PostgreSQL é um projeto incrível e evolui a uma velocidade incrível. Vamos nos concentrar na evolução dos recursos de tolerância a falhas no PostgreSQL em todas as suas versões com uma série de postagens no blog. Este é o quarto post da série e falaremos sobre commit síncrono e seus efeitos na tolerância a falhas e confiabilidade do PostgreSQL.
Se você quiser testemunhar o progresso da evolução desde o início, confira as três primeiras postagens do blog da série abaixo. Cada postagem é independente, então você não precisa ler uma para entender a outra.
- Evolução da tolerância a falhas no PostgreSQL
- Evolução da tolerância a falhas no PostgreSQL:fase de replicação
- Evolução da tolerância a falhas no PostgreSQL:viagem no tempo
Compromisso síncrono
Por padrão, o PostgreSQL implementa a replicação assíncrona, onde os dados são transmitidos sempre que conveniente para o servidor. Isso pode significar perda de dados em caso de failover. É possível solicitar ao Postgres que exija um (ou mais) standbys para reconhecer a replicação dos dados antes do commit, isso é chamado de replicação síncrona (commit síncrono ) .
Com a replicação síncrona, o atraso da replicação diretamente afeta o tempo decorrido das transações no mestre. Com a replicação assíncrona, o mestre pode continuar a toda velocidade.
A replicação síncrona garante que os dados sejam gravados em pelo menos dois nós antes que o usuário ou aplicativo seja informado de que uma transação foi confirmada.
O usuário pode selecionar o modo de confirmação de cada transação , para que seja possível ter transações de confirmação síncronas e assíncronas em execução simultaneamente.
Isso permite trocas flexíveis entre desempenho e certeza de durabilidade da transação.
Configurando a confirmação síncrona
Para configurar a replicação síncrona no Postgres, precisamos configurar o
synchronous_commit parâmetro em postgresql.conf. O parâmetro especifica se a confirmação da transação aguardará que os registros WAL sejam gravados no disco antes que o comando retorne um sucesso indicação ao cliente. Os valores válidos estão ativados , remote_apply , remote_write , local e desativado . Discutiremos como as coisas funcionam em termos de replicação síncrona quando configurarmos o
synchronous_commit parâmetro com cada um dos valores definidos. Vamos começar com a documentação do Postgres (9.6):
Aqui entendemos o conceito de commit síncrono, como descrevemos na parte de introdução do post, você é livre para configurar a replicação síncrona, mas se não fizer isso, sempre há o risco de perder dados. Mas sem risco de criar inconsistência no banco de dados, ao contrário de desativar
fsync off – porém isso é assunto para outro post -. Por fim, concluímos que, se precisarmos, não queremos perder nenhum dado entre atrasos de replicação e queremos ter certeza de que os dados são gravados em pelo menos dois nós antes que o usuário/aplicativo seja informado de que a transação foi confirmada , precisamos aceitar perder algum desempenho. Vamos ver como diferentes configurações funcionam para diferentes níveis de sincronização. Antes de começarmos, vamos falar como o commit é processado pela replicação do PostgreSQL. O cliente executa consultas no nó mestre, as alterações são gravadas em um log de transações (WAL) e copiadas pela rede para o WAL no nó em espera. O processo de recuperação no nó de espera lê as alterações do WAL e as aplica aos arquivos de dados como durante a recuperação de falhas. Se o modo de espera estiver em espera ativa modo, os clientes podem emitir consultas somente leitura no nó enquanto isso está acontecendo. Para obter mais detalhes sobre como a replicação funciona, confira a postagem do blog de replicação nesta série.
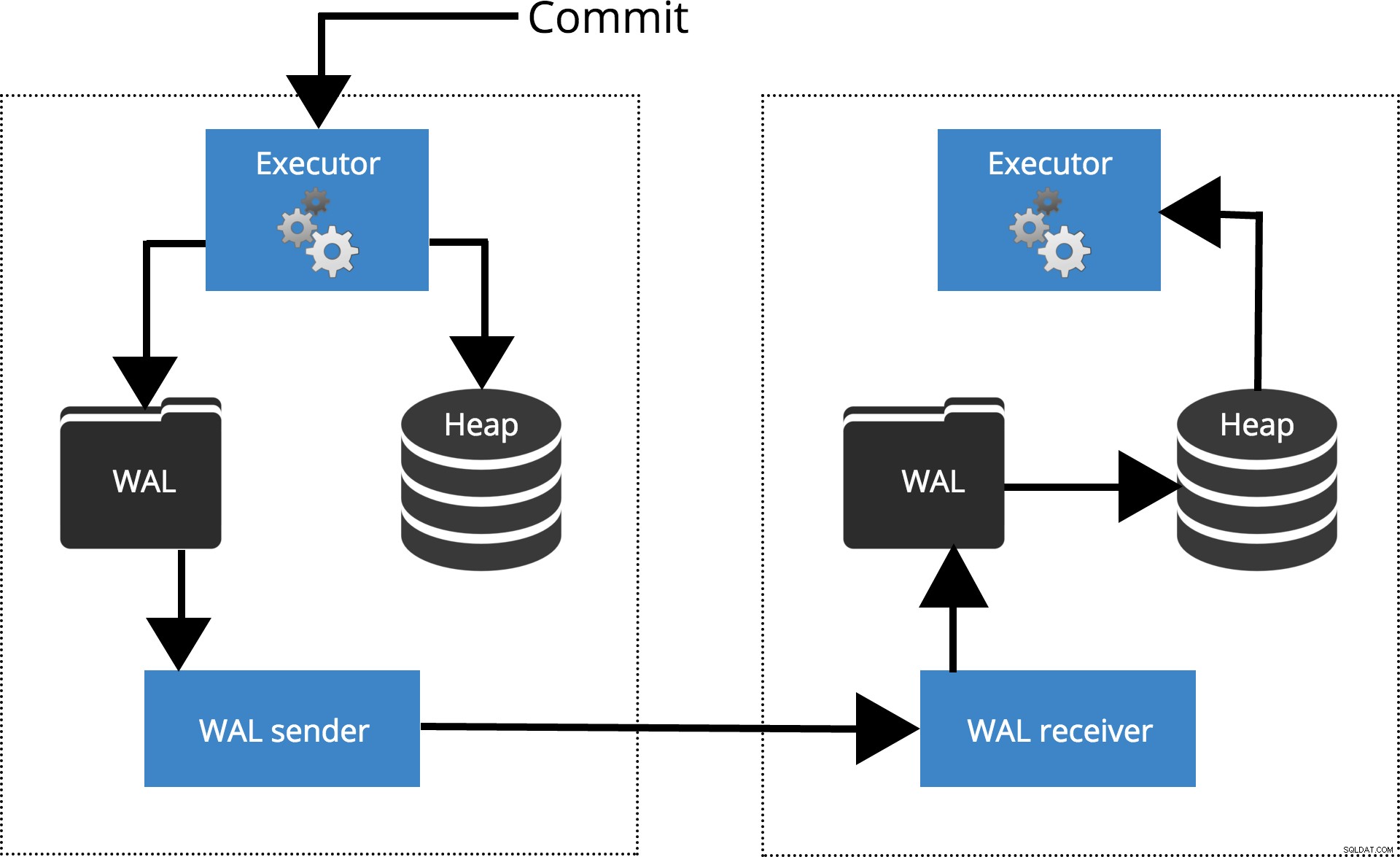
Fig.1 Como funciona a replicação
synchronous_commit =desativado
Quando definimos
sychronous_commit = off, o COMMIT não espera que o registro da transação seja liberado para o disco. Isso é destacado na Fig.2 abaixo. 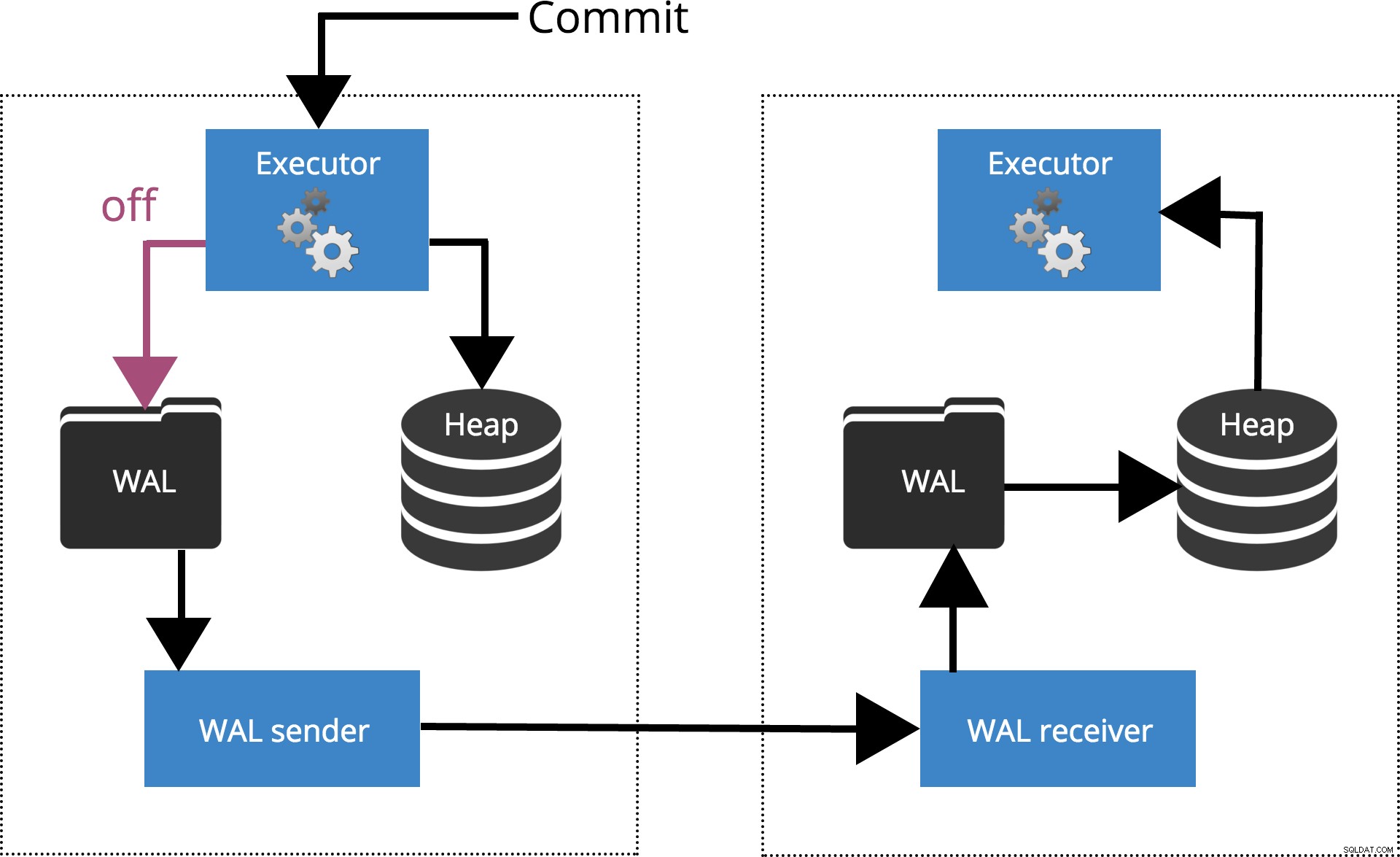
Fig.2 synchronous_commit =off
synchronous_commit =local
Quando definimos
synchronous_commit = local, o COMMIT espera até que o registro da transação seja liberado para o disco local. Isso é destacado na Fig.3 abaixo. 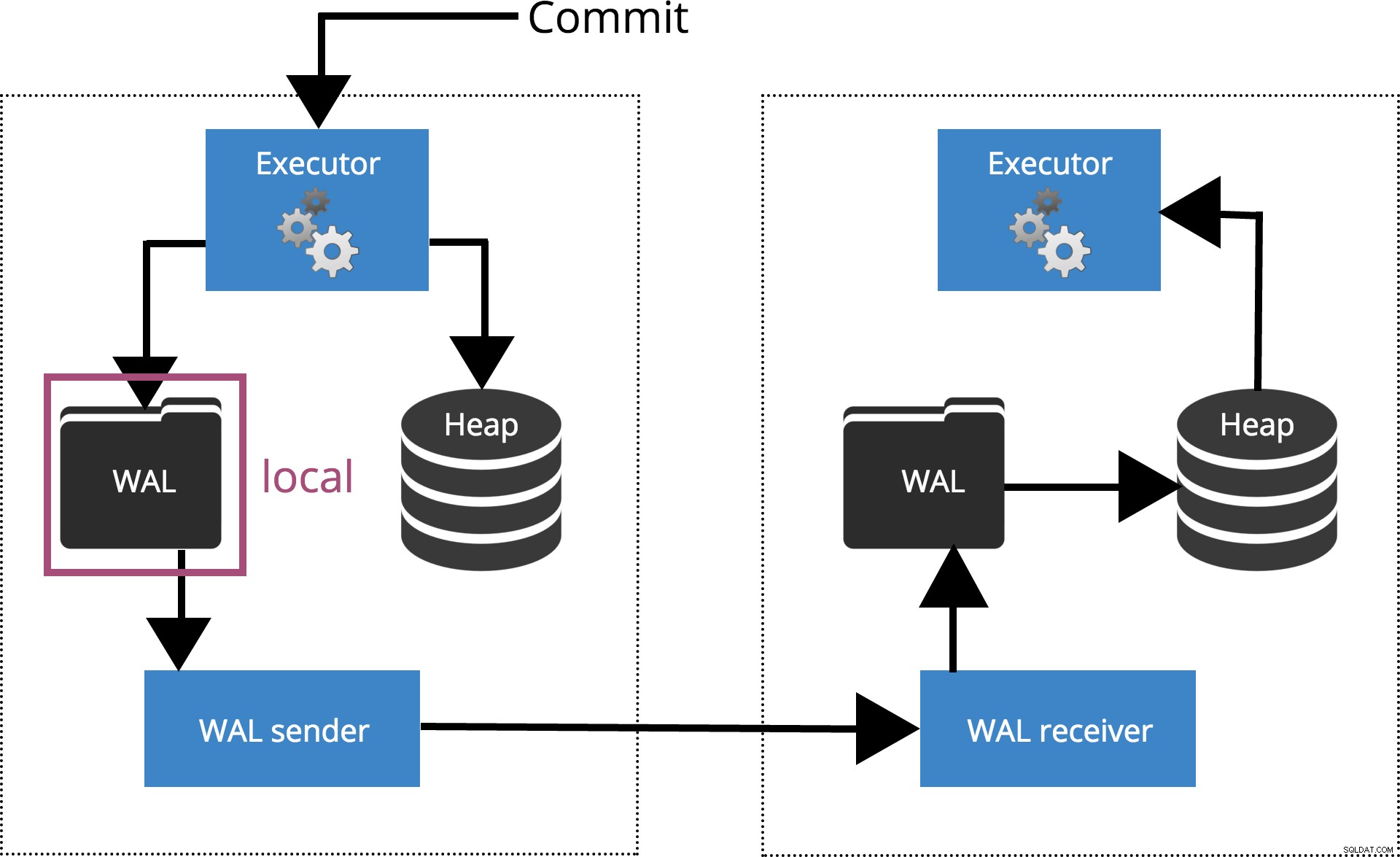
Fig.3 synchronous_commit =local
synchronous_commit =ativado (padrão)
Quando definimos
synchronous_commit = on, o COMMIT aguardará até que o(s) servidor(es) especificado(s) por synchronous_standby_names confirme se o registro da transação foi gravado com segurança no disco. Isso é destacado na Fig.4 abaixo. Observação: Quando
synchronous_standby_names está vazio, esta configuração se comporta da mesma forma que synchronous_commit = local . 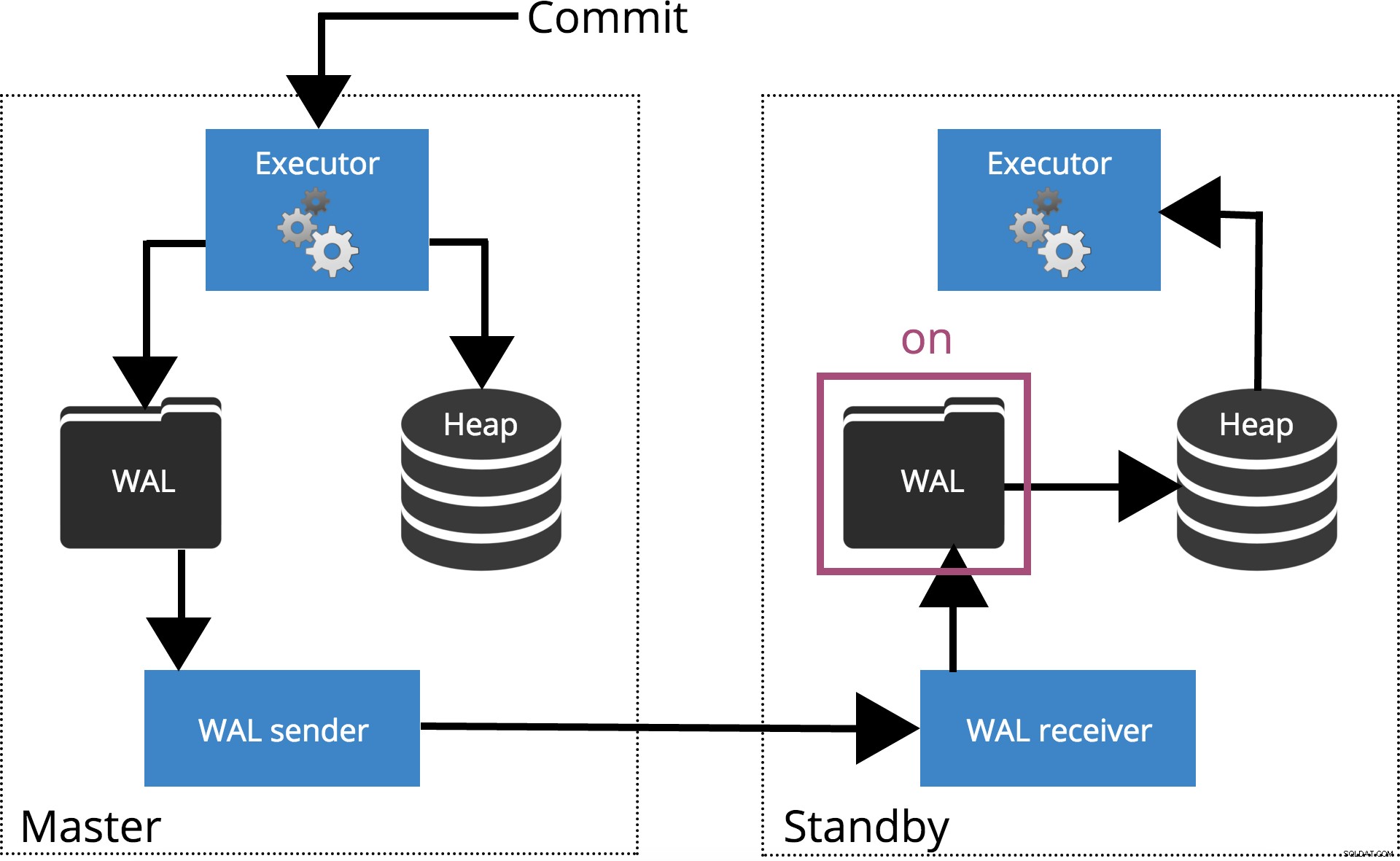
Fig.4 synchronous_commit =ativado
synchronous_commit =remote_write
Quando definimos
synchronous_commit = remote_write, o COMMIT aguardará até que o(s) servidor(es) especificado(s) por synchronous_standby_names confirme a gravação do registro da transação no sistema operacional, mas não necessariamente atingiu o disco. Isso é destacado na Fig.5 abaixo. 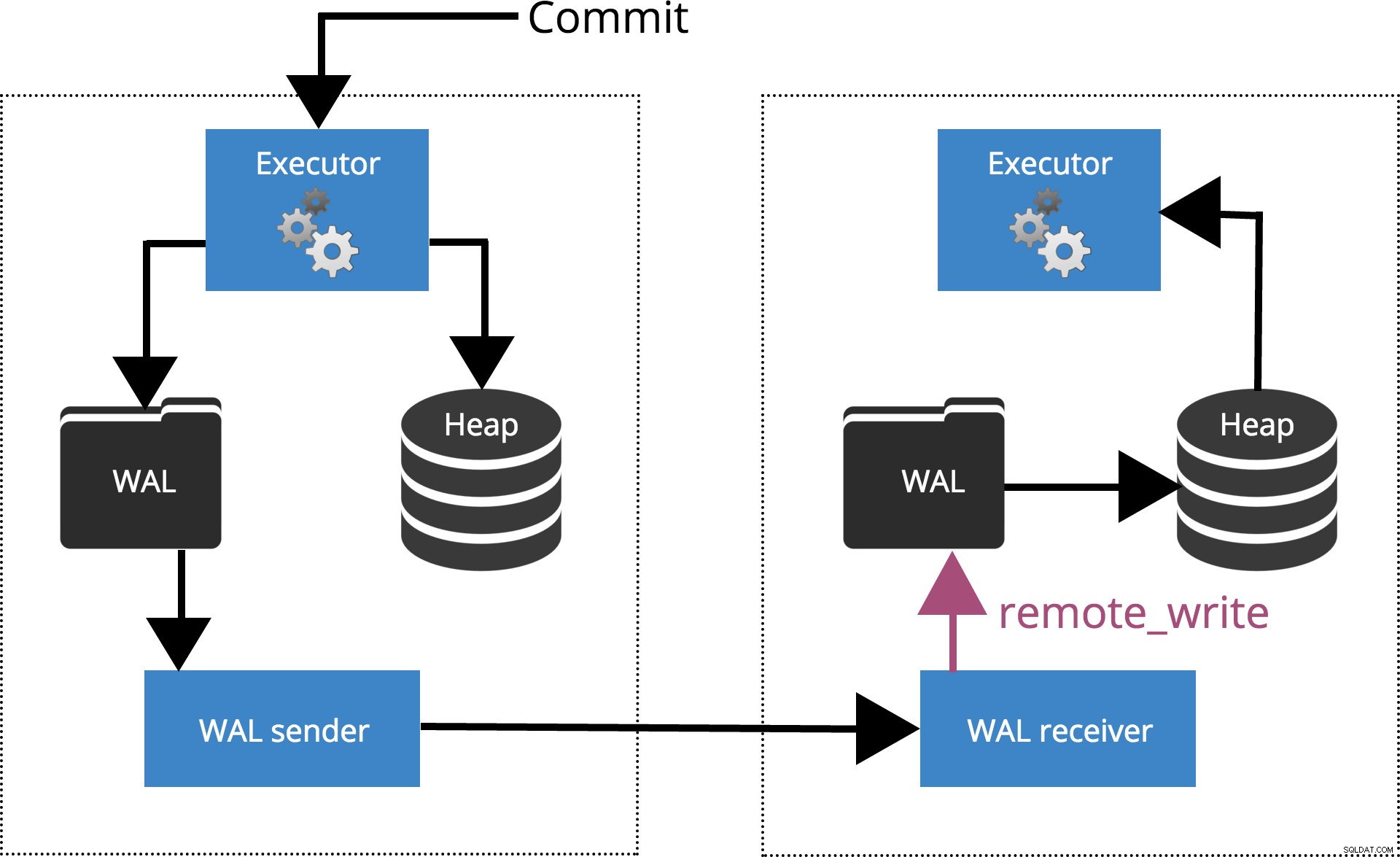
Fig.5 synchronous_commit =remote_write
synchronous_commit =remote_apply
Quando definimos
synchronous_commit = remote_apply, o COMMIT aguardará até que o(s) servidor(es) especificado(s) por synchronous_standby_names confirmar que o registro da transação foi aplicado ao banco de dados. Isso é destacado na Fig.6 abaixo. 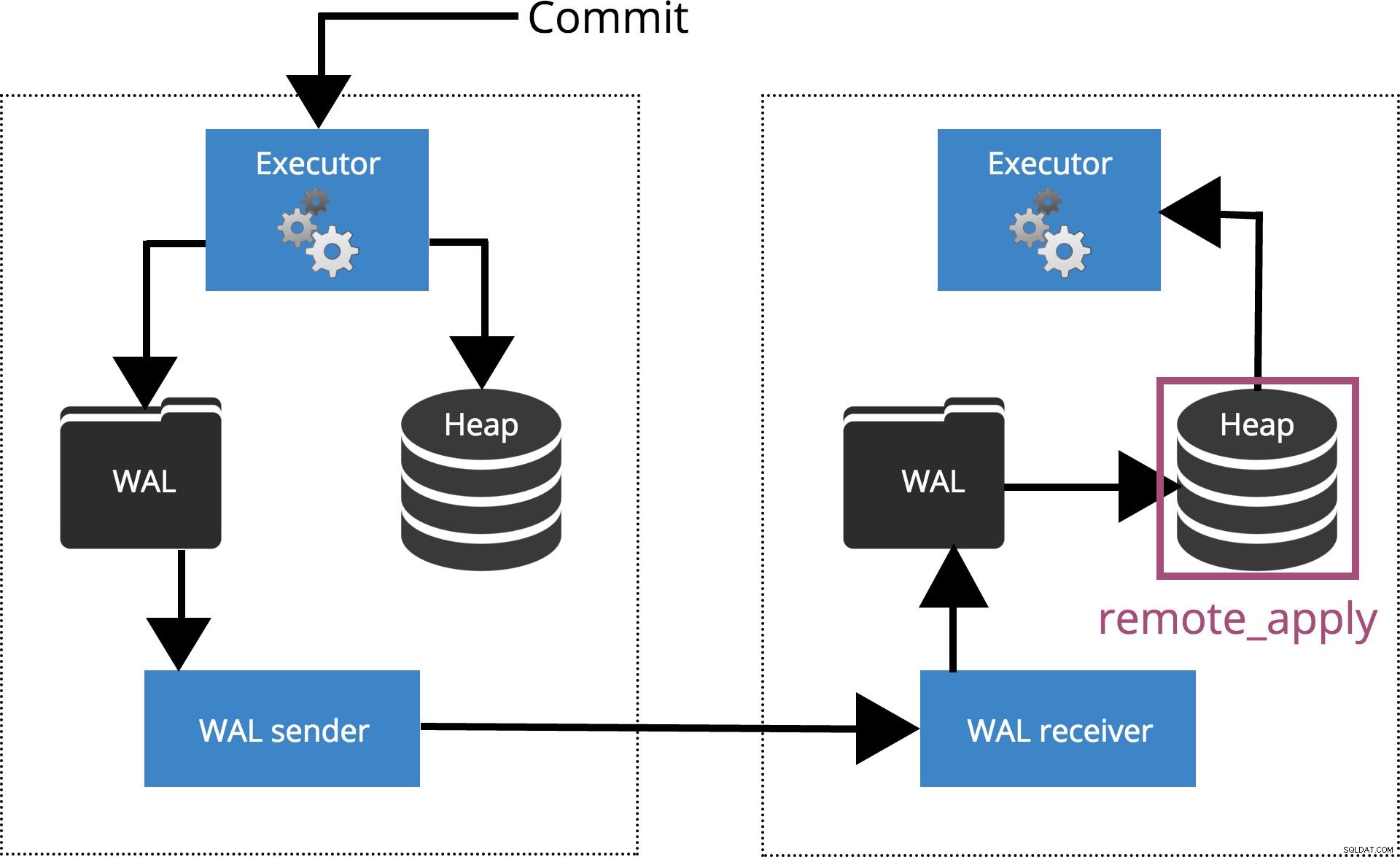
Fig.6 synchronous_commit =remote_apply
Agora, vamos ver sychronous_standby_names parâmetro em detalhes, que é referido acima ao definir synchronous_commit como on , remote_apply ou remote_write .
synchronous_standby_names =‘standby_name [, …]’
A confirmação síncrona aguardará a resposta de um dos standbys listados na ordem de prioridade. Isso significa que, se o primeiro standby estiver conectado e transmitindo, o commit síncrono sempre aguardará a resposta dele, mesmo que o segundo standby já tenha respondido. O valor especial de
* pode ser usado como stanby_name que corresponderá a qualquer espera conectada. synchronous_standby_names ='num (standby_name [, …])'
A confirmação síncrona aguardará a resposta de pelo menos
num número de standbys listados na ordem de prioridade. As mesmas regras acima se aplicam. Então, por exemplo, definindo synchronous_standby_names = '2 (*)' fará com que a confirmação síncrona aguarde a resposta de quaisquer 2 servidores em espera. synchronous_standby_names está vazio
Se este parâmetro estiver vazio como mostrado, ele altera o comportamento da configuração de
synchronous_commit para on , remote_write ou remote_apply para se comportar da mesma forma que local (ou seja, o COMMIT apenas aguardará a liberação para o disco local). Conclusão
Nesta postagem do blog, discutimos a replicação síncrona e descrevemos os diferentes níveis de proteção disponíveis no Postgres. Continuaremos com a replicação lógica na próxima postagem do blog.
Referências
Agradecimentos especiais ao meu colega Petr Jelinek por me dar a ideia das ilustrações.
Documentação do PostgreSQL
Livro de receitas de administração do PostgreSQL 9 – segunda edição