Há poucos dias foi lançado uma nova versão do ClusterControl, a 1.7.1, onde podemos ver várias novidades, sendo uma das principais o suporte ao PostgreSQL 11.
Para instalar o PostgreSQL 11 manualmente, devemos primeiro adicionar os repositórios ou baixar os pacotes necessários para a instalação, instalá-los e configurá-los corretamente, dependendo de nossa infraestrutura. Todas essas etapas levam tempo, então vamos ver como podemos evitar isso.
Neste blog, veremos como implantar esta nova versão do PostgreSQL com apenas alguns cliques usando o ClusterControl e como gerenciá-la. Como pré-requisito, instale a versão 1.7.1 do ClusterControl em um host ou VM dedicado.
Implantar PostgreSQL 11
Para realizar uma nova instalação a partir do ClusterControl, basta selecionar a opção “Deploy” e seguir as instruções que aparecem. Observe que, se você já tiver uma instância do PostgreSQL 11 em execução, precisará selecionar 'Import Existing Server/Database'.
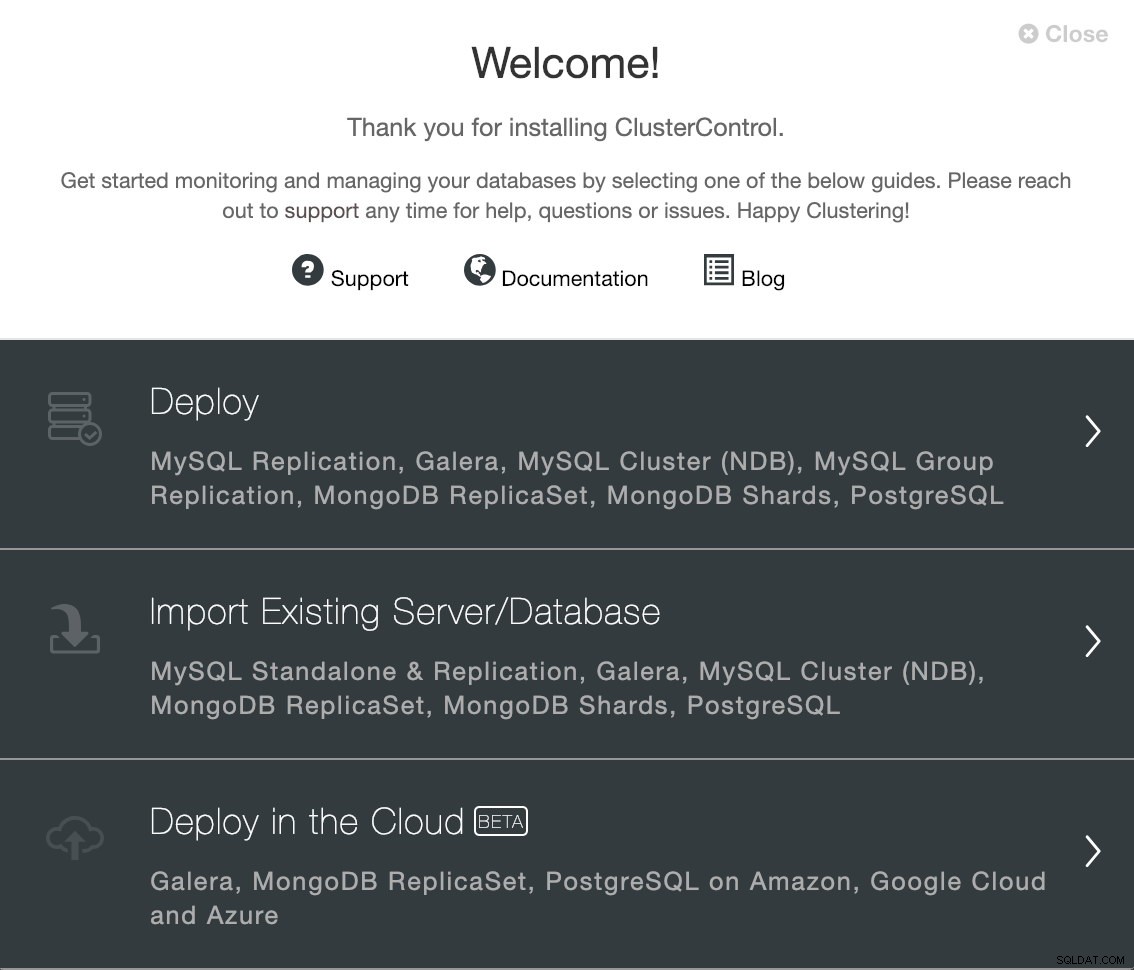 Opção de implantação do ClusterControl
Opção de implantação do ClusterControl Ao selecionar PostgreSQL, devemos especificar Usuário, Chave ou Senha e porta para conectar por SSH aos nossos hosts PostgreSQL. Também precisamos do nome do nosso novo cluster e se queremos que o ClusterControl instale o software e as configurações correspondentes para nós.
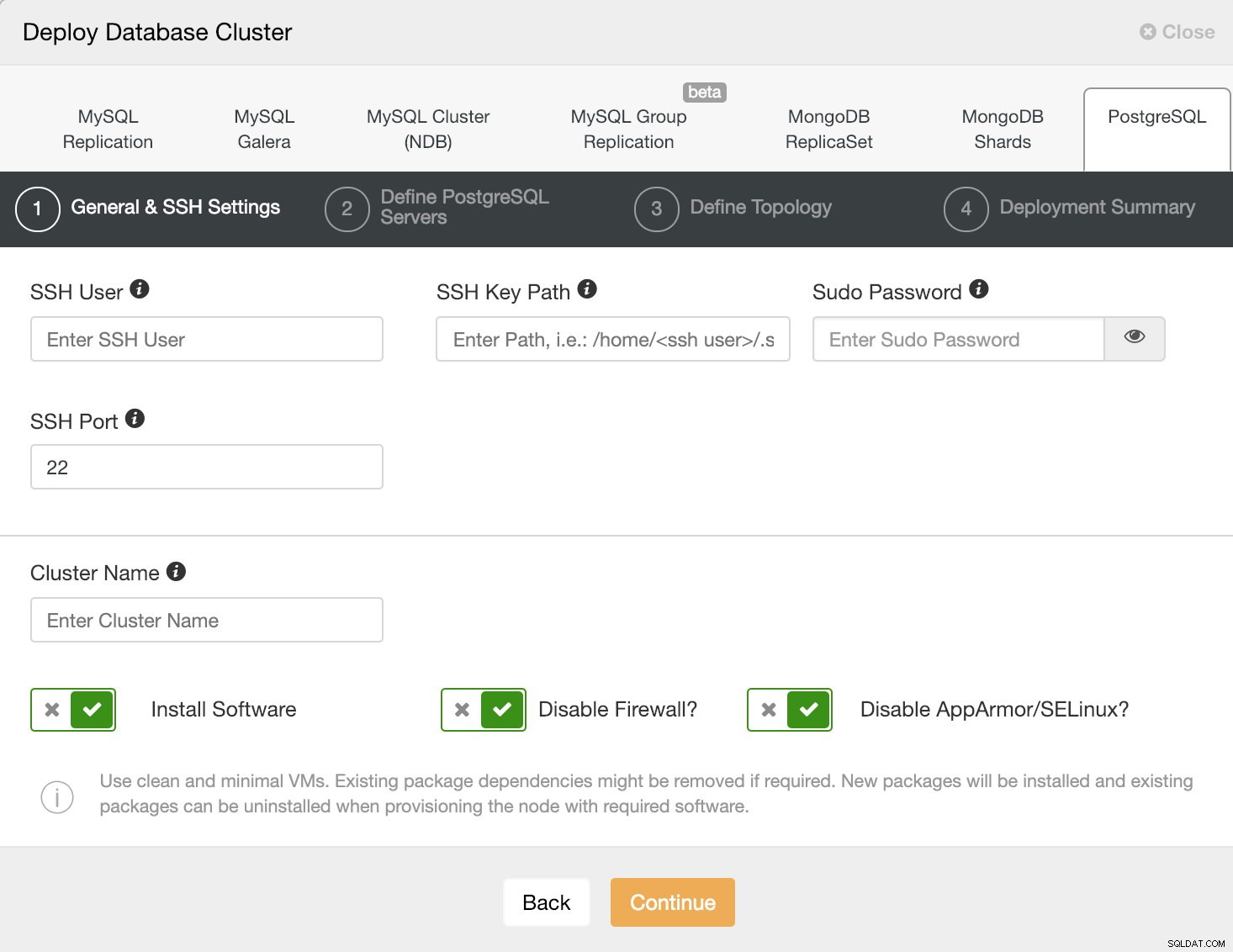 ClusterControl Deploy Information 1
ClusterControl Deploy Information 1 Verifique aqui o requisito de usuário do ClusterControl para esta tarefa.
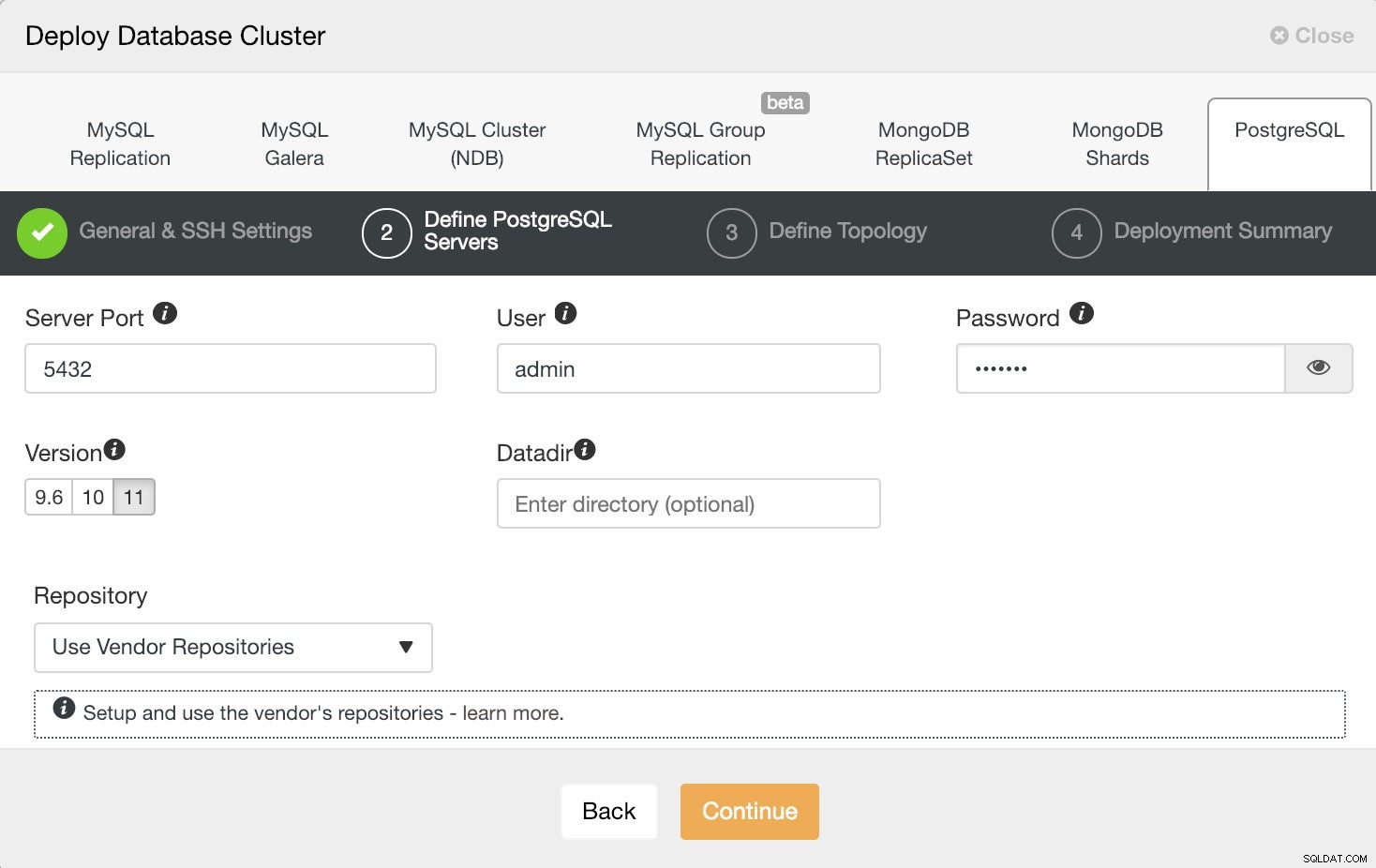 ClusterControl Deploy Information 2
ClusterControl Deploy Information 2 Após configurar as informações de acesso SSH, devemos definir o usuário do banco de dados, versão e datadir (opcional). Também podemos especificar qual repositório usar. Neste caso, queremos implantar o PostgreSQL 11, então basta selecioná-lo e continuar.
Na próxima etapa, precisamos adicionar nossos servidores ao cluster que vamos criar.
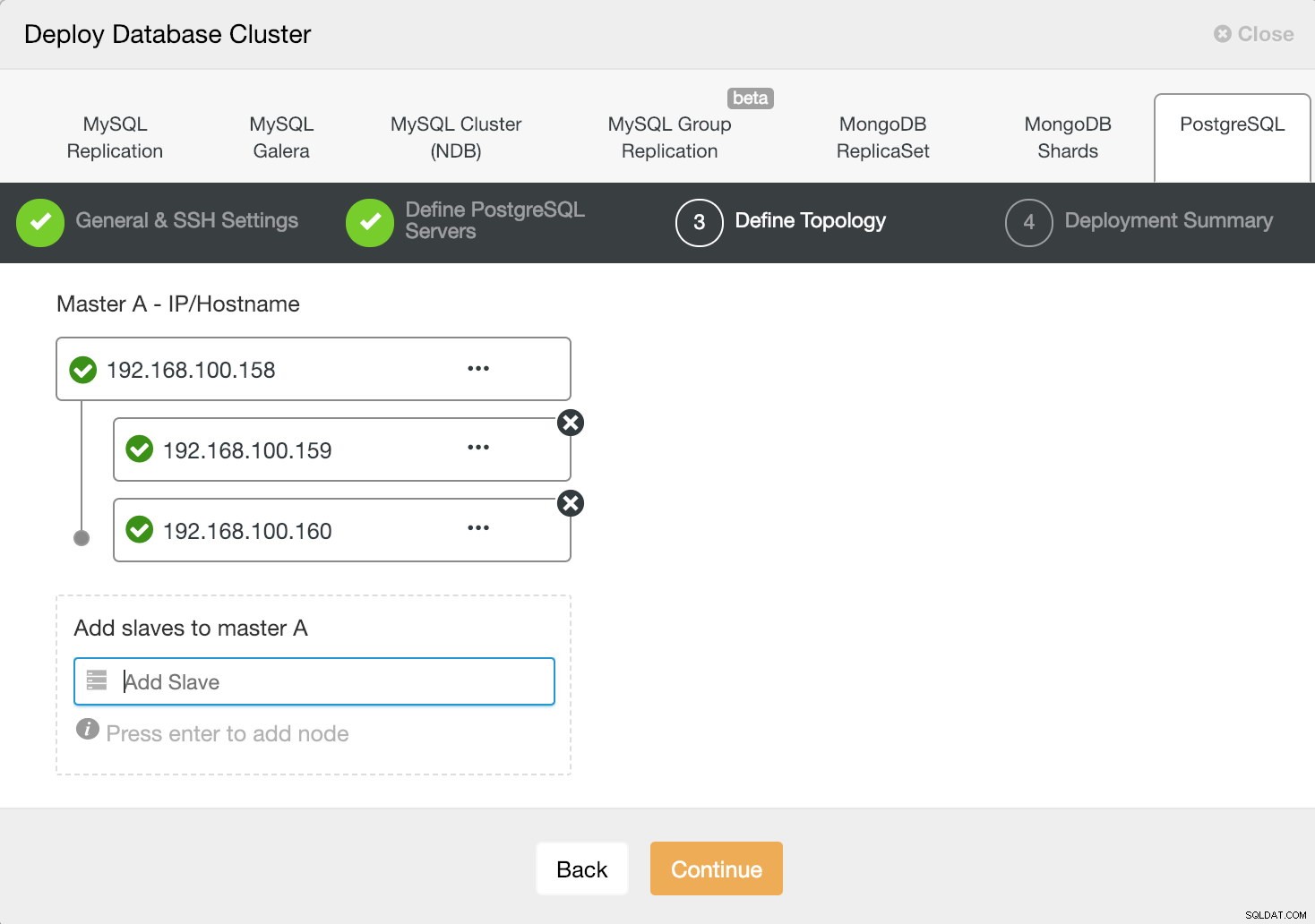 ClusterControl Deploy Information 3
ClusterControl Deploy Information 3 Ao adicionar nossos servidores, podemos inserir o IP ou o nome do host.
Na última etapa, podemos escolher se nossa replicação será síncrona ou assíncrona.
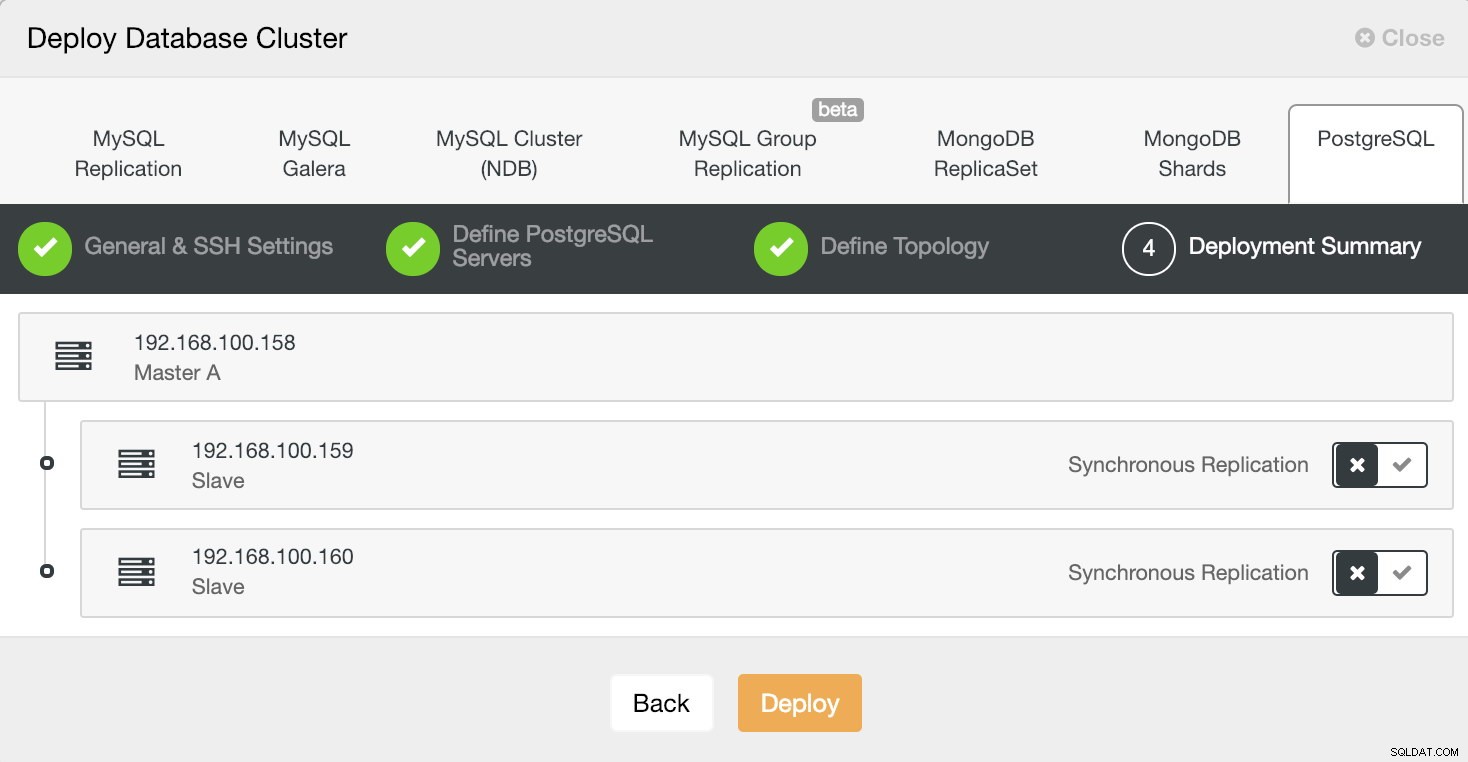 ClusterControl Deploy Information 4
ClusterControl Deploy Information 4 Podemos monitorar o status da criação do nosso novo cluster a partir do monitor de atividades do ClusterControl.
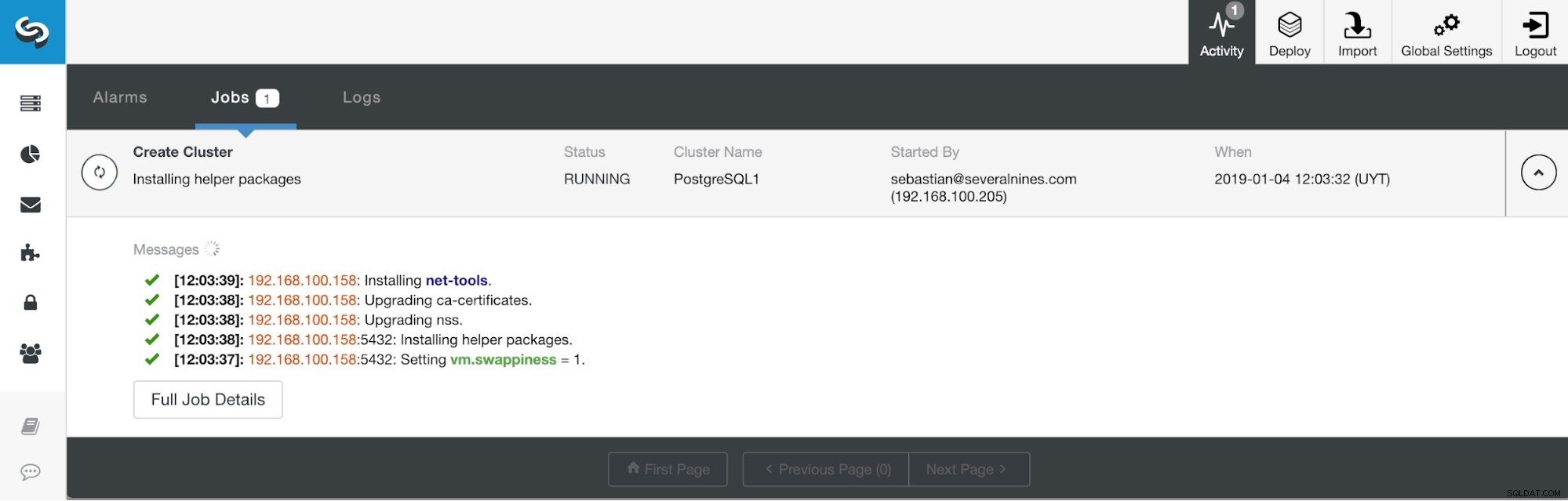 Seção de atividade de controle de cluster
Seção de atividade de controle de cluster Quando a tarefa estiver concluída, podemos ver nosso novo cluster do PostgreSQL 11 na tela principal do ClusterControl.
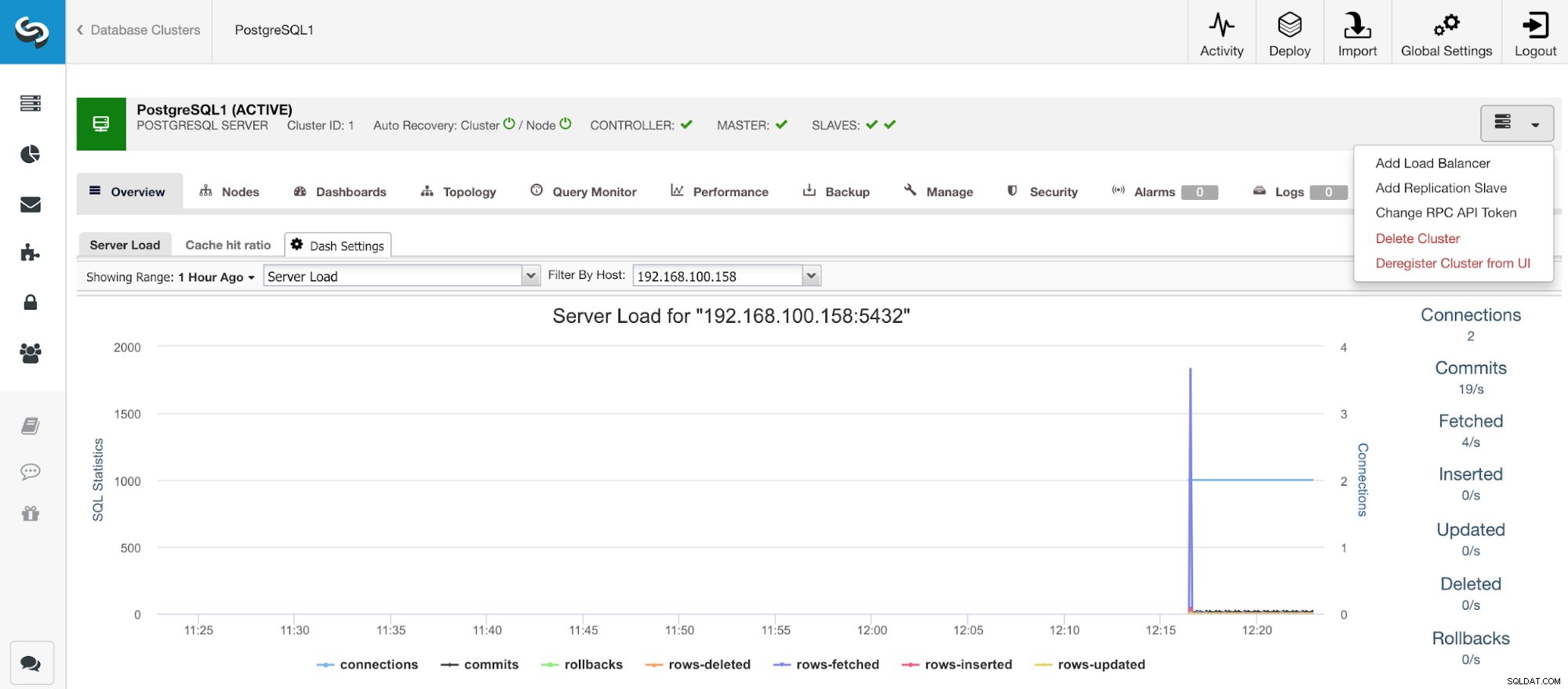
 Tela principal do ClusterControl
Tela principal do ClusterControl Depois de criar nosso cluster, podemos realizar várias tarefas nele, como adicionar um balanceador de carga (HAProxy) ou uma nova réplica.
 Seção ClusterControl Cluster
Seção ClusterControl Cluster Escalando o PostgreSQL 11
Se formos para ações de cluster e selecionarmos “Add Replication Slave”, podemos criar uma nova réplica do zero ou adicionar um banco de dados PostgreSQL existente como réplica.
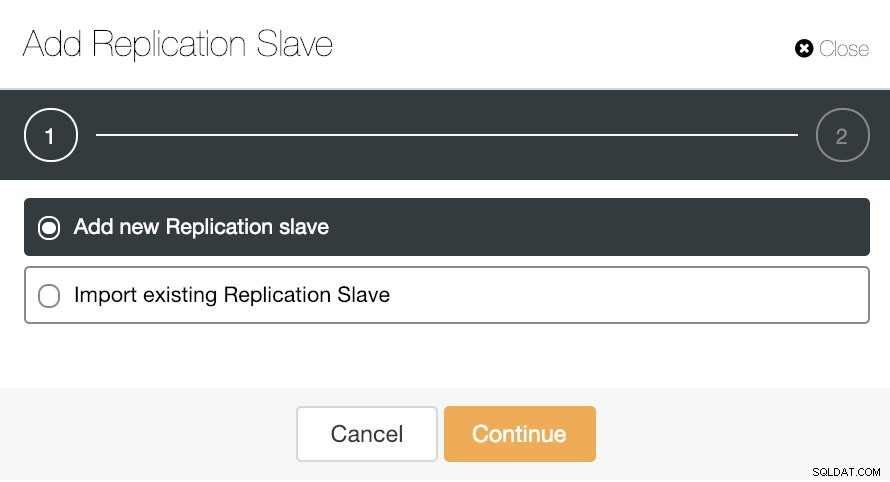 ClusterControl Add Replication Slave Option
ClusterControl Add Replication Slave Option Vamos ver como adicionar um novo slave de replicação pode ser uma tarefa muito fácil.
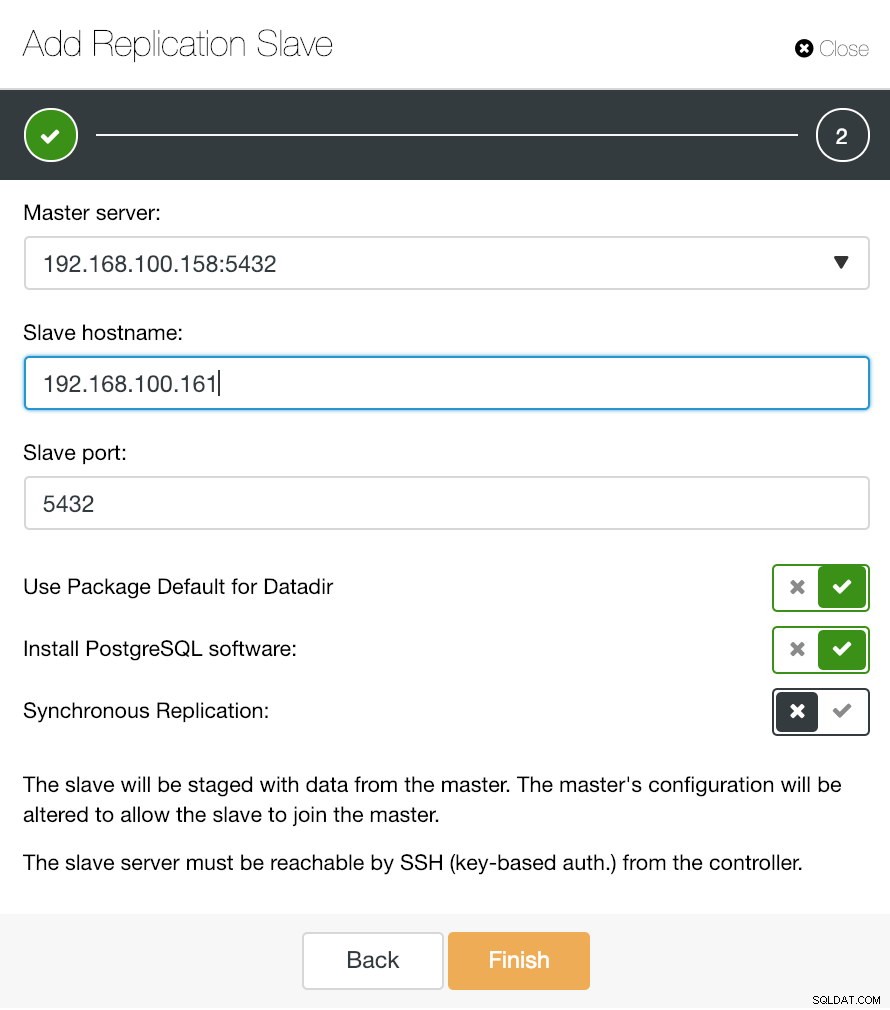 ClusterControl Adicionar informações do escravo de replicação
ClusterControl Adicionar informações do escravo de replicação Como você pode ver na imagem, só precisamos escolher nosso servidor Master, inserir o endereço IP do nosso novo servidor slave e a porta do banco de dados. Então, podemos escolher se queremos que o ClusterControl instale o software para nós e se o escravo de replicação deve ser síncrono ou assíncrono.
Dessa forma, podemos adicionar quantas réplicas quisermos e distribuir o tráfego de leitura entre elas usando um balanceador de carga, que também podemos implementar com o ClusterControl.
Podemos ver mais informações sobre o HA para PostgreSQL em um blog relacionado.
A partir do ClusterControl, você também pode executar diferentes tarefas de gerenciamento como Reboot Host, Rebuild Replication Slave ou Promover Slave, com um clique.
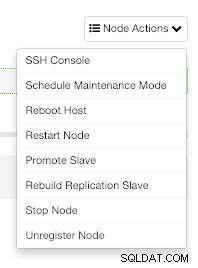 Ações do nó ClusterControl
Ações do nó ClusterControl Backups
Em blogs anteriores, demos uma olhada nos recursos de backup e PITR ClusterControl para PostgreSQL. Agora, na última versão do ClusterControl, temos os recursos "verificar/restaurar backup em um host autônomo" e "criar um cluster a partir de um backup existente".
No ClusterControl, selecione seu cluster e vá para a seção "Backup" para ver seus backups atuais.
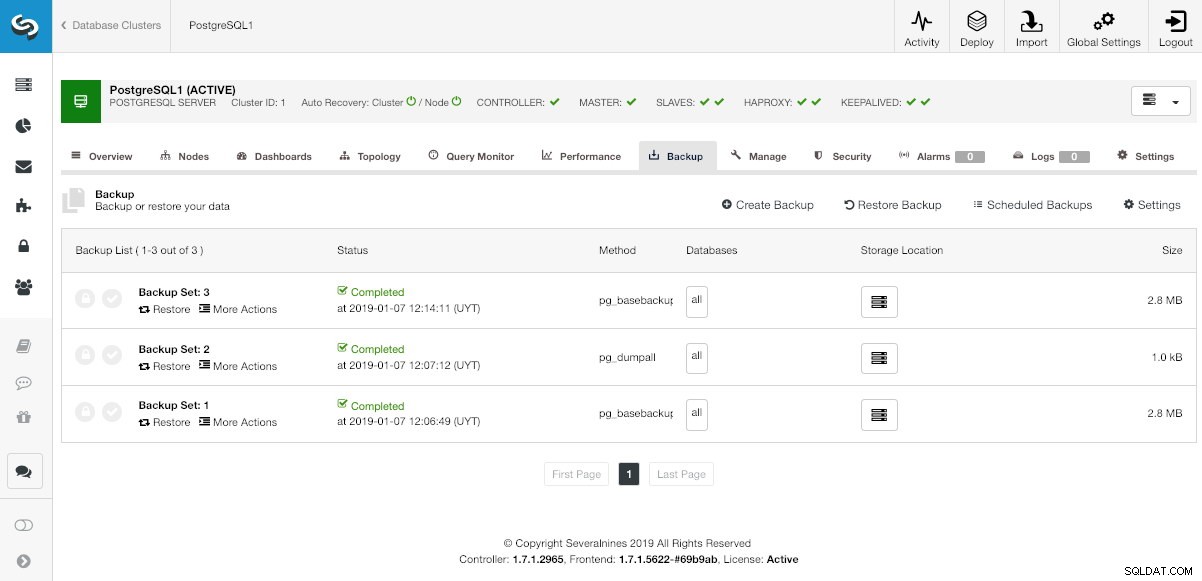 Seção de backups do ClusterControl
Seção de backups do ClusterControl Na opção "Restaurar", primeiro você pode escolher qual backup será restaurado.
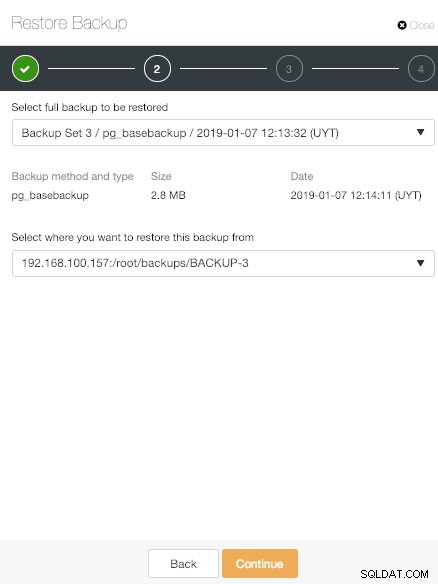 Opção de backup de restauração do ClusterControl
Opção de backup de restauração do ClusterControl Aí temos três opções.
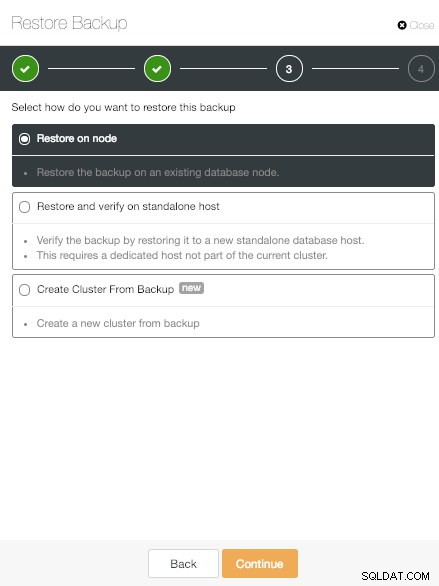 ClusterControl Restore on node Option
ClusterControl Restore on node Option A primeira é a opção clássica "Restaurar no nó". Isso apenas restaura o backup selecionado em um nó específico.
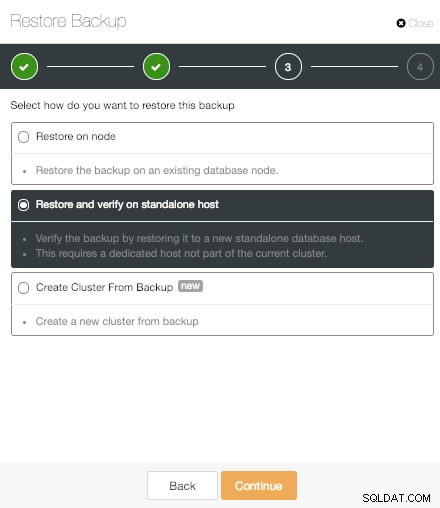 ClusterControl Restaurar e verificar no host autônomo Opção
ClusterControl Restaurar e verificar no host autônomo Opção A opção "Restaurar e verificar no host autônomo" é um novo recurso do ClusterControl PostgreSQL. Isso nos permite testar o backup gerado restaurando-o em um host autônomo. Isso é realmente útil para evitar surpresas em um cenário de recuperação de desastres.
Para usar esse recurso, precisamos de um host dedicado (ou VM) que não faça parte do cluster.
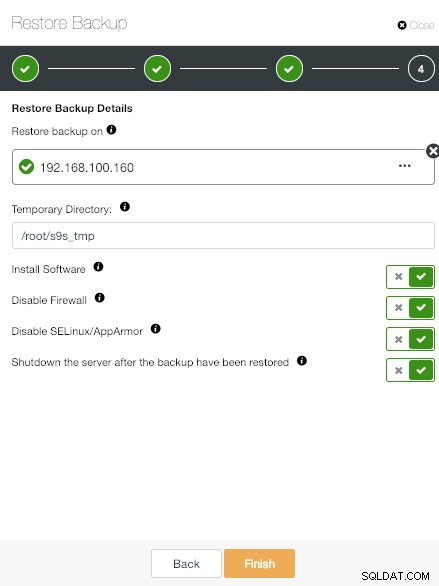 ClusterControl Restaurar e verificar no host autônomo Informações
ClusterControl Restaurar e verificar no host autônomo Informações Adicione o endereço IP do host dedicado e escolha as opções desejadas.
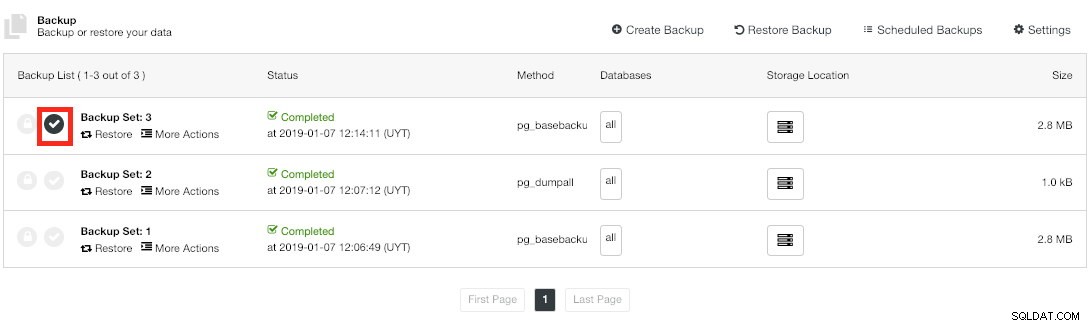 Backup verificado do ClusterControl
Backup verificado do ClusterControl Quando o backup for verificado, você poderá ver o ícone "Verificado" na lista de backups.
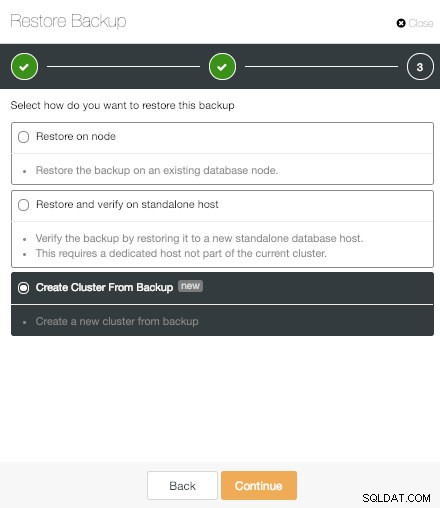 ClusterControl Criar cluster a partir da opção de backup
ClusterControl Criar cluster a partir da opção de backup "Criar cluster do backup" é outro novo recurso importante do PostgreSQL do ClusterControl.
Como o próprio nome sugere, este recurso nos permite criar um novo cluster PostgreSQL com os dados do backup gerado.
Após escolher esta opção, precisamos seguir os mesmos passos que vimos na seção de deploy.
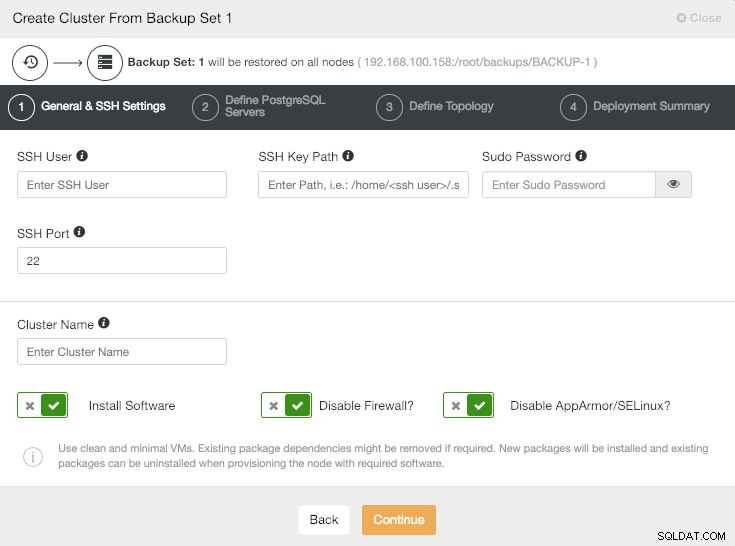 ClusterControl Criar cluster a partir de informações de backup
ClusterControl Criar cluster a partir de informações de backup Todas as configurações como usuário, número de nós ou tipo de replicação podem ser diferentes neste novo cluster.
Quando o novo cluster é criado, você pode ver tanto o antigo quanto o novo na tela principal do ClusterControl.
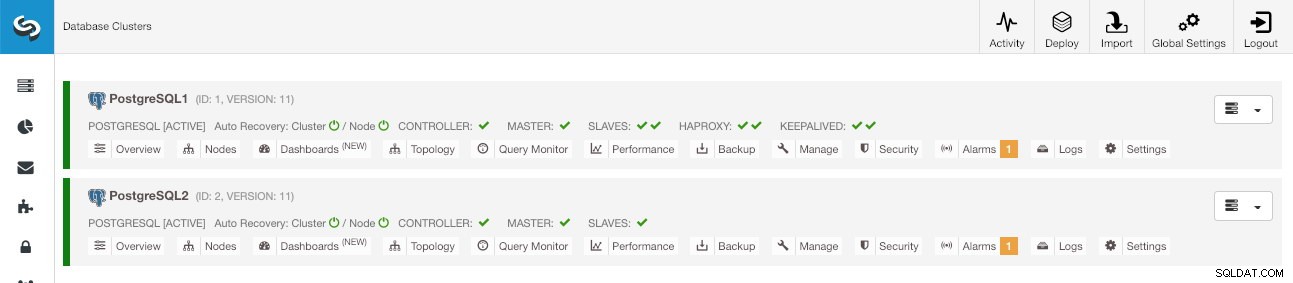 Tela principal do ClusterControl
Tela principal do ClusterControl Conclusão
Como vimos acima, agora você pode implantar a versão mais recente do PostgreSQL, versão 11, usando o ClusterControl. Uma vez implantado, o ClusterControl fornece uma ampla gama de recursos, desde monitoramento, alerta, failover automático, backup, recuperação pontual, verificação de backup, até dimensionamento de réplicas de leitura. Isso pode ajudá-lo a gerenciar o Postgres de maneira amigável e intuitiva. De uma chance!