No mundo da tecnologia da informação, a automação não é novidade para a maioria de nós. Na verdade, a maioria das organizações o está usando para diversos fins, dependendo do tipo de trabalho e dos objetivos. Por exemplo, analistas de dados usam automação para gerar relatórios, administradores de sistema usam automação para tarefas repetitivas, como limpeza de espaço em disco, e desenvolvedores usam automação para automatizar seu processo de desenvolvimento.
Atualmente, existem muitas ferramentas de automação para TI disponíveis e podem ser escolhidas, graças à era DevOps. Qual é a melhor ferramenta? A resposta é um previsível ‘depende’, pois depende do que estamos tentando alcançar, bem como da configuração do nosso ambiente. Algumas das ferramentas de automação são Terraform, Bolt, Chef, SaltStack e uma muito moderna é o Ansible. O Ansible é um mecanismo de TI sem agente de código aberto que pode automatizar a implantação de aplicativos, o gerenciamento de configuração e a orquestração de TI. O Ansible foi fundado em 2012 e foi escrito na linguagem mais popular, Python. Ele usa um playbook para implementar toda a automação, onde todas as configurações são escritas em uma linguagem legível por humanos, YAML.
No post de hoje, vamos aprender como usar o Ansible para fazer a implantação do banco de dados Postgresql.
O que torna o Ansible especial?
A razão pela qual o ansible é usado principalmente por causa de seus recursos. Esses recursos são:
-
Qualquer coisa pode ser automatizada usando linguagem YAML simples e legível por humanos
-
Nenhum agente será instalado na máquina remota (arquitetura sem agente)
-
A configuração será enviada de sua máquina local para o servidor de sua máquina local (modelo push)
-
Desenvolvido usando Python (uma das linguagens populares atualmente usadas) e muitas bibliotecas podem ser escolhidas
-
Coleção de módulos Ansible cuidadosamente selecionados pela equipe de engenharia da Red Had
Como o Ansible funciona
Antes que o Ansible possa executar qualquer tarefa operacional nos hosts remotos, precisamos instalá-lo em um host que se tornará o nó controlador. Neste nó controlador, estaremos orquestrando quaisquer tarefas que gostaríamos de fazer nos hosts remotos também conhecidos como nós gerenciados.
O nó controlador deve ter o inventário dos nós gerenciados e o software Ansible para gerenciá-lo. Os dados necessários a serem usados pelo Ansible, como o nome do host ou o endereço IP do nó gerenciado, serão colocados dentro desse inventário. Sem um inventário adequado, o Ansible não poderia fazer a automação corretamente. Veja aqui para saber mais sobre o inventário.
O Ansible não tem agente e usa SSH para enviar as alterações, o que significa que não precisamos instalar o Ansible em todos os nós, mas todos os nós gerenciados devem ter python e quaisquer bibliotecas python necessárias instaladas. Tanto o nó do controlador quanto os nós gerenciados devem ser configurados como sem senha. Vale ressaltar que a conexão entre todos os nós do controlador e os nós gerenciados é boa e testada corretamente.
Para esta demonstração, provisionei 4 VMs Centos 8 usando o vagrant. Uma atuará como um nó controlador e as outras 2 VMs atuarão como os nós de banco de dados a serem implantados. Não entraremos em detalhes sobre como instalar o Ansible nesta postagem do blog, mas caso você queira ver o guia, sinta-se à vontade para visitar este link. Observe que estamos usando 3 nós para configurar uma topologia de replicação de streaming, com um nó primário e 2 nós de espera. Atualmente, muitos bancos de dados de produção estão em uma configuração de alta disponibilidade e uma configuração de 3 nós é comum.
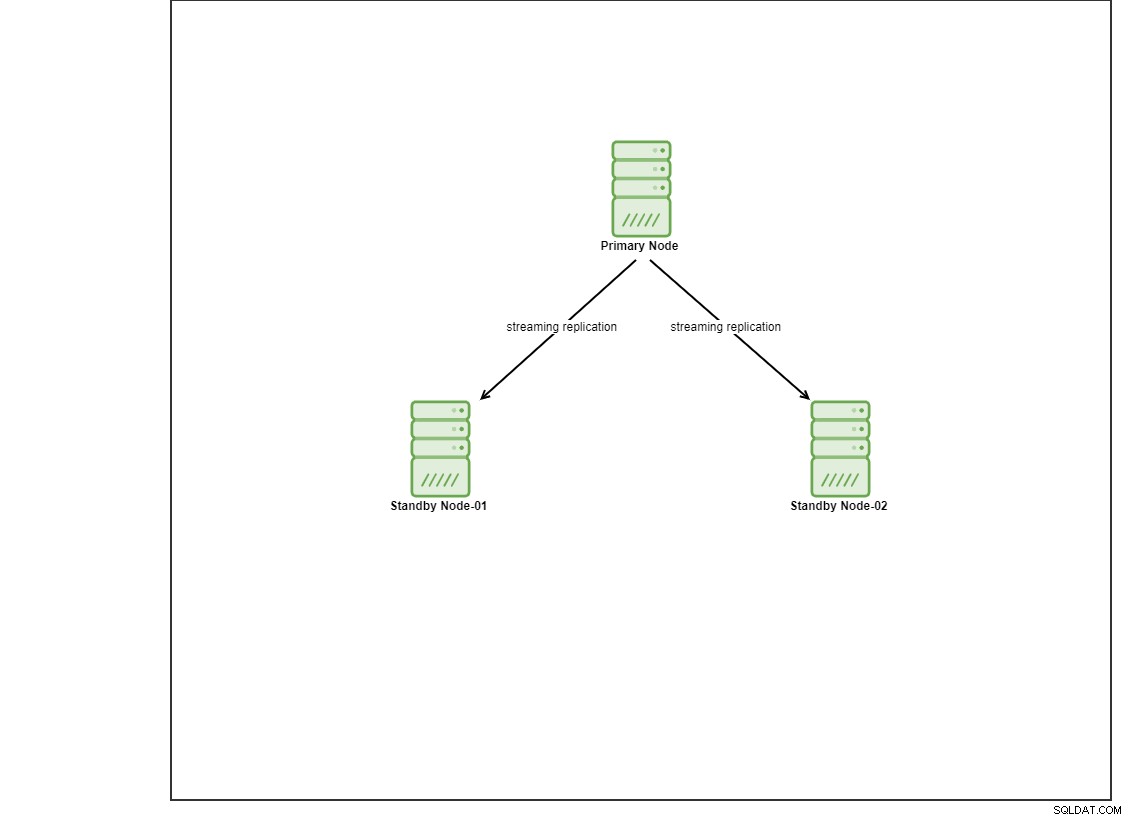
Instalando o PostgreSQL
Existem várias maneiras de instalar o PostgreSQL usando o Ansible. Hoje, usarei o Ansible Roles para atingir esse objetivo. Ansible Roles em poucas palavras é um conjunto de tarefas para configurar um host para servir a um determinado propósito, como configurar um serviço. As funções do Ansible são definidas usando arquivos YAML com uma estrutura de diretórios predefinida disponível para download no portal do Ansible Galaxy.
O Ansible Galaxy, por outro lado, é um repositório para Ansible Roles que estão disponíveis para serem colocados diretamente em seus Playbooks para otimizar seus projetos de automação.
Para esta demonstração, escolhi os papéis que foram mantidos por dudefellah. Para que possamos utilizar essa função, precisamos baixá-la e instalá-la no nó do controlador. A tarefa é bastante simples e pode ser feita executando o seguinte comando, desde que o Ansible tenha sido instalado no nó do controlador:
$ ansible-galaxy install dudefellah.postgresqlVocê deverá ver o seguinte resultado assim que a função for instalada com sucesso no nó do controlador:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfullyPara instalarmos o PostgreSQL usando esta função, há alguns passos que precisam ser feitos. Aí vem o Playbook Ansible. O Ansible Playbook é onde podemos escrever o código Ansible ou uma coleção dos scripts que gostaríamos de executar nos nós gerenciados. O Ansible Playbook usa YAML e consiste em uma ou mais reproduções executadas em uma ordem específica. Você pode definir hosts, bem como um conjunto de tarefas que gostaria de executar nesses hosts atribuídos ou nós gerenciados.
Todas as tarefas serão executadas como o usuário ansible que fez login. Para que possamos executar as tarefas com um usuário diferente, incluindo o 'root', podemos usar o torne. Vamos dar uma olhada no pg-play.yml abaixo:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Como você pode ver, eu defini os hosts como pgcluster e uso o torne para que o Ansible execute as tarefas com o privilégio sudo. O usuário vagrant já está no grupo sudoer. Também defini o papel que instalei dudefellah.postgresql. pgcluster foi definido no arquivo hosts que criei. Caso você se pergunte como é, você pode dar uma olhada abaixo:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleAlém disso, criei outro arquivo personalizado (custom_var.yml) no qual incluí todas as configurações e configurações do PostgreSQL que gostaria de implementar. Os detalhes para o arquivo personalizado são os seguintes:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }Para executar a instalação, basta executar o seguinte comando. Você não poderá executar o comando ansible-playbook sem o arquivo playbook criado (no meu caso é pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostDepois de executar este comando, ele executará algumas tarefas definidas pela função e mostrará esta mensagem se o comando foi executado com sucesso:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12Depois que o ansible completou as tarefas, loguei no slave (n2), parei o serviço PostgreSQL, retirei o conteúdo do diretório de dados (/var/lib/pgsql/13/data/) e execute o seguinte comando para iniciar a tarefa de backup:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |Também podemos verificar o status da replicação em espera usando o seguinte comando após iniciarmos o serviço PostgreSQL:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyComo você pode ver, há muitos trabalhos que precisam ser feitos para que possamos configurar a replicação para o PostgreSQL, embora tenhamos automatizado algumas das tarefas. Vamos ver como isso pode ser feito com o ClusterControl.
Implantação do PostgreSQL usando a GUI do ClusterControl
Agora que sabemos como implantar o PostgreSQL usando o Ansible, vamos ver como podemos implantar usando o ClusterControl. ClusterControl é um software de gerenciamento e automação para clusters de banco de dados, incluindo MySQL, MariaDB, MongoDB e TimescaleDB. Ele ajuda a implantar, monitorar, gerenciar e dimensionar seu cluster de banco de dados. Existem duas maneiras de implantar o banco de dados, nesta postagem do blog mostraremos como implantá-lo usando a interface gráfica do usuário (GUI) supondo que você já tenha o ClusterControl instalado em seu ambiente.
O primeiro passo é fazer login no seu ClusterControl e clicar em Deploy:
Você verá a captura de tela abaixo para a próxima etapa da implantação , escolha a guia PostgreSQL para continuar:
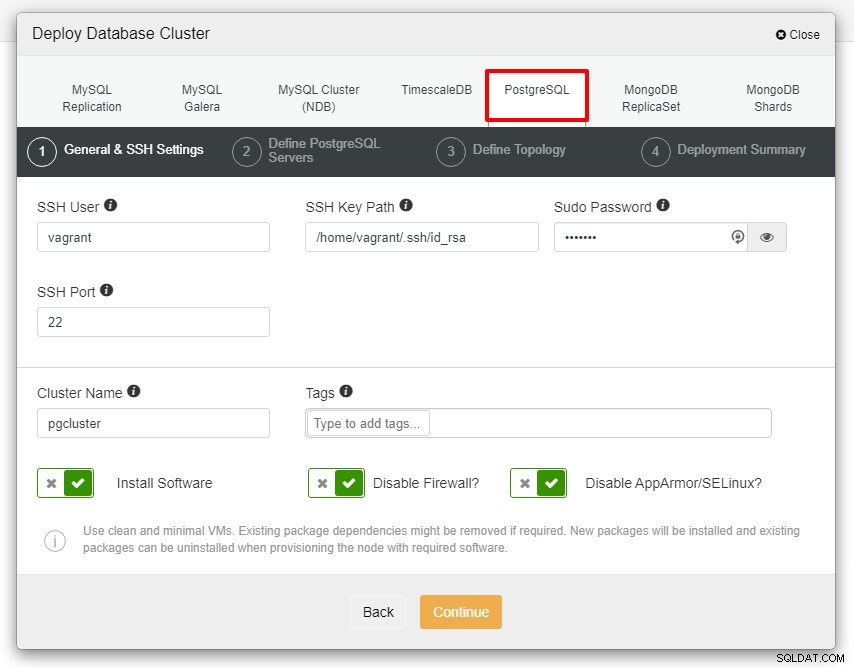
Antes de prosseguirmos, gostaria de lembrá-lo que a conexão entre o nó ClusterControl e os nós de banco de dados deve ser sem senha. Antes da implantação, tudo o que precisamos fazer é gerar o ssh-keygen do nó ClusterControl e copiá-lo para todos os nós. Preencha a entrada para o usuário SSH, a senha do Sudo e o nome do cluster conforme sua necessidade e clique em Continuar.
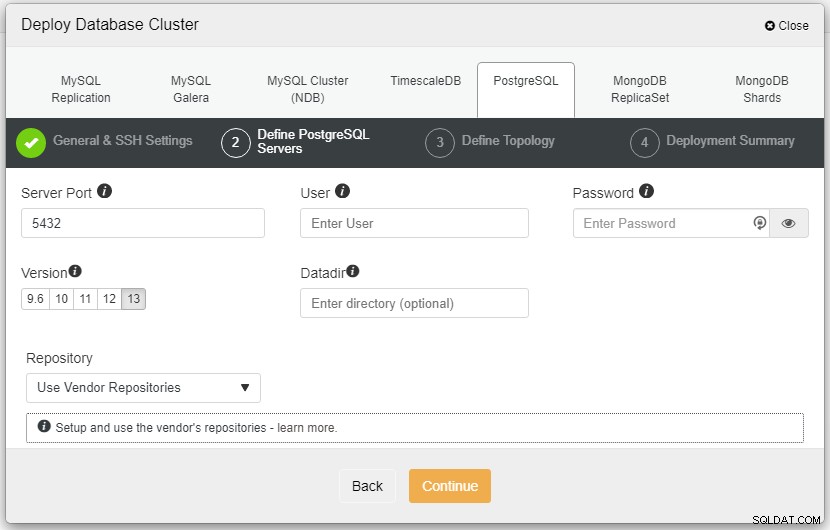
Na captura de tela acima, você precisará definir a Porta do Servidor (caso queira usar outras), o usuário que deseja, bem como a senha e a Versão que deseja para instalar.
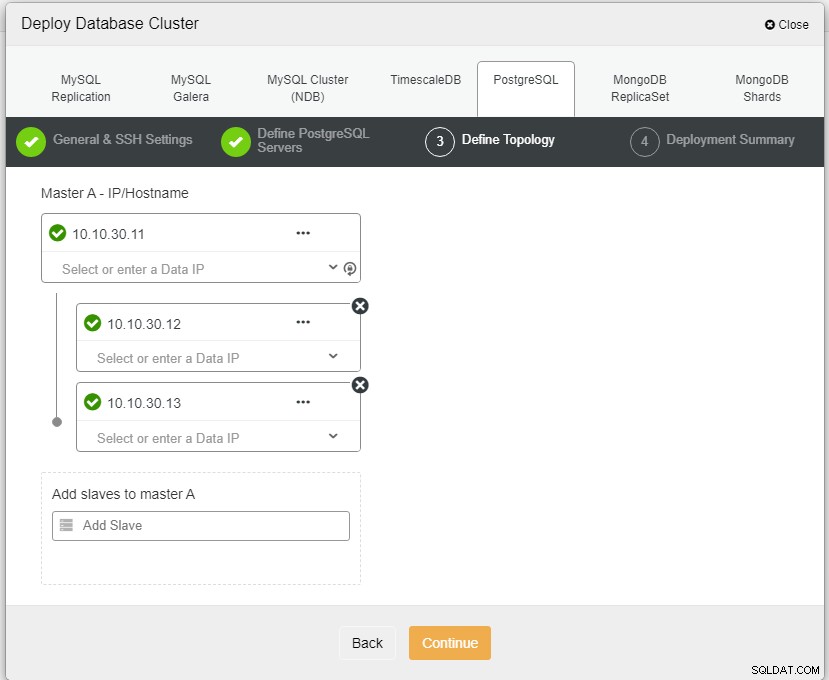
Aqui precisamos definir os servidores usando o nome do host ou o endereço IP, como neste caso 1 mestre e 2 escravos. A etapa final é escolher o modo de replicação para nosso cluster.
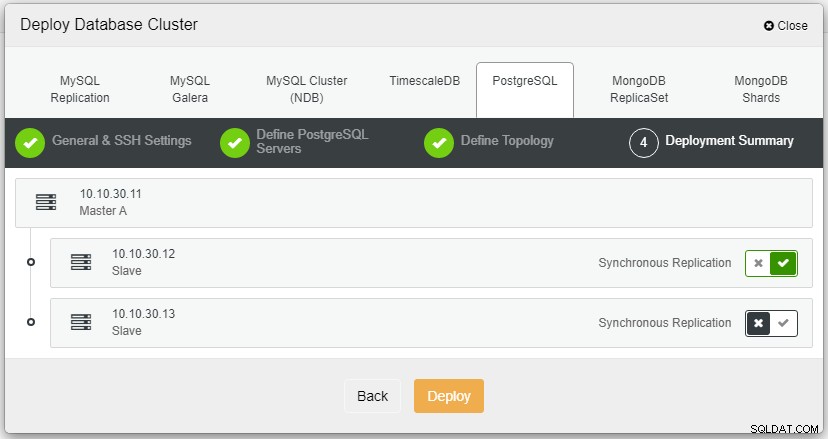
Depois de clicar em Implantar, o processo de implantação será iniciado e poderemos monitorar o progresso na guia Atividade.
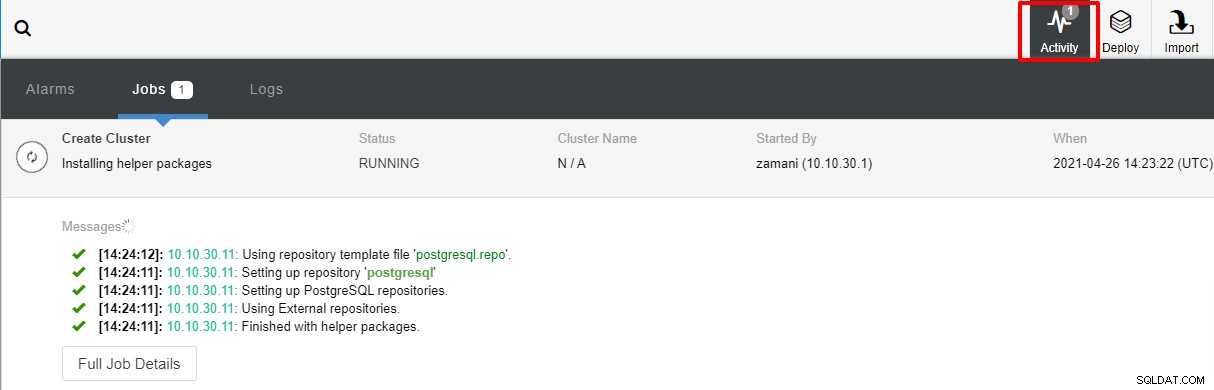
A implantação normalmente leva alguns minutos, o desempenho depende principalmente da rede e da especificação do servidor.

Agora que temos o PostgreSQL instalado usando o ClusterControl.
Implantação do PostgreSQL usando CLI do ClusterControl
A outra forma alternativa de implantar o PostgreSQL é usando a CLI. desde que já tenhamos configurado a conexão sem senha, podemos apenas executar o seguinte comando e deixá-lo terminar.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logVocê deverá ver a mensagem abaixo assim que o processo for concluído com êxito e puder fazer login na Web do ClusterControl para verificar:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Conclusão
Como você pode ver, existem algumas maneiras de como implantar o PostgreSQL. Nesta postagem do blog, aprendemos como implantá-lo usando o Ansible e também usando nosso ClusterControl. Ambas as maneiras são fáceis de seguir e podem ser alcançadas com uma curva de aprendizado mínima. Com o ClusterControl, a configuração de replicação de streaming pode ser complementada com HAProxy, VIP e PGBouncer para adicionar failover de conexão, IP virtual e pool de conexão à configuração.
Observe que a implantação é apenas um aspecto de um ambiente de banco de dados de produção. Mantê-lo em funcionamento, automatizar failovers, recuperar nós quebrados e outros aspectos como monitoramento, alertas e backups são essenciais.
Esperamos que esta postagem do blog beneficie alguns de vocês e dê uma ideia de como automatizar as implantações do PostgreSQL.



