Em um artigo anterior, discutimos o modelo de esquema em estrela. O esquema floco de neve está próximo ao esquema estrela em termos de sua importância na modelagem de data warehouse. Ele foi desenvolvido a partir do esquema em estrela e oferece algumas vantagens em relação ao seu antecessor. Mas essas vantagens têm um custo. Neste artigo, discutiremos quando e como usar o esquema de floco de neve.
O esquema do floco de neve
O nome do esquema de floco de neve vem do fato de que as tabelas de dimensão se ramificam e se parecem com um floco de neve. Quando olhamos para o modelo acima, notamos que é uma tabela de fatos cercada por algumas tabelas de dimensão, algumas das quais fazem a ramificação mencionada. Ao contrário do esquema em estrela, as tabelas de dimensão no esquema floco de neve podem ter suas próprias categorias.
A ideia dominante por trás do esquema floco de neve é que as tabelas de dimensão são completamente normalizadas. Cada tabela de dimensão pode ser descrita por uma ou mais tabelas de pesquisa. Cada tabela de consulta pode ser descrita por uma ou mais tabelas de consulta adicionais. Isso é repetido até que o modelo esteja totalmente normalizado. O processo de normalização das tabelas de dimensão do esquema em estrela é chamado de floco de neve.
Você ouvirá muito sobre normalização neste artigo. O que é normalização? Basicamente, é organizar um banco de dados de forma a minimizar redundâncias e proteger a integridade dos dados. Confira este post para saber mais sobre normalização e desnormalização.
Exemplo de esquema de floco de neve:modelo de vendas
Anteriormente, usávamos um esquema em estrela para modelar um departamento de vendas fictício – isso seria semelhante a um data mart usado para rastrear atividades e resultados de vendas. O modelo tem cinco dimensões:produto , hora , loja , vendas tipo e funcionário . No
fact_sales tabela, preço e quantidade são armazenados e agrupados com base nos valores das tabelas de dimensão. Para relembrar, dê uma olhada no modelo de vendas do esquema em estrela abaixo:Aqui está o mesmo modelo organizado como um esquema de floco de neve:
O
dim_employee e dim_sales_type as tabelas de dimensão são exatamente as mesmas do modelo de esquema em estrela porque já estão normalizadas. Por outro lado, aplicamos regras de normalização ao restante das tabelas de dimensão.


O dim_product A tabela de dimensões do esquema em estrela é dividida em duas tabelas no modelo floco de neve. O dim_product_type A tabela foi adicionada para referenciar o tipo de correspondência no dim_product tabela. Usando isso, evitamos alguns problemas de integridade de dados.
É lógico supor que já teremos todos os nomes de produtos e seus tipos relacionados inseridos como parte do processo ETL, mas suponha que precisamos adicionar mais nomes e tipos de produtos. Em um esquema em estrela, poderíamos inserir erroneamente o tipo de produto errado na tabela. No esquema do floco de neve:
- Se encontrarmos um novo nome de tipo de produto, podemos adicionar um novo tipo de produto e relacioná-lo a um registro recém-adicionado. No entanto, isso pode fazer com que o usuário insira informações erradas, assim como no esquema em estrela.
- Podemos verificar se o nome do produto que queremos adicionar já existe. Se sim, podemos obter seu ID; caso contrário, aparecerá um aviso perguntando se queremos adicionar um novo produto e um tipo relacionado.

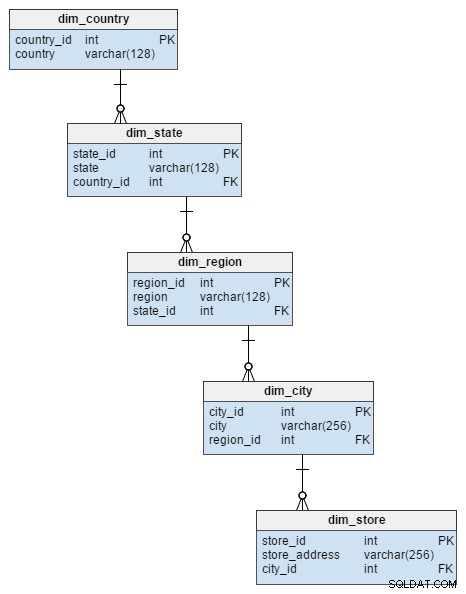
O dim_store A tabela de dimensões do esquema em estrela é representada por 5 tabelas no esquema floco de neve. Eles dividem os atributos de cidade, região, estado e país que foram armazenados no dim_store tabela. A normalização dessa tabela não apenas evitou o risco de integridade dos dados, como também economizou algum espaço em disco.
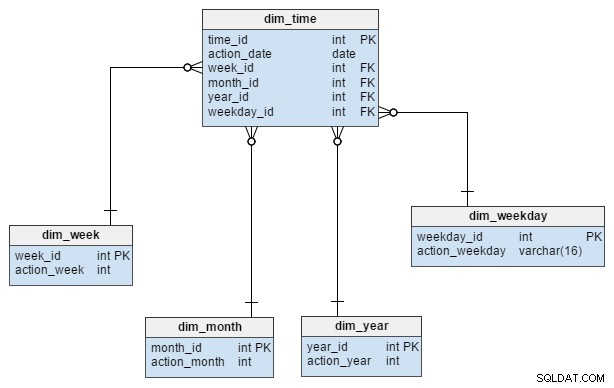
O dim_time dimensão é representada com cinco tabelas. Podemos pensar em dim_week , dim_month , dim_year e o dim_weekday tabelas como dicionários que descrevem o dim_time tabela.
A dim_week , dim_month , dim_year e dim_weekday tabelas são quatro hierarquias diferentes usadas para descrever nossa dimensão de tempo. Poderíamos adicionar mais dimensões, como trimestres ou outras tabelas relacionadas, se precisássemos delas. Neste exemplo, dim_month é um dicionário contendo 12 meses; somente desta dimensão, não temos como saber a que ano pertence aquele mês; essa é a função do dim_year tabela.
Exemplo de esquema de floco de neve:modelo de pedidos de fornecimento
O outro data mart que discutimos foi para pedidos de fornecimento. A ideia é armazenar e agregar todos os dados de pedidos de fornecimento para as quatro dimensões a seguir:produto , hora , fornecedor e funcionário . Mais uma vez, vamos dar uma olhada no esquema em estrela relevante:
Convertendo isso para o esquema de floco de neve, obtemos o seguinte modelo:
As mesmas regras de normalização descritas para o modelo de vendas foram usadas no
dim_product , dim_time e dim_supplier tabelas de dimensão. Vantagens e desvantagens do esquema de floco de neve
Existem duas vantagens principais para o esquema do floco de neve:
- Melhor qualidade de dados (os dados são mais estruturados, portanto, os problemas de integridade de dados são reduzidos)
- Menos espaço em disco é usado em um modelo desnormalizado
A desvantagem mais notável para o modelo floco de neve é que ele requer consultas mais complexas. Essas consultas, com seu maior número de junções, podem diminuir significativamente o desempenho.
Vamos reescrever a mesma consulta usada no artigo do esquema em estrela para o modelo de vendas do esquema floco de neve. Aqui está a consulta necessária para retornar a quantidade de todos os tipos de produtos do tipo telefone vendidos nas lojas de Berlim em 2016:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
O Esquema Starflake
Um esquema em floco de estrelas é uma combinação dos esquemas de floco de neve e em estrela. Podemos visualizá-lo como um esquema de floco de neve que possui algumas tabelas de dimensão desnormalizadas. Quando usado corretamente, o esquema starflake pode oferecer uma abordagem do melhor dos dois mundos. Obviamente, a parte floco de neve do modelo deve economizar espaço em disco, enquanto a parte estrela deve melhorar o desempenho.
O modelo acima é basicamente um modelo de floco de neve com um
dim_time tabela. Como esse esquema reduz o número de junções de consulta necessárias, ele pode melhorar o desempenho. Por outro lado, não perderemos uma quantidade notável de espaço em disco, pois a maioria dos atributos de tabela e atributos de chave estrangeira compartilham o int tipo. O Esquema da Galáxia
No armazenamento de dados, um esquema de galáxia é quando duas ou mais tabelas de fatos compartilham uma ou mais tabelas de dimensão. Um motivo para usar esse esquema é economizar espaço em disco. Criamos um esquema de galáxia de amostra abaixo:
Aqui, temos duas tabelas de fatos,
fact_sales e fact_supply_order , que compartilham diretamente três tabelas de dimensão:dim_product , dim_employee e dim_time . Observe que mesmo dim_store e dim_supplier compartilham a mesma tabela de pesquisa, dim_city . Vamos economizar espaço dessa forma, mas devemos ter algumas coisas em mente antes de juntarmos dois data marts (neste caso, pedidos de vendas e suprimentos) em um esquema de galáxia:
- Existe alguma lógica por trás de se juntar a eles? Por exemplo Os dois data marts seriam usados pelo mesmo departamento?
- Temos certeza de que precisamos precisamente da mesma dimensão e granulação para ambos os data marts?
O esquema floco de neve é frequentemente usado na modelagem de dados. Pode ser a escolha certa em situações em que o espaço em disco é mais importante que o desempenho. Se quisermos um equilíbrio entre economia de espaço e desempenho, podemos usar o esquema starflake. Ainda assim, o ajuste certo para qualquer problema específico depende de muitos parâmetros. Esta é uma das áreas de TI onde podemos “brincar” com fatores para encontrar a melhor solução.