Em 2013, escrevi sobre um bug no otimizador onde o 2º e 3º argumentos para
DATEDIFF() pode ser trocado – o que pode levar a estimativas incorretas de contagem de linhas e, por sua vez, seleção de plano de execução ruim:- Surpresas e suposições de desempenho :DATEDIFF
No fim de semana passado, fiquei sabendo de uma situação semelhante e fiz a suposição imediata de que era o mesmo problema. Afinal, os sintomas pareciam quase idênticos:
- Havia uma função de data/hora em
WHEREcláusula.- Desta vez foi
DATEADD()em vez deDATEDIFF().
- Desta vez foi
- Houve uma estimativa de contagem de linhas obviamente incorreta de 1, em comparação com uma contagem real de mais de 3 milhões.
- Na verdade, essa era uma estimativa de 0, mas o SQL Server sempre arredonda essas estimativas para 1.
- Foi feita uma seleção de plano ruim (neste caso, uma junção de loop foi escolhida) devido à estimativa baixa.
O padrão ofensivo ficou assim:
WHERE [datetime2(7) column] >= DATEADD(DAY, -365, SYSUTCDATETIME());
O usuário tentou várias variações, mas nada mudou; eles finalmente conseguiram contornar o problema alterando o predicado para:
WHERE DATEDIFF(DAY, [column], SYSUTCDATETIME()) <= 365;
Isso obteve uma estimativa melhor (a estimativa típica de desigualdade de 30%); então não está certo. E embora tenha eliminado a junção de loop, existem dois grandes problemas com esse predicado:
- Não é não a mesma consulta, pois agora está procurando por limites de 365 dias passados, em vez de ser maior do que um ponto específico no tempo de 365 dias atrás. Estatisticamente significativo? Talvez não. Mas, tecnicamente, não é a mesma coisa.
- Aplicar a função na coluna torna a expressão inteira não-sargável – levando a uma varredura completa. Quando a tabela contém apenas um pouco mais de um ano de dados, isso não é grande coisa, mas à medida que a tabela fica maior ou o predicado se torna mais estreito, isso se torna um problema.
Novamente, cheguei à conclusão de que o
DATEADD() operação era o problema e recomendou uma abordagem que não dependesse de DATEADD() – construindo um datetime de todas as partes do tempo atual, permitindo-me subtrair um ano sem usar DATEADD() :WHERE [column] >= DATETIMEFROMPARTS(
DATEPART(YEAR, SYSUTCDATETIME())-1,
DATEPART(MONTH, SYSUTCDATETIME()),
DATEPART(DAY, SYSUTCDATETIME()),
DATEPART(HOUR, SYSUTCDATETIME()),
DATEPART(MINUTE, SYSUTCDATETIME()),
DATEPART(SECOND, SYSUTCDATETIME()), 0); Além de ser volumoso, isso tinha alguns problemas próprios, ou seja, um monte de lógica teria que ser adicionado para explicar adequadamente os anos bissextos. Primeiro, para que não falhe se for executado em 29 de fevereiro e segundo, para incluir exatamente 365 dias em todos os casos (em vez de 366 durante o ano seguinte a um dia bissexto). Correções fáceis, é claro, mas tornam a lógica muito mais feia – especialmente porque a consulta precisava existir dentro de uma visão, onde variáveis intermediárias e várias etapas não são possíveis.
Enquanto isso, o OP registrou um item do Connect, consternado com a estimativa de 1 linha:
- Conexão nº 2567628:restrição com DateAdd() não fornecendo boas estimativas
Então Paul White (@SQL_Kiwi) apareceu e, como muitas vezes antes, lançou alguma luz adicional sobre o problema. Ele compartilhou um item relacionado do Connect arquivado por Erland Sommarskog em 2011:
- Conexão nº 685903:estimativa incorreta quando sysdatetime aparece em uma expressão dateadd()
Essencialmente, o problema é que uma estimativa ruim pode ser feita não simplesmente quando
SYSDATETIME() (ou SYSUTCDATETIME() ) aparece, como Erland relatou originalmente, mas quando qualquer datetime2 expressão está envolvida no predicado (e talvez apenas quando DATEADD() também é usado). E pode acontecer nos dois sentidos – se trocarmos >= para <= , a estimativa se torna a tabela inteira, então parece que o otimizador está olhando para o SYSDATETIME() value como uma constante e ignorando completamente quaisquer operações como DATEADD() que são realizados contra ele. Paul compartilhou que a solução é simplesmente usar um
datetime equivalente ao calcular a data, antes de convertê-la para o tipo de dados apropriado. Neste caso, podemos trocar SYSUTCDATETIME() e altere para GETUTCDATE() :WHERE [column] >= CONVERT(datetime2(7), DATEADD(DAY, -365, GETUTCDATE()));
Sim, isso resulta em uma pequena perda de precisão, mas também uma partícula de poeira pode desacelerar seu dedo no caminho para pressionar o

As leituras são semelhantes porque a tabela contém dados quase exclusivamente do ano passado, portanto, mesmo uma busca se torna uma varredura de intervalo da maior parte da tabela. As contagens de linhas não são idênticas porque (a) a segunda consulta é interrompida à meia-noite e (b) a terceira consulta inclui um dia extra de dados devido ao dia bissexto no início deste ano. De qualquer forma, isso ainda demonstra como podemos nos aproximar das estimativas adequadas eliminando
DATEADD() , mas a correção adequada é remover a combinação direta de DATEADD() e datetime2 . Para ilustrar ainda mais como as estimativas estão errando, você pode ver que, se passarmos argumentos e direções diferentes para a consulta original e a reescrita de Paul, o número de linhas estimadas para a primeira é sempre baseado no tempo atual - eles não 'não muda com o número de dias passados (enquanto o de Paul é relativamente preciso todas as vezes):
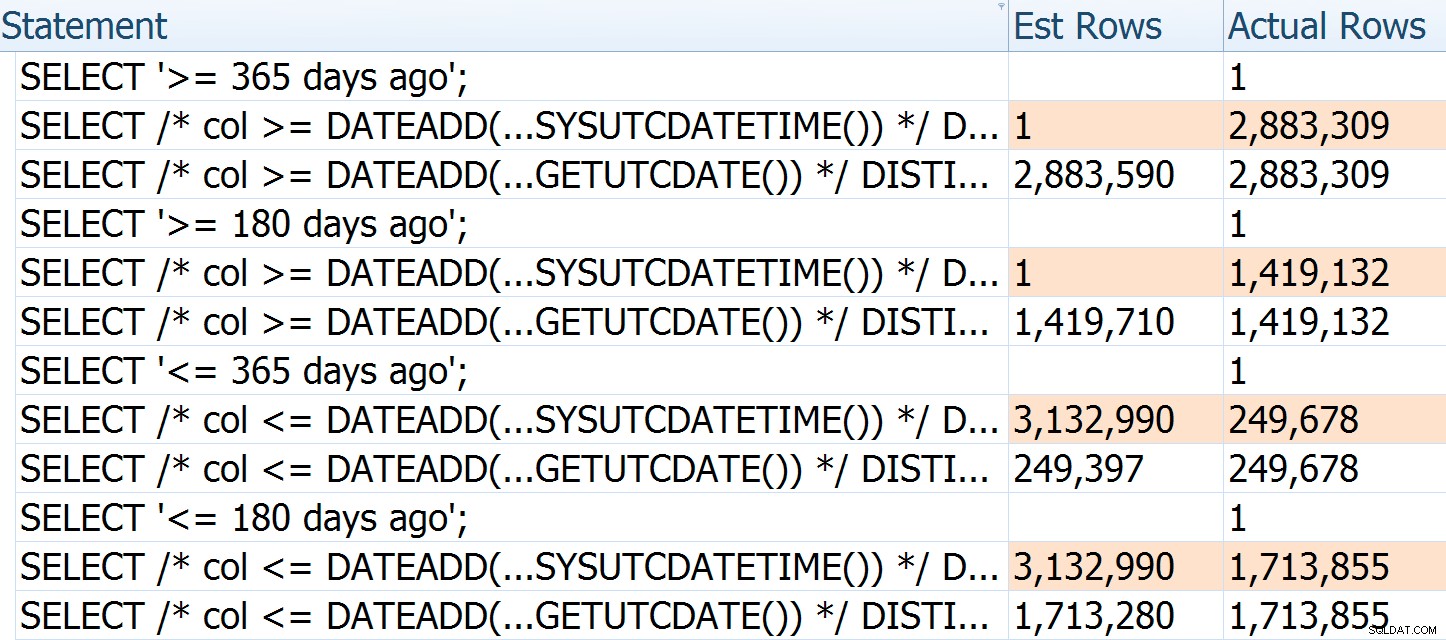 As linhas reais para a primeira consulta são um pouco menores porque isso foi executado após um longo cochilo
As linhas reais para a primeira consulta são um pouco menores porque isso foi executado após um longo cochilo As estimativas nem sempre serão tão boas; minha tabela apenas tem distribuição relativamente estável. Eu o preenchi com a seguinte consulta e, em seguida, atualizei as estatísticas com fullscan, caso você queira experimentar isso por conta própria:
-- OP's table definition:
CREATE TABLE dbo.DateaddRepro
(
SessionId int IDENTITY(1, 1) NOT NULL PRIMARY KEY,
CreatedUtc datetime2(7) NOT NULL DEFAULT SYSUTCDATETIME()
);
GO
CREATE NONCLUSTERED INDEX [IX_User_Session_CreatedUtc]
ON dbo.DateaddRepro(CreatedUtc) INCLUDE (SessionId);
GO
INSERT dbo.DateaddRepro(CreatedUtc)
SELECT dt FROM
(
SELECT TOP (3150000) dt = DATEADD(HOUR, (s1.[precision]-ROW_NUMBER()
OVER (PARTITION BY s1.[object_id] ORDER BY s2.[object_id])) / 15, GETUTCDATE())
FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2
) AS x;
UPDATE STATISTICS dbo.DateaddRepro WITH FULLSCAN;
SELECT DISTINCT SessionId FROM dbo.DateaddRepro
WHERE /* pick your WHERE clause to test */; Comentei sobre o novo item do Connect e provavelmente voltarei e retocarei minha resposta do Stack Exchange.
A moral da história
Tente evitar combinar
DATEADD() com expressões que geram datetime2 , especialmente em versões mais antigas do SQL Server (isso foi no SQL Server 2012). Também pode ser um problema, mesmo no SQL Server 2016, ao usar o modelo de estimativa de cardinalidade mais antigo (devido ao nível de compatibilidade mais baixo ou ao uso explícito do sinalizador de rastreamento 9481). Problemas como esse são sutis e nem sempre imediatamente óbvios, então espero que isso sirva como um lembrete (talvez até para mim na próxima vez que me deparar com um cenário semelhante). Como sugeri no último post, se você tiver padrões de consulta como esse, verifique se está obtendo estimativas corretas e anote em algum lugar para verificá-las novamente sempre que houver grandes alterações no sistema (como uma atualização ou um service pack).