Percona XtraDB Cluster é uma solução de alta disponibilidade muito conhecida no mundo MySQL. Ele é baseado no Galera Cluster e fornece replicação virtualmente síncrona em vários nós. Como em todo banco de dados, é fundamental acompanhar o que está acontecendo no sistema, se o desempenho está nos níveis esperados e, caso contrário, qual é o gargalo. Isso é de extrema importância para poder reagir adequadamente na situação em que o desempenho é afetado. É claro que o Percona XtraDB Cluster vem com várias métricas e nem sempre fica claro quais delas são as mais importantes para rastrear o estado do banco de dados. Neste blog, discutiremos algumas das principais métricas nas quais você deve ficar de olho ao trabalhar com o PXC.
Para deixar claro, estaremos focando nas métricas exclusivas para PXC e Galera, não abordaremos métricas para MySQL ou InnoDB. Essas métricas foram discutidas em nossos blogs anteriores.
Vamos dar uma olhada em algumas das informações mais importantes que a PXC nos apresenta.
Controle de fluxo
O controle de fluxo é praticamente a métrica mais importante que você pode monitorar em qualquer Galera Cluster, portanto, vamos ter um pouco de fundo. Galera é um cluster multimestre virtualmente síncrono. É possível executar gravações em qualquer um dos nós do banco de dados que o formam. Cada gravação deve ser enviada a todos os nós do cluster para garantir que possa ser aplicada - esse processo é chamado de certificação. Nenhuma transação pode ser aplicada antes que todos os nós concordem que ela pode ser confirmada. Se algum dos nós tiver problemas de desempenho que o tornem incapaz de lidar com o tráfego, ele começará a emitir mensagens de controle de fluxo que visam informar o restante do cluster sobre os problemas de desempenho e solicitar que reduzam a carga de trabalho e ajudem os atrasados. node para alcançar o resto do cluster.
Você pode rastrear quando os nós tiveram que introduzir uma pausa artificial para permitir que seus pares atrasados se atualizassem usando a métrica de controle de fluxo pausado (wsrep_flow_control_paused):

Você também pode rastrear se o nó está enviando ou recebendo as mensagens de controle de fluxo (wsrep_flow_control_recv e wsrep_flow_control_sent).
Estas informações ajudarão você a entender melhor qual nó não está funcionando no mesmo nível como seus pares. Você pode então se concentrar nesse nó e tentar entender qual é o problema e como remover o gargalo.
Enviar e receber filas
Essas métricas estão relacionadas ao controle de fluxo. Como discutimos, um nó pode estar atrasado em relação a outros nós do cluster. Isso pode ser causado por uma divisão não uniforme da carga de trabalho ou por outros motivos (algum processo em execução em segundo plano, backup ou algumas consultas pesadas e personalizadas). Antes que o controle de fluxo entre em ação, os nós atrasados tentarão armazenar os conjuntos de gravação de entrada na fila de recebimento (wsrep_local_recv_queue) esperando que o impacto no desempenho seja transitório e seja capaz de recuperar o atraso muito em breve. Somente se a fila se tornar muito grande (ela é controlada pela configuração gcs.fc_limit), as mensagens de controle de fluxo começam a ser enviadas pelo cluster.

Você pode pensar em uma fila de recebimento como o marcador inicial que mostra que há há problemas com o desempenho e o controle de fluxo pode entrar em ação.

Por outro lado, a fila de envio (wsrep_local_send_queue) informará que o nó não pode enviar os conjuntos de gravação para outros membros do cluster, o que pode indicar problemas com a conectividade da rede (enviando os conjuntos de gravação para a rede não é realmente intensiva em recursos).
Métricas de paralelização
O cluster Percona XtraDB pode ser configurado para usar vários encadeamentos para aplicar os conjuntos de gravação de entrada - ele permite lidar melhor com vários encadeamentos conectando-se ao cluster e emitindo gravações ao mesmo tempo. Existem duas métricas principais que você pode querer ficar de olho.
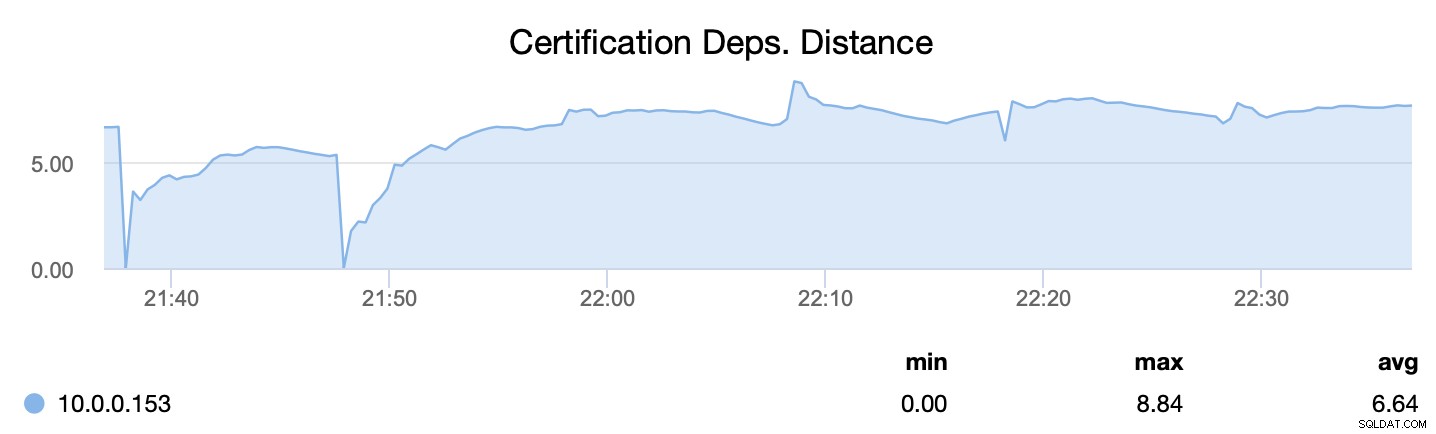
Primeiro, wsrep_cert_deps_distance, nos diz qual é o potencial de paralelização - quantos conjuntos de escrita podem, potencialmente, ser aplicados ao mesmo tempo. Com base nesse valor, você pode configurar o número de encadeamentos escravos paralelos (wsrep_slave_threads) que funcionarão na aplicação de conjuntos de gravação de entrada. A regra geral é que não faz sentido configurar mais encadeamentos do que o valor de wsrep_cert_deps_distance.
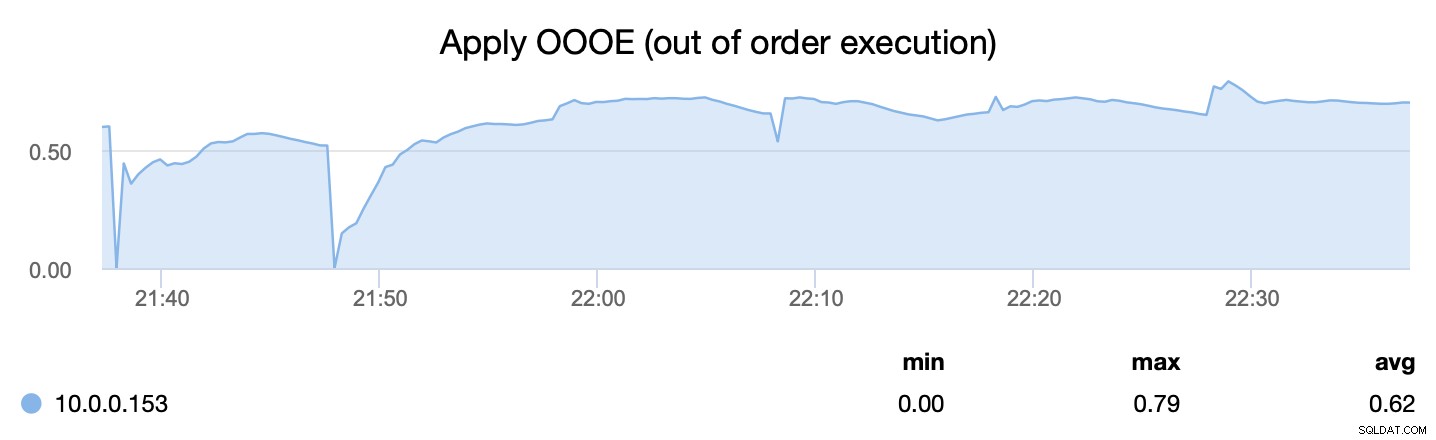
A segunda métrica, por outro lado, nos diz com que eficiência conseguimos paralelizar o processo de aplicação de conjuntos de gravação - wsrep_apply_oooe nos diz com que frequência o aplicador começou a aplicar conjuntos de gravação fora de ordem (o que aponta para uma melhor paralelização ).
Conclusão
Como você pode ver, há algumas métricas que valem a pena observar no Percona XtraDB Cluster. Claro que, como dissemos no início deste blog, são métricas estritamente relacionadas ao PXC e ao Galera Cluster em geral.
Você também deve ficar de olho nas métricas regulares do MySQL e do InnoDB para entender melhor o estado do seu banco de dados. E lembre-se, você pode monitorar essa tecnologia gratuitamente usando o ClusterControl Community Edition.



