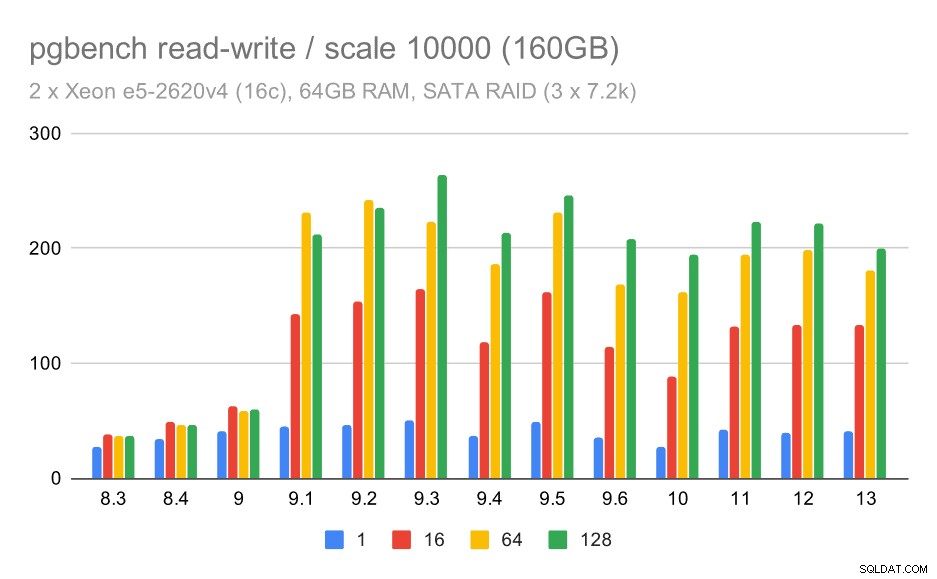
pgbench resulta em SATA RAID / read-write em grande conjunto de dados (escala 10000, ou seja, 160 GB)
Resumo e futuro
Para resumir isso, para a configuração do NVMe as conclusões parecem ser bastante positivas. Para a carga de trabalho somente leitura, há uma aceleração moderada em 9.2 e uma aceleração significativa em 9.5, graças a otimizações de escalabilidade, enquanto para a carga de trabalho de leitura e gravação, o desempenho melhorou cerca de 2x ao longo do tempo, em várias versões/etapas.
Com a configuração SATA RAID, as conclusões são um pouco confusas. No caso da carga de trabalho somente leitura, há muita variabilidade / ruído e possível regressão no 9.6. Para a carga de trabalho de leitura e gravação, há uma enorme aceleração no 9.1, onde a taxa de transferência aumentou repentinamente de 100 tps para cerca de 600 tps.
E quanto a melhorias em futuras versões do PostgreSQL? Não tenho uma ideia muito clara de qual será a próxima grande melhoria - tenho certeza de que outros hackers do PostgreSQL terão ideias brilhantes que tornarão as coisas mais eficientes ou permitirão aproveitar os recursos de hardware disponíveis. O patch para melhorar a escalabilidade com muitas conexões ou o patch para adicionar suporte para buffers WAL não voláteis são exemplos de tais melhorias. Podemos ver algumas melhorias radicais no armazenamento PostgreSQL (formato em disco mais eficiente, usando E/S direta etc.), indexação etc.