PostgreSQL é um dos bancos de dados que podem ser implantados via ClusterControl, juntamente com MySQL, MariaDB e MongoDB. O ClusterControl não apenas simplifica a implantação do cluster de banco de dados, mas também possui uma função de escalabilidade caso seu aplicativo cresça e exija essa funcionalidade.
Ao dimensionar seu banco de dados, seu aplicativo funcionará de forma muito mais suave e melhor caso a carga do aplicativo ou o tráfego aumente. Nesta postagem do blog, revisaremos as etapas sobre como fazer a implantação, bem como a expansão do PostgreSQL v13 com ClusterControl 1.8.2.
Implantação da interface do usuário (IU)
Existem duas formas de implantação no ClusterControl, interface de usuário da web (UI) e interface de linha de comando (CLI). O usuário tem a liberdade de escolher qualquer uma das opções de implantação dependendo de seu gosto e necessidade. Ambas as opções são fáceis de seguir e bem documentadas em nossa documentação. Nesta seção, passaremos pelo processo de implantação usando a primeira opção - UI da web.
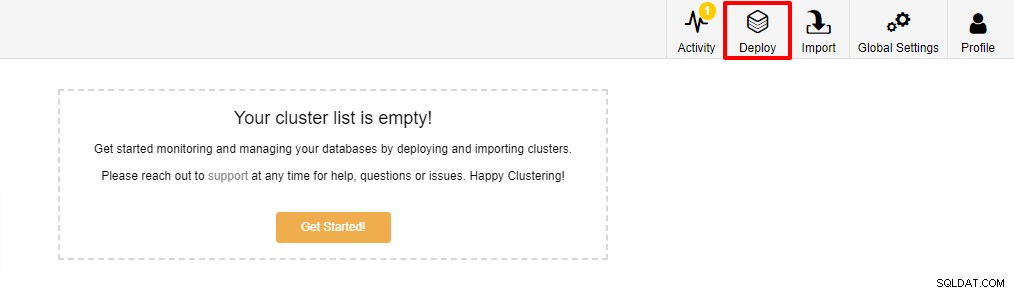
O primeiro passo é fazer login no seu ClusterControl e clicar em Deploy:
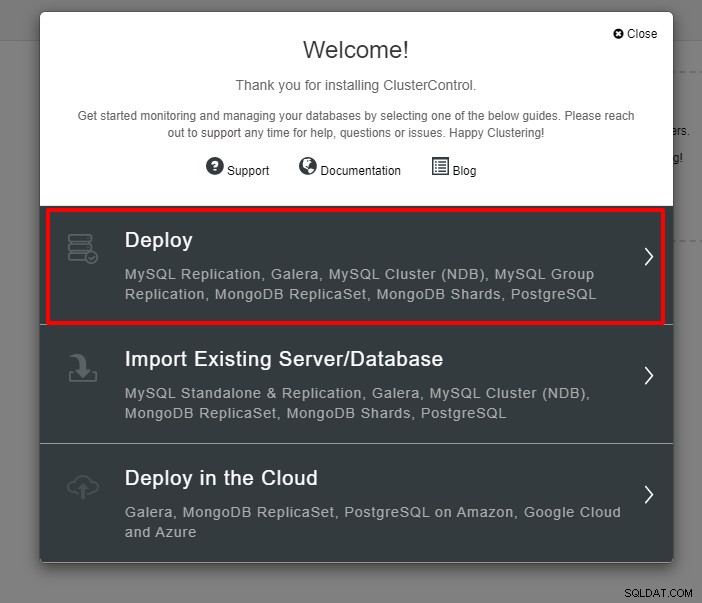
Você verá a captura de tela abaixo para a próxima etapa da implantação , escolha a guia PostgreSQL para continuar:
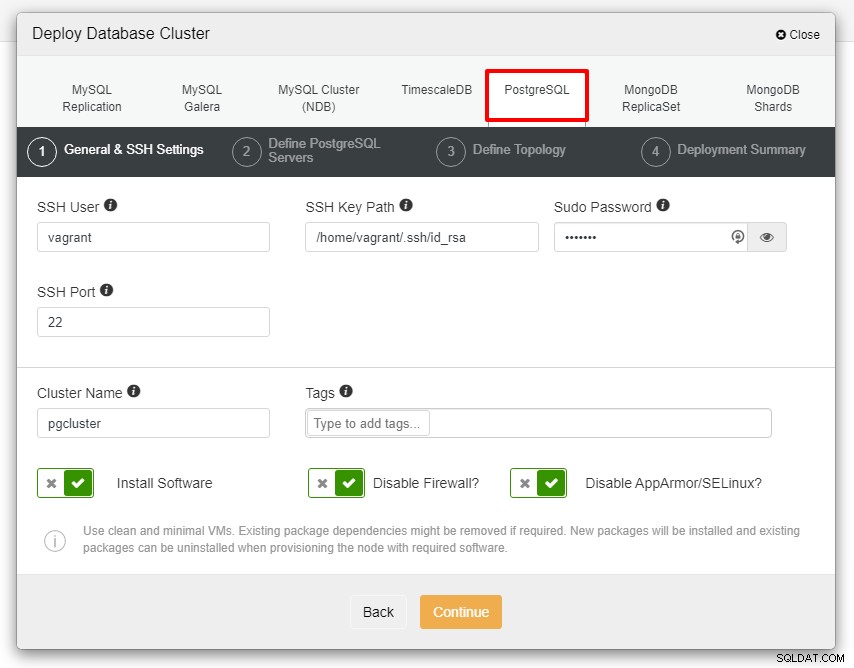
Antes de prosseguirmos, gostaria de lembrá-lo que a conexão entre o nó ClusterControl e os nós de bancos de dados devem ser sem senha. Antes da implantação, tudo o que precisamos fazer é gerar o ssh-keygen do nó ClusterControl e copiá-lo para todos os nós. Preencha a entrada para o usuário SSH, a senha do Sudo e o nome do cluster conforme sua necessidade e clique em Continuar.
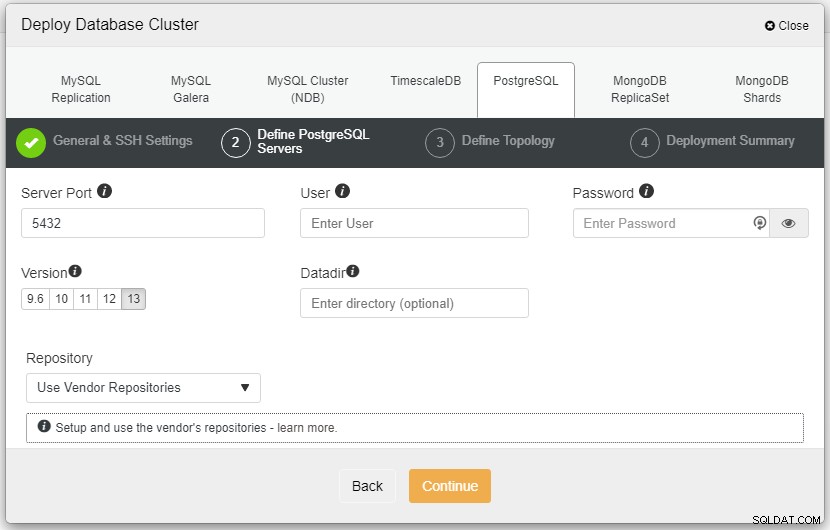
Na captura de tela acima, você precisará definir a Porta do Servidor (em caso você queira usar outros), o usuário que você gostaria, bem como a senha e certifique-se de escolher a Versão 13 que você deseja instalar.
 Autor da fotoDescrição da foto
Autor da fotoDescrição da foto
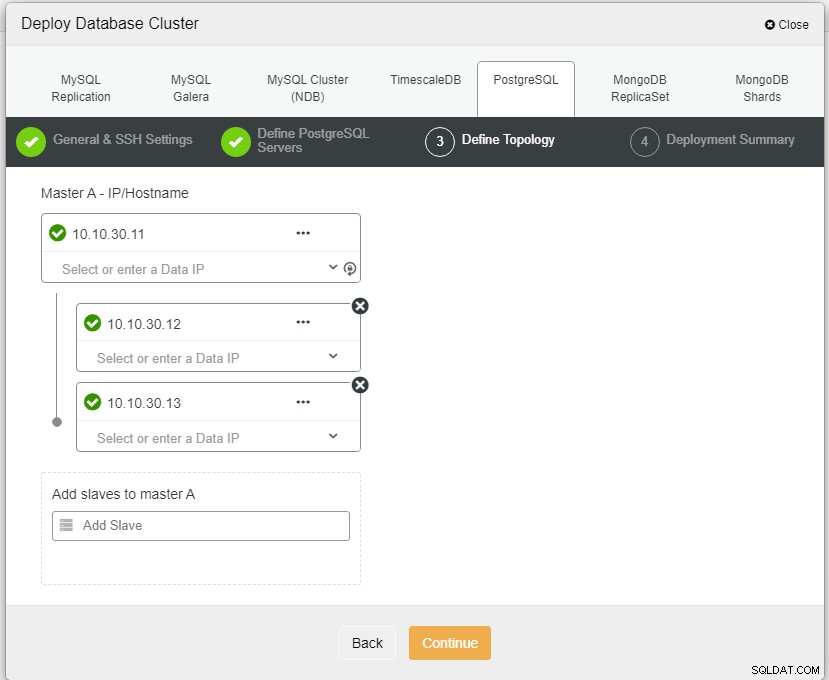
Aqui precisamos definir os servidores usando o nome do host ou o endereço IP, como neste caso 1 mestre e 2 escravos. A etapa final é escolher o modo de replicação para nosso cluster.
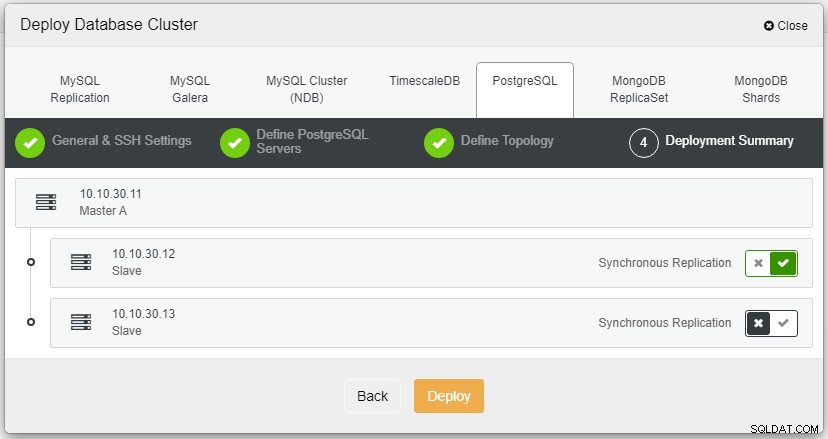
Depois de clicar em Deploy, o processo de implantação será iniciado e poderemos monitorar o progresso na guia Atividade.
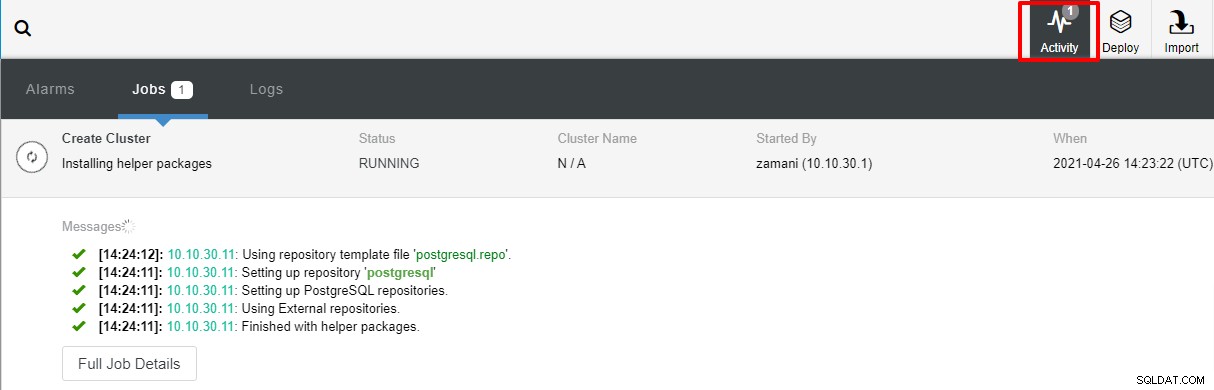
A implantação normalmente leva alguns minutos, o desempenho depende principalmente do rede e a especificação do servidor.

Agora que temos o PostgreSQL v13 instalado usando a GUI do ClusterControl, que é bastante simples .
Implantação do PostgreSQL da interface de linha de comando (CLI)
A partir do exposto, podemos ver que a implantação é bastante direta usando a interface do usuário da web. A observação importante é que todos os nós devem ter conexões SSH sem senha antes da implantação. Nesta seção, veremos como implantar usando a linha de comando ClusterControl CLI ou ferramentas “s9s”.
Assumimos que o ClusterControl foi instalado antes disso, vamos começar gerando o arquivo ssh-keygen. No nó ClusterControl, execute os seguintes comandos:
$ whoami
root
$ ssh-keygen -t rsa # generate the SSH key for the user
$ ssh-copy-id 10.10.40.11 # pg node1
$ ssh-copy-id 10.10.40.12 # pg node2
$ ssh-copy-id 10.10.40.13 # pg node3Uma vez que todos os comandos acima foram executados com sucesso, podemos verificar a conexão sem senha usando o seguinte comando:
$ ssh 10.10.40.11 "whoami" # make sure can ssh without passwordSe o comando acima for executado com sucesso, a implantação do cluster poderá ser iniciada a partir do servidor ClusterControl usando a seguinte linha de comando:
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.40.11?master;10.10.40.12?slave;10.10.40.13?slave" --provider-version='13' --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logLogo após executar o comando acima, você verá algo assim, o que significa que a tarefa começou a ser executada:
O cluster será criado em 3 nós de dados.
Verificando os parâmetros do trabalho.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.12: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.13: Checking ssh/sudo with credentials ssh_cred_job_6656.
…
…
This will take a few moments and the following message will be displayed once the cluster is deployed:
…
…
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Você também pode verificá-lo fazendo login no console da Web, usando o nome de usuário que você criou. Agora temos um cluster PostgreSQL implantado usando 3 nós. Se você quiser saber mais sobre o comando de implantação acima, aqui está a melhor referência para você.
Escalando o PostgreSQL com a interface do usuário do ClusterControl
O PostgreSQL é um banco de dados relacional e sabemos que escalar esse tipo de banco de dados não é fácil em comparação com um banco de dados não relacional. Atualmente, a maioria dos aplicativos precisa de escalabilidade para fornecer melhor desempenho e velocidade. Há muitas maneiras de implementar isso, dependendo de sua infraestrutura e ambiente.
A escalabilidade é um dos recursos que podem ser facilitados pelo ClusterControl e podem ser realizados tanto usando UI quanto CLI. Nesta seção, veremos como podemos escalar o PostgreSQL usando a interface do usuário do ClusterControl. O primeiro passo é fazer login na sua UI e escolher o cluster, uma vez que o cluster é escolhido você pode clicar na opção conforme a captura de tela abaixo:
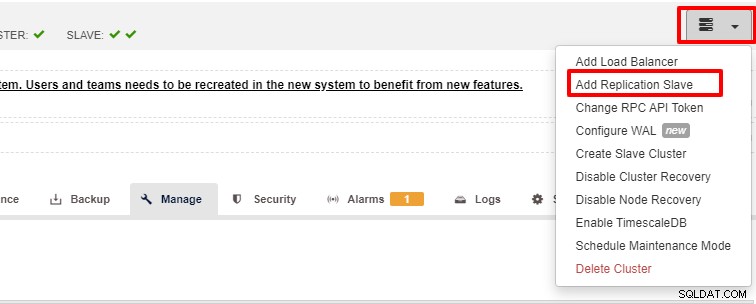
Depois de clicar em “Add Replication Slave”, você verá a seguinte página . Você pode escolher “Adicionar novo…” ou “Importar…” dependendo da sua situação. Neste exemplo vamos escolher a primeira opção:
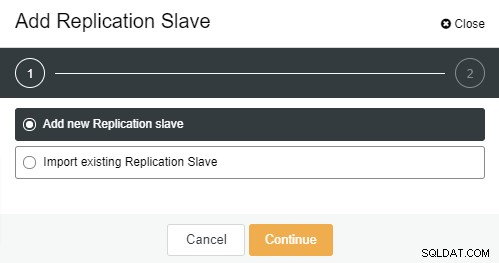
A tela a seguir será apresentada assim que você clicar nela:
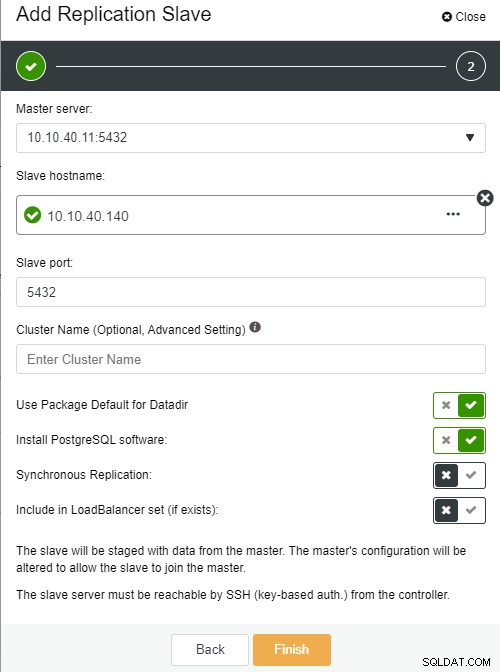 Autor da fotoDescrição da foto
Autor da fotoDescrição da foto
-
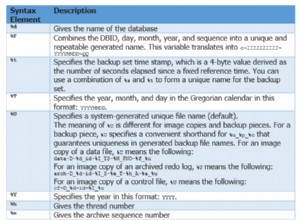
Nome do host escravo:o nome do host/endereço IP do novo escravo ou nó
-
Porta Escrava:a porta PostgreSQL do escravo, o padrão é 5432
-
Nome do cluster:o nome do cluster, você pode adicionar ou deixar em branco
-
Use Package Default for Datadir:você pode marcar esta opção ao desmarcar se quiser ter um local diferente para Datadir
-
Instalar o software PostgreSQL:você pode deixar esta opção marcada
-
Replicação Síncrona:você pode escolher o tipo de replicação que deseja neste
-
Incluir no conjunto LoadBalancer (se existir):esta opção deve ser marcada se você tiver o LoadBalancer configurado para o cluster
A nota importante aqui é que você precisa configurar o novo host escravo para ser sem senha antes de poder executar esta configuração. Depois que tudo estiver confirmado, podemos clicar no botão “Concluir” para concluir a configuração. Neste exemplo, adicionei o IP “10.10.40.140”.
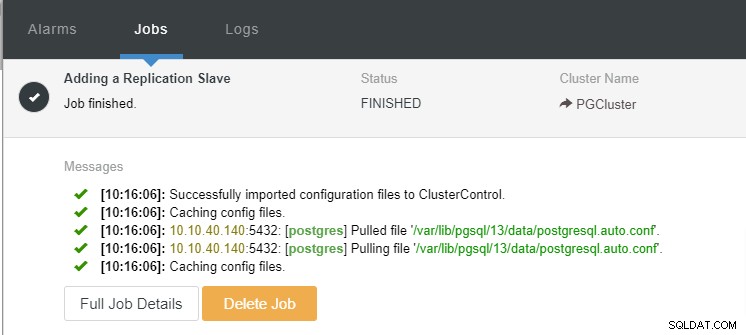
Agora podemos monitorar a atividade do trabalho e concluir a configuração. Para confirmar a configuração, podemos ir até a aba “Topologia” para ver o novo escravo:
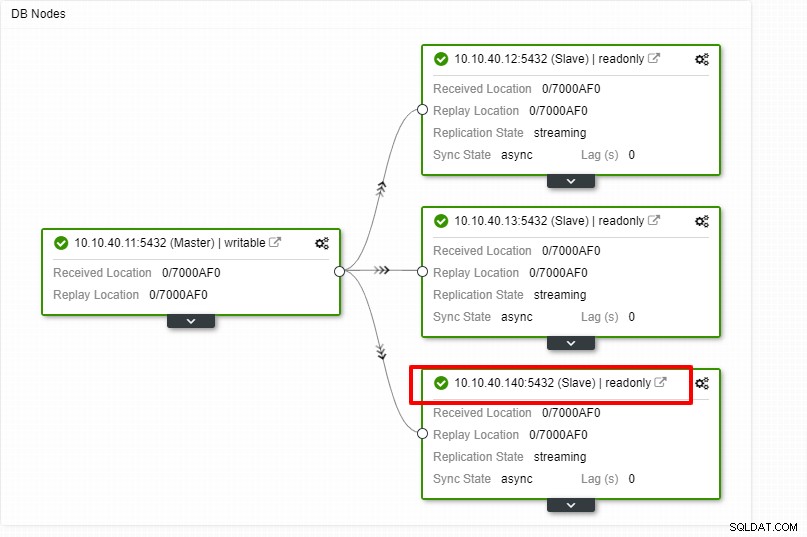
Escalando PostgreSQL com CLI ClusterControl
Para adicionar os novos nós ao cluster existente é muito simples usando a CLI. A partir do nó do controlador, você executa o comando a seguir. O primeiro comando é identificar o cluster ao qual gostaríamos de adicionar o novo nó:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED postgresql_single admin admins PGCluster All nodes are operational.Neste exemplo, podemos ver que o ID do nó é “1” para o nome do cluster “PGCluster”. Vamos ver a primeira opção de comando sobre como adicionar um novo nó ao cluster PostgreSQL existente:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.141?slave" --logA abreviação “--log” no final da linha nos permitirá ver qual é a tarefa atual em execução após o comando executado conforme abaixo:
Using SSH credentials from cluster.
Cluster ID is 1.
The username is 'root'.
Verifying job parameters.
Found a master candidate: 10.10.40.11:5432, adding 10.10.40.141:5432 as a slave.
Verifying job parameters.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_cluster_1_6245.
10.10.40.11:5432: Loading configuration file '/var/lib/pgsql/13/data/postgresql.conf'.
10.10.40.11:5432: wal_keep_segments is set to 0, increase this for safer replication.
…
…O próximo comando disponível que você pode usar é semelhante ao seguinte:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.142?slave" --waitAdicionar nó ao cluster
\ Job 9 RUNNING [▋ ] 5% Installing packagesObserve que há uma abreviação “--wait” na linha e a saída que você verá será exibida como acima. Depois que o processo for concluído, podemos confirmar os novos nós na guia "Visão geral" do cluster na interface do usuário:
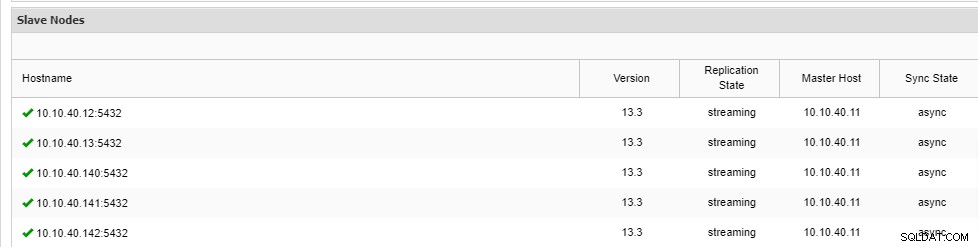
Conclusão
Nesta postagem do blog, analisamos duas opções de dimensionamento horizontal do PostgreSQL no ClusterControl. Como você pode notar, escalar o PostgreSQL é fácil com o ClusterControl. O ClusterControl não apenas pode fazer a escalabilidade, mas você também pode obter uma configuração de alta disponibilidade para seu cluster de banco de dados. Recursos como HAProxy, PgBouncer e Keepalived estão disponíveis e prontos para serem implementados em seu cluster sempre que você sentir a necessidade dessas opções. Com o ClusterControl, seu cluster de banco de dados é fácil de gerenciar e monitorado ao mesmo tempo.
Esperamos que esta postagem do blog ajude você a expandir sua configuração do PostgreSQL.