Este blog é uma breve apresentação sobre o Jenkins e mostra como usar essa ferramenta para ajudar em algumas de suas tarefas diárias de administração e gerenciamento do PostgreSQL.
Sobre Jenkins
Jenkins é um software de código aberto para automação. É desenvolvido em java e é uma das ferramentas mais populares para Integração Contínua (CI) e Entrega Contínua (CD).
Em 2010, após a aquisição da Sun Microsystems pela Oracle, o software "Hudson" estava em disputa com sua comunidade de código aberto. Essa disputa se tornou a base para o lançamento do projeto Jenkins.
Hoje em dia, "Hudson" (licença pública Eclipse) e "Jenkins" (licença MIT) são dois projetos ativos e independentes com um propósito muito semelhante.
Jenkins tem milhares de plugins que você pode usar para acelerar a fase de desenvolvimento por meio da automação de todo o ciclo de vida do desenvolvimento; construir, documentar, testar, empacotar, preparar e implantar.
O que Jenkins faz?
Embora o principal uso do Jenkins possa ser a Integração Contínua (CI) e a Entrega Contínua (CD), este código aberto possui um conjunto de funcionalidades e pode ser utilizado sem qualquer compromisso ou dependência de CI ou CD, assim o Jenkins apresenta algumas funcionalidades interessantes para explorar:
- Agendar trabalhos de período (em vez de usar o tradicional crontab )
- Monitorando jobs, seus logs e atividades por uma visão limpa (já que eles têm uma opção de agrupamento)
- A manutenção dos trabalhos pode ser feita facilmente; supondo que Jenkins tenha um conjunto de opções para isso
- Configurar e programar a instalação do software (usando o Puppet) no mesmo host ou em outro.
- Publicando relatórios e enviando notificações por e-mail
Executando tarefas do PostgreSQL no Jenkins
Existem três tarefas comuns que um desenvolvedor PostgreSQL ou administrador de banco de dados deve realizar diariamente:
- Agendamento e execução de scripts PostgreSQL
- Executando um processo PostgreSQL composto por três ou mais scripts
- Integração Contínua (CI) para desenvolvimentos PL/pgSQL
Para a execução desses exemplos, supõe-se que os servidores Jenkins e PostgreSQL (pelo menos a versão 9.5) estejam instalados e funcionando corretamente.
Agendamento e execução de um script PostgreSQL
Na maioria dos casos a implementação de scripts PostgreSQL diários (ou periodicamente) para a execução de uma tarefa usual como...
- Geração de backups
- Testar a restauração de um backup
- Execução de uma consulta para fins de relatório
- Limpar e arquivar arquivos de registro
- Chamar um procedimento PL/pgSQL para limpar tabelas
t está definido no crontab :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shComo o crontab não é a melhor ferramenta amigável para gerenciar esse tipo de agendamento, isso pode ser feito no Jenkins com as seguintes vantagens...
- Interface muito amigável para monitorar seu progresso e status atual
- Os logs estão disponíveis imediatamente e não há necessidade de nenhuma concessão especial para acessá-los
- O trabalho pode ser executado manualmente no Jenkins em vez de ter um agendamento
- Para alguns tipos de trabalhos, não é necessário definir usuários e senhas em arquivos de texto simples, pois o Jenkins faz isso de maneira segura
- Os jobs podem ser definidos como uma execução de API
Portanto, pode ser uma boa solução migrar os trabalhos relacionados às tarefas do PostgreSQL para o Jenkins em vez do crontab.
Por outro lado, a maioria dos administradores e desenvolvedores de banco de dados tem fortes habilidades em linguagens de script e seria fácil para eles desenvolver pequenas interfaces para lidar com esses scripts para implementar os processos automatizados com o objetivo de melhorar suas tarefas. Mas lembre-se, Jenkins provavelmente já tem um conjunto de funções para fazer isso e essas funcionalidades podem facilitar a vida dos desenvolvedores que optam por usá-las.
Assim para definir a execução do script é necessário criar um novo trabalho, selecionando a opção “Novo Item”.
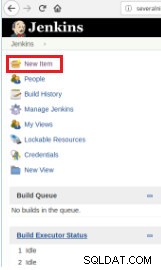 Figura 1 – "Novo Item" para definir um job para executar um script PostgreSQL
Figura 1 – "Novo Item" para definir um job para executar um script PostgreSQL Em seguida, após nomeá-lo, escolha o tipo “Projetos FreeStyle” e clique em OK.
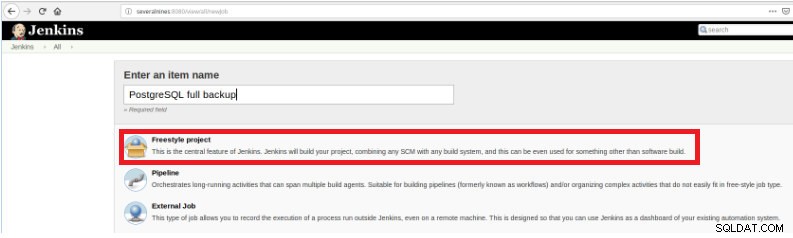 Figura 2 – Seleção do tipo de trabalho (item)
Figura 2 – Seleção do tipo de trabalho (item) Para finalizar a criação deste novo job, na seção “Build” deve ser selecionada a opção “Execute script” e na caixa de linha de comando o caminho e parametrização do script que será executado:
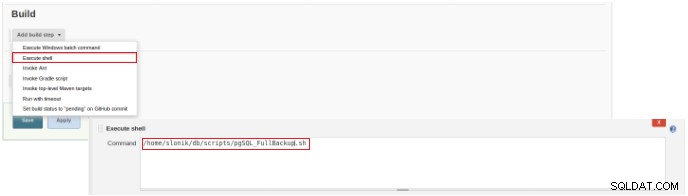 Figura 3 – Especificação do comando a ser executado
Figura 3 – Especificação do comando a ser executado Para este tipo de trabalho, é aconselhável verificar as permissões de script, pois pelo menos a execução para o grupo ao qual o arquivo pertence e para todos deve ser definida.
Neste exemplo, o script query.sh tem permissões de leitura e execução para todos, permissões de leitura e execução para o grupo e leitura, gravação e execução para o usuário:
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ Este script possui um conjunto de comandos muito simples, basicamente apenas chamadas ao utilitário psql para executar consultas:
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datExecutando um processo PostgreSQL composto por três ou mais scripts
Neste exemplo, descreverei o que você precisa para executar três scripts diferentes para ocultar dados confidenciais e, para isso, seguiremos os passos abaixo...
- Importar dados de arquivos
- Prepare os dados a serem mascarados
- Backup de banco de dados com dados mascarados
Assim, para definir este novo trabalho é necessário selecionar a opção “New Item” na página principal do Jenkins e depois de atribuir um nome, deve-se escolher a opção “Pipeline”:
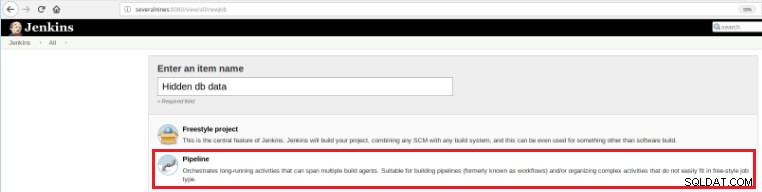 Figura 5 - Item de pipeline no Jenkins
Figura 5 - Item de pipeline no Jenkins Uma vez que o trabalho seja salvo na seção “Pipeline”, na aba “Opções avançadas do projeto”, o campo “Definição” deve ser definido como “Script de pipeline”, conforme mostrado abaixo:
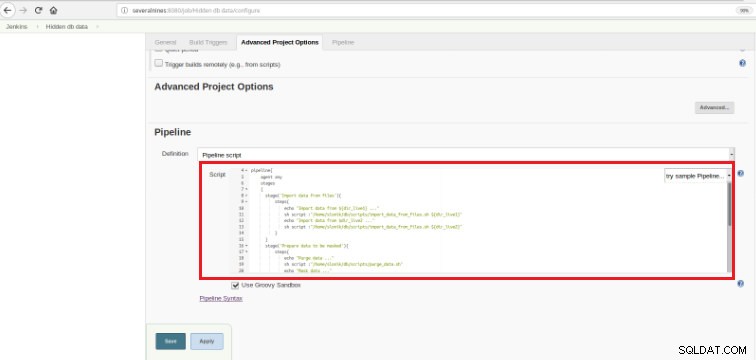 Figura 6 - Script Groovy na seção de pipeline
Figura 6 - Script Groovy na seção de pipeline Como mencionei no início do capítulo, o script Groovy utilizado é composto por três estágios, ou seja, três partes distintas (estágios), conforme apresentado no script a seguir:
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovy é uma linguagem de programação orientada a objetos compatível com a sintaxe Java para a plataforma Java. É uma linguagem estática e dinâmica com recursos semelhantes aos de Python, Ruby, Perl e Smalltalk.
É fácil de entender, pois esse tipo de script é baseado em algumas declarações…
Estágio
Significa os 3 processos que serão executados:“Importar dados de arquivos”, “Preparar dados a serem mascarados”
e “Backup de banco de dados com dados mascarados”.
Passo
Uma “etapa” (geralmente chamada de “etapa de construção”) é uma única tarefa que faz parte de uma sequência. Cada etapa pode ser composta de várias etapas. Neste exemplo, o primeiro estágio tem duas etapas.
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'Os dados estão sendo importados de duas fontes distintas.
No exemplo anterior, é importante observar que existem duas variáveis definidas no início e com escopo global:
dir_live1
dir_live2Os scripts usados nessas três etapas estão chamando o psql , pg_restore e pg_dump Serviços de utilidade pública.
Uma vez definido o trabalho, é hora de executá-lo e, para isso, basta clicar na opção “Build Now”:
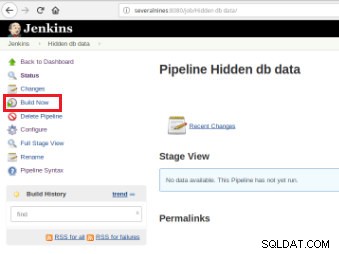 Figura 7 – Trabalho de execução
Figura 7 – Trabalho de execução Após o início da compilação, é possível verificar seu progresso.
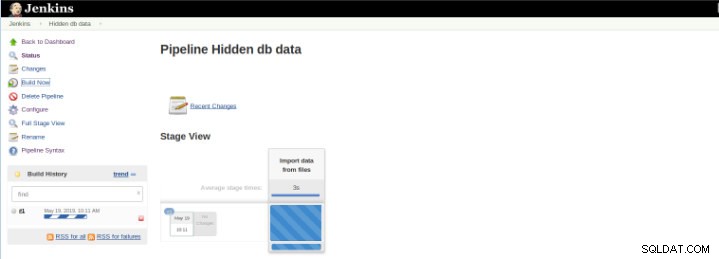 Figura 8 – Iniciando “Build”
Figura 8 – Iniciando “Build” O plug-in Pipeline Stage View inclui uma visualização estendida do histórico de construção do Pipeline na página de índice de um projeto de fluxo em Stage View. Essa visualização é construída assim que as tarefas são concluídas e cada tarefa é representada por coluna da esquerda para a direita e é possível visualizar e comparar o tempo decorrido para as execuções do serval (conhecido como Build no Jenkins).
Uma vez que a execução (também chamada de Build) termina, é possível obter detalhes adicionais, clicando no thread finalizado (caixa vermelha).
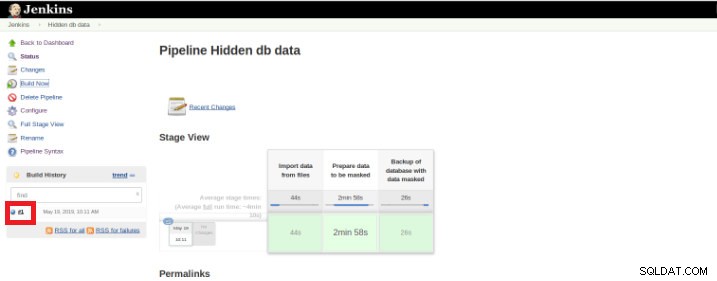 Figura 9 – Iniciando “Build”
Figura 9 – Iniciando “Build” e depois na opção “Saída do Console”.
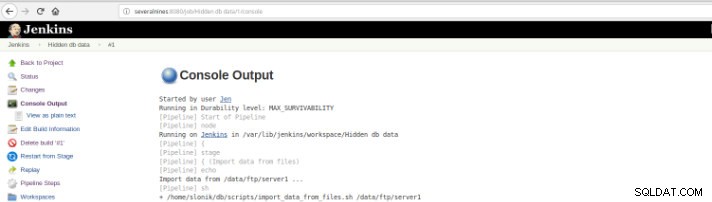 Figura 10 – Saída do console
Figura 10 – Saída do console As visualizações anteriores são de extrema utilidade, pois permitem ter uma percepção do tempo de execução necessário de cada etapa.
Pipelines, também conhecido como workflow, é um plugin que permite a definição do ciclo de vida do aplicativo e é uma funcionalidade usada no Jenkins para entrega contínua (CD).vEste plugin foi construído com requisitos para um recurso de workflow de CD flexível, extensível e baseado em script em mente.
Este exemplo é para ocultar dados confidenciais, mas com certeza existem muitos outros exemplos diários de administrador de banco de dados PostgreSQL que podem ser executados em um trabalho de pipeline.
O Pipeline está disponível no Jenkins desde a versão 2.0 e é uma solução incrível!

Integração Contínua (CI) para Desenvolvimentos PL/pgSQL
A integração contínua para o desenvolvimento do banco de dados não é tão fácil quanto em outras linguagens de programação devido aos dados que podem ser perdidos, por isso não é fácil manter o banco de dados no controle de origem e implantá-lo em um servidor dedicado principalmente quando há scripts que contêm instruções DDL (linguagem de definição de dados) e DML (linguagem de manipulação de dados). Isso ocorre porque esses tipos de instruções modificam o estado atual do banco de dados e, diferentemente de outras linguagens de programação, não há código-fonte para compilar.
Por outro lado, há um conjunto de declarações de banco de dados para as quais é possível a integração contínua como para outras linguagens de programação.
Este exemplo é baseado apenas no desenvolvimento de procedimentos e ilustrará o acionamento de um conjunto de testes (escritos em Python) pelo Jenkins uma vez que os scripts do PostgreSQL, nos quais são armazenados o código das seguintes funções, são submetidos a um repositório de código.
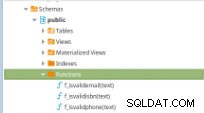 Figura 11 – Funções PLpg/SQL
Figura 11 – Funções PLpg/SQL Estas funções são simples e seu conteúdo possui apenas algumas lógicas ou uma consulta em PLpg/SQL ou plperlu idioma como a função f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;Todas as funções aqui apresentadas não dependem umas das outras e, portanto, não há precedência nem no seu desenvolvimento nem na sua implantação. Além disso, como será verificado adiante, não há dependência de suas validações.
Assim, para executar um conjunto de scripts de validação uma vez que um commit é realizado em um repositório de código é necessário a criação de um build job (novo item) no Jenkins:
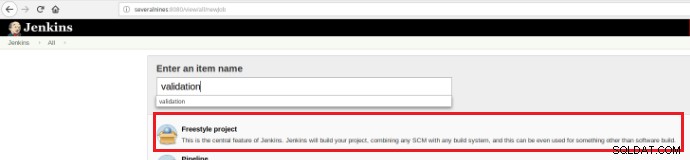 Figura 12 – Projeto "Freestyle" para Integração Contínua
Figura 12 – Projeto "Freestyle" para Integração Contínua Este novo trabalho de compilação deve ser criado como projeto “Freestyle” e na seção “Source code repository” deve ser definida a URL do repositório e suas credenciais (caixa laranja):
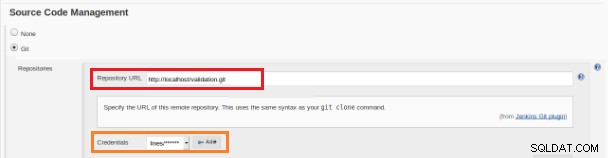 Figura 13 – Repositório de código-fonte
Figura 13 – Repositório de código-fonte Na seção "Build Triggers" a opção "GitHub hook trigger for GITScm polling" deve ser marcada:
 Figura 14 – Seção “Build triggers”
Figura 14 – Seção “Build triggers” Por fim, na seção “Build”, deve-se selecionar a opção “Execute Shell” e na caixa de comando os scripts que farão a validação das funções desenvolvidas:
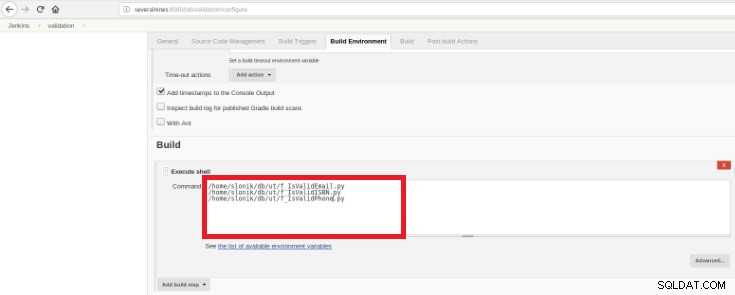 Figura 15 – Seção “Ambiente de compilação”
Figura 15 – Seção “Ambiente de compilação” O objetivo é ter um script de validação para cada função desenvolvida.
Este script Python possui um conjunto simples de instruções que chamará esses procedimentos de um banco de dados com alguns resultados esperados predefinidos:
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()Este script irá testar o PLpg/SQL apresentado ou plperlu funções e será executado após cada commit no repositório de código para evitar regressões nos desenvolvimentos.
Depois que essa criação de trabalho for executada, as execuções de log poderão ser verificadas.
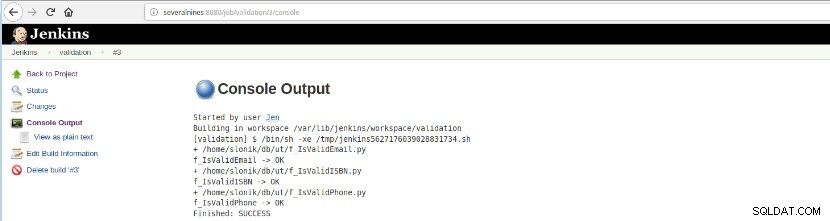 Figura 16 – “Saída do Console”
Figura 16 – “Saída do Console” Esta opção apresenta o status final:SUCESSO ou FALHA, a área de trabalho, os arquivos/script executados, os arquivos temporários criados e as mensagens de erro (para os de falha)!
Conclusão
Em resumo, o Jenkins é conhecido como uma ótima ferramenta para Integração Contínua (CI) e Entrega Contínua (CD), porém, pode ser utilizado para diversas funcionalidades como,
- Programação de tarefas
- Execução de scripts
- Processos de monitoramento
Para todos esses propósitos em cada execução (vocabulário Build on Jenkins) podem ser analisados os logs e o tempo decorrido.
Devido ao grande número de plugins disponíveis poderia evitar alguns desenvolvimentos com um objetivo específico, provavelmente existe um plugin que faz exatamente o que você procura, é apenas uma questão de pesquisar no centro de atualização ou Gerenciar Jenkins>>Gerenciar Plugins dentro a aplicação web.